FiftyOne Active Learning Plugin Can Help You Label Data Faster!
Welcome to week seven of Ten Weeks of Plugins. During these ten weeks, we will be building a FiftyOne Plugin (or multiple!) each week and sharing the lessons learned!
If you’re new to them, FiftyOne Plugins provide a flexible mechanism for anyone to extend the functionality of their FiftyOne App. You may find the following resources helpful:
What we’ve built so far:
- Week 0: 🌩️ Image Quality Issues & 📈 Concept Interpolation
- Week 1: 🎨 AI Art Gallery & Twilio Automation
- Week 2: ❓Visual Question Answering
- Week 3: 🎥 YouTube Player Panel
- Week 4: 🪞Image Deduplication
- Week 5: 👓Optical Character Recognition (OCR) & 🔑Keyword Search
- Week 6: 🎭Zero-shot Prediction
Ok, let’s dive into this week’s FiftyOne Plugin — Active Learning!
Active Learning 🏃🎓🔄
When it comes to machine learning, one of the most time-consuming and costly steps is data annotation. In the realm of computer vision, labeling images or videos can be an incredibly laborious task, often requiring a team of annotators and hours of meticulous work to generate high-quality labels. Even with a well-labeled dataset, the effort doesn’t stop there: model training, evaluation, and then re-annotation in case of inaccuracies are all parts of an ongoing cycle.
