FiftyOne launched August 2020, about six months ago. Although the launch was exciting for our team, as it was the culmination of many months of work, the last six months have been even more exciting. With its unique emphasis on rapid dataset analysis for better models, faster, FiftyOne is quickly become an everyday tool for computer vision and machine learning engineers. Even in the face of growing competition in tools like Aquarium and Nucleus, FiftyOne’s flexibility — it is the sole open-source offering and brings the tool to you and your data rather than forcing you to bring your data into some specific cloud-service — and capabilities — it has several unique and innovative features around dataset quality and model performance analysis — have brought it to the forefront of the machine learning developer tools conversation.
So, yes, definitely exciting! But, I’ve personally been lost in the dust. While FiftyOne’s userbase grew from a few dozen private-beta users to hundreds of returning active users, the team has been adding a rich amount of new functionality. Although we collectively plan and work through our roadmap, as the CEO and a Professor, I was more outward facing: giving talks about open-source AI and my views on the future of AI, talking with users and customers, maintaining relationships with investors, and so on. I hence thought it would be good to take a moment and review these new developments with FiftyOne and how it’s progressed over the last six months.
Here is what I found, with an emphasis on the core features for dataset analysis, as I intentionally neglect the Brain capabilities for tasks like finding label mistakes and unique images in a dataset, for now.
- Setup and Installation: getting started with FiftyOne now takes less than a minute!
- Analysis: working with new datasets has a rich set of new user interface features for rapidly building an intuition for a dataset through interactive querying, searching and sorting.
- Access: an integrated dataset zoo and an innovative model zoo make trying out new ideas so easy.
- Video: FiftyOne now support native video datasets and associated tasks.
- Sharing: Jupyter notebooks and Colab support significantly enhance FiftyOne’s utility for computer vision and machine learning in practice.
Setup and Installation: Easy as Pie
What’s New? Simple pip-based install from the standard pypi server with no additional manual work required.
When I was a core code contributor to FiftyOne last year, it took some serious work to get it up and running on my machine: multiple packages, various setup and configuration scripts, and the download of some packages took a good amount of time. Today, here’s what I did to get it up and running. This is from scratch, with python 3.7.5. already installed.
python3 -m venv foe source foe/bin/activate pip install -U pip setuptools wheel pip install ipython pip install fiftyone
This whole installation took 1 minute (over my very slow cell-phone based internet connection). The installation of IPython is optional but it’s my basic workflow so I kept it here for completeness; and, the upgrade of pip, setuptools, and wheel are also optional but I’ve learned to keep them as a best practice so that as few things as possible are built from source (instead of 1 minute, the FiftyOne installation takes about 10 minutes on my machine if I do not upgrade pip, for example, because of building some of its dependencies from source). The FiftyOne version installed ((foe)$ fiftyone constants) is 0.7.2.
And, there is a quickstart now, which did not exist the last time I used FiftyOne!
(foe)$ fiftyone quickstart
Voila! I see the quickstart dataset popup in my browser.
