Welcome to our weekly FiftyOne tips and tricks blog where we give practical pointers for using FiftyOne on topics inspired by discussions in the open source community. This week we’ll cover embeddings.
Wait, What’s FiftyOne?
FiftyOne is an open source machine learning toolset that enables data science teams to improve the performance of their computer vision models by helping them curate high quality datasets, evaluate models, find mistakes, visualize embeddings, and get to production faster.

- If you like what you see on GitHub, give the project a star.
- Get started! We’ve made it easy to get up and running in a few minutes.
- Join the FiftyOne Slack community, we’re always happy to help.
Ok, let’s dive into this week’s tips and tricks!
A primer on embeddings
In computer vision, embeddings are used to represent visual features of images or videos as numerical vectors. These vectors, which are typically lower in dimension than the raw source media, capture underlying characteristics of the visual data and can be used for downstream tasks such as image classification, object detection, and image retrieval.
In FiftyOne, embeddings are managed by the FiftyOne Brain, a library that provides powerful machine learning techniques designed to transform how you curate your data from an art into a measurable science. Using embeddings makes it easy to analyze and visualize datasets, and accelerates your ML workflows.
Continue reading for some tips and tricks to help you master embeddings in FiftyOne!
Compute sample properties (uniqueness, similarity, and more) from embeddings
If you want to harness the power of embeddings in computer vision but aren’t sure where to start, FiftyOne has you covered. Any FiftyOne Brain method that utilizes embeddings is equipped with a default general purpose embedding model.
This means that in many cases you can use Brain methods out of the box to assess properties of the samples in your dataset.