What if you could make this iterative process smarter and more efficient? Enter Active Learning—a paradigm that iteratively selects the most “informative” or “ambiguous” examples for labeling, thereby reducing the amount of manual annotation needed. In practical terms, this means your model gets better, faster, and with fewer labeled samples.
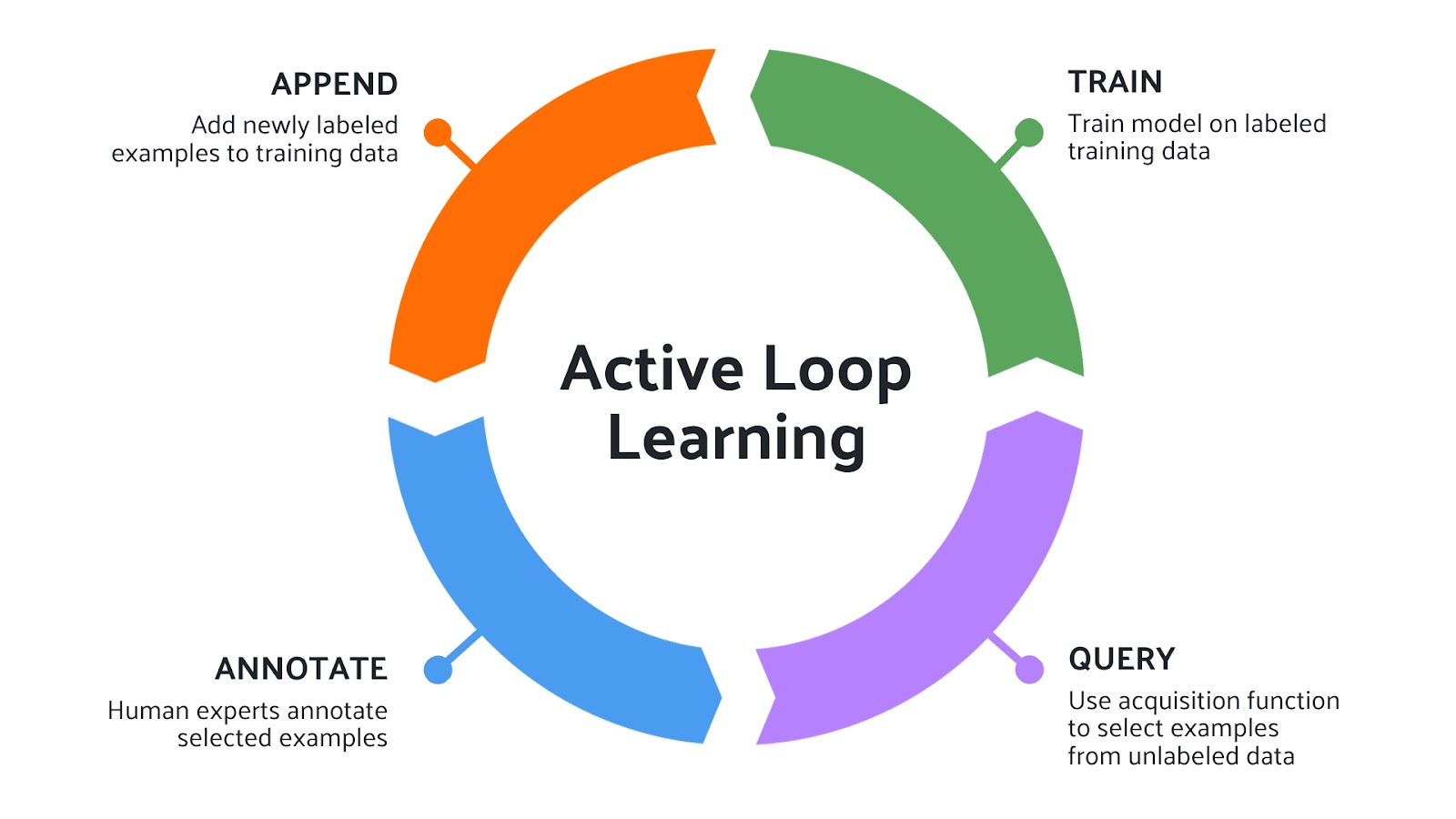
This FiftyOne plugin brings Active Learning to your computer vision data, allowing you to integrate this accelerant directly into your annotation workflow. Now you can prioritize, query, and annotate the most crucial data points, all within the FiftyOne App—no coding necessary.
The best part? You can use this in tandem with your traditional annotation service providers (via FiftyOne’s integrations with CVAT, Labelbox and Label Studio), or even with last week’s Zero-shot Prediction plugin!
Read on to learn how you can leverage the Active Learning Plugin to build high-quality models with less manual effort.
Plugin Overview & Functionality
For the seventh week of 10 Weeks of Plugins, I built an Active Learning Plugin. This plugin leverages the tried and tested modular active learning framework, modAL, to help you expedite your data labeling processes.