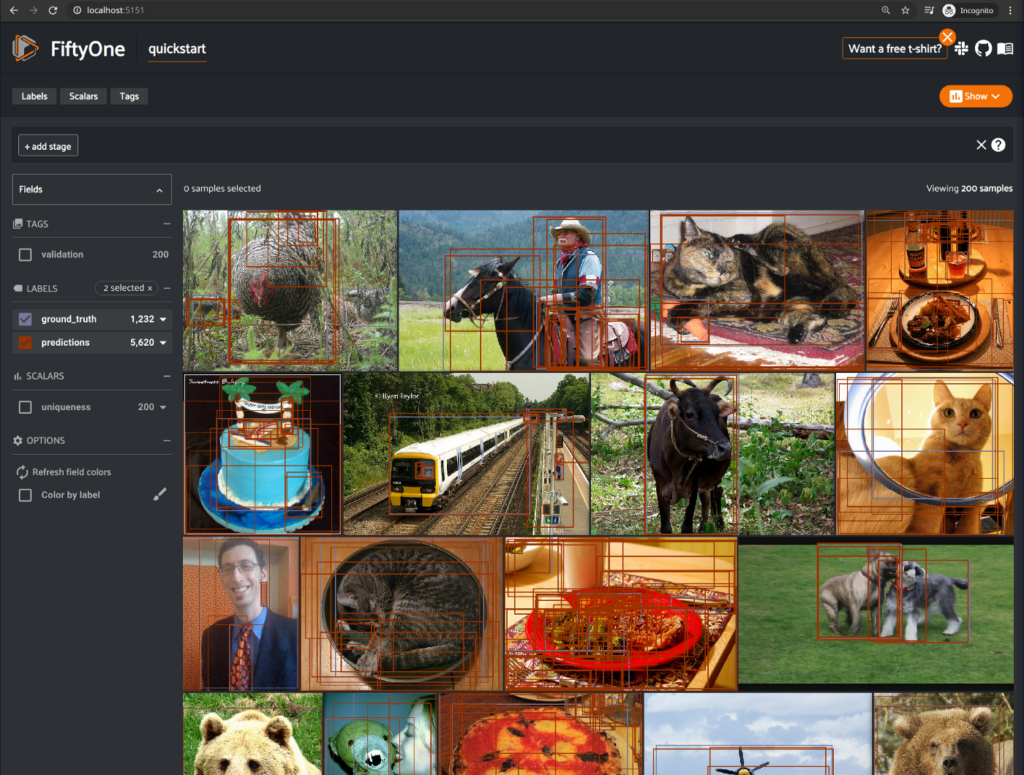
Immediately, I’m excited by the leaps in analysis capabilities and UX that the tool has seen in the last six months. I’ll talk about a lot of these aspects below. But, one interesting surprise to me is the elegant way the interface in the browser handles disconnection from the server (in this case, when I hit CTRL-C from the bash shell that was running the quickstart).
Analysis: Working with new Datasets
What’s New? Numerous filtering and visualization capabilities that help a machine learning scientist rapidly analyze and build an intuition for a dataset.
When we launched FiftyOne, it had support for visualizing image datasets, including their annotations, as well as support for adding dynamic fields to the dataset, such as tags. The interface did allow you to easily filter based on tags at the time, but not much more.
Wow, have things changed. Now, you can directly analyze the distributions over not only tags, but also labels and scalar fields captured in your dataset. The UX has a handy toggle button to expose these graphing tools.
Toggling that button slides out a graphing pane that blows my mind! Direct distributions over nearly any field in your dataset: the denumerable labels fields, the continuous scalar fields and various tags. Here are two example outputs from the quickstart dataset, which includes a scalar field called uniqueness, computed from the Brain functionality.
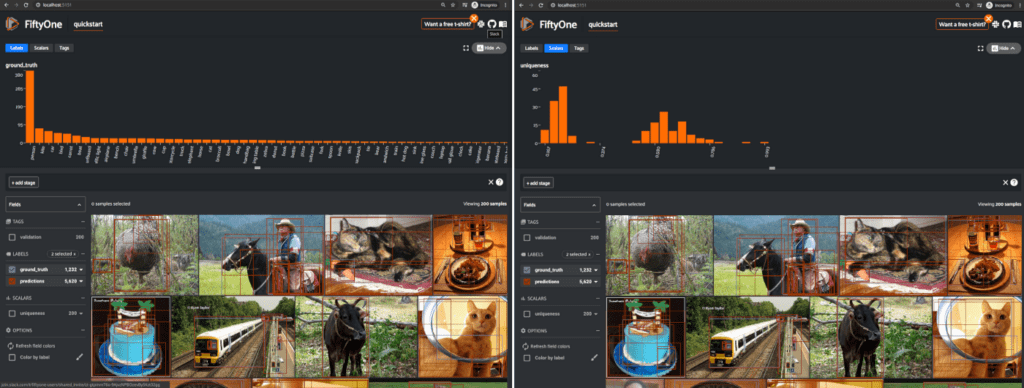
Under the hood, this graphing capability is enabled by the new Aggregations capabilities in Fiftyone that let you compute various summary statistical measures over your dataset and its properties. The importance of understanding how your labels and model outputs are distributed in aggregate on the dataset is huge. Label imbalance, for example, remains a technical challenge for training robust models that will transfer into operational production and meet the same performance measures that were observed in the lab. If the machine learning scientist does not adequately study and monitor dataset imbalance, he or she runs the great risk of delivering a tool that will underperform in practice. It is his or her responsibility to explicitly analyze dataset balance, for example.
