
Last week Voxel51 hosted the February 2023 Computer Vision Meetup. In this blog post you’ll find the playback recordings, highlights from the presentations and Q&A, as well as the upcoming Meetup schedule so that you can join us at a future event.
First, Thanks for Voting for Your Favorite Charity!
In lieu of swag, we gave Meetup attendees the opportunity to help guide our monthly donation to charitable causes. The charity that received the highest number of votes by an overwhelming majority this month was Direct Relief. We are sending this month’s charitable donation of $200 to Direct Relief’s Turkey-Syria Earthquake Relief program on behalf of the computer vision community.

Computer Vision Meetup Recap at a Glance
Paula Ramos // Breaking the Bottleneck of AI Deployment at the Edge with OpenVINO
Vishal Rajput // Understanding Speech Recognition Using OpenAI’s Whisper Model
Next steps
- Computer Vision Meetup Locations
- Computer Vision Meetup Speakers — March, April, and May
- Get Involved!
Breaking the Bottleneck of AI Deployment at the Edge with OpenVINO
Video Replay
Executive Summary
One of the biggest problems in computer vision is data. As Paula Ramos, Computer Vision, AI and IoT Evangelist at Intel, notes, “good datasets make good models; bad datasets will affect the model’s performance and accuracy, and could result in frustration for you.” Getting quality data is a common challenge in AI use cases across industries. For example, Eigen Innovations, an Intel partner, helps manufacturers prevent quality issues by accurately detecting defects. But in real world scenarios there can be an imbalance of data where there are not enough samples of defects in order to train an accurate model. So what can we do? It’s real world datasets like this that motivated the creation of Anomalib.
An Introduction to Anomalib
Anomalib, part of the OpenVINO toolkit, is a library for unsupervised anomaly detection from data collection to deployment. As part of a tutorial Paula prepared for CVPR last year, she checked for defects in a production system. To train the model, she made use of Anomalib and was able to train her model with just 10 total images, none of which were samples of defects. How does this magic happen? Paula explores the main components of Anomalib so we can learn more.
Exploring Anomalib: Algorithms
Anomalib includes state-of-the-art anomaly detection algorithms across four main categories: knowledge based models, clustering models, reconstruction based models, and probabilistic models. Choose a model depending on your use case.
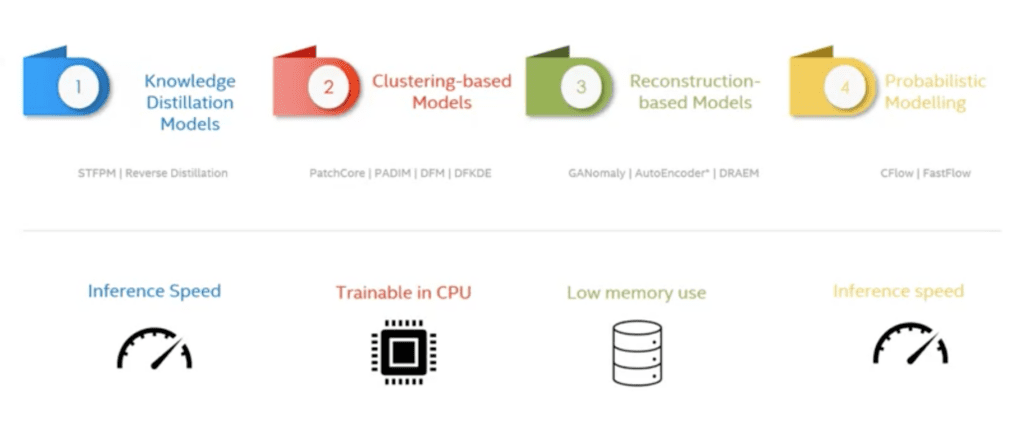
Exploring Anomalib: Modules, Tools, and Tests
Anomalib includes modules for data, pre-processing, models, and post-processing, and deployment. It also includes tools and tests. Paula describes each of these seven areas.