modAL is an active learning framework built on top of Sci-kit learn. It allows you to apply a variety of active learning strategies to models from Sci-kit learn, including solitary “estimators” like the KNeighborsClassier, and ensembles like the RandomForestClassifier, and even to create “committees” out of estimators, so you can estimate label uncertainty by comparing multiple hypotheses about the underlying data.
All of the necessary functionality from modAL is wrapped into FiftyOne Python operators, so that you can reap the rewards of Active Learning without writing a line of code.
💡At present, this plugin only supports Active Labeling for Classification tasks. However, it could be extended to object detection, semantic segmentation, and other computer vision tasks.
The plugin has three operators:
create_learner: creates an active learning model and environmentquery_learner: queries the active learning model for samples to labelupdate_learner_predictions: teaches the active learning model the previous queries, and updates the model’s predictions across the dataset
Because it uses caching, and it is not a JavaScript plugin, it will only work with the open source version of FiftyOne.
Creating the Active Learner
To create the Active Learner, your dataset must have:
- Initial labels
- Input features for the classifiers
First, for the purposes of illustration, I have taken a subset of the Caltech101 dataset with the labels airplane, Motorbike, helicopter, shuffled the data, and deleted the ground truth labels. In this blog post, we will use Active Learning to label this dataset. If you want to follow along at home, you can do so as follows:
import fiftyone as fo
import fiftyone.zoo as foz
import fiftyone.brain as fob
from fiftyone import ViewField as F
caltech101 = foz.load_zoo_dataset("caltech101")
## create sub-dataset
dataset = caltech101.filter_labels(
"ground_truth",
F("label").is_in(["airplanes", "Motorbikes", "helicopter"])
).shuffle().clone(name = "caltech3")
dataset.delete_sample_field("ground_truth")
dataset.persistent = True
session = fo.launch_app(dataset)
If you press “`” to open up the operators list and select any of this plugin’s three operators, you will be met with warning messages like this:
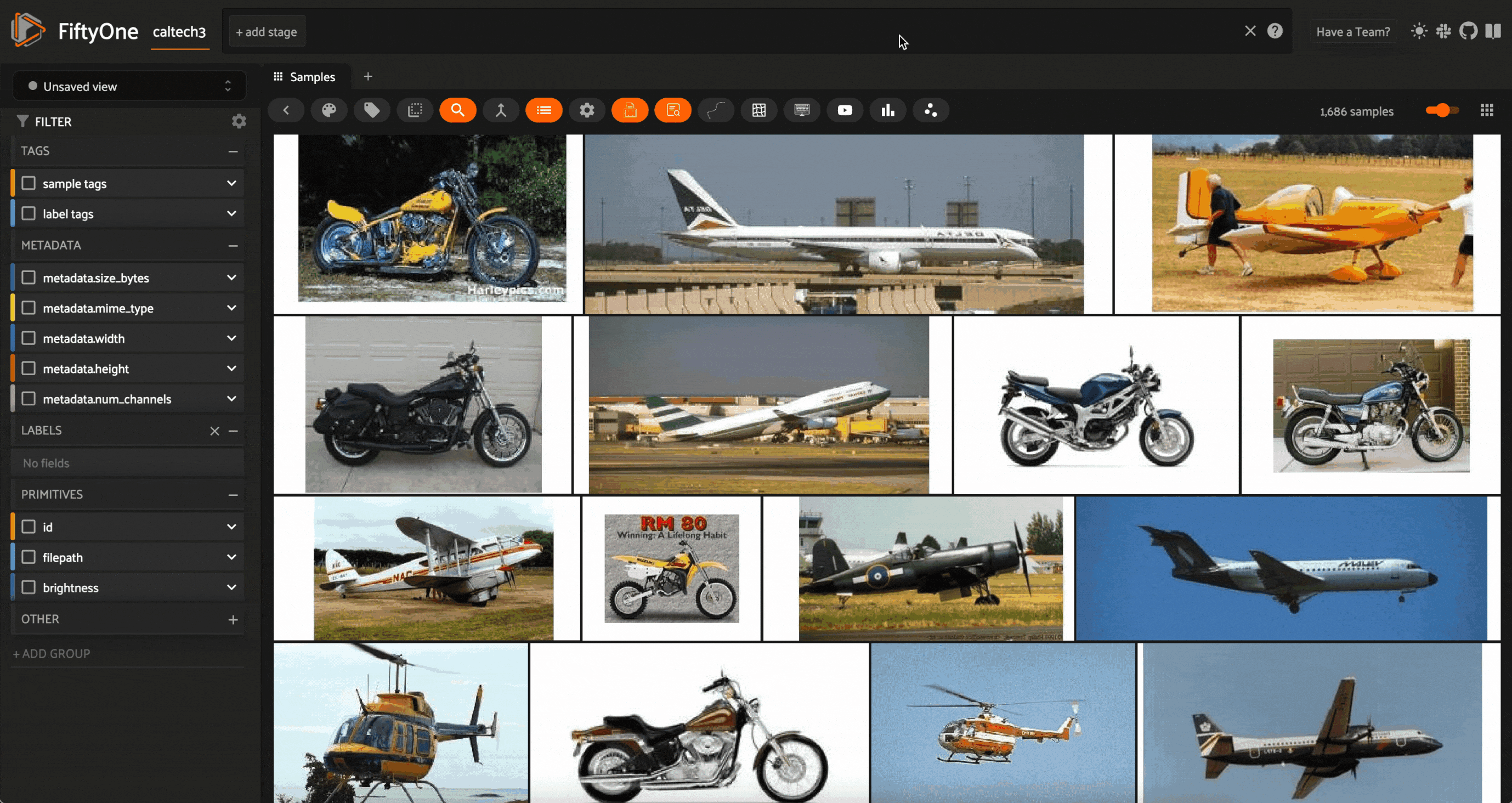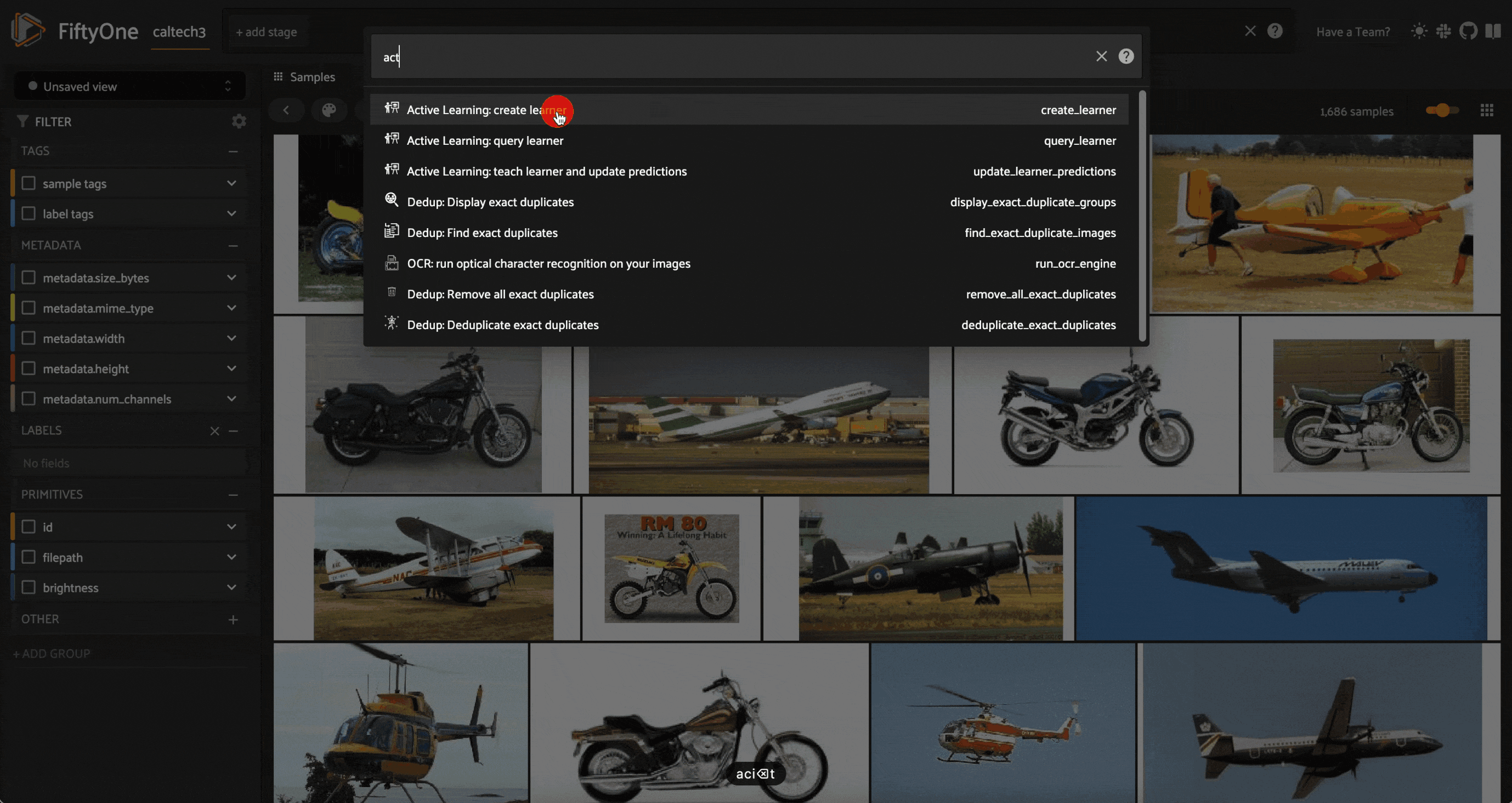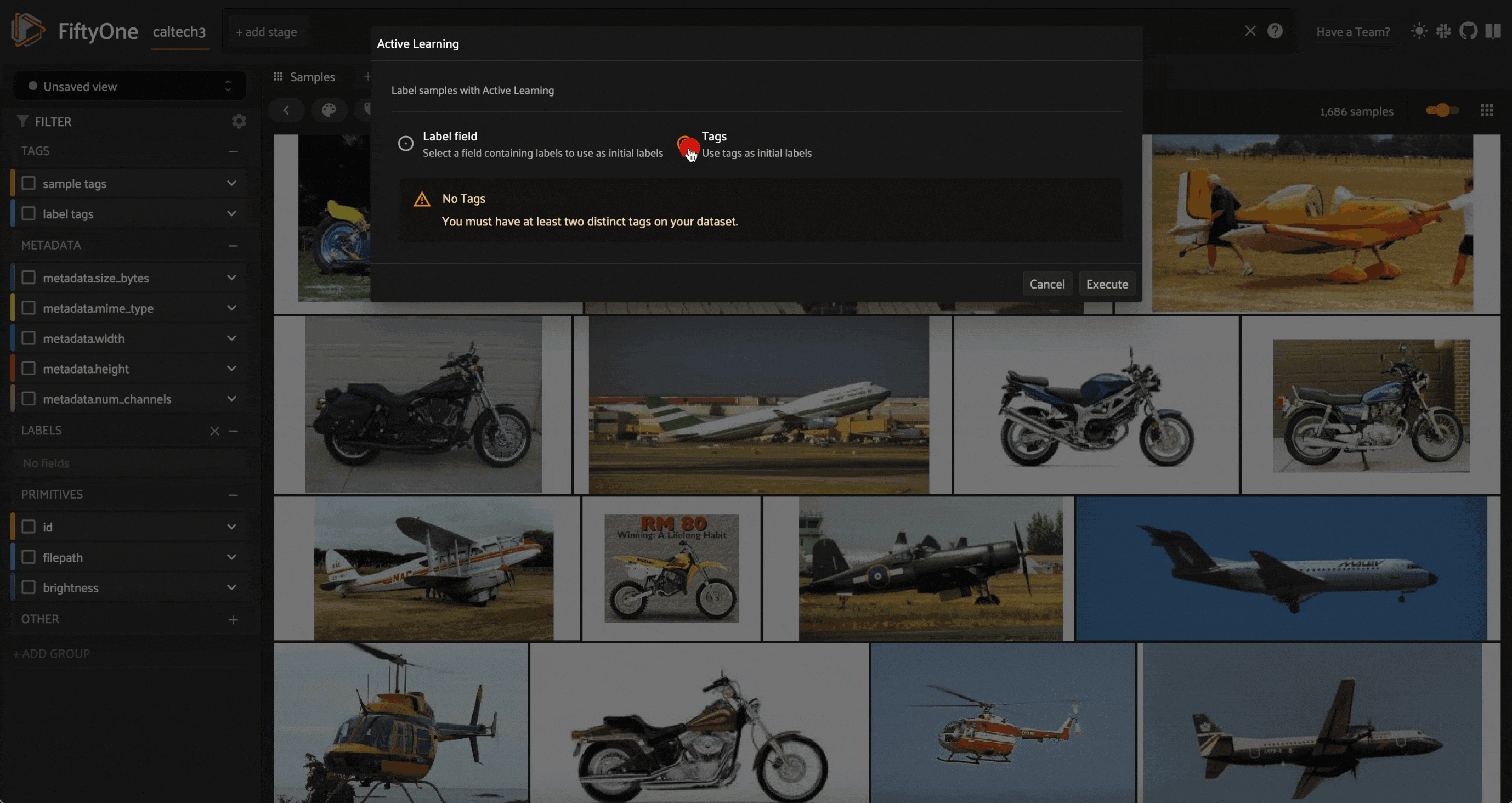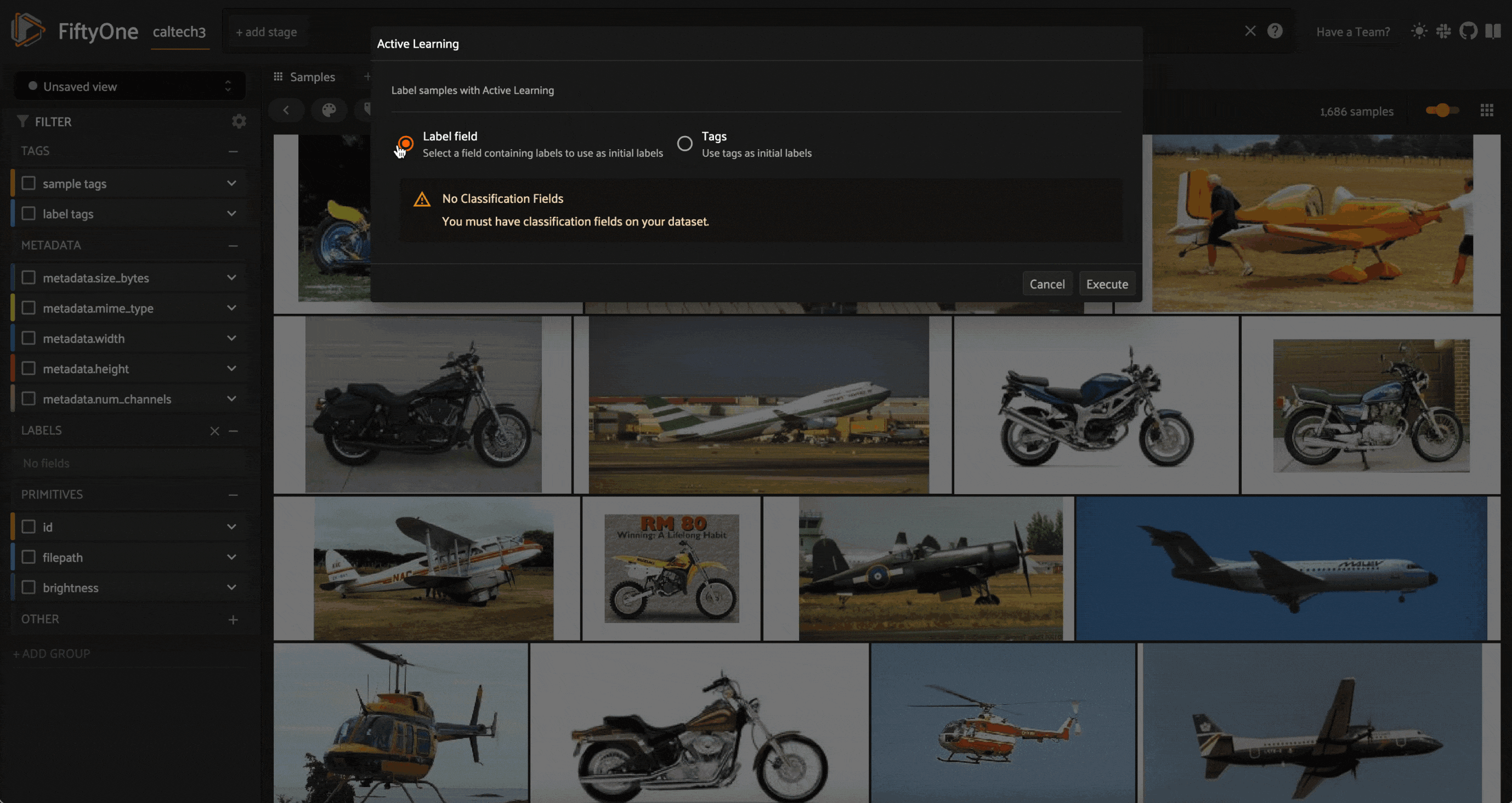
This is because you must have a set of labels to use to initialize the learner. We can either use tags, or we can generate some zero-shot classification predictions with our Week 6 Zero-shot Prediction Plugin, and use these as a starting point:
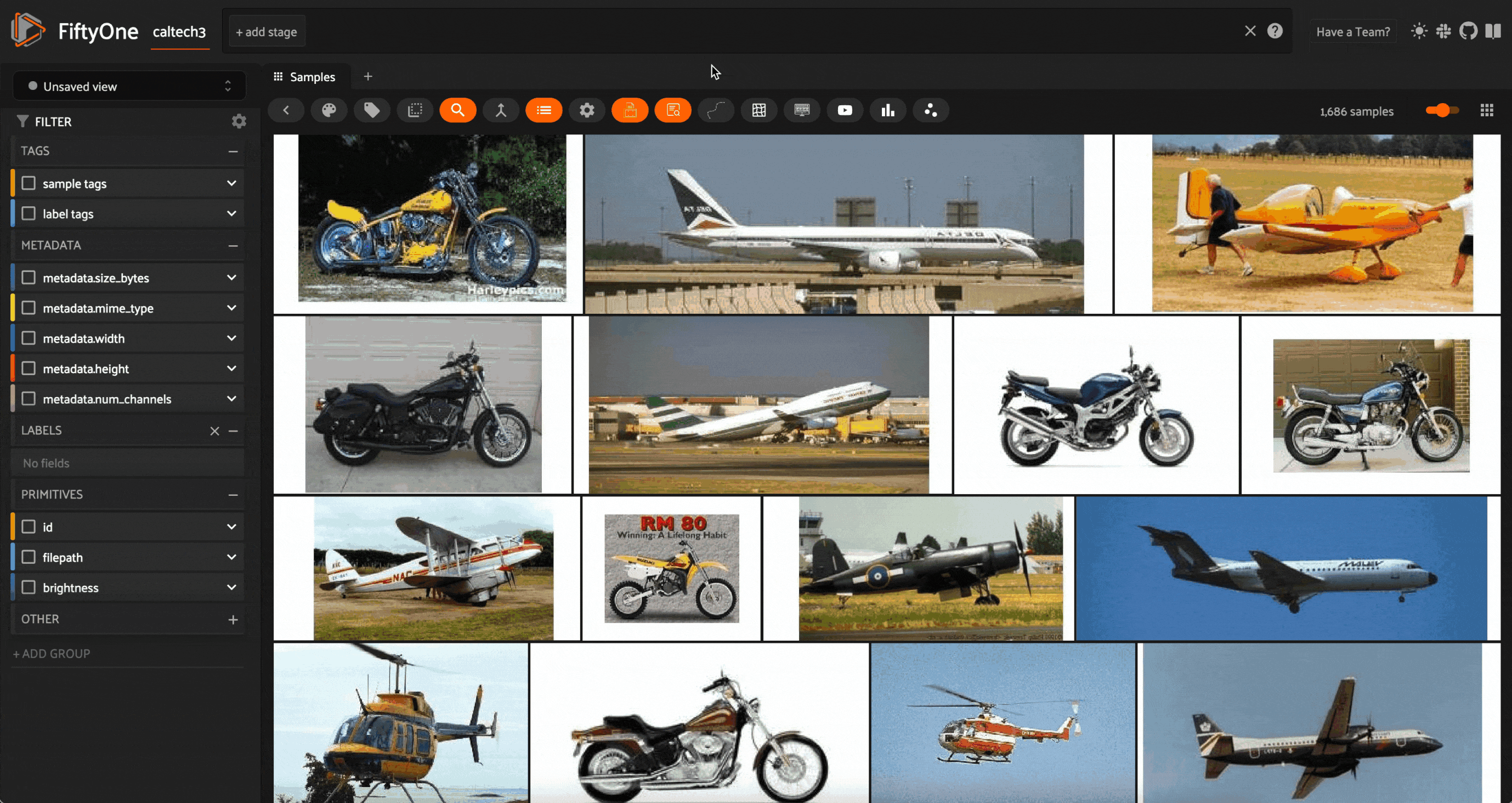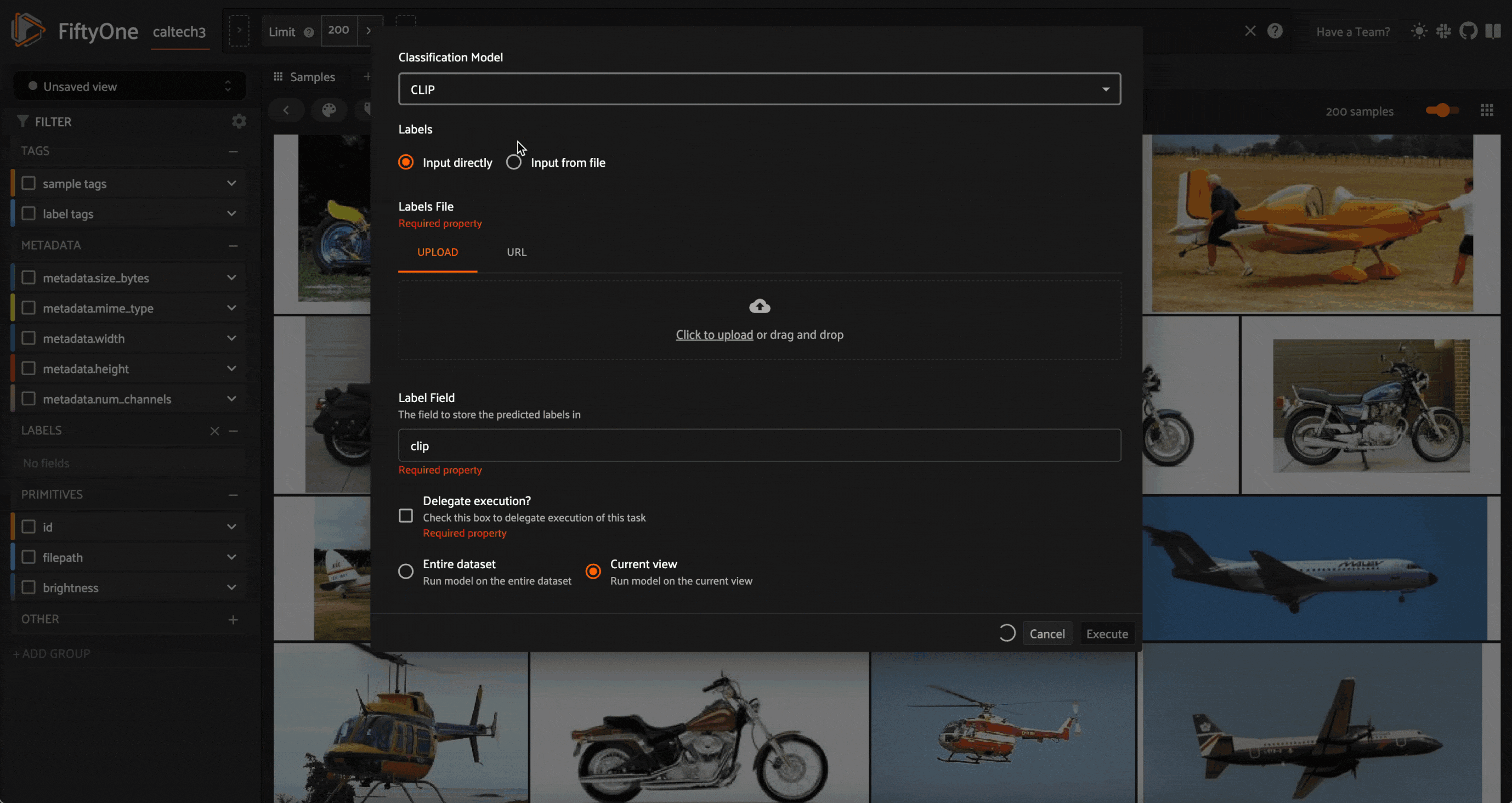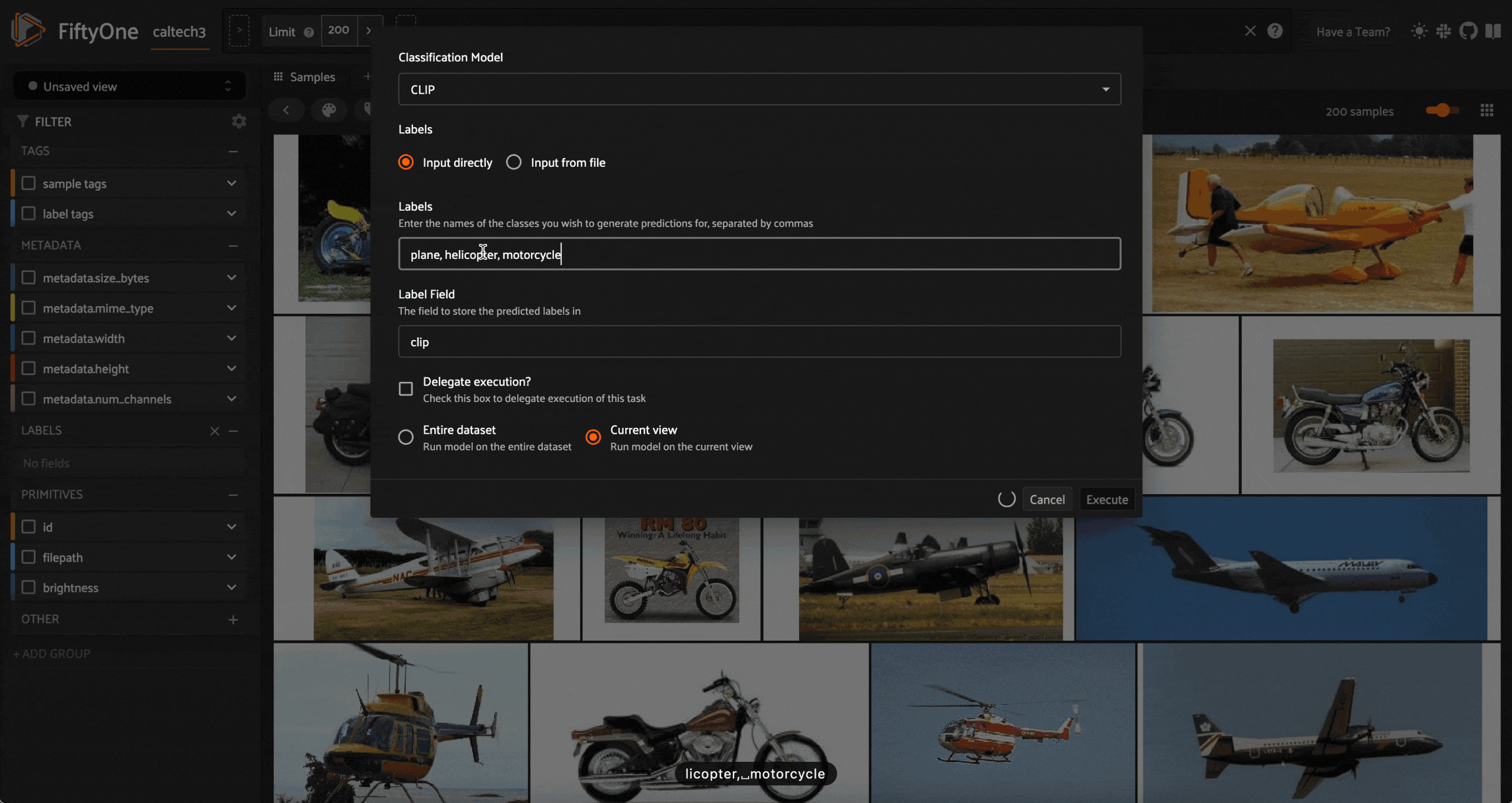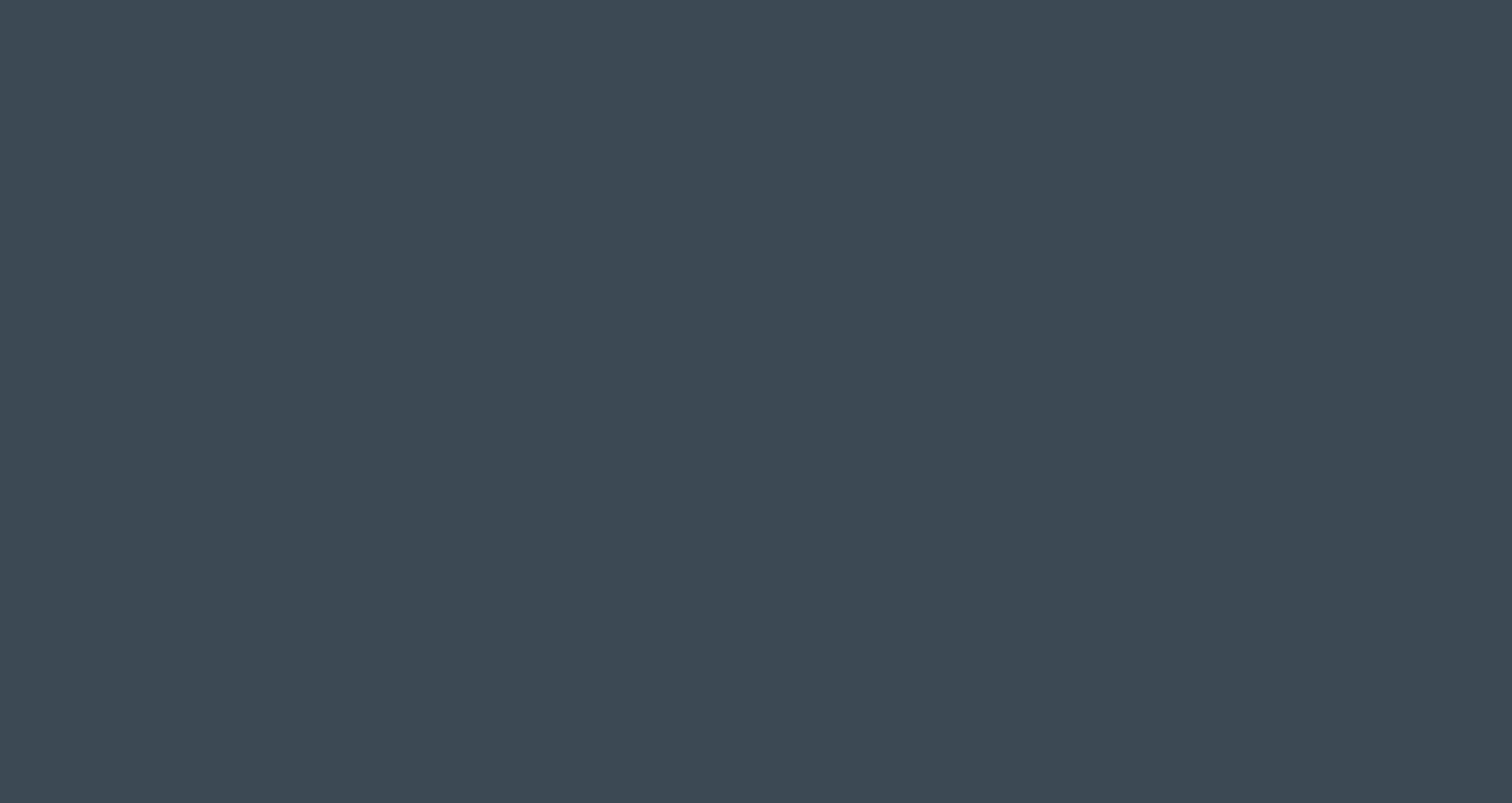