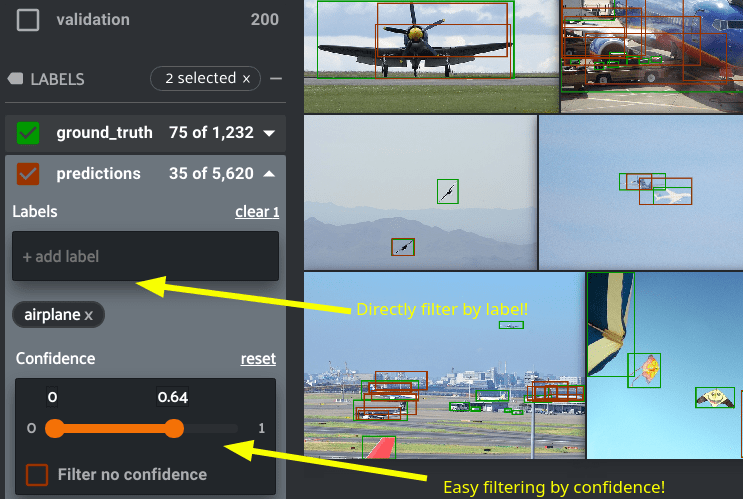
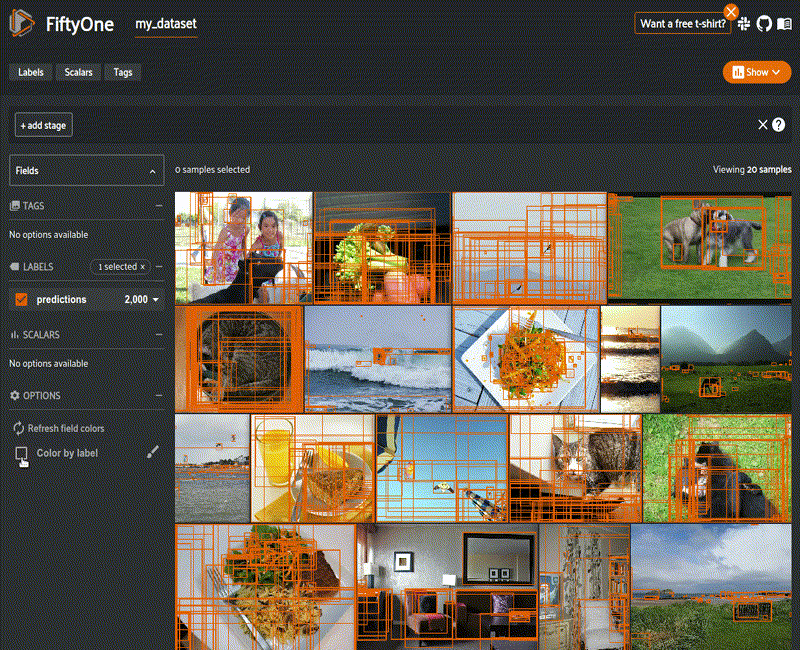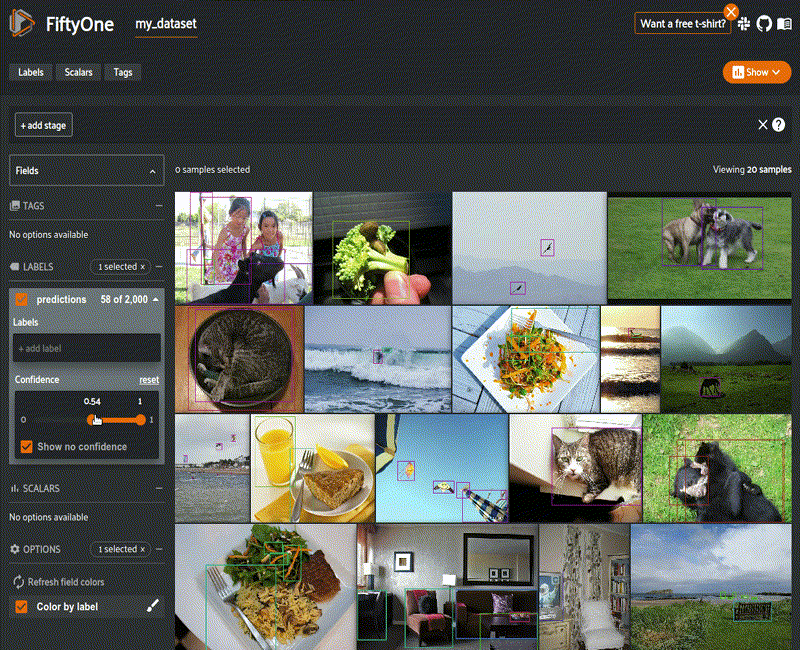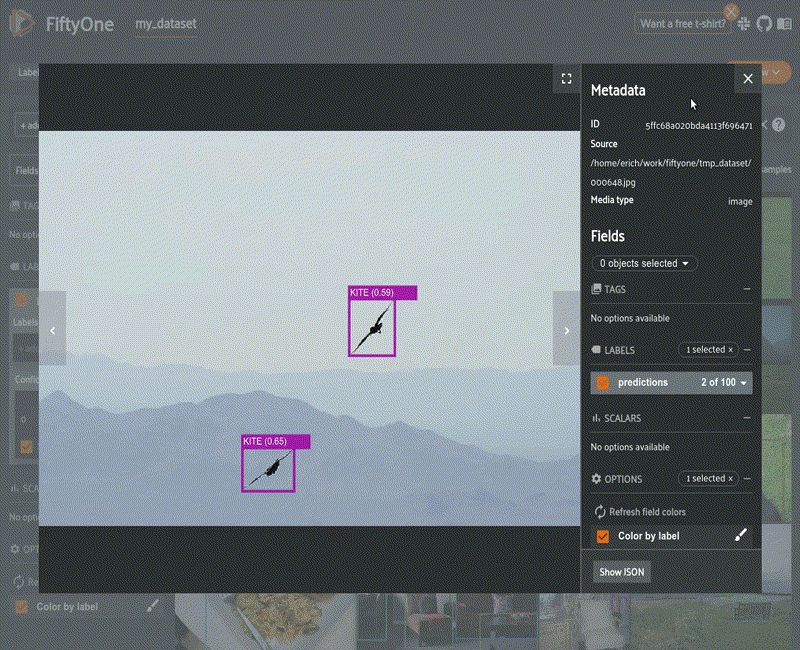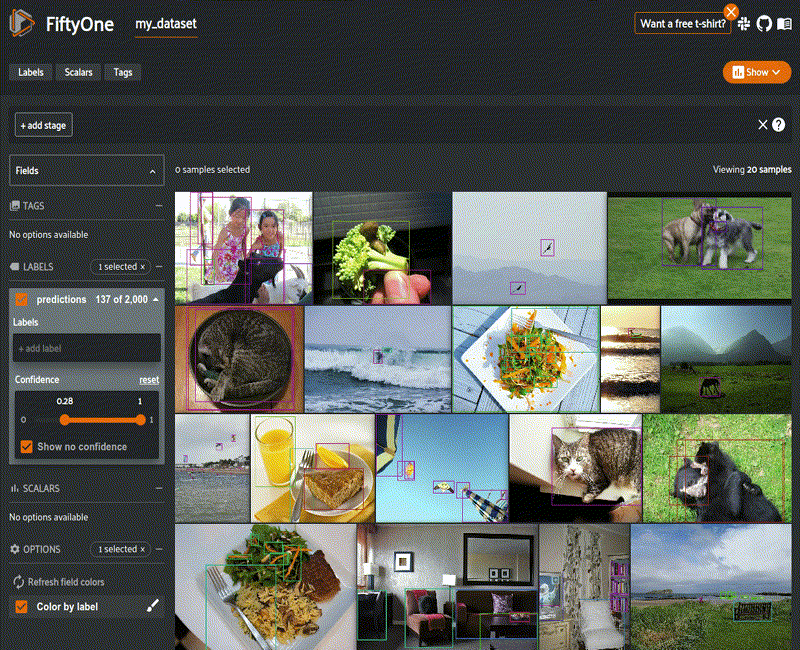
Beyond aggregate analysis, the last six months have seen major enhancements to analyze individual data samples and groups of samples based on various characteristics, such as the confidence on a certain model output (as I show on the left), or on more sophisticated functions based on interesting properties of the data and model output, such as object size, for example. The UX has greatly improved to allow for easy manipulation of many of these properties too with sliders and direct ability to filter images by label, as the example.
