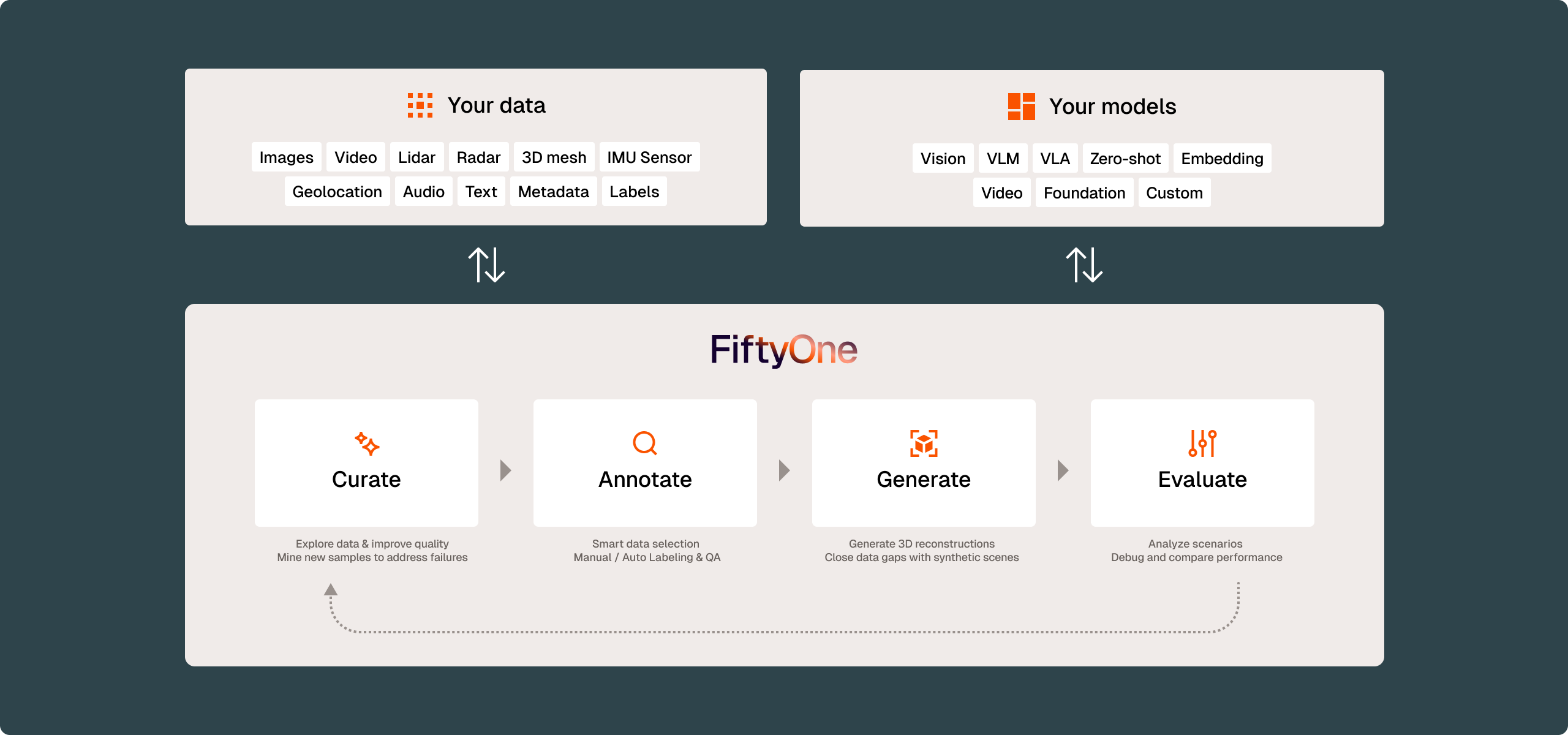
FiftyOne powers multimodal and physical AI