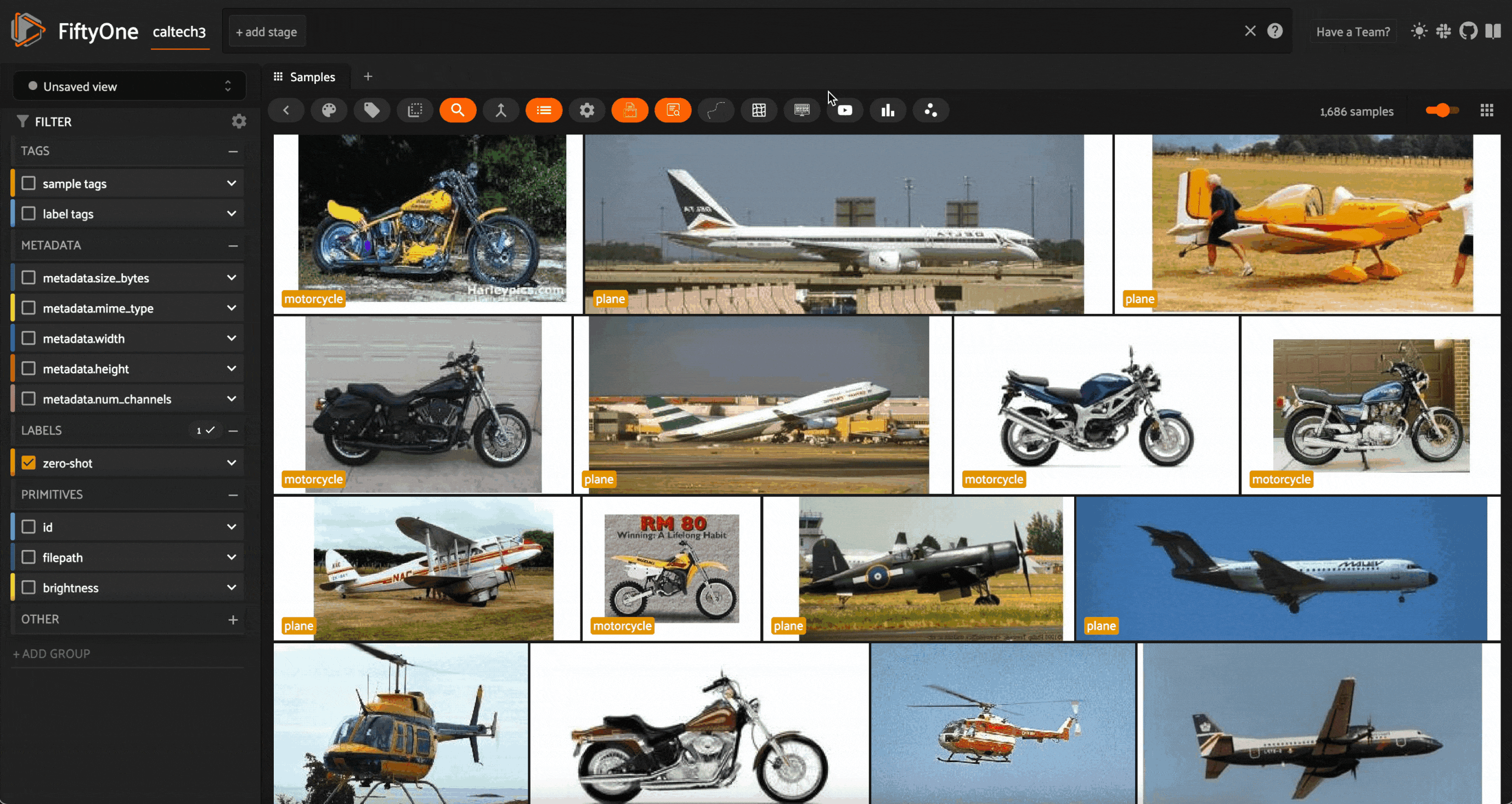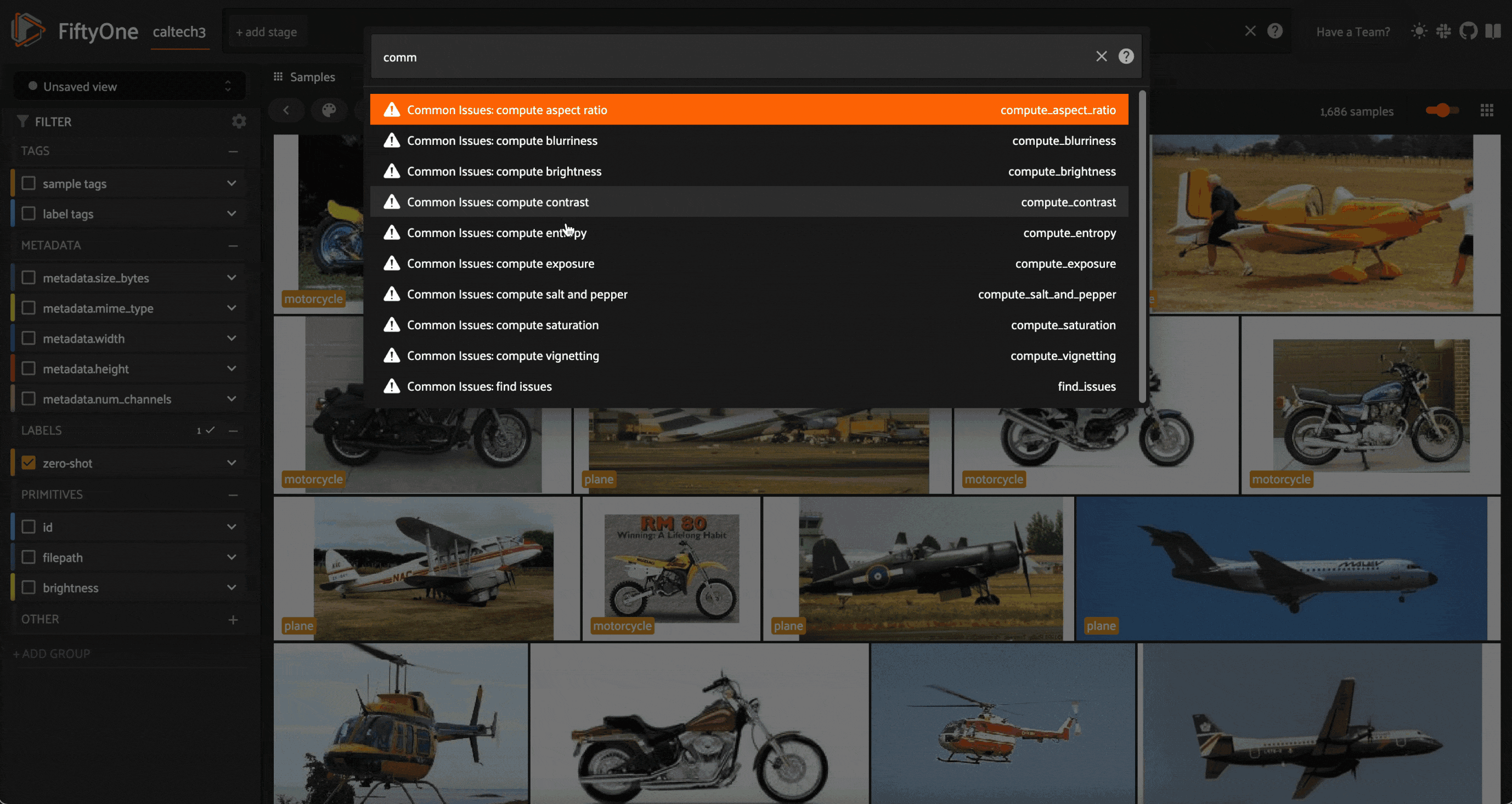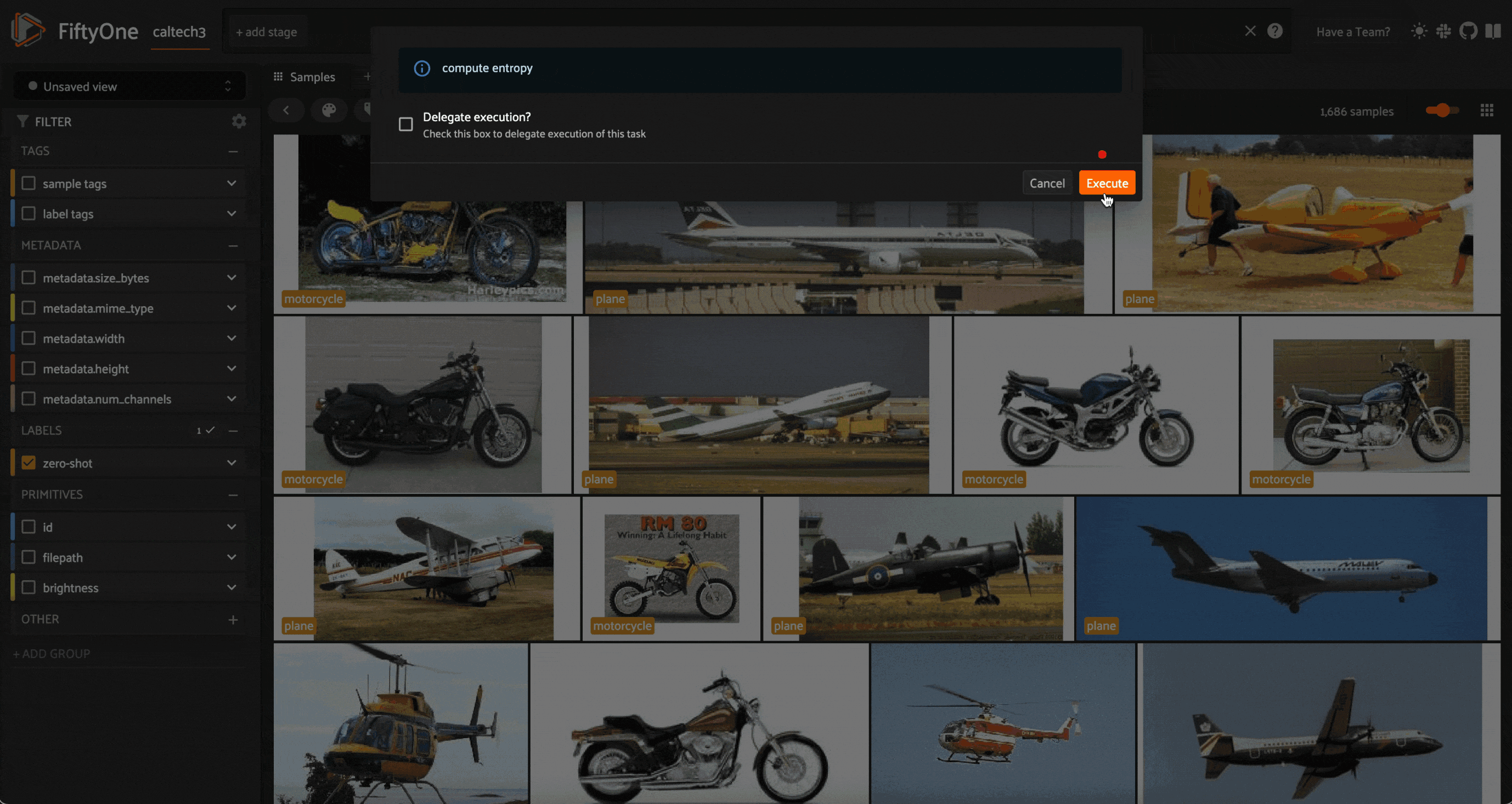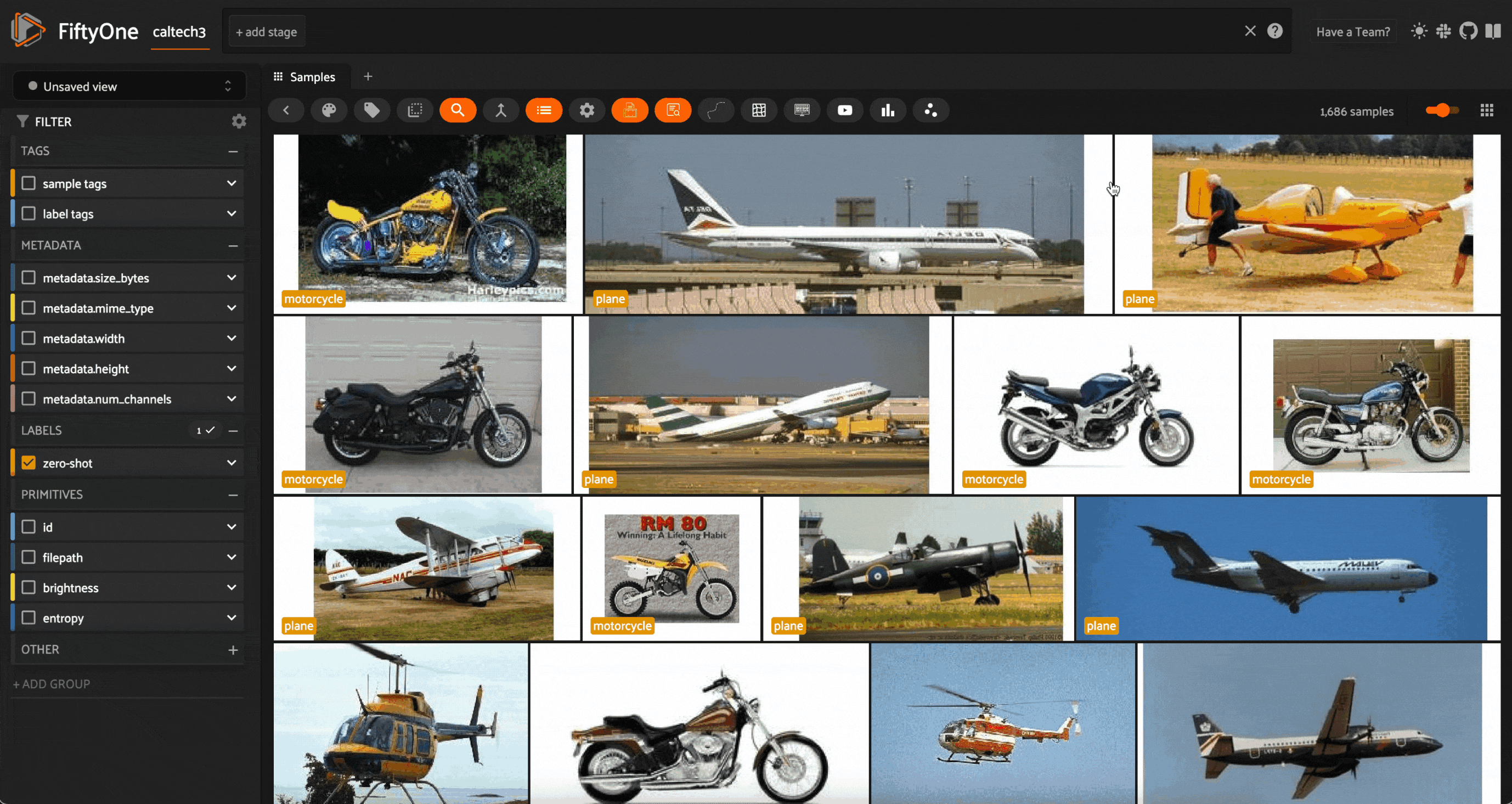
Regardless of which approach we take to initial labels, the only requirement is that we have at least one example from each class we are trying to classify. You do not need to run zero-shot labeling on the entire dataset, or tag all samples in the dataset.
💡In practice, typically a few examples from each class is good enough to start.
The second requirement is that the dataset has at least one field that can be used as an input feature to the “estimators” in the Active Learner. This could be any fo.FloatField (float-valued field) or any fo.VectorField (one-dimensional numpy array). If you want to use multiple fields as features, they will be concatenated into a one-dimensional feature vector.
If you don’t have any candidate feature fields, a good starting point is to use model embeddings.You can compute embeddings in Python by loading a model from the FiftyOne Model Zoo and running compute_embeddings(). For this walkthrough, I’ll compute embeddings using one more semantic model, CLIP, and one model trained more to represent data on the level of pixels and patches, MobileNet:
mobilenet = foz.load_zoo_model("mobilenet-v2-imagenet-torch")
dataset.compute_embeddings(
mobilenet,
embeddings_field = "mobilenet_embeddings"
)