When more sophisticated filtering is required than these easy-to-use elements, the app now allows power users to control all aspects of filtering, sorting, and searching datasets and dataset samples directly in the UX.
These enhancements are captured in the view bar.
For example, as one user in our Slack community recently asked: “In the app, is there a way to search for a sample with a filepath that contains a given string?” Why yes! Place the following (appropriately customized for your dataset, of course) into the view bar’s match box:
{
"$expr": {
"$regexMatch": {
"input": "$filepath",
"regex": "\\.jpg$",
"options": null
}
}
}
This is the same as the following direct Python expression:
view = dataset.match(F(“filepath”).re_match(“\.jpg$”))
The view bar unlocks huge query possibilities. But, I must caution you: it is so powerful it can overwhelm. We are considering ways to improve the UX for the view bar and its capabilities — ideas welcome! Stay tuned.
Access: Going to the Zoo
What’s New? A native dataset zoo and an innovative model zoo that both work out of the box to give easy access to important datasets and models.
One design goal we had from the beginning with FiftyOne was to make the user’s work as simple as possible and meet them in their context. This design goal gave rise to a number of valuable properties of the tool at launch, such as the ability to work on a laptop on an airplane with no internet connection (the pandemic notwithstanding). However, we knew we could do better and help our users spend increasingly more of their time directly on computer vision and machine learning science, rather than tedious scripting and data wrangling.
To that end, we have added not one but two Zoos to the open-source library. We have a dataset zoo and a model zoo. At the surface, neither seems exceptionally innovative. But, when you look deeper, well, you’ll smile.
The dataset zoo, for example, currently has about two dozen datasets across the computer vision problem spectrum. It is more flexible than other dataset zoos. For example, works whether you use a TensorFlow or PyTorch backend. And, more importantly, since FiftyOne support so many different dataset formats and schemas, the dataset zoo functionality can act as a Babel-like translator to help you get any of these datasets into a format you need to get your work done.
