How Image Embeddings Transform Computer Vision Capabilities

Advances in Computer Vision (CV) have significantly transformed the way machines learn and infer complex visual data with human-like accuracy. Tasks such as image classification, object detection, and video analysis drive multiple applications ranging from detecting abnormalities in medical scans to powering self-driving car features. Innovative techniques such as embeddings help machine learning engineers simplify their data analysis by being able to generate image embeddings that extract relevant and meaningful information from their data.
Several approaches have been developed in the field to analyze and interpret visual data. Classical approaches rely on hand-crafted features and algorithms such as edge and contour detection to extract and interpret visual information from images or video. However, these approaches are limited in capabilities since they are unable to generalize unseen data. These techniques are also highly sensitive to variability in light, orientation, and are quite noisy – making them inefficient for complex recognition scenarios. In contrast, deep learning-based approaches to analyzing visual data are better able to generalize to a variety of complex use cases and environments as the features with this approach are learned and not hand-crafted. Image embeddings are a popular deep learning-based approach and a powerful alternative to traditional or classical CV methods. The embedding approach extracts essential features from input data, enabling models to better understand, categorize, and retrieve images accurately and efficiently.
In this article, we’ll dive deeper into the topic of embeddings. We’ll cover guidelines and best practices for generating embeddings and discuss typical ML workflow examples that can greatly benefit from using embeddings during data and model analysis.
What are image embeddings?
Image embeddings are compact, numerical representations that encode essential visual features and patterns in a lower-dimensional vector space. Unlike raw pixel data which primarily provides color and intensity information of the pixels, embeddings capture more abstract and meaningful attributes, such as the shape of the object, orientation, and overall semantic context.
Embeddings are typically generated by computer vision models (such as CLIP or transformer-based models) which process the image through multiple layers to identify patterns and relationships within the data. Over the last decade, machine learning has further advanced the use of embeddings to capture spatial relationships and contextual information. Transferring the information of the image into an embedding makes it easy to analyze and understand patterns in data, e.g. visualizing data clusters to identify relationships or using it for image retrieval and to locate areas of poor model performance.
How to compute embeddings
There are several methods for generating lower-dimensional representations of visual data. Some examples of such methods are:
- Using pre-trained models such as a ViT (Vision Transformer) or CLIP (Contrastive Language-Image Pretraining) which are trained on large datasets that enable them to recognize complex patterns and structures.
- Fine-tuning a large vision model on a specific task so the embeddings extracted are better descriptive for a specific task or dataset.
- Training an autoencoder to learn a lower dimensional representation of your data. This is useful when your data belongs to a specific domain and you don’t need the complex features learned by a pre-trained vision model.
- Using dimensionality reduction techniques like UMAP or t-SNE on less complex images to generate embeddings.
The method used often depends on the complexity of the domain and the variation in the source data. Once embeddings are generated, they can be consumed by visualization tools to further analyze the relationship between samples.
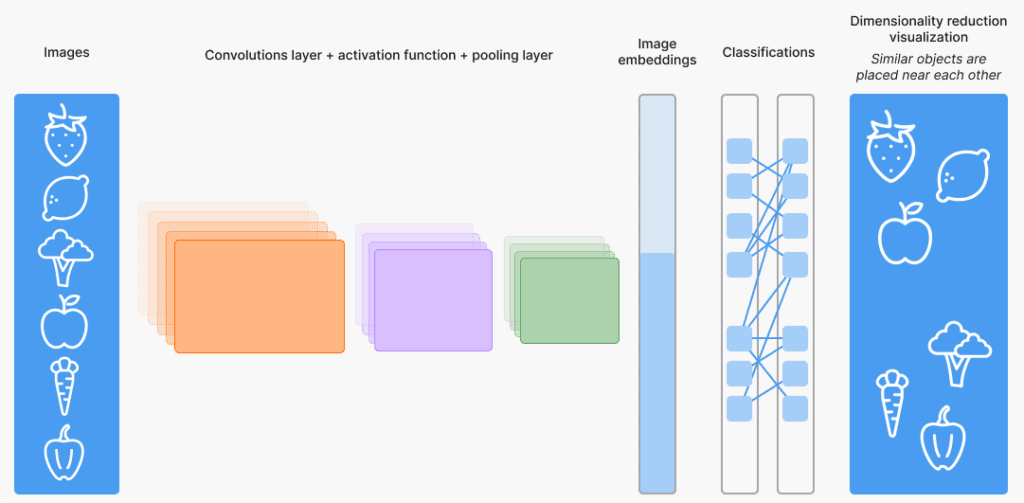
Three powerful embeddings use cases in ML workflows
Embeddings can be used in various ways to gain a deep understanding of your data and model performance. We’ll go over some typical use cases with examples. These use cases are tool-agnostic. However, here we showcase them using FiftyOne – a powerful tool that helps AI builders develop high-performing models by providing data insights at every phase of the ML workflow, from data exploration and analysis to model evaluation and testing.