clip = foz.load_zoo_model("clip-vit-base32-torch")
dataset.compute_embeddings(
clip,
embeddings_field = "clip_embeddings"
)
This stores the embeddings in the fields mobilenet_embeddings and clip_embeddings on our samples.
I will also use a few additional scalar properties computed using our Image Quality Issues Plugin. Here is how the entropy is computed:
The contrast and brightness are computed in analogous fashion.
Now that we have candidate input features on our samples and some initial labels, we can create an active learner!
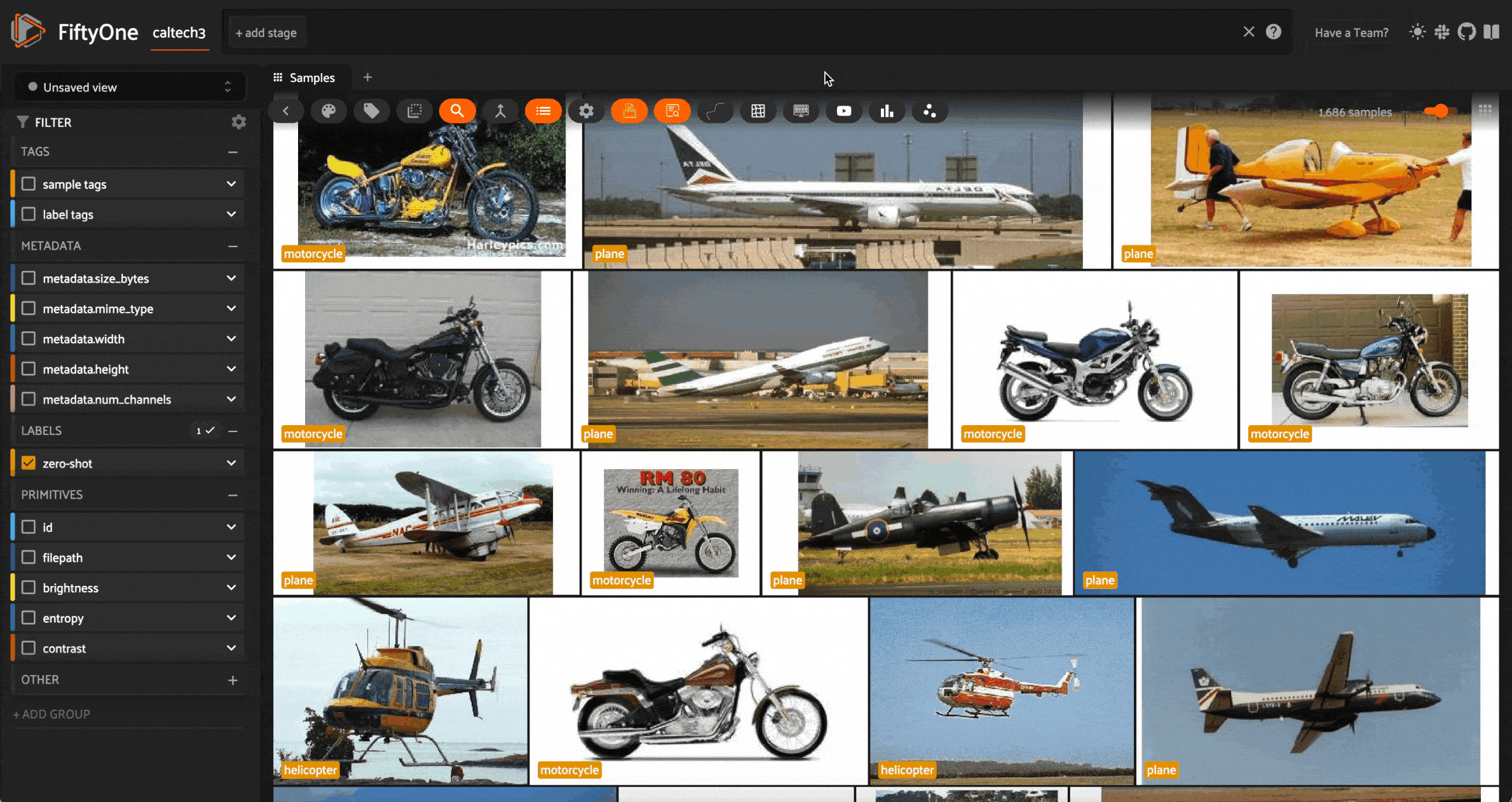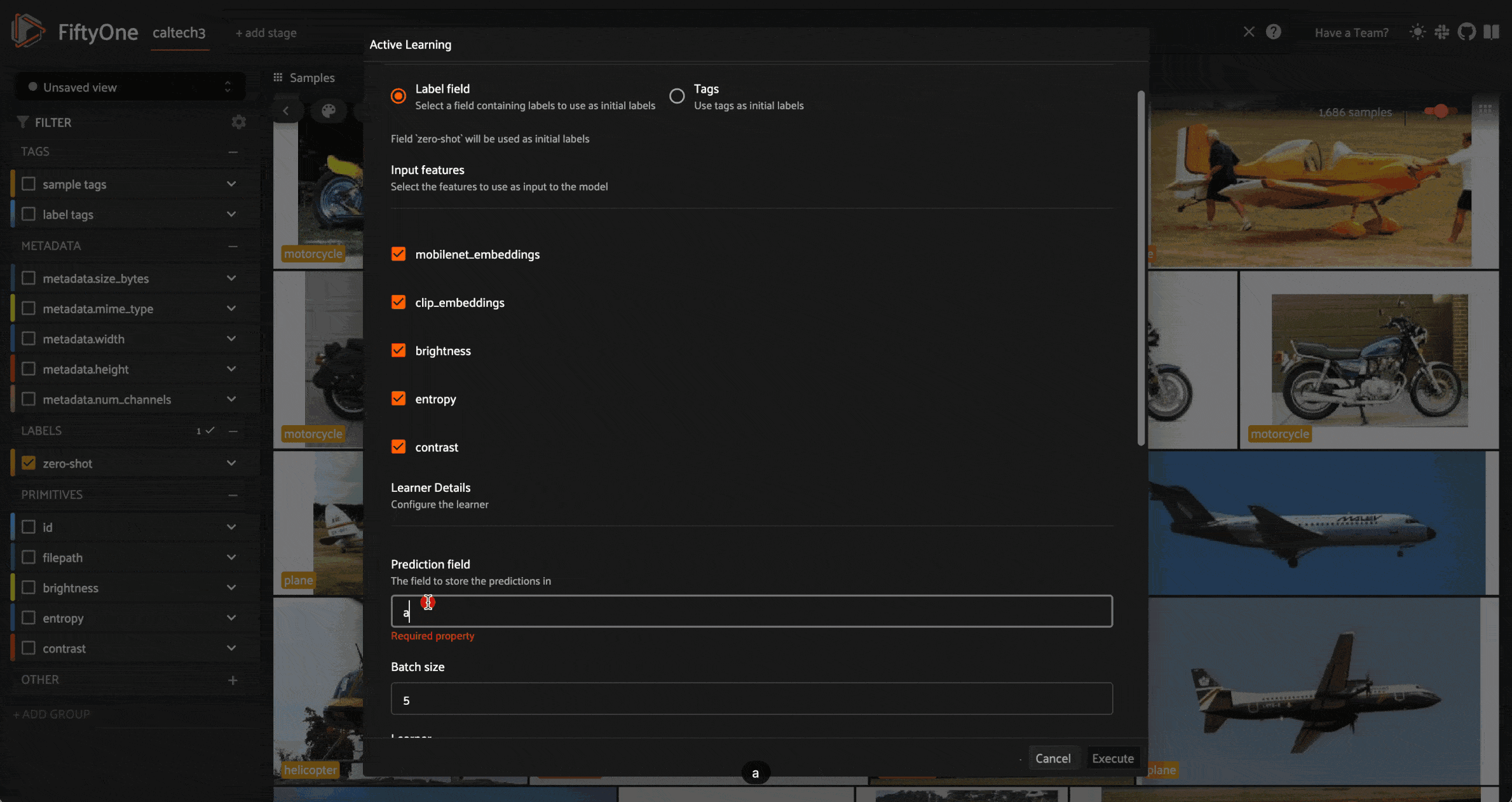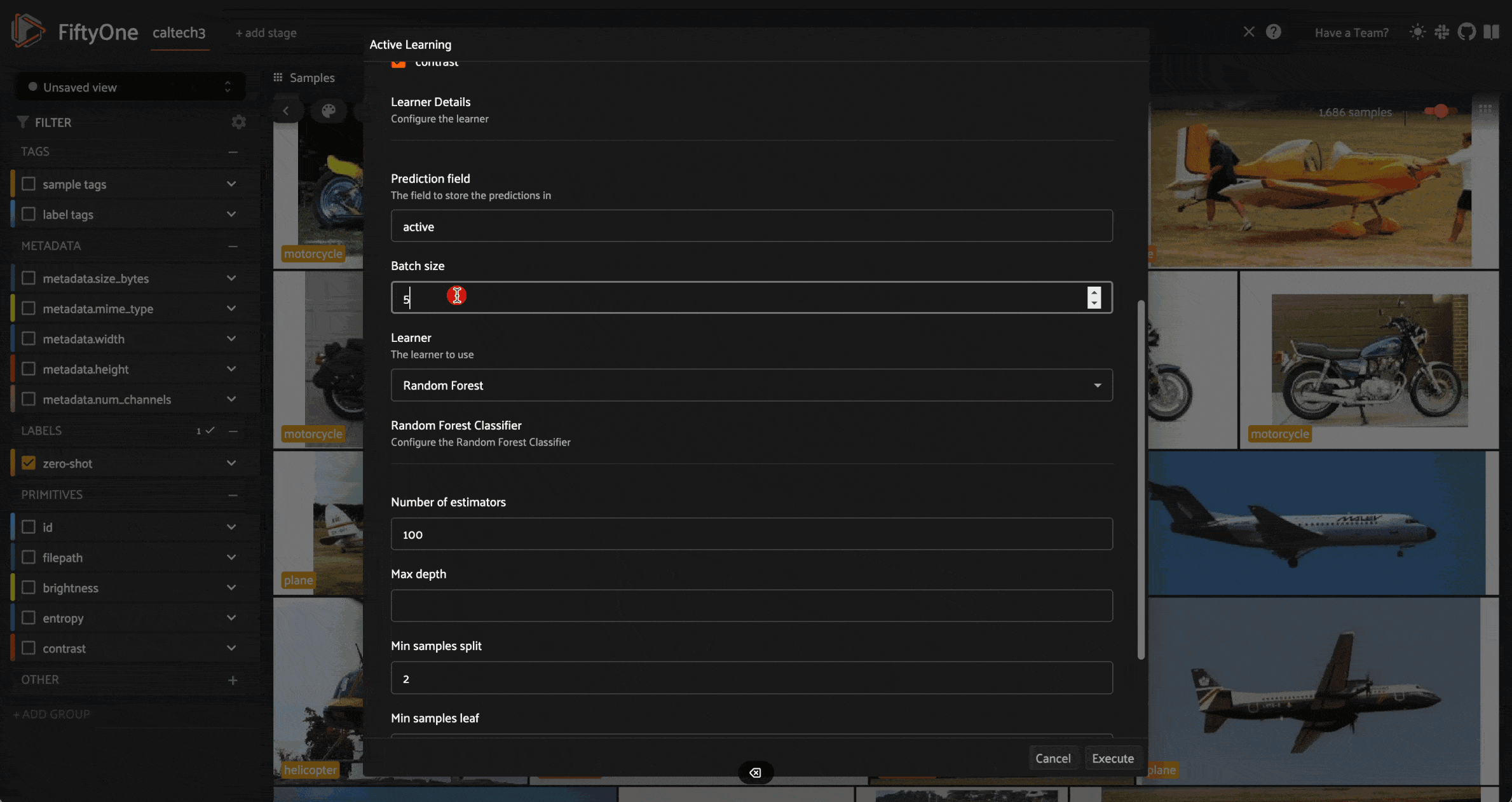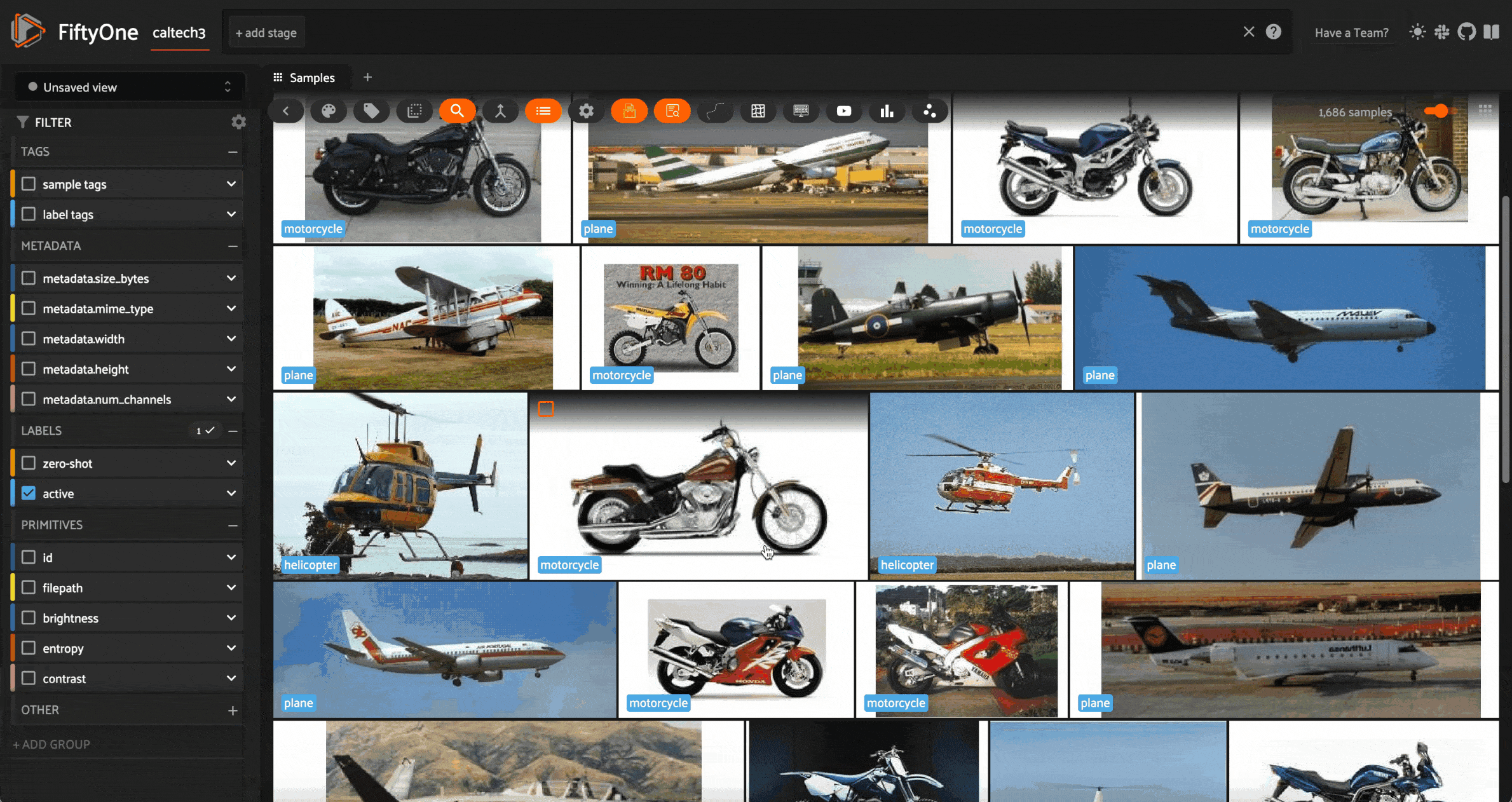
We can choose:
- The field or fields to use as a feature vector
- The label field in which to store predictions
- The default batch size — the number of samples per query
- The
Active Learner
For the latter of these, we can select from a variety of ensemble strategies, including Random Forest, Gradient Boosting, Bagging, and AdaBoost. When we make this top-level selection, the remainder of the form dynamically updates with appropriate hyperparameter configuration choices.
Executing this operator creates a modAL ActiveLearner that uses an “uncertainty” batch sampling. The execution also invokes the generation of initial predictions, and triggers the reload of the dataset.