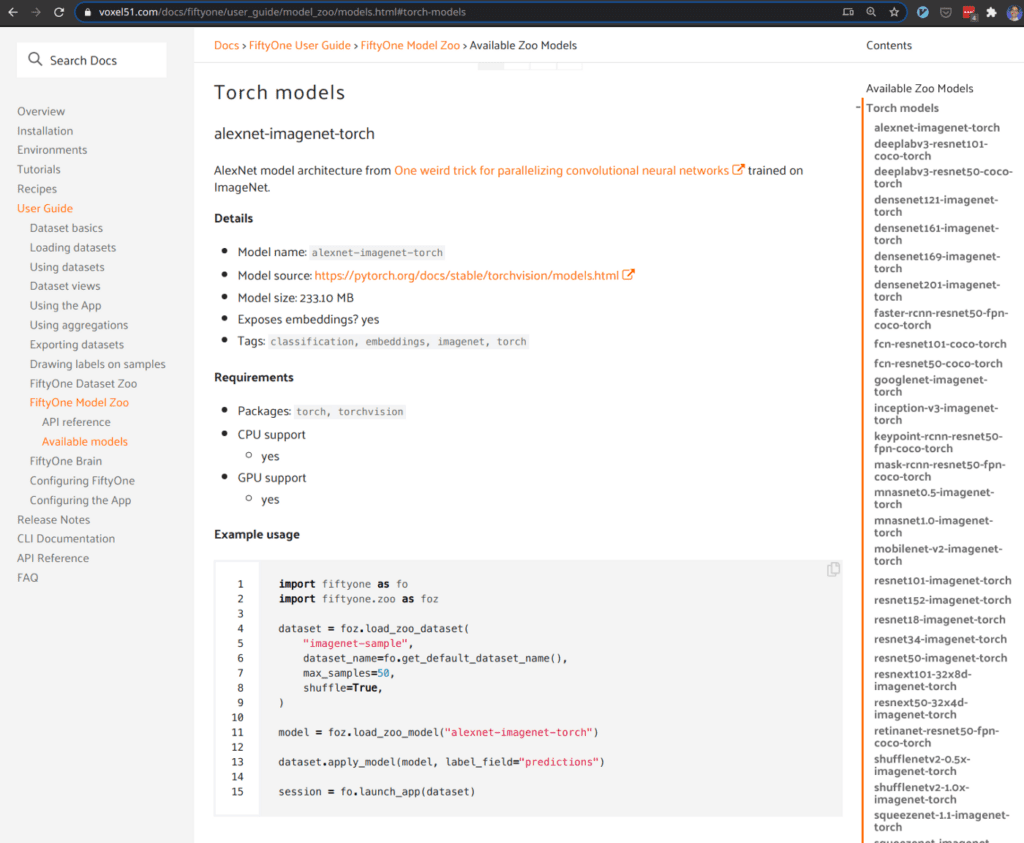
The model zoo sets the bar for model sharing. Yes, our broader community has gotten better at sharing code (e.g., https://paperswithcode.com/). Yet, it remains nebulous when you actually want to quickly test out an idea from a paper or try out a new model. Whereas existing model zoos present what amounts to an unconstrained bazaar of code, the FiftyOne model zoo is a curated collection of models that will run out of the box with no configuration. There are dozens of such models across the Tensorflow and Torch backends in FiftyOne.
Finally, an important reminder about the tool: since FiftyOne is open-source, one natural way to contribute is to add a new dataset or model to the zoo! This will help make FiftyOne even more valuable. Do note that given the advantages of the FiftyOne zoos noted above, there are more strict requirements for how to add something to them in contrast to other zoos, which, well, are more like jungles.
Video: FiftyOne now supports video datasets
What’s New? The section title says everything: FiftyOne now supports both image and video datasets natively.
In some sense, it seems like video has always been the black sheep in computer vision. The number of image-based papers seems to always dwarf the number of video-based papers. Video is harder to work with: it is bigger, more complex, and exposes a new layer of potential inference problems. Yet, the number of video cameras worldwide is increasing at an alarming pace (nearly 45 billion video cameras today). Interestingly, video has taken an enhanced role in the recent literature, perhaps catapulted by the potential for self-supervision and related ideas that reduce the need for extensive and error-prone manual annotation.
Well, I definitely have a bit of a proverbial chip on my shoulder about this(as you may know, I focus on video in my academic research). So, you can imagine how excited I was when the FiftyOne dev team announced the native support for video (numerous video datasets, many video mtasks, even a state of the art javascript-based annotated video renderer) in FiftyOne.