Using embeddings to understand structure in raw data
Embeddings can reveal the underlying structure of the data by capturing hidden relationships and distributions in the original data. You can visualize embeddings by plotting the data in 2D space to better understand patterns in the data. This can be achieved by running dimensionality reduction methods like UMAP or PCA on your data to transform it into 2D or 3D space. You can also understand if the data naturally forms any particular clusters and what information those clusters convey.
Let’s take a look at the CIFAR-10 dataset. This open dataset contains about 60K images spread across various categories. Visualizing embeddings on the dataset reveals several distinct distributions. After further drill-down into a few clusters, you’ll notice that every cluster is somewhat of a distinct category: images of ships, automobiles, trucks, horses, etc. This type of analysis can provide a first level of understanding of your image data.
Visualizing image embeddings to understand clusters of images
For unlabelled data, natural clustering is also used for pre-annotation and tagging workflows; where images are classified and categorized by certain attributes before they are queued up for annotation. For example, we can select the leftmost cluster. These images aren’t labeled but through visual inspection, we can see that this cluster contains car images. Now we can batch-select these images, tag them as “modern cars”, and queue them for annotation. This type of workflow significantly speeds up annotation as the tags already indicate the ground truth labels for human annotators and they can instead focus their time on drawing bounding boxes for those objects.
Interested in learning more about image clustering? Check out this tutorial that teaches you how to cluster images using scikit-learn and feature embeddings.
Using embeddings to QA annotation quality
Embeddings can be used to find annotation errors in your dataset. By coloring embedding vectors by fields, you can easily check if the samples match the clustering intuition and identify samples that could be incorrectly labeled.
Let’s take a look at the Berkeley Driving Dataset (BDD100) – a large-scale diverse driving dataset that contains annotated data of multiple cities, weather conditions, times of day, and scene types. Coloring embeddings by timeofday.label you can see two distinct clusters. A quick visualization of them tells you that the right side cluster is “daytime” images and the left side is “nighttime” images, with dawn/dusk samples scattered over the 2 sides.
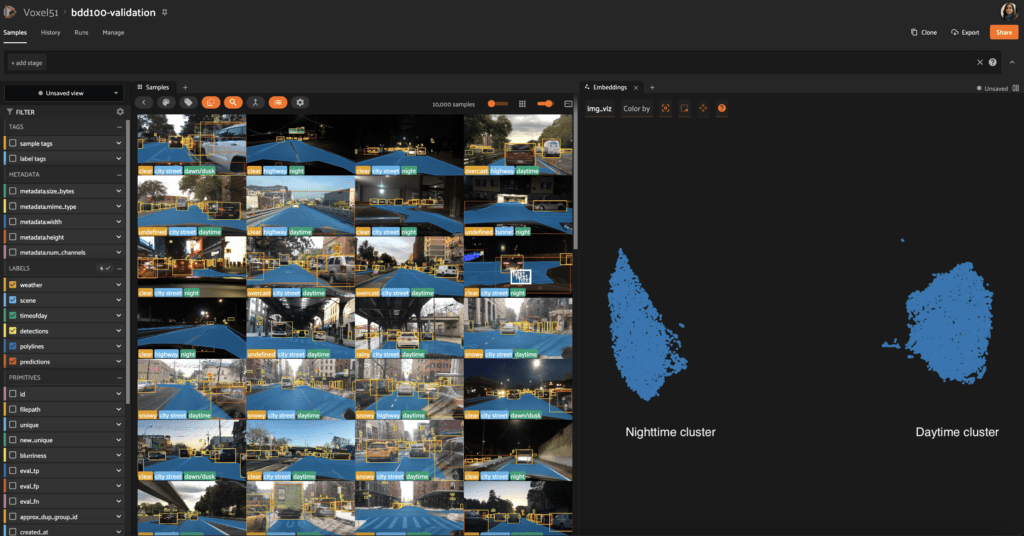
After closer observation, you might notice that certain “green” night samples appear in the daytime cluster on the right. By visualizing these specific night samples, we can see that they are images taken during the day. The ground_truth does not match what the model predicted, indicating that the model is accurate, but the samples have a labeling issue and are incorrectly classified. Through this process, labeling issues can be easily identified and corrected.