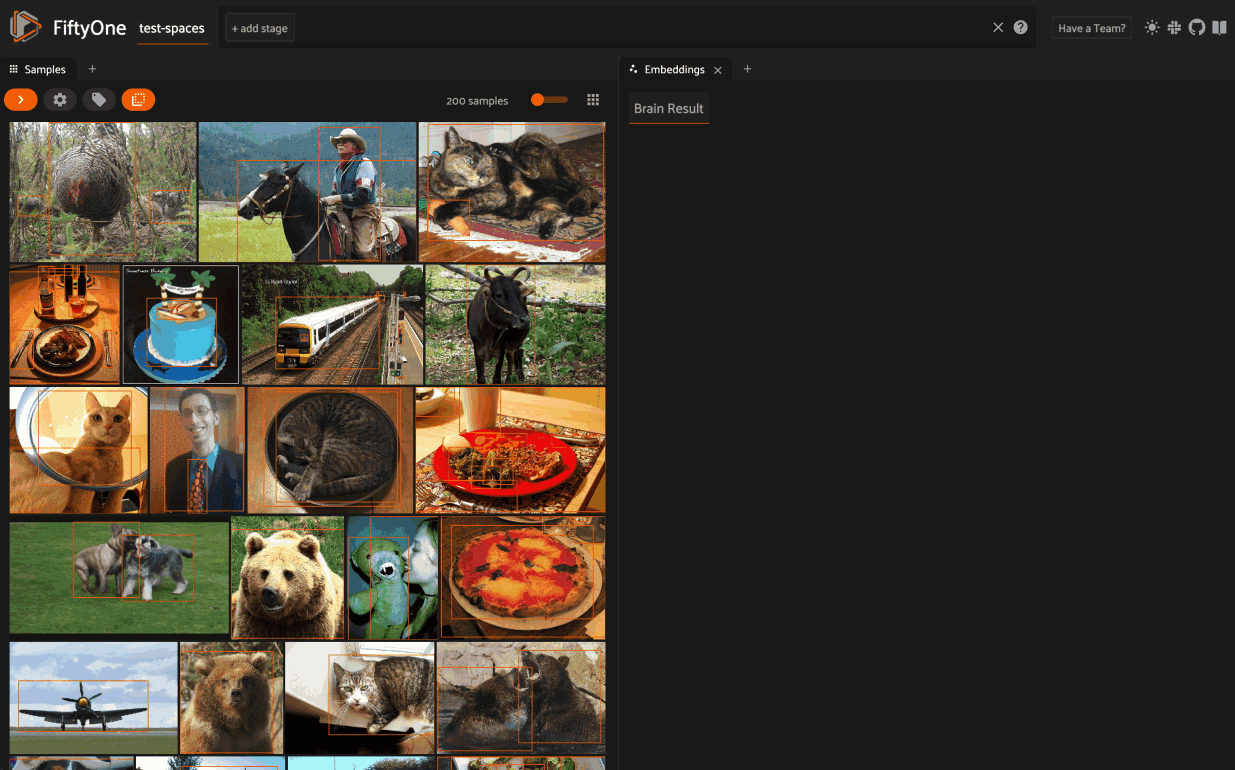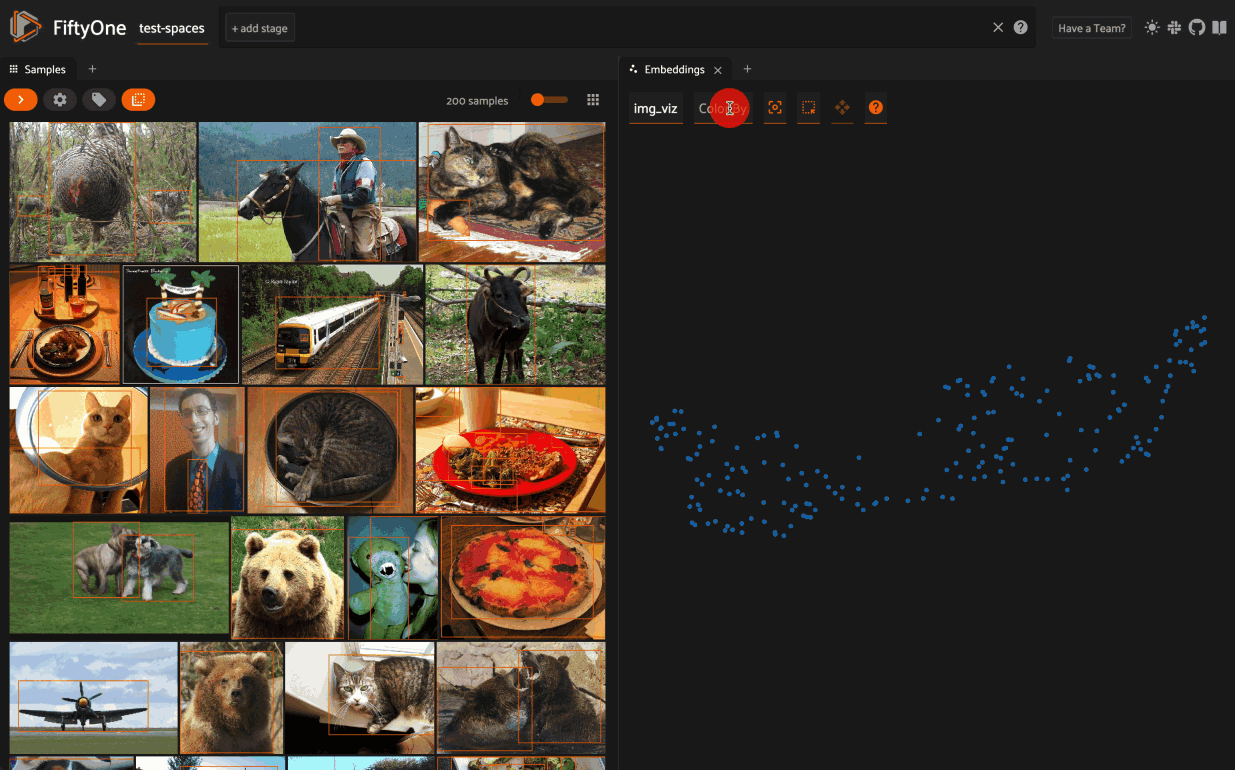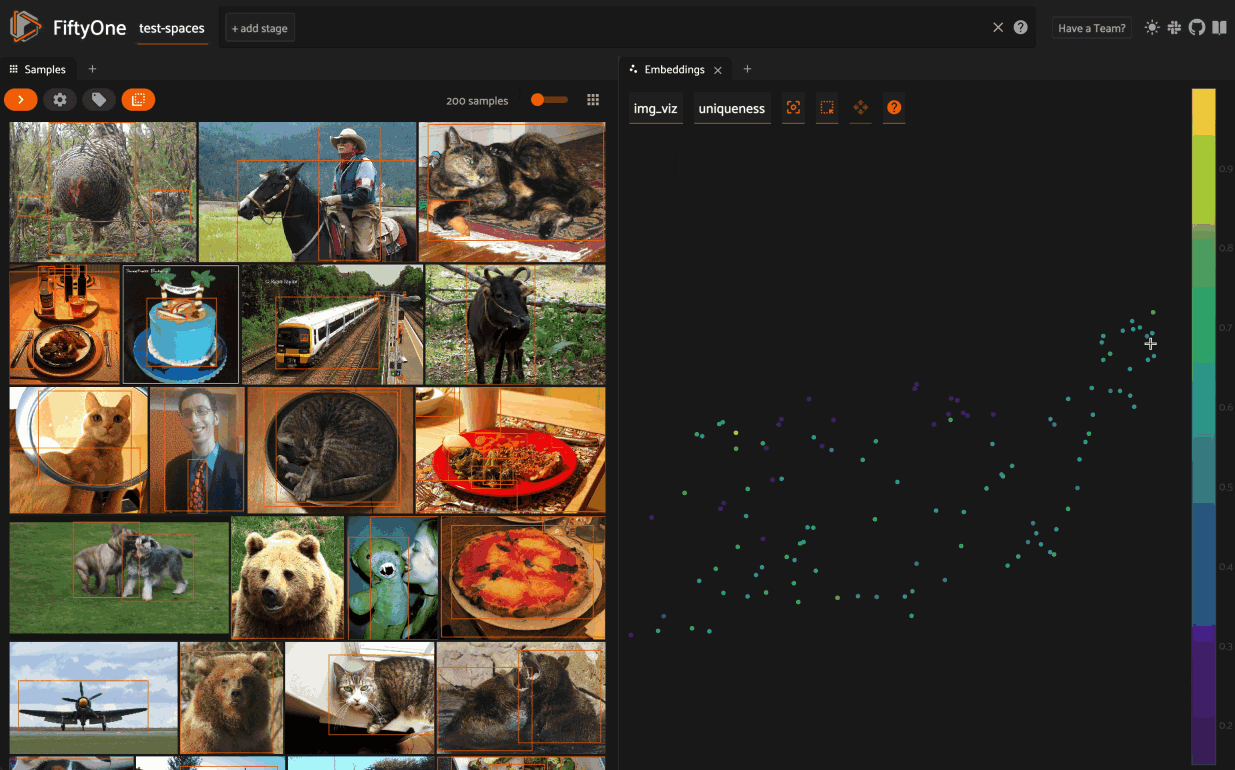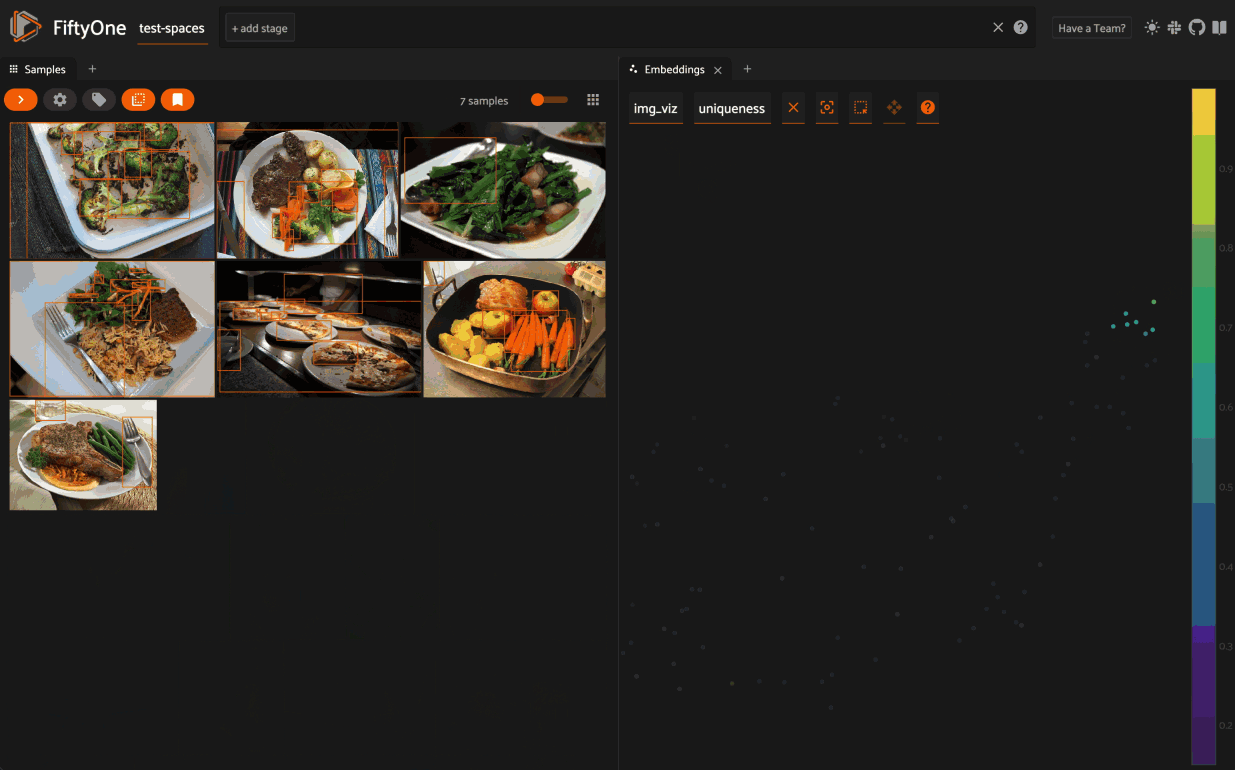
For instance, when training a model, unique samples will help your model to understand and represent distributions in your dataset. To aid in this process, the FiftyOne Brain provides a method to compute the “uniqueness” of images, helping you to answer questions such as “What data should I select to annotate?”. Here’s how easy it is to compute the uniqueness of images in the quickstart dataset:
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
# load in dataset
dataset = foz.load_zoo_dataset("quickstart")
fob.compute_uniqueness(dataset)
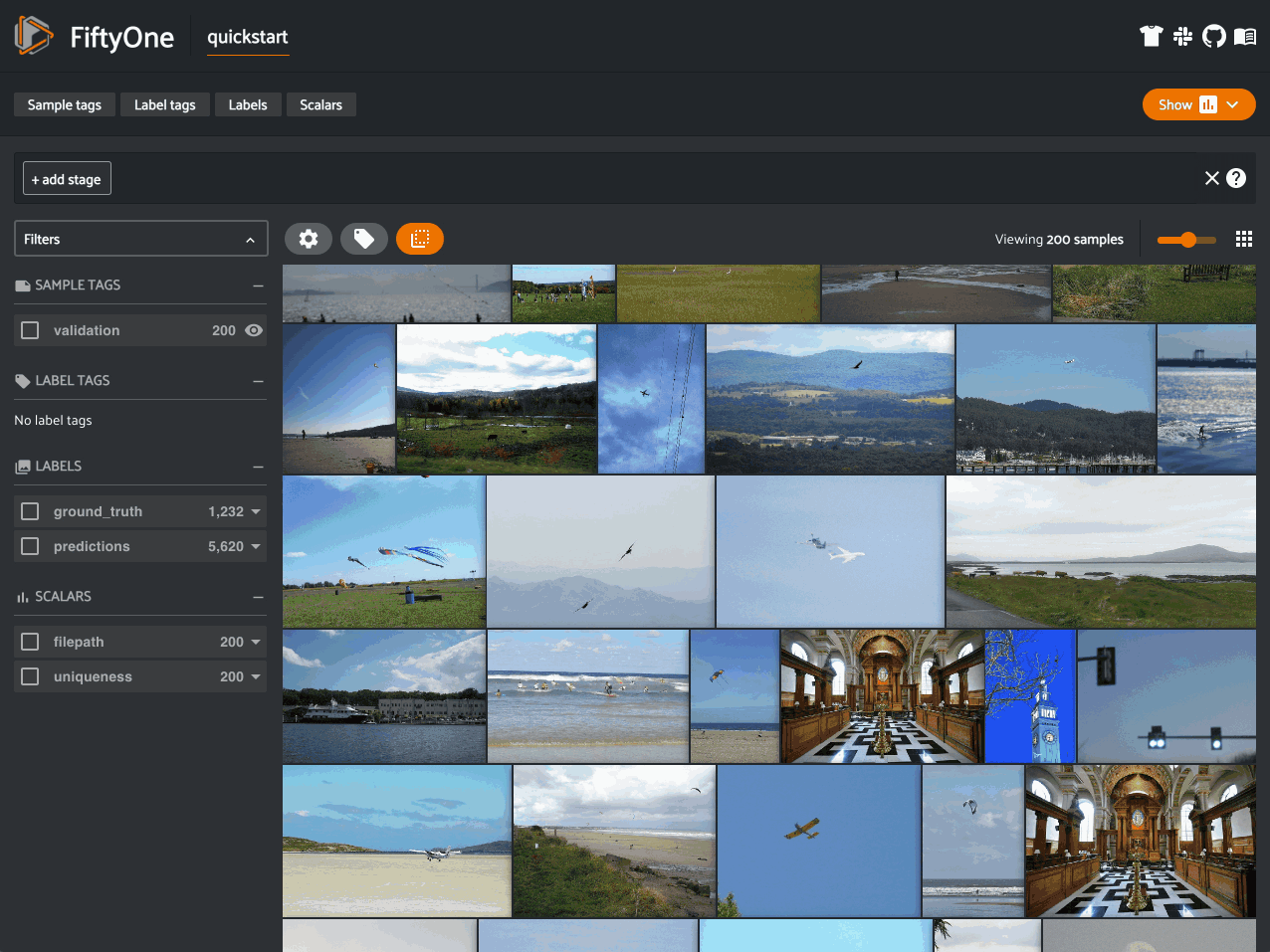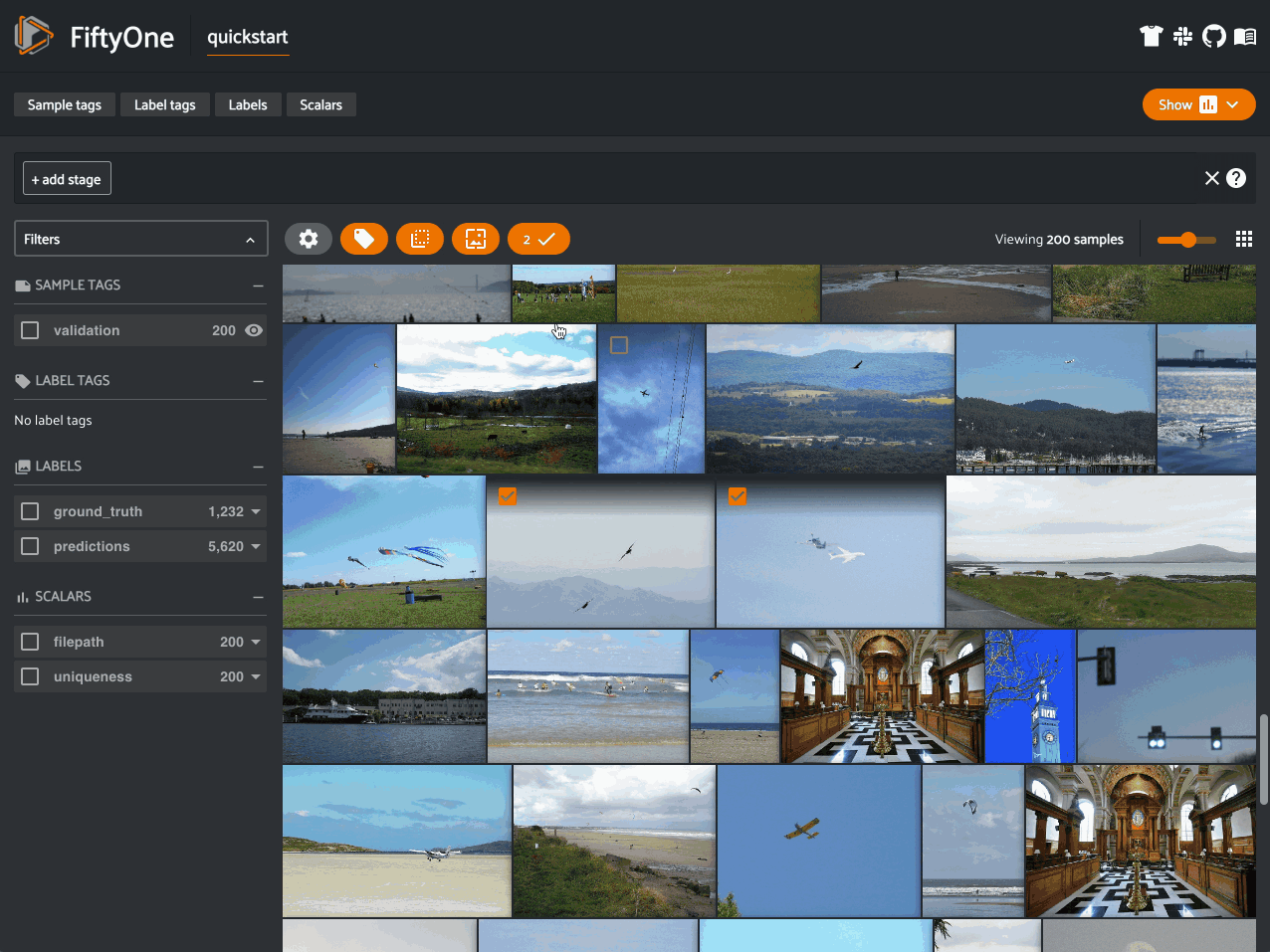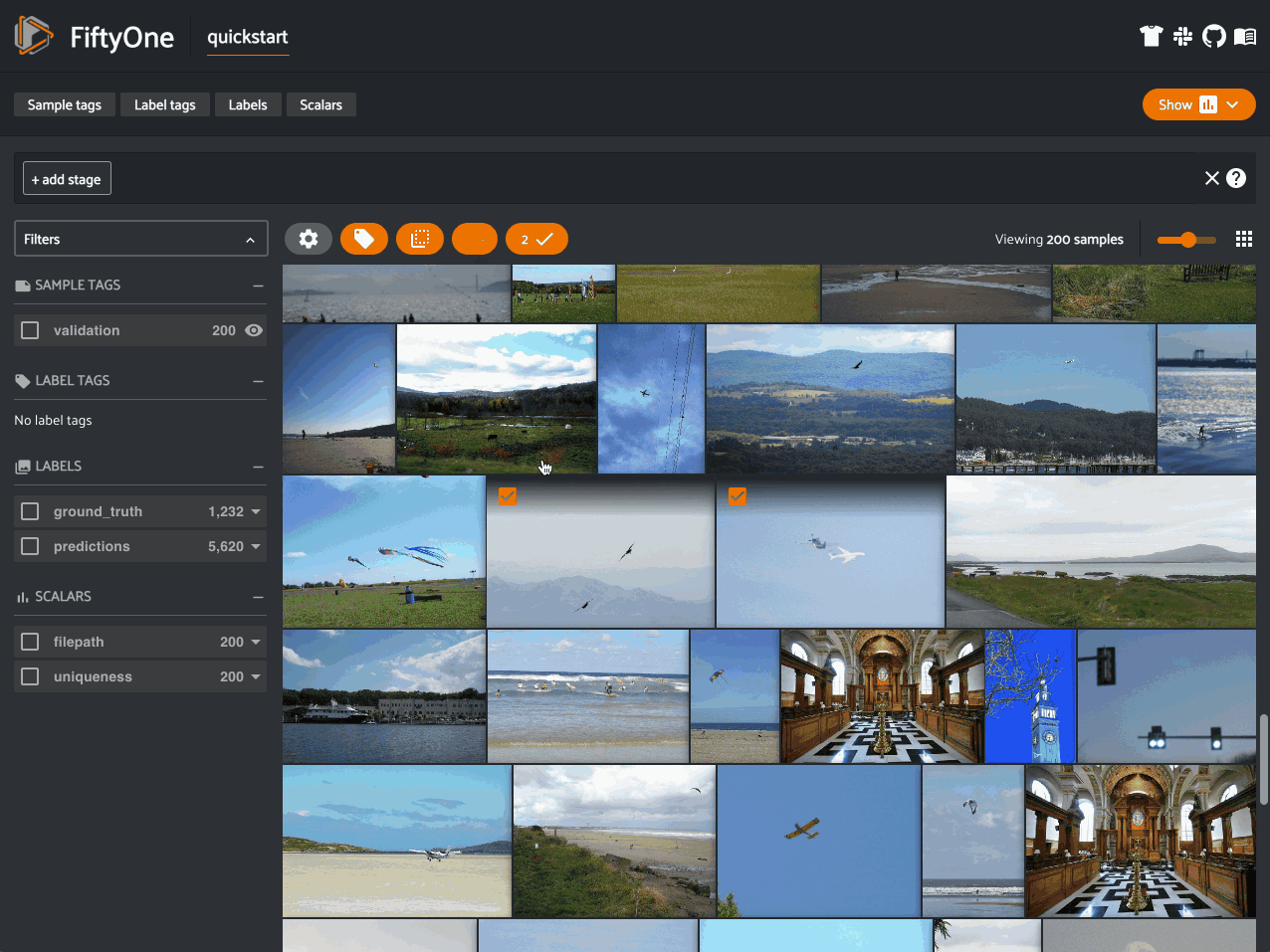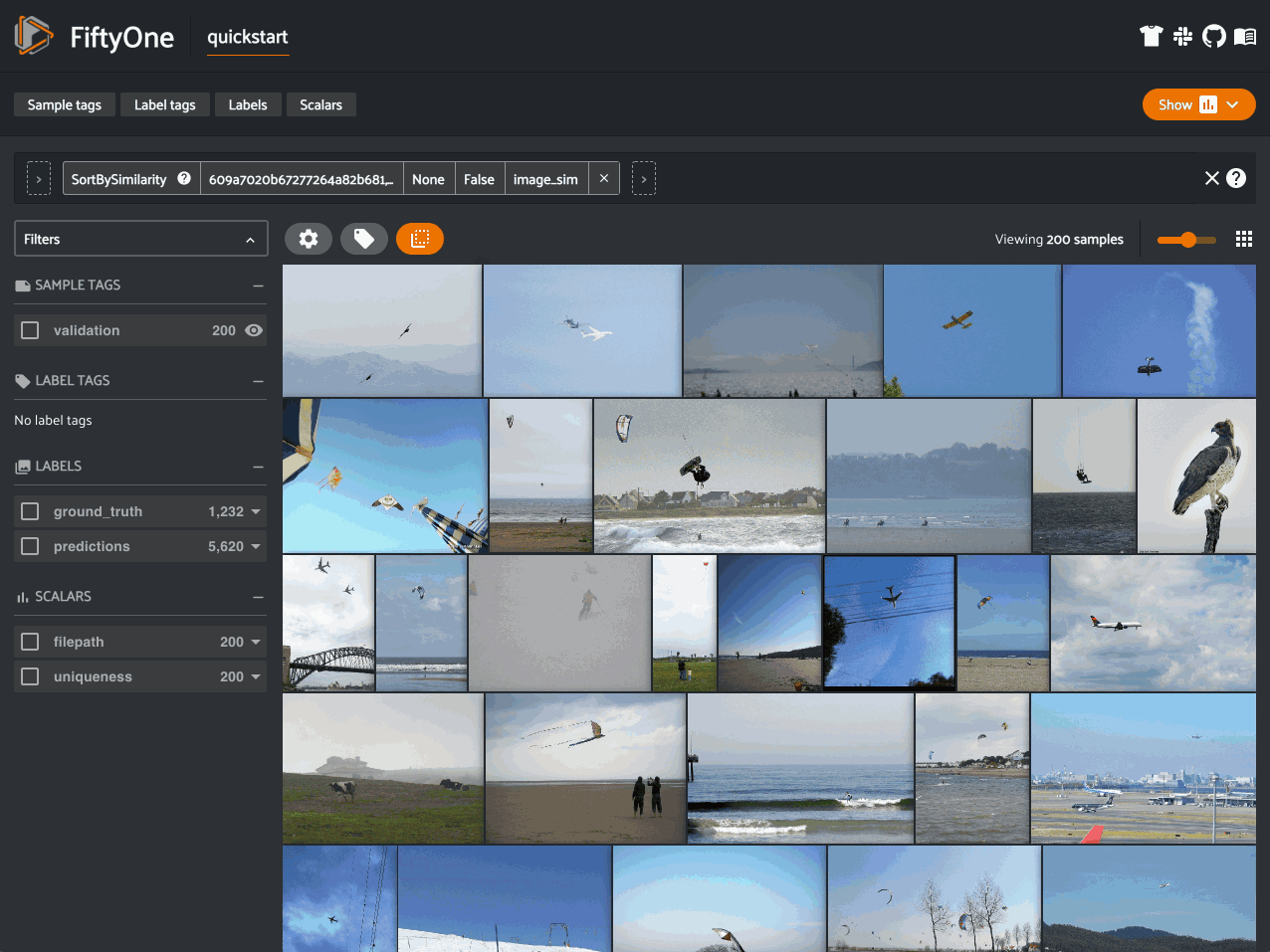
In a similar vein, when constructing a dataset or training a model, have you ever wanted to find similar examples to an image or object of interest? The FiftyOne Brain makes computing