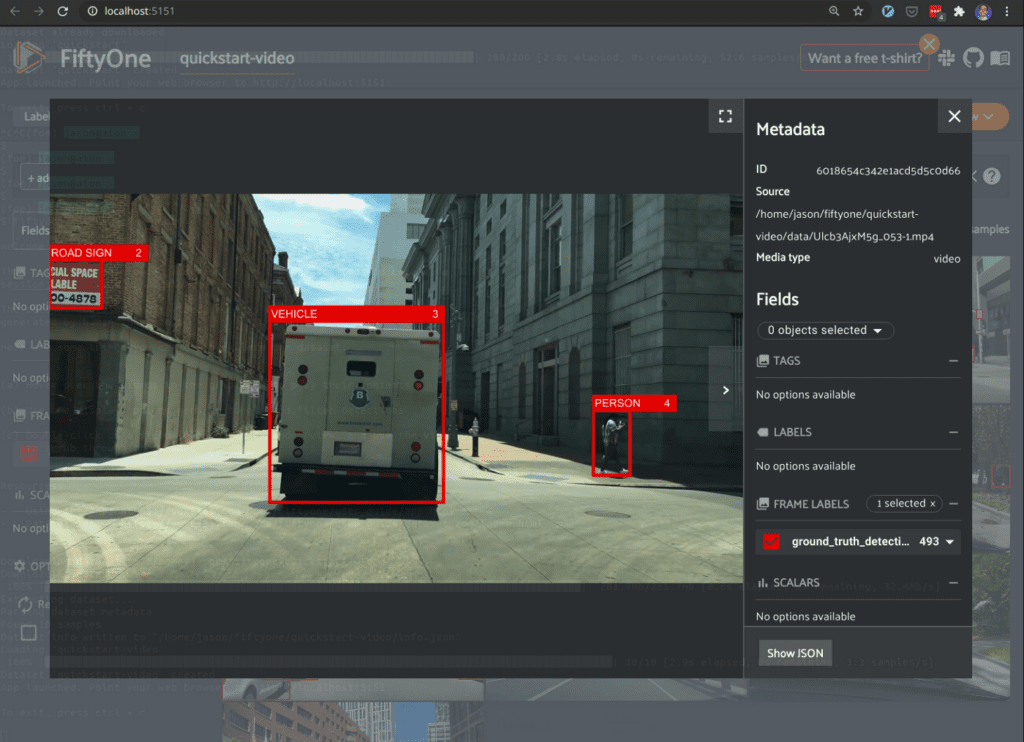
Video support is easily explored using this command:
fiftyone quickstart --video
Sharing: Notebooks and Colab
What’s New? FiftyOne works in the Jupyter and Colab ecosystem while nicely maintaining the notebook metaphor for recordability and sharing.
In practice, computer vision and machine learning seldom happen by lone scientists in dark, late night offices as we might have observed in classical hackers. No, CV/ML is increasingly a team effort complete with somewhat mature analyses over how to best compose the team, suggesting we’re well beyond the direct appreciation of the need for a team in the first place. This is true for numerous organizations I have been a part of over the last decade, including Voxel51 when we have had active machine learning application projects.
And, when you have teams, you need to cooperate by sharing your work and by maintaining a good record of what you’ve done. The current de facto approach to both is now through the use of Jupyter Notebooks, also open-source, which make it natural to both share and record your work. Numerous services, such as Google Colab (which I’ve used as the backdrop for giving assignments in my computer vision course in recent offerings!), then make it easy to run the notebook in the cloud.
So, you could imagine my jaw dropped to the floor when the team was able to add native Jupyter and Colab support to FiftyOne. I mean — Fiftyone is an app — how can you inject an interactive app into a notebook? You see, my understanding of notebooks is operating under the well appreciated notebook metaphor: I can write things down in the notebook, I can package it up and share it with a friend, I can record my work in the notebook, I can compute things I’ve written in the notebook and then record their outputs (in the notebook), and so on. So, how could an interactive app be integrated within the notebook and yet, maintain this natural metaphor? Well, the FiftyOne team did it.
FiftyOne notebooks indeed do let you incorporate the interactive app inside of the notebook so you can do your visual data analysis, dataset quality and model performance work like you would with an IPython session for example. But, you have the added benefit of then being able to ship off your work to share with a colleague, or come back to it and rerun it in a Colab instance. The Jupyter integration for FiftyOne maintains the notebook metaphor by automatically recording an image of your work for each cell in which the app was invoked; each of the cells are connected to the same underlying Python session to avoid memory overload. Then each such recorded image can be reactivated and further manipulated. You have to see it to believe, it’s seriously amazing; try the quickstart in Colab. Here is an example of a Jupyter notebook in action.