Coloring image embeddings by "time of day" to identify mislabeled images

Using embeddings to find similar samples
Another interesting scenario where embeddings play a role is to find similar or unique objects from your dataset. This type of workflow is particularly useful for cases where you want to get an understanding of a certain category of images to possibly augment your dataset with more of those similar image types (perhaps with variations) for improving model performance. For example, if you are building an e-commerce visual recommendation system, you’ll need to see if your models contain enough images of the product photographed under different conditions (angles, backgrounds, lighting) so it can do a good job of generalizing and identifying true visual similarities.
Similarity searches by text or images use embeddings to find and display the appropriate images. Text and image embeddings can be used to identify relevant images because visually or semantically similar objects are mapped closer to each other in the 2D space.
Let’s take a look at a dataset that has random images of people, animals, transportation, food, and other categories. Let’s select the image of an airplane and then find similar samples. You can do this by sorting samples by similarity to visualize all images in your dataset that look like airplanes.
Similarity search uses embeddings to find samples that are mapped closer to each other
Another way to look for similar samples is to use natural language prompts so you can “talk to your data”. Here we are trying to find samples of “pedestrians using a crosswalk”. A quick similarity image search yields the corresponding samples that closely relate to that prompt.
Similarity query using natural language prompts
Summary: Embedding use cases
As we saw from the use cases, embeddings are transformative techniques that enable a deeper understanding of the underlying data through clustering and visualization. They reveal hidden structures in raw data, help identify patterns, speed up annotation QA workflows, and aid in finding visually or semantically related samples to enhance the diversity of the dataset and improve model performance.
The future of image embeddings
The growing use and specialization of embeddings are driving the development of accurate, reliable, and robust datasets and models.
Embeddings for generative tasks
A popular area of active innovation is the accurate representation of text-to-image conversion. Over the last few years, we’ve seen significant progress with models like DALL-E and CLIP that generate images from textual descriptions by learning joint embeddings of text and images. Such models enable the generation of textual context-aware embeddings and enable workflows like text similarity search. Advances in these techniques will further improve the accuracy of text-to-image conversion, create realistic AI-generated art, and perhaps even greatly assist with the scary side of deepfakes where images and videos are manipulated by encoding facial features into embeddings and reconstructing them onto other faces.
Efficient and lightweight embedding models
There is also considerable innovation (here and here) in smaller, faster models (e.g. MobileNet) that generate embeddings for use in real-time applications such as edge computing and mobile devices to improve the performance of ML systems, particularly in resource-constrained environments.
How to use embedding capabilities in FiftyOne
FiftyOne, from Voxel51, is a solution designed to make it easy for AI builders to develop high-quality data and robust models by providing data insights through every critical phase of the ML workflow. FiftyOne simplifies the computation, visualization, and application of image embeddings, making it easier for AI builders and organizations to unlock the full potential of their visual data.
The image embedding capabilities in FiftyOne analyze datasets in a low-dimensional space to reveal interesting patterns and clusters that can answer important questions about your dataset and model performance. Manual solutions to compute, visualize, and use embeddings in workflows can be time-consuming and harder to scale. FiftyOne supports out-of-the-box advanced techniques (powered by FiftyOne Brain) that make it easy to compute and visualize embeddings. By incorporating embedding-based workflows into the ML pipeline, FiftyOne equips teams with the data-centric capabilities they need to get the data insights for developing robust models.
Here are some resources that can help you start using embeddings in your workflow
- Tutorial on How to use embeddings in FiftyOne; follow along using this Google Colab notebook.
- Blog post: Visualizing data with dimensionality reduction techniques
- Practical pointers for using embeddings with these tips-and-tricks
Conclusion
Image embeddings have transformed how ML engineers analyze data to solve complex visual tasks, from object detection to anomaly detection and beyond. ML workflows can greatly benefit from using embeddings to improve the efficiency and reliability of processing and analyzing large datasets and visual AI models.
Next steps
Building visual AI successfully is possible with the right solution. Refer to FiftyOne docs on how to get started.
Looking for a scalable solution for your visual AI projects? Check out FiftyOne Teams and connect with an expert to see it in action.