visual similarity easy, too. You can compute the similarity of samples in your dataset using the default (MobileNetv2) embedding model and store the results in the brain key image_sim:
fob.compute_similarity(dataset, brain_key="image_sim")
You can then sort your samples by similarity or use this information to find potential duplicate images.
Learn more about the FiftyOne Brain’s similarity interface, as well as other brain methods, such as sample hardness and mistakeness, in the FiftyOne Docs.
Visualize embeddings
Another application of embeddings in computer vision is visualization. By pairing embeddings with a dimensionality reduction technique such as uMAP or tSNE, you can plot your data in a low dimensional space, allowing you to identify clusters and better understand the patterns in your data.
In FiftyOne, all of the logic of combining embeddings, dimensionality reduction techniques, and plotting are wrapped in the easy to use interface of the FiftyOne Brain’s compute_visualization() method.
If we want to generate default embeddings for the Quickstart dataset and use them to visualize our dataset, employing uMAP to reduce the dimensionality of the embedding vector down to two dimensions, we can run:
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
# Image embeddings
fob.compute_visualization(dataset, brain_key="img_viz")
# Object patch embeddings
fob.compute_visualization(
dataset, patches_field="ground_truth", brain_key="gt_viz"
)
session = fo.launch_app(dataset)
Then we can visualize these results, coloring by label:
Learn more about the Embeddings Panel in the FiftyOne Docs.
Use your own embedding model
If you’re working with more specialized or application-specific computer vision data, it might be beneficial to use your own, custom model to generate embeddings. Fortunately, all of the Brain methods that utilize embeddings, from compute_uniqueness() and compute_similarity() to compute_visualization() support this!