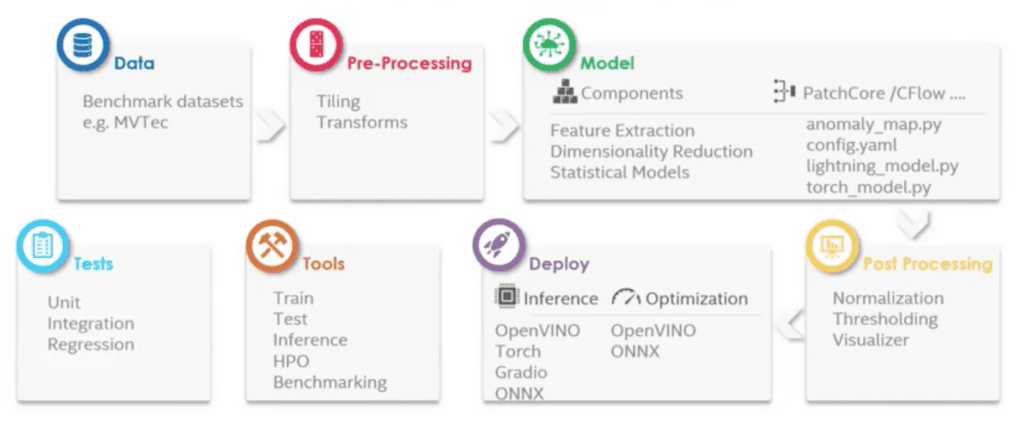
Anomalib’s data component provides dataset adapters for a growing number of public benchmark datasets in both the image and video domains. Custom datasets are also supported.
Pre-processing applies transformations to input images before training and optionally divides the image into overlapping or non-overlapping tiles. Paula shares a common use case for image tiling in real world datasets: high resolution images that include anomalies in a relatively small pixel area. Scenarios like these can be challenging for deep learning model to handle, so to address this issue, Anomalib can tie images to patches to support high resolution image training.
Anomalib’s model component contains a selection of state-of-the art anomaly detection and localization algorithms, as well as a set of modular components that serve as building blocks to compose custom algorithms.
Anomalib also offers post-processing features for normalization, thresholding, and visualization outputs.
Anomalib’s deployment options include using Torch, ONNX, Gradio, or OpenVINO.
Within the Anomalib library there are tools that include entry points for training, testing, inferring, benchmarking, and hyper parameter optimization.
Additionally, the Anomalib library constantly undergoes unit integration and regression tests to capture any potential defects.
Getting Started with Anomalib
Paula shows how easy it is to get started with Anomalib, including a demo:
- Create an environment to run Anomalib (Python version 3.8)
- Clone the Anomalib repo and install it locally (with OpenVINO requirements)
- Install Jupyter Notebooks and ipywidgets
- Download the MVTec-AD dataset needed to run the demonstration before you follow along with the demo in the notebook
- Head to the getting_started Anomalib notebook (available on GitHub) to get started and run the demo to see it in action for yourself
The demo shows how easy it is to install Anomalib and the other packages you need, choose a model, update the config file, start model training, visualize results, and perform inference.
Now it’s your turn to try! Plus, giving Anomalib a whirl could win you one of five limited edition hoodies if you follow these steps before February 16, 2023.

Other Exciting Tools: OpenVINO and Intel Geti
Anomalib is part of the OpenVINO ecosystem. If you’re interested in using the OpenVINO toolkit in your deployments, Paula invites you to check out the examples in the OpenVINO tutorial notebooks. More than 60 demos are there, including object detection, pose estimation, human action recognition, style transfer, text spotting, OCR, stable diffusion, YOLOv8, and many more.
In her presentation, Paula also introduces another exciting tool for computer vision: the Intel® Geti™ platform. Intel Geti enables users to build and optimize computer vision models by abstracting away technical complexity with an intuitive interface. Learn more about Intel Geti in less than 3 minutes in this video showcasing how the computer vision AI platform is used to help optimize coffee production.
Q&A Recap
Here’s a recap of the live Q&A from this presentation during the virtual Computer Vision Meetup:
After anomaly detection, can we use DC-GANs to remove the anomaly in the image or solve the data imbalance problem?