Querying the Active Learner
Now that we have our learner, we can query the learner for the next batch of samples to label. If we’d like, we can override the default query batch size we set earlier:
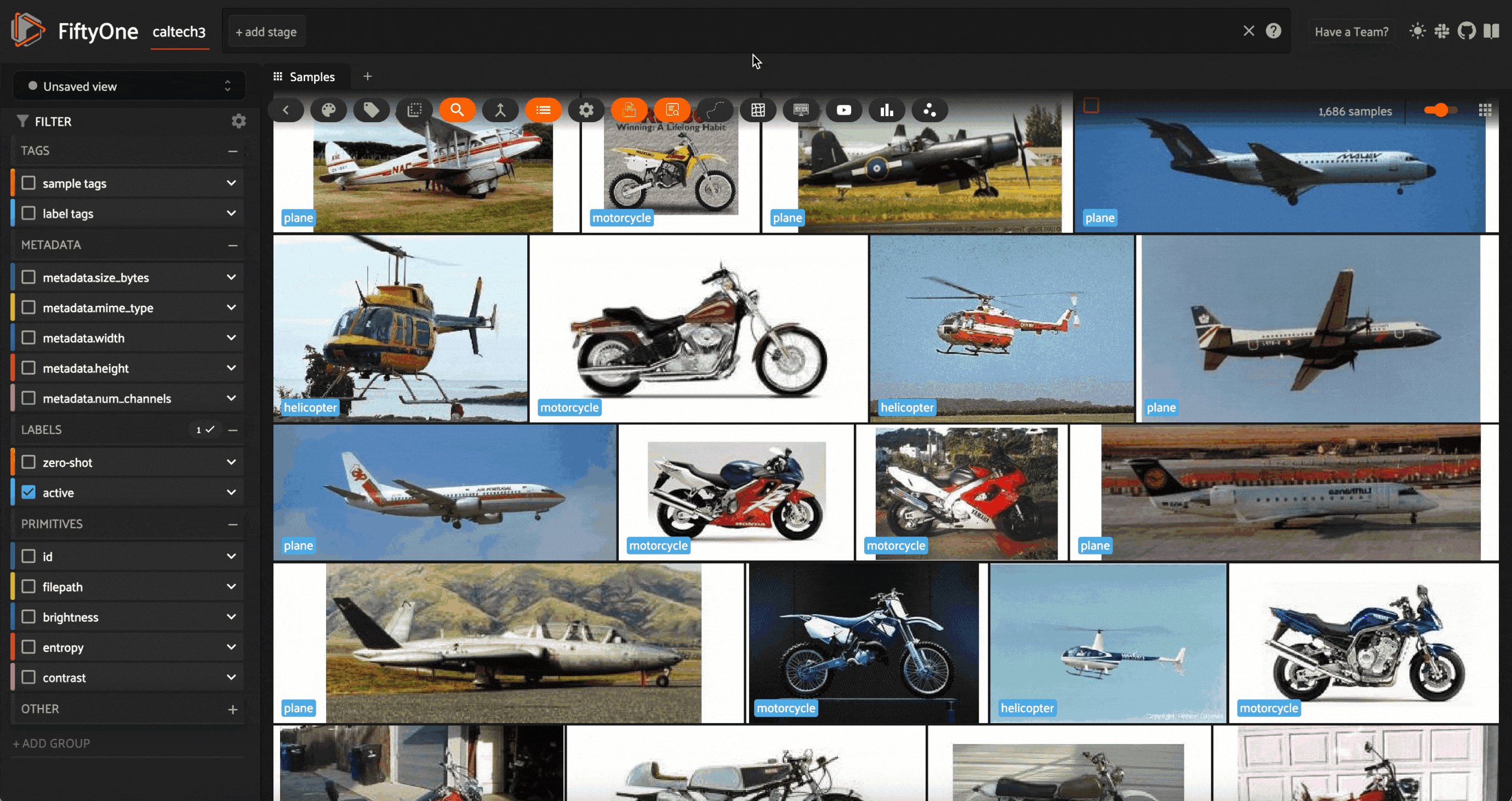