Any FiftyOne Brain method that works with embeddings allows you to specify your own embeddings in three ways.
The first two ways involve the optional embeddings argument, which is useful if you have already precomputed your embeddings. You can either give the precomputed embeddings explicitly as input in the form of an num_samples x num_embedding_dims array, or you can pass in the name of a field in the dataset containing the embeddings:
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
# The BDD dataset must be manually downloaded. See the zoo docs for details
source_dir = "/path/to/dir-with-bdd100k-files"
# Load dataset
dataset = foz.load_zoo_dataset(
"bdd100k", split="validation", source_dir=source_dir,
)
# Compute embeddings
# You will likely want to run this on a machine with GPU, as this requires
# running inference on 10,000 images
model = foz.load_zoo_model("mobilenet-v2-imagenet-torch")
# option 1
embeddings = dataset.compute_embeddings(model)
results = fob.compute_visualization(dataset, embeddings=embeddings)
# option 2
embeddings = dataset.compute_embeddings(model, embeddings_field = “my_embeddings”)
results = fob.compute_visualization(dataset, embeddings=”my_embeddings”)
As an alternative, if you have not yet computed your embeddings, you can pass in a model for FiftyOne to use to compute the embeddings:
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
# The BDD dataset must be manually downloaded. See the zoo docs for details
source_dir = "/path/to/dir-with-bdd100k-files"
# Load dataset
dataset = foz.load_zoo_dataset(
"bdd100k", split="validation", source_dir=source_dir,
)
# Compute embeddings
# You will likely want to run this on a machine with GPU, as this requires
# running inference on 10,000 images
model = foz.load_zoo_model("mobilenet-v2-imagenet-torch")
# option 3
results = fob.compute_visualization(dataset, model = model)
Any model that has logits should work, and you can check if the model supports embeddings by verifying that print(model.has_embeddings) returns True.