Using a DC-GAN it may be possible to remove the anomaly, but it would not be able to solve the imbalance problem 100%. There is another way to try to balance the data; in the Anomalib library, we have the option to create scientific abnormalities, but some imbalancing would still exist.
Can OpenVINO speed up deep learning models that are deployed to CPU up to the same performance as GPU?
Yes, with OpenVINO we have the flexibility to run models on different hardware, so we can load the model in the CPU at the beginning, then we can load the model in GPU, and we can have the advantage to accelerate the performance of the model. Join the Computer Vision Meetup on May 11 at 10 AM PT for part 2 of today’s presentation, focused on performant ML models for Edge Apps using OpenVINO.
Can we have access to this Jupyter Notebook?
Yes, you can access the Jupyter Notebook in the Anomalib repo on GitHub, including the getting_started notebook we shared today.
What real world examples do you see this type of anomaly detection being useful in? Other than the industry example you already showed?
In our example, we showed how useful Anomalib is in a manufacturing or factory setting. Other real-world use cases include security, such as screening for anomalies in luggage at airports. And also healthcare; for example, there are scenarios where we need to detect the presence of cancer in medical images. So Anomalib is not just for factory data, it’s also popular for healthcare and security use cases.
What about edge inference? Are many anomaly detection networks capable of “compression” and therefore can be effectively deployed via tinyML?
OpenVINO gives us the flexibility to write models once and deploy them everywhere, including the ability to run inference at the edge. With OpenVINO you can use less memory, while also being able to make use of different types of hardware; so with just one model, you can deploy it everywhere, regardless of the hardware required to run it. Although there are competitors in this space, OpenVINO has differentiating features that make it attractive for a variety of use cases, including edge AI.
In coffee AI work, how was the labeling handled? Does it need thousands of images to be labeled?
Back when Paula was pursuing her PhD in computer vision and machine learning, she built a system for coffee production detection, before the launch of Intel Geti made the same use case significantly easier. Paula explains the requirements for image labeling across both scenarios: “During my PhD, I needed to annotate tens of thousands of images in video. (However) using Intel Geti, I just needed to annotate 20 images to start with in the first round of training.” If you are interested to learn more about Intel Geti, you visit geti.intel.com.
How easy is it for anyone who doesn’t have wide knowledge in deep learning to start with Intel Geti?
If somebody doesn’t have knowledge in deep learning, they can start with Intel Geti in a simple way. Intel Geti has this flexibility because it abstracts away the technical complexity with an intuitive user interface. For example, in the use case regarding coffee production, we can involve accounting, the farmer, and the data scientist, each with differing levels of knowledge in deep learning.
Additional Resources
Check out the additional resources on the presentation:
Thank you Paula on behalf of the entire Computer Vision Meetup community for sharing your expertise on working with Anomalib, OpenVINO, and Intel Geti to optimize computer vision models, especially at the edge!
Understanding Speech Recognition Using OpenAI’s Whisper Model
Video Replay
Executive Summary
Vishal Rajput, AI Vision Engineer, Author, presents an overview of speech recognition technology and its importance in today’s digital world. To start, Vishal provides an overview of what speech recognition is, as described by a Google search he performed that surfaced the top result from Oxford Languages: “the ability of a computer to identify and respond to the sounds produced in human speech”.
Why do we need speech recognition systems and how can they help us? Vishal hits the highlights. First, we can, so why not? Next, they can make our lives easier and more comfortable. Additionally, they can be used in scenarios where we cannot use hands. Lastly, they speed things up – speech can be almost three times faster than typing.
In order to get us up to speed in modern speech recognition, Vishal first takes us back to 2013-2015 to give us a glimpse into early speech recognition systems.