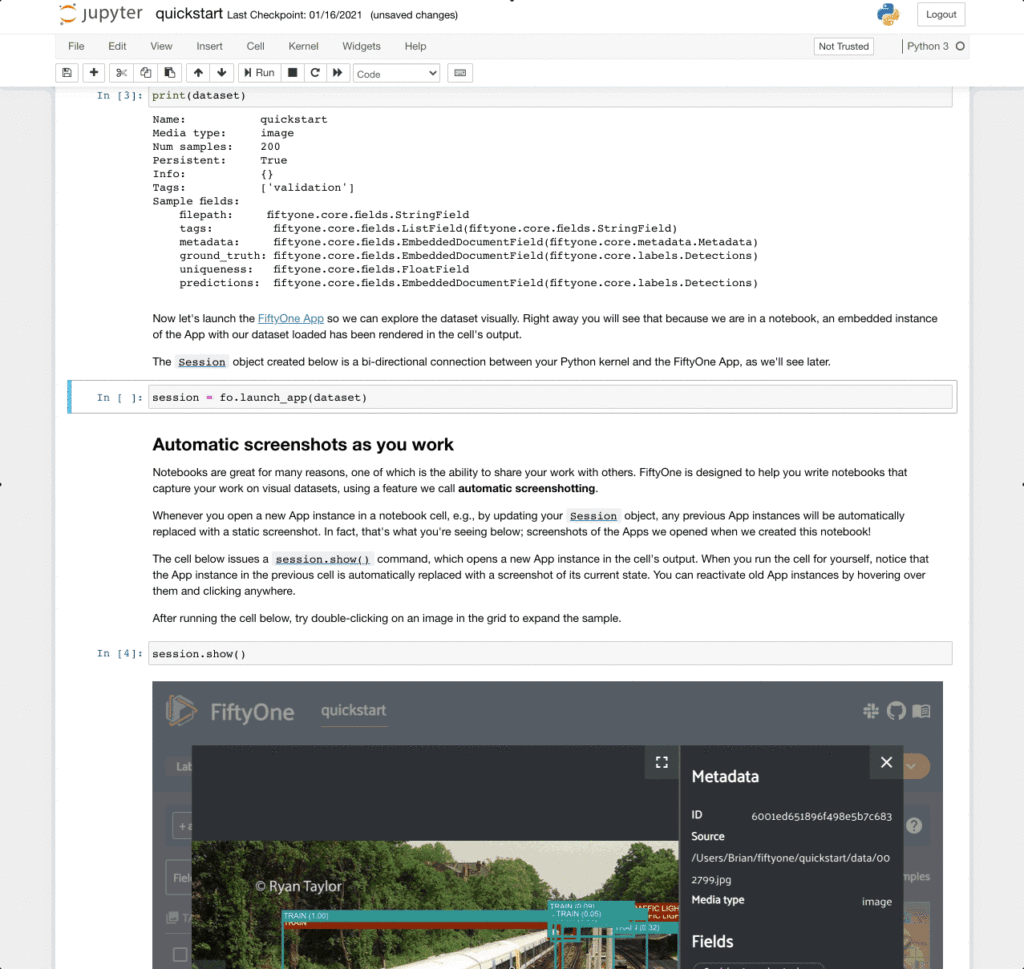
This really pushes the foundational boundary of what is possible with Jupyter notebooks. We’re the first — to my knowledge — interactive app inside of a notebook that still nicely maintains the true notebook metaphor. If you’re interested in learning more about the notebook and Colab support for FiftyOne, I suggest you check out Ben’s recent blog post.
Wrapping Up
Thanks for taking the time to walk through some of the cool enhancements FiftyOne has seen in the last six months since its initial launch. There are many more enhancements to the tool at both the core, library level and the user interface that I could not include in here for time. The docs are a good place to go to learn more about the capabilities that make FiftyOne the new standard in open-source computer vision and machine learning developer tools for dataset analysis and model performance analysis. Add it to your toolbox today!
We always love to hear from our users: what are you learning, how are you using FiftyOne in your CV/ML work, what features would help? There are two ways to connect to us: our interactive Slack community for general discussion and help, and our GitHub repo for issues, forks, and stars!