Overview
FiftyOne Overview
Get full visibility into your data
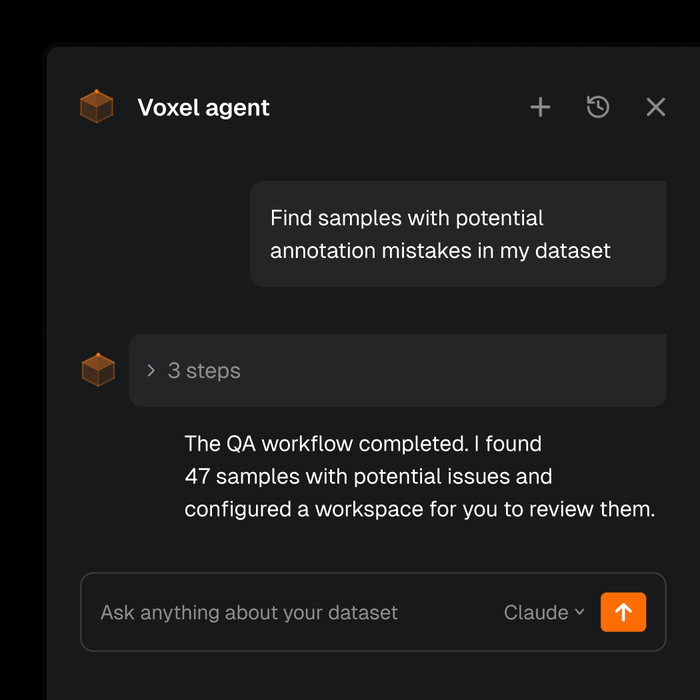
Label the right data and QA more efficiently
- Streamline your annotation pipeline with Intelligent Review and VLM-powered Agentic Labeling
- Curate high-value samples that are most likely to improve your model
- Deliver projects to spec with project management, workforce routing, schemas, ontologies, and more.
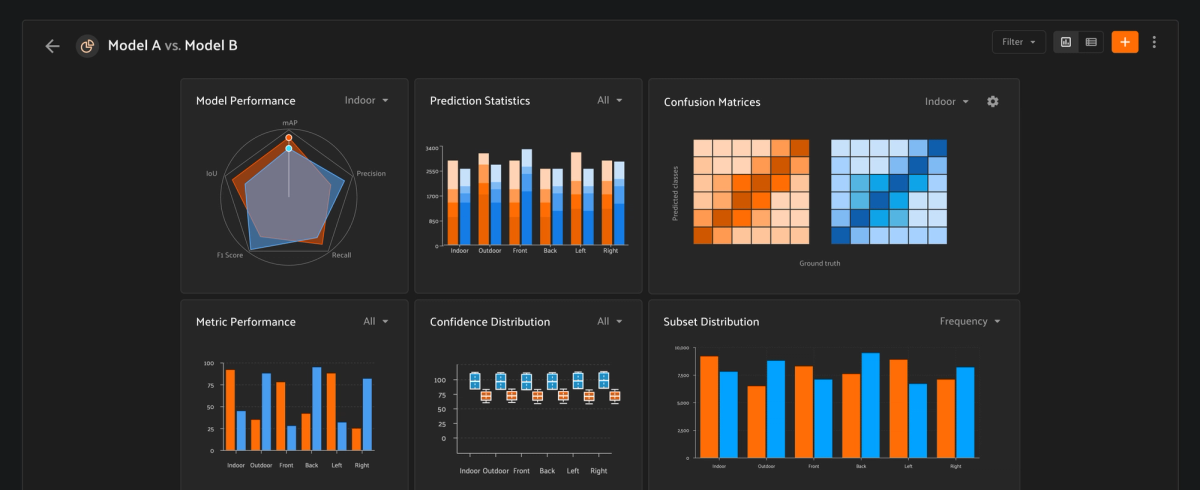
Pinpoint exactly why your models fail
Multiply the value of every scene you capture













Multimodal
Get native support for multimodal time-series data
Workflows
FiftyOne Platform
customers
Loved by developers
“FiftyOne is our primary resource for machine learning research. Thanks to FiftyOne's convenient field visualizations and filtering capabilities, we can easily distinguish incorrect labels and predictions, and therefore iterate on models faster than ever. As a result, we've achieved a 77% reduction in images sent for manual verification.”
Ryan SzetoSenior Computer Vision Engineer at SafelyYou
“As we developed our Florence-2 model, FiftyOne proved invaluable for data management and visualization. Its powerful capabilities helped streamline our workflow, ensuring we built a robust foundation for our models. Now, as we dive into the development of Florence-5B, we're relying on FiftyOne more than ever. The tool's intuitive interface and rich feature set are essential for effectively managing our large datasets and gaining critical insights.”
Bin XiaoAI Researcher, Meta (formerly Principal Research Manager, Microsoft GenAI)
“FiftyOne has helped us speed up investigations by 3x. For example, if we see a wrong suction cup grasping an item, we can quickly visualize the issue across all data sources and identify what went wrong.”
Dimitry PechyoniSenior Principal Machine Learning Engineer at Berkshire Grey
"FiftyOne enables researchers to analyze and improve the quality of their datasets rapidly, replacing the weeks of manual labor that would otherwise be required without this technology. High-quality data is critical to the success of machine learning systems. Without the right tools to analyze and curate datasets, machine learning development can be inefficient and ineffective.”
Jordi Pont-TusetResearch Scientist at Google

“At Allstate, my team works on auto vehicle damage inspection. Verifying the damage to a vehicle can take an insurance claim agent hours to verify, but using computer vision and FiftyOne, we can segment the parts of vehicles first, then detect the damages, and finally match the damage to repair costs and generate reports for the adjusters.”
Pavan NanjundappaData Science Manager, Allstate India

“We use FiftyOne to organize large research datasets. My favorite feature is the ability to view distributions over image attributes in the dataset, and filter the dataset by those attributes.”
Brett IsraelsenPrincipal Research Scientist, AI, Raytheon

“What really stands out about FiftyOne is the flexibility. The plugin framework lets us customize our workflows based on our unique needs, and the mature SDK lets us consolidate more of our pipeline into one tool, avoiding the cost of stitching together multiple systems. FiftyOne integrates directly into our production pipeline to drive 80% reductions in workplace incidents .”
Patrick RowsomeHead of Computer Vision Operations, Protex AI
COMPLIANCE & GOVERNANCE
Enterprise-grade security, scale, and extensibility

Join our AI, ML, and computer vision community

Enough data wrangling.
Request a demo.
