We recently released FiftyOne 0.18 with a lot of exciting new features to make it easier than ever to build high quality computer vision datasets and machine learning models!
Voxel51 Co-Founder and CTO Brian Moore walked us through all the new features in a live webinar, with plenty of live demos and code examples to show it in action. You can watch the playback on YouTube, take a look at the slides, see the full transcript, and read the recap below for the highlights. Enjoy!
Donating $200 to World Literacy Foundation
In lieu of swag, we gave attendees the opportunity to vote for their favorite charity and help guide our monthly donation to charitable causes. The charity that received the highest number of votes for the third time in a row was the World Literacy Foundation. We are pleased to be making another donation of $200 (totaling now $600 across three events!) to this wonderful organization on behalf of the FiftyOne community.
Presentation Highlights
Why FiftyOne and Voxel51?
So much data; so little time. Brian says “visual data contains a lot of information. But if you don’t actually pull up those samples, look at them, and understand the data you have, the annotations that you’re generating, and the model predictions that you’re getting, you won’t really understand the performance of your model.” While you might think the large majority of time data scientists and ML engineers spend developing a computer vision model is centered around the model itself, it’s not; instead, it’s spent on wrangling data. And, as Brian adds, “as datasets continue to increase in size, that proportion is only going to increase.”
Data quality matters. It’s no secret that low quality data leads to problems such as model bias, physical danger, and reduced model performance. Brian notes “if you train on incorrect data, your model will learn incorrect things.”
So the goal is to efficiently improve the quality of your datasets. The key to doing so is to get hands-on with your data to achieve high quality datasets on which to train your models. That’s why FiftyOne and our company Voxel51 exist! We’re focused on improving the transparency and clarity of your data, helping you understand what’s in your data, and how you can improve the quality of your datasets.
What is FiftyOne?
The open source FiftyOne project is designed to be the computer vision tool that brings together your data-centric tasks and your model-centric tasks. Data-centric tasks include the way you get your data annotated, and the way you find and store your data; model-centric tasks include the way you train your models, the frameworks you use, and the tools you use to track your experiments. FiftyOne joins those two worlds and helps you iterate on datasets and models together.
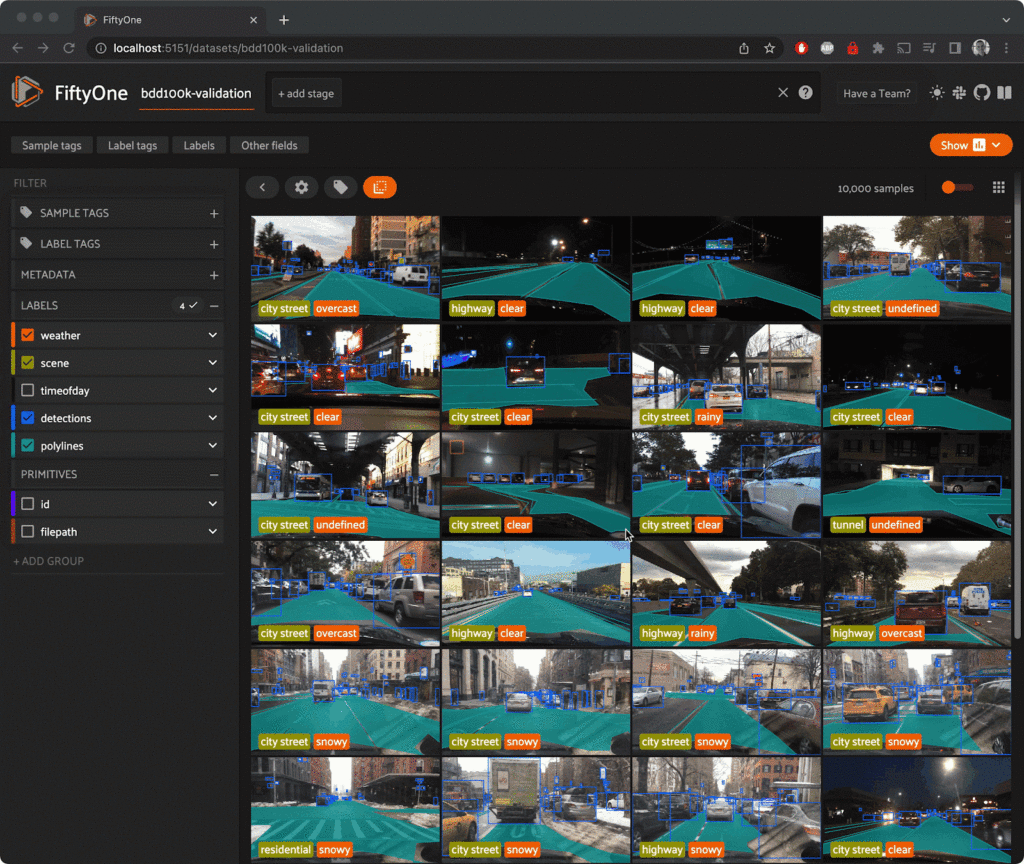
FiftyOne is meant for all things computer vision and supports tasks such as classification, detection, segmentation, polylines, and key points on images, video, and 3D data.