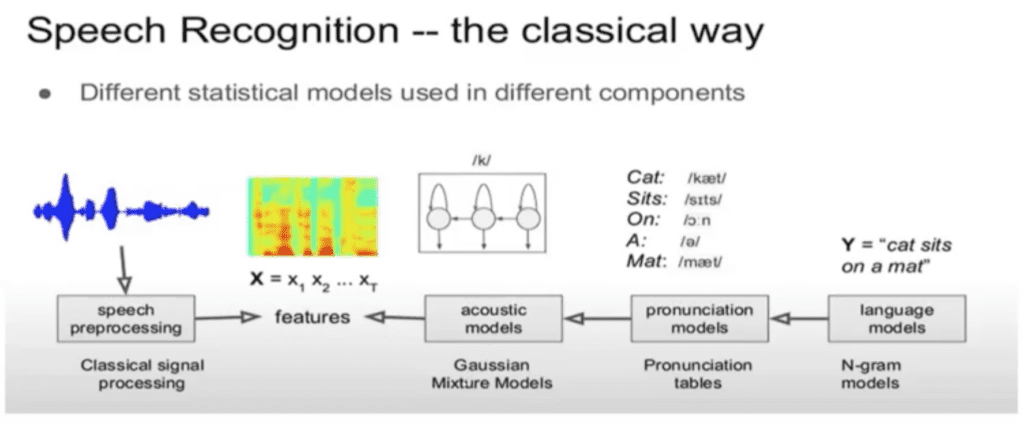
Early speech recognition technologies, such as Cortana, had some challenges, including low signal-to-noise ratio, variability in speaker accents, and difficulty in understanding natural conversational speech. This is in part because of how they operated. Each model was trained differently, with different objectives. Changing one model created blind spots in terms of how it affected the others.
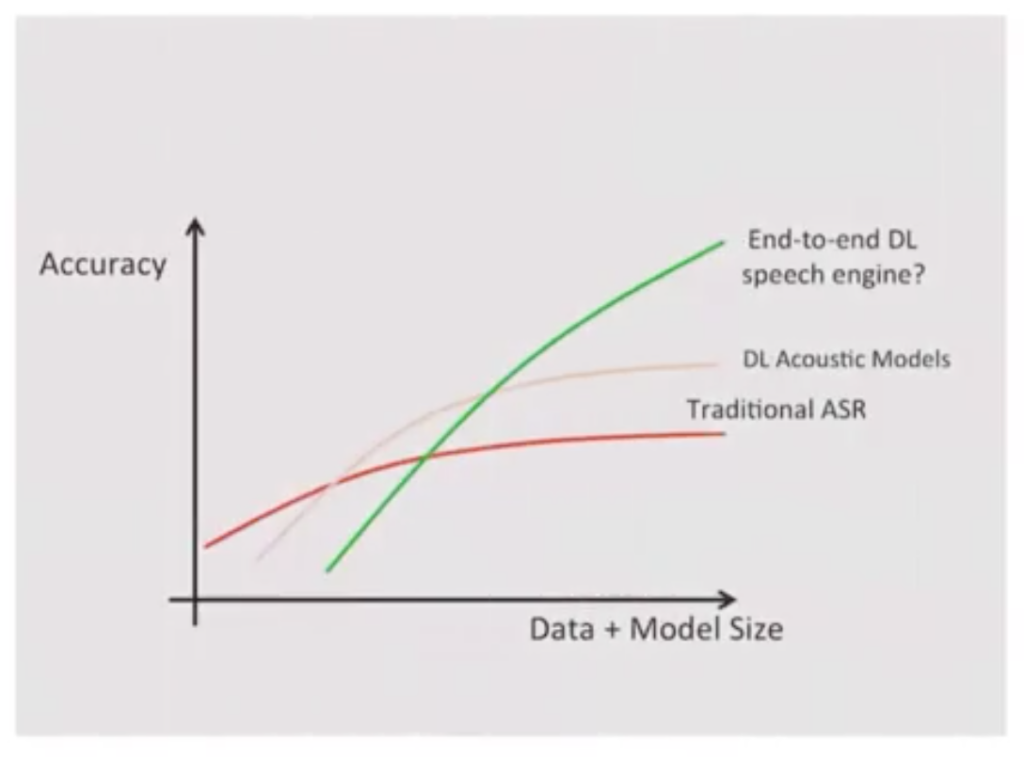
To achieve better results, deep learning was introduced, first into the acoustic models. Then the next step was to make an end-to-end deep learning speech engine. And you can see as the data and model size increased, speech recognition accuracy increased significantly.
Vishal then discusses various deep learning models used in speech recognition systems and specifically calls out two models, which are very important in the development of speech recognition: Connectionist Temporal Classification (CTC), which solves the alignment problem in speech recognition, and sequence to sequence (listen attend and spell, or LAS). Vishal notes that these two important models predated attention, which came out in the Attention Is All You Need paper in 2017.
Next, Vishal takes time to appreciate other important work in speech recognition, including: wav2vec, vq-wav2vec, wav2vec2, and XLSR-wav2vec.
Before diving into OpenAI Whisper, Vishal notes that there are two ways to make speech recognition systems: supervised and unsupervised. Unsupervised offers more than a million hours of audio data; while supervised has only about 5000 hours of data available.
What was OpenAI Whisper able to do to outperform previous models? First, OpenAI Whisper introduced weak supervision to scale its data from 5,000 hours to 680,000 hours, bringing it close to the scale of unsupervised systems. Additionally, OpenAI used automated filtering methods on the automated transcripts available on the internet, as well as manual inspection, to improve the quality of the transcripts.
Looking at Whisper’s transformer block, the architecture is similar to an off-the-shelf transformer with the main differences being the use of a Mel Spectrogram and the use of specialized tokens.
Vishal explores the tokens (noting that you don’t actually see this happening; this is happening in the back end): language tag, no speech, transcribe, translate, and timestamp tokens. The model is trained on 99 different languages and can detect which language is being spoken, transcribe it into text, translate it into a different language if needed, and provide timestamps for each sound or word in the audio sample.
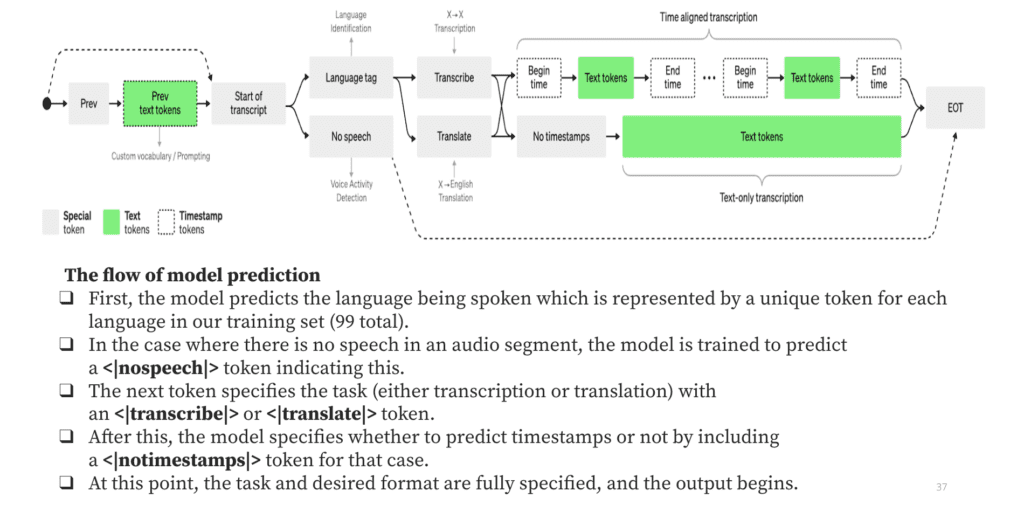
Additionally, OpenAI fine-tuned the Whisper model to better differentiate between different speakers talking and to standardize text (example, to standardize color and colour) before calculating the word error rate (WER) metric.
Speech recognition models still have room for improvement in the areas of improving decoding strategies on long-form transcriptions, increasing training data for lower-resource languages, studying fine-tuning, and the impact of language models on robustness. Nonetheless, Whisper still produces impressive results. To give us a taste, Vishal runs 25 seconds of audio through Whisper to show how accurately it transcribes audio to text. In the example of a narrative spoken in a Scottish accent, Whisper misconstrued only one word (mistaking Eldons as Yildens) in the entire audio file!