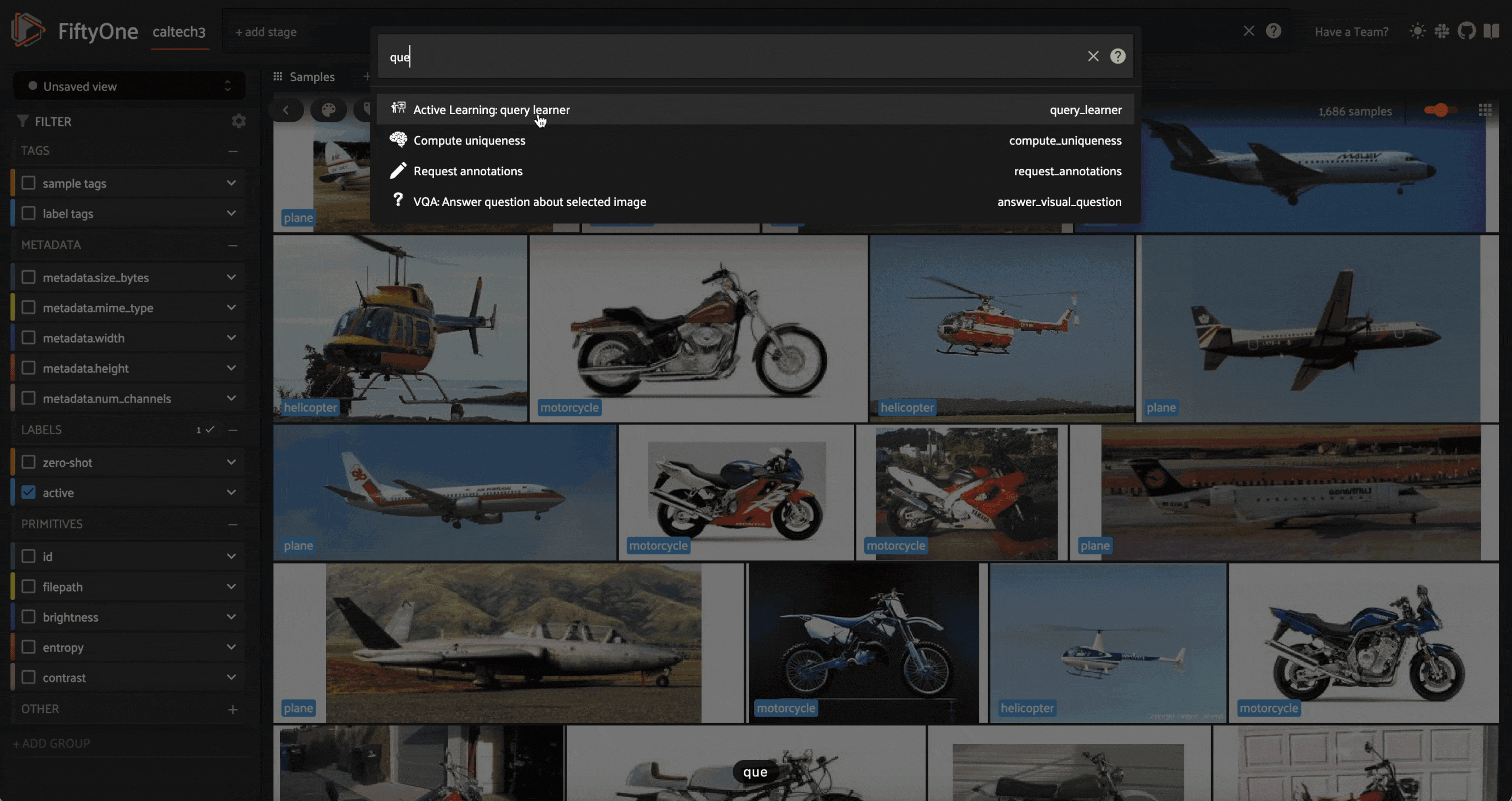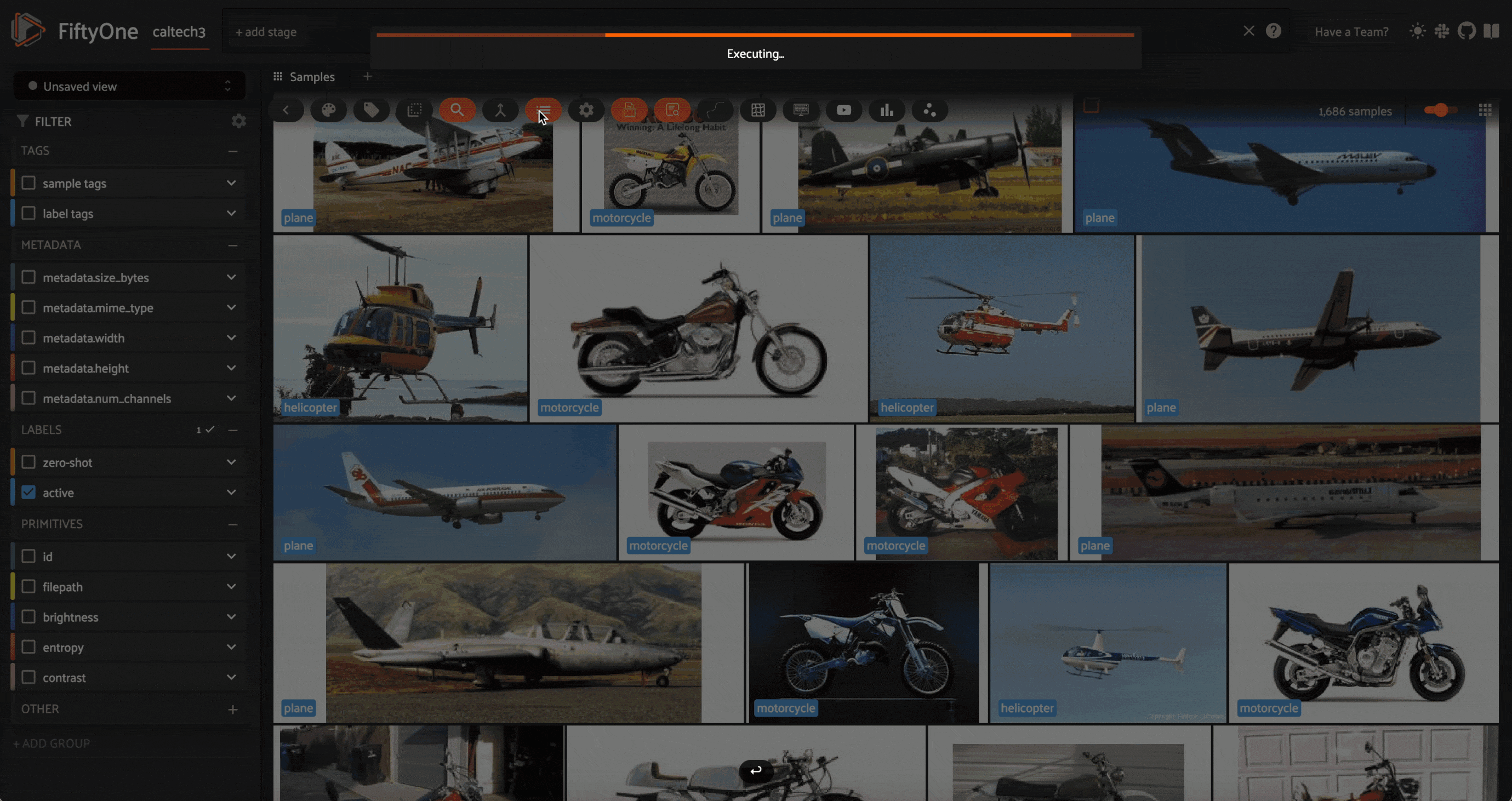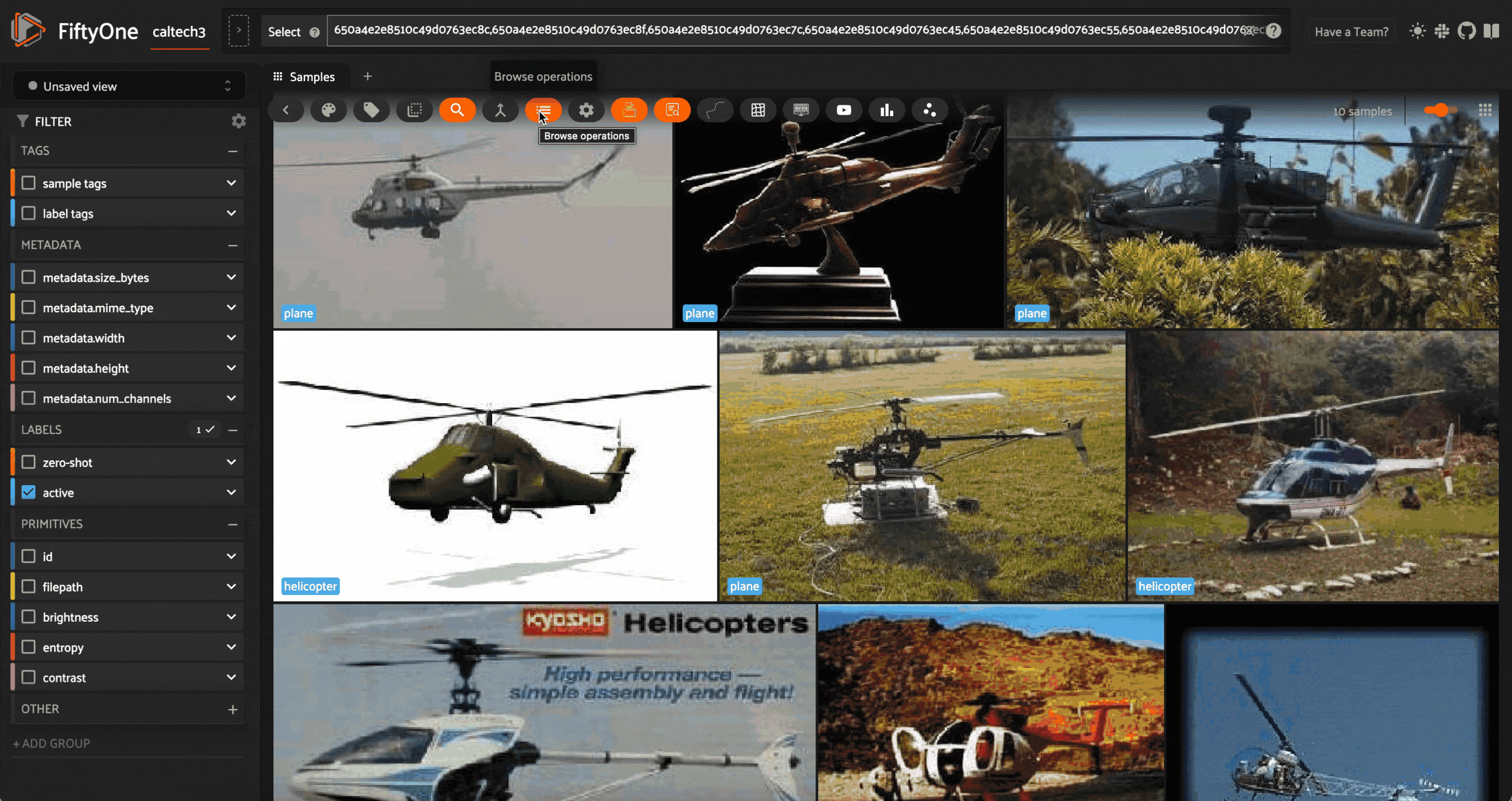
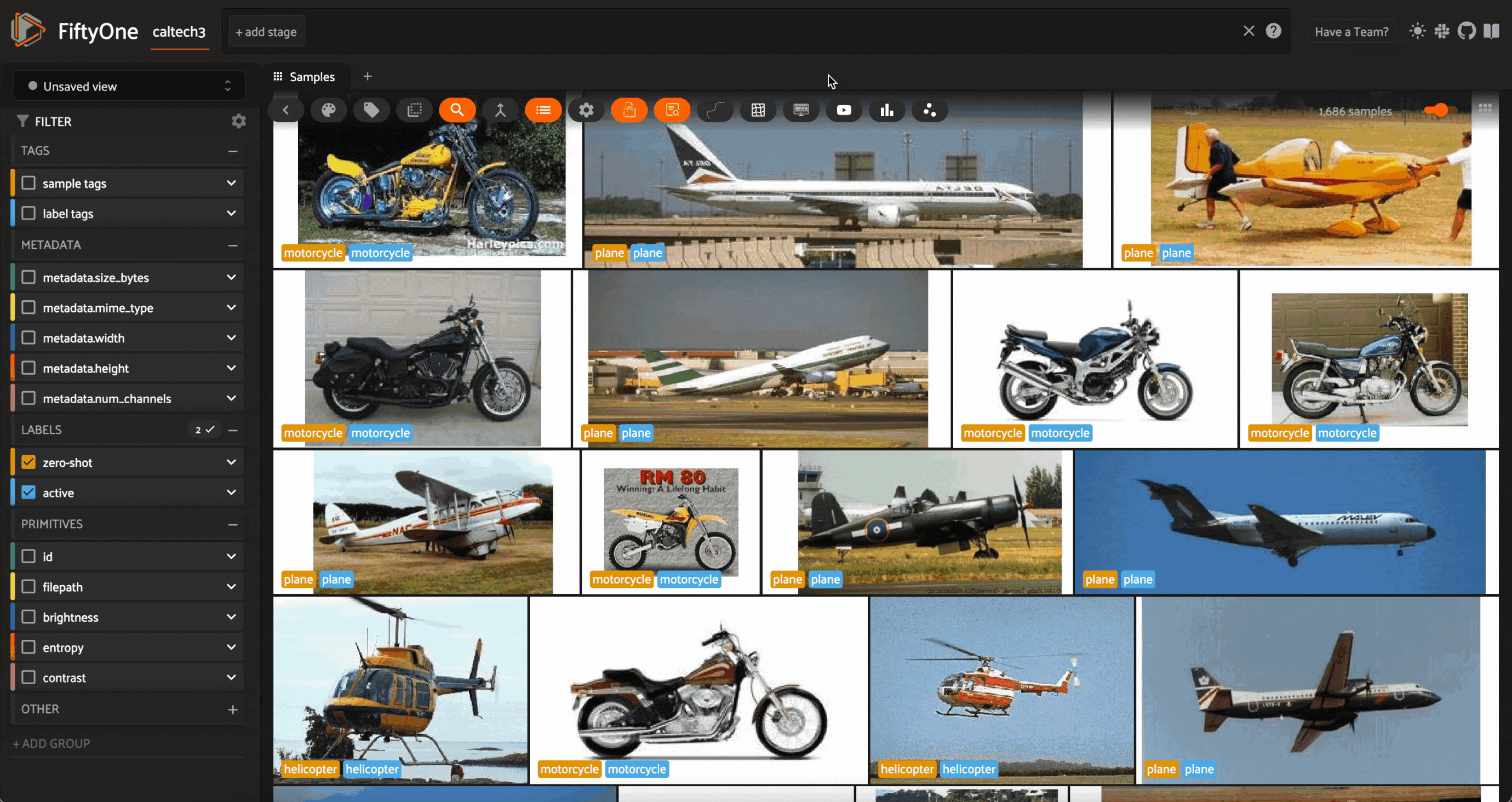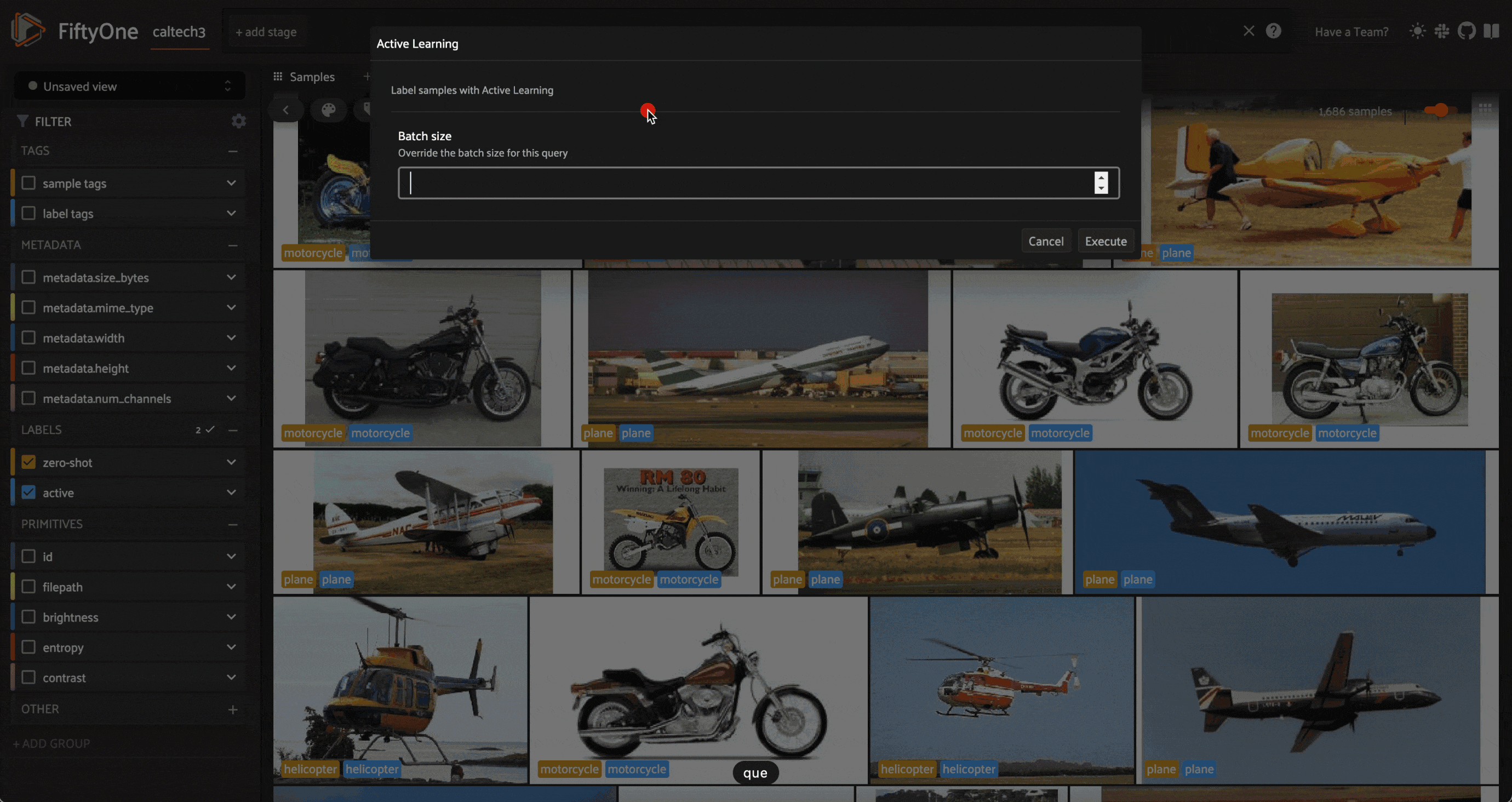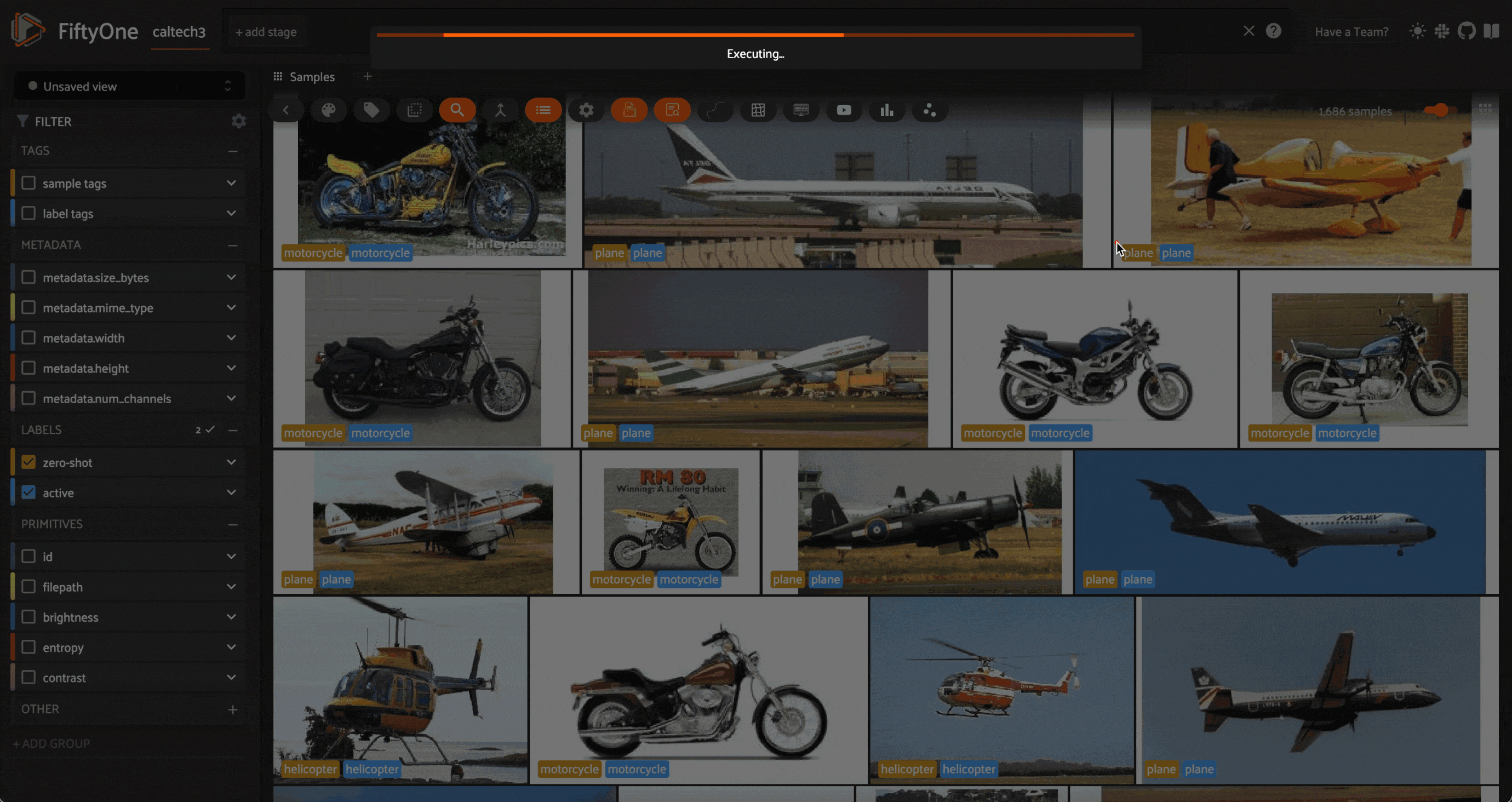