It has a very powerful API that’s designed to help you organize your data and query it. A recent blog post came out comparing the way that you can filter your data in FiftyOne to the way that you can with tabular data in pandas. Brian shares: “So one analogy to think of is that FiftyOne can be the pandas for computer vision.”

What’s new in the latest version (0.18) of FiftyOne?
We recently released FiftyOne 0.18 and there were a number of new goodies that were added based on community input, including:
- 1 — Significant performance improvements to the FiftyOne App
- 2 — New sidebar modes to further optimize user experience for large datasets
- 3 — The ability to programmatically modify your dataset’s sidebar groups
- 4 — The ability to declare and filter by custom label attributes
- 5 — Support for storing and viewing field metadata in the App
- 6 — A new light mode option
Brian did a show and tell of each, and why they matter. In the rest of this post, we’ll briefly explore the awesomeness of each one.
1 — App Performance Improvements
It is of utmost importance for us to make FiftyOne as fast as possible and for as large of datasets as possible. With that in mind, FiftyOne 0.18 brings significant improvements in performance to the FiftyOne App.
In the presentation, Brian compares a search across 180,000 objects in FiftyOne 0.17 vs the same search happening in 0.18 and sees a 10x improvement in the App! Underlying these performance wins are the new sidebar modes that substantially decrease the amount of load on the database enabling the system to load far faster. We cover the new sidebar modes in the next section. But even without making use of the new sidebar modes (aka using the classic “All” mode, which was previously the only mode), performance overall is still significantly faster, so there are performance enhancements across the board.
Brian shows this in a .gif in the webinar playback starting at 7:47–8:35.
2 — App Sidebar Modes
With FiftyOne 0.18, the App sidebar now has three different modes of operation — All, Fast, and Best. These modes control how many statistics are computed in the sidebar when you update your dataset or update the current dataset view. For smaller datasets, the default is All. However, if you have a very large dataset, FiftyOne will automatically default to Fast mode, where all of the statistics will not be computed by default, but rather they will compute when you expand the filter tray for one of those attributes.
Why is this awesome? Choosing the right mode for the dataset makes the App experience much faster because now it’s only computing what you ask it to, which means you can get ahold of the underlying data and start looking at it in the App grid much faster.
The best news (no pun intended)? You don’t have to change anything about your existing datasets, they will default to Best mode when you upgrade, which chooses the appropriate mode for your dataset based on its size, the type of media, and other criteria.
You can toggle between All and Fast on-the-fly in the App, and it’s also possible to configure the default sidebar mode on a per-dataset basis via code.
You can see all this in action from 23:51–26:39 in the webinar replay. Also visit the sidebar mode section of the docs to learn more.
3 — Custom Sidebar Groups
With the FiftyOne App, you’ve always been able to customize the groups in the sidebar, including the ability to create, rename, or delete sections and the fields they contain; drag and drop groups and fields just where you’d like them; and expand or collapse groups as you see fit. All of these options enable you to fully customize how you organize your App sidebar.
But now with FiftyOne 0.18, you have the ability to also customize all of this on a per-dataset basis via code in the dataset’s app config! After doing so, when you work with a particular dataset in the App, it will automatically load with the sidebar groups you defined. This means you can visualize what you want immediately, while also being able to customize further in the App, as usual.
In the demo, Brian shows how to add a new sidebar group called “new” and add a field to it, as well as set the metadata fields to non-expanded by default, all through code.
See the demo in the playback video from 26:39–28:22. Also learn more in the custom sidebar groups section of the docs.
4 — Custom Label Attributes
With FiftyOne, it has always been the case that, in code, you could add as many label fields to your dataset as you’d like. You could also add your own custom attributes to the labels. As an example, in a scenario with a ground truth field containing object detections, you could add a custom attribute declaring whether that object is a crowd annotation or not. Now this capability extends beyond code, enabling you to see and filter on custom label attributes in the App!
First, Brian shows code samples and describes a variety of methods to help you achieve your desired end-state from 13:18–16:24 in the presentation.