It’s easy to get started with the Whisper model (start here on GitHub, for example).
Q&A Recap
For new ASR pipelines, is there vector quantization? Gaussian mixture models remind me of diffusion models.
Yes, for ASR pipelines, Gaussian mixture models are similar to diffusion models.
Can you please explain how using FFT preserves the sequence in the speech?
FFT doesn’t need to preserve the sequences because the window size is very, very small, like 20 milliseconds. FFT doesn’t preserve, but RNN does.
Besides contrastive loss, there is reconstruction loss. L1 reconstruction performs better than L2 reconstruction and why?
Generally what happens is you combine the losses to have a better performance rather than just using L1 loss or L2 loss. It’s a combination of both, which performs better than one of them individually. And performance depends on the task. Sometimes L2 will perform better and sometimes L1 will perform better.
What is the difference between GPT and BERT?
As far as I understand GPT, GPT is not bidirectional because it is predicting the future, but BERT is bidirectional. (This notion is mentioned in the name–bidirectional encoder representations for transformers.) That is the primary difference between the two.
In what real world scenarios does the Whisper model have advantages over traditional ASR?
The Whisper model can definitely handle noise much better. It is actually on par with human understanding or in some cases even better than humans.
Additional Resources
Check out these additional resources:
A big thank you to Vishal on behalf of the entire Computer Vision Meetup community for getting us up-to-speed on speech recognition and the latest Whisper model by OpenAI.
Computer Vision Meetup Locations
Computer Vision Meetup membership has grown to nearly 3,000 members in just a few months! The goal of the meetups is to bring together communities of data scientists, machine learning engineers, and open source enthusiasts who want to share and expand their knowledge of computer vision and complementary technologies.
New Meetup Alert – We just added a Computer Vision Meetup location in Singapore! Join one of the (now) 13 Meetup locations closest to your timezone.
- Ann Arbor
- Austin
- Bangalore
- Boston
- Chicago
- London
- New York
- Peninsula
- San Francisco
- Seattle
- Silicon Valley
- Singapore
- Toronto
Upcoming Computer Vision Meetup Speakers & Schedule
We have exciting speakers already signed up over the next few months! Become a member of the Computer Vision Meetup closest to you, then register for the Zoom for the Meetups of your choice.
March 9 @ 10AM PT
- Lighting up Images in the Deep Learning Era — Soumik Rakshit, ML Engineer (Weights & Biases)
- Training and Fine Tuning Vision Transformers Efficiently with Colossal AI — Sumanth P (ML Engineer)
- Zoom Link
April 13 @ 10AM PT
- Emergence of Maps in the Memories of Blind Navigation Agents — Dhruv Batra (Meta & Georgia Tech)
- Talk 2 — coming soon!
- Zoom Link
May 11 @ 10AM PT
- Machine Learning for Fast, Motion-Robust MRI — Nalini Singh (MIT)
- Quick and Performant Machine Learning Models for Edge Applications using OpenVINO — Paula Ramos, PhD (Intel)
- Zoom Link
Get Involved!
There are a lot of ways to get involved in the Computer Vision Meetups. Reach out if you identify with any of these:
- You’d like to speak at an upcoming Meetup
- You have a physical meeting space in one of the Meetup locations and would like to make it available for a Meetup
- You’d like to co-organize a Meetup
- You’d like to co-sponsor a Meetup
Reach out to Meetup co-organizer Jimmy Guerrero on Meetup.com or ping him over LinkedIn to discuss how to get you plugged in.
The Computer Vision Meetup network is sponsored by Voxel51, the company behind the open source FiftyOne computer vision toolset. FiftyOne enables data science teams to improve the performance of their computer vision models by helping them curate high quality datasets, evaluate models, find mistakes, visualize embeddings, and get to production faster. It’s easy to get started, in just a few minutes.