Learn more about the FiftyOne Model Zoo in the FiftyOne Docs.
Compute embeddings for object patches
Just as you can compute embeddings for images, FiftyOne allows you to compute embeddings for object patches, with the built-in method compute_patch_embeddings() functioning in analogous fashion to compute_embeddings(). To compute embeddings for ground truth objects, we just use ”ground_truth” as the patches field:
import fiftyone as fo
import fiftyone.zoo as foz
# Load zoo model
model = foz.load_zoo_model("inception-v3-imagenet-torch")
print(model.has_embeddings) # True
# Load zoo dataset
dataset = foz.load_zoo_dataset("quickstart")
dataset.compute_patch_embeddings(model, "ground_truth", embeddings_field = "gt_embed")
Alternatively, Brain methods like compute_similarity() and compute_visualization() work natively with patches when you specify the patches_field argument, telling the Brain which labels to use:
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
# Load zoo model
model = foz.load_zoo_model("inception-v3-imagenet-torch")
print(model.has_embeddings) # True
# Load zoo dataset
dataset = foz.load_zoo_dataset("quickstart")
# compute similarity of ground truth patches
fob.compute_similarity(dataset, patches_field = "ground_truth")
Learn more about object patches and computing embeddings for object patches in the FiftyOne Docs.
Perform zero-shot classification with CLIP
Over the past few years, progress in embeddings has enabled a suite of new applications and use cases in computer vision. One of the most significant advances in this area has been the development and honing of techniques which embed multimodal data into a common embedding space.
In particular, with OpenAI’s CLIP model pioneering contrastive language-image pre-training, it is possible to transfer knowledge from one domain to another. This paved the way for dramatically improved zero-shot computer vision models.
The PyTorch implementation of the CLIP Vision Transformer model in FiftyOne’s Model Zoo makes it easy to leverage CLIP’s multi-modal embeddings to classify images into novel categories.
Here’s an example of performing zero-shot classification on COCO validation data with custom class labels:
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset(
"coco-2017",
split="validation",
dataset_name=fo.get_default_dataset_name(),
max_samples=50,
shuffle=True,
)
model = foz.load_zoo_model("clip-vit-base32-torch")
dataset.apply_model(model, label_field="predictions")
session = fo.launch_app(dataset)
# Make zero-shot predictions with custom classes
model = foz.load_zoo_model(
"clip-vit-base32-torch",
text_prompt="A photo of a",
classes=["person", "dog", "cat", "bird", "car", "tree", "chair"],
)
dataset.apply_model(model, label_field="predictions")
session.refresh()
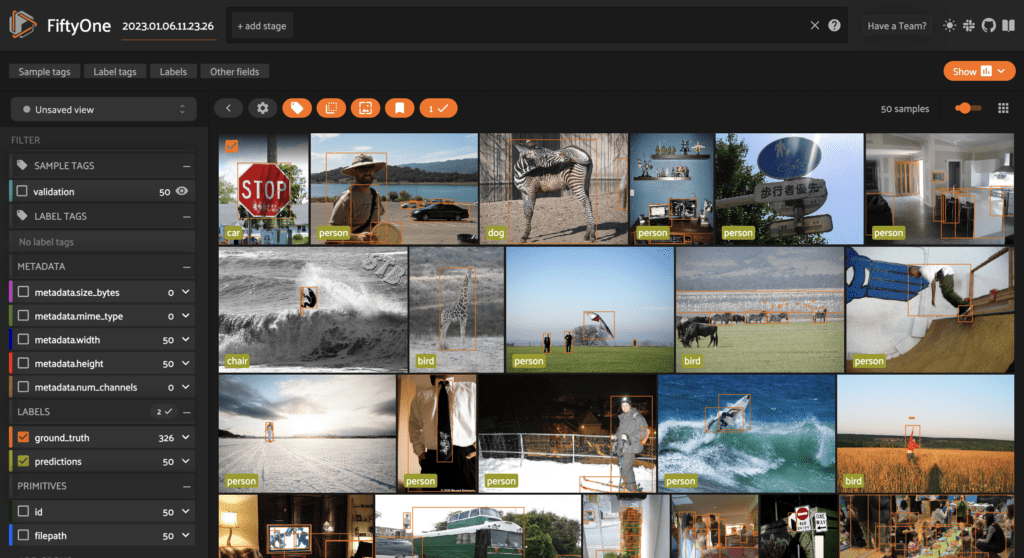
Learn more about apply_model() and understanding your computer vision data with a CLIP model in the FiftyOne Docs.
Join the FiftyOne community!
Join the thousands of engineers and data scientists already using FiftyOne to solve some of the most challenging problems in computer vision today!
- 1,475+ FiftyOne Slack members
- 2,700+ stars on GitHub
- 3,600+ Meetup members
- Used by 266+ repositories
- 58+ contributors