Then later in the demo, starting from 18:46–23:51 in the video replay, Brian loads up an example dataset with images of animals. The dataset has some ground truth object detections in it, with a custom attribute called “mood”. With the new features in 0.18 it’s now possible to add these dynamic attributes to the dataset schema, and then view and filter by these dynamic custom attributes in the App.
To show this with a popular open dataset, Brian then loads up COCO and shows that there are additional attributes already on the dataset, including an “iscrowd” attribute, and then shows how to use a variety of methods to find the dynamic attributes, add those to the dataset, and then filter and view samples by that attribute in the App.
Read more about custom label attributes in the docs.
5 — Storing Field Metadata
As of FiftyOne 0.18, you can now store metadata, including a description and other info such as URLs or an arbitrary mapping of keys and values on the fields of your dataset. In addition, if you save those details, you can retrieve them later through code and see them in the App via a new tooltip that appears when you hover over a field or an attribute name in the sidebar.
In the demo, Brian defines the description and info fields on a few fields in a dataset, then looks at the App to show the tooltip that exposes the metadata on hover.
See how to do this from 28:22–29:18 in the webinar playback and here in the docs on storing field metadata.
6 — Light Mode
With this release, there’s a new toggle in the upper right of the FiftyOne App to toggle between light mode and dark mode options. Try it out to determine your favorite mode, or anytime you’re feeling up for a different vibe while working in the App.
Q&A from the Webinar
There was a lively Q&A all throughout the presentation and demos! Here’s a recap:
Are you planning to have more tutorials on using FiftyOne, especially video tutorials?
You can find some tutorials in the docs, but yes, the plan is to generate more video content about how to work with image datasets, video datasets, and 3D datasets with FiftyOne. So stay tuned! We’ll be posting to our YouTube channel when they’re ready.
Where is the data stored when you’re working with FiftyOne? (Specifically, can the data storage still be on our own servers?)
Re: the specific question — yes, you can store the data locally on your own servers. With FiftyOne Teams, you can also store (and access) data in private clouds.
Re: where data is stored more broadly — open source FiftyOne is designed for a single user and local deployment. So when you import the library the first time, a mongoDB database is spun up in the background. And any metadata or samples you create, all that information is stored in the database. And then, you’re also storing pointers to the media — a path to the media, like a video, on disk. So that media lives separately from FiftyOne.
You can work with FiftyOne in all kinds of different environments. Here’s a section of the docs that includes comprehensive details for different local environments where you can use open source FiftyOne (as well as where the data is stored for each environment and how to launch the App in each type of environment):
- Local machine: Data is stored on the same computer that will be used to launch the App
- Remote machine: Data is stored on disk on a separate machine (typically a remote server) from the one that will be used to launch the App
- Notebooks: You are working from a Jupyter Notebook or a Google Colab Notebook
If you’re looking for native cloud storage support, check out FiftyOne Teams. It’s a fully backwards compatible version of FiftyOne that supports native cloud datasets, multiuser collaboration features, and much more! Learn more or reach out in the Slack community and we’d be happy to answer any questions you may have.
Are there video tensor loading capabilities in minibatches with FiftyOne?
Datasets in FiftyOne work with data loaders, such as the PyTorch DataLoader. You can definitely work in batches. When working with large datasets, for instance, sending tasks to annotation services, it is good practice to send in batches.
What would a video action recognition pipeline look like in FiftyOne?
So suppose you have a pipeline where you’re training and you want to apply inference on, whether it’s inference on images or inference on a fancier model, like a video action recognition model, FiftyOne does have a built-in capability for that. One way to do this in FiftyOne is to use a method called apply_model() which you can learn about in the docs. We’ll be adding documentation coming up soon about how you can wrap your own PyTorch model as a model instance in FiftyOne, and then just pass it to this method, along with some configuration around batch size, the number of workers for your data loader, and so on. Stay tuned for that.
Another, more standard way to do that would just be to write your own loop. FiftyOne is a way to store the model predictions and it works in concert with your existing training loops. Looking at our tutorial about Training with Detectron2 as an example, what you’ll see is that you run inference as normal and you train as normal. What you just need to do is add to your inference loop some code that extracts the model’s predictions and stores them in the appropriate FiftyOne types and adds them to your dataset. Inference happens on the machines where you are doing inference, and then basically use them to import FiftyOne and load the right dataset and add your data to that dataset.
Can you show how to use FiftyOne with ActivityNet?
Yes! FiftyOne provides a Dataset Zoo that contains a collection of common datasets that you can download and load into FiftyOne via a few simple commands. You can find all of the datasets available in the Zoo here, including ActivityNet. In fact, the ActivityNet authors are recommending to download and work with their dataset through FiftyOne, as you can see on their website.
In the FiftyOne documentation we have a comprehensive tutorial on how to download, visualize, and evaluate on ActivityNet, including all kinds of options for loading a specific split of the dataset, or only certain classes or only videos of a certain duration and more.
You can get a brief tour of the tutorial in the webinar replay from 35:10–36:45 in this video.
Can FiftyOne provide any automations for frame by frame annotations?
Yes, in FiftyOne we have integrations with annotation tools, currently CVAT, Label Studio, and Labelbox. Video annotations are supported, as is frame by frame video annotation. You can send a video dataset up for annotation using the integration and pull back in frame by frame annotations.
Often for video annotations, key frames are annotated vs every frame. FiftyOne will automatically interpolate frame annotations, while also indicating which ones were human-annotated key frames annotated. For more information, visit the annotation integrations in the docs.
Are the changes in app config also exported when we export the dataset?
Yes! There are a lot of ways to export datasets in FiftyOne. But, if you are looking to export all of the dataset metadata you’ve customized in FiftyOne, like field metadata and app config settings, that’s all included when you export in FiftyOne dataset format. So if you export in this format and then pull it back in, yes, it will be included.
Is video embedding clustering possible with FiftyOne? Maybe even object flow visualizations?
Yes! The part of the tool where you work with embeddings is called the FiftyOne Brain. In the docs, we provide examples of visualizing embeddings. If you want to work with visualizing video embeddings, you will need to use the “compute your own embeddings and provide them in array form” option in FiftyOne. It’s possible to wrap your own model in FiftyOne’s interface. And there is an interface video embeddings model. But the choice of how you want to generate an embedding for a video is up to you because it depends on what you’re trying to optimize for.
For example, if you want to embed every 10th frame and then average the embeddings or concatenate embeddings, you can do that. Or if you want to use an activity recognition model and pull some video embeddings from it, you can do that, too. Once you’ve computed some embeddings, you can pass them to the relevant methods downstream in FiftyOne and you can have your clustering workflows for video models.
Can a dataset be corrected on the go?
Yes! Everything about FiftyOne is mutable. For example, there’s support in the App for editing in the form of tagging. Once you’ve loaded in a dataset, if you find some samples that you don’t like, for example, you can tag them, and then find or exclude those samples through the App. Those changes made in the App are also persisted to the underlying dataset, so that you can edit your datasets programmatically too. You can also add or remove new fields at any time. There’s also a workflow for editing annotation data, simply check out one of FiftyOne’s annotation integrations to learn more about it.
In addition, many parts of FiftyOne are pluggable, including the tabs here:
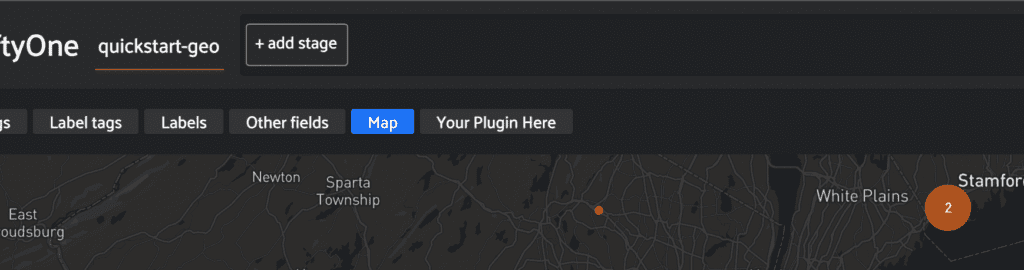
There’s a plugin API whereby you could write your own plugin to render your own custom visualization of your dataset. Checkout the docs on custom plugins here. Not only can you plug in this area of the code, you could also plug in your own visualizer. So it’s possible, and would be amazing, for someone to write a plugin that would embed the annotation tool into the App, because then you could directly edit in FiftyOne if that was of interest to you.
Is FiftyOne also an all-in-one CV tool with segmentation features, etc?
FiftyOne has semantic segmentation capabilities, but it is not meant to be an all-in-one CV tool. It is meant to be an essential part of the CV workflow to help data science teams improve the performance of their computer vision models by helping them curate high quality datasets, evaluate models, find mistakes, visualize embeddings, and get to production faster.
What’s Next
- If you like what you see on GitHub, give the project a star!
- Get started! We’ve made it easy to get up and running in a few minutes.
- Join the FiftyOne Slack community, we’re always happy to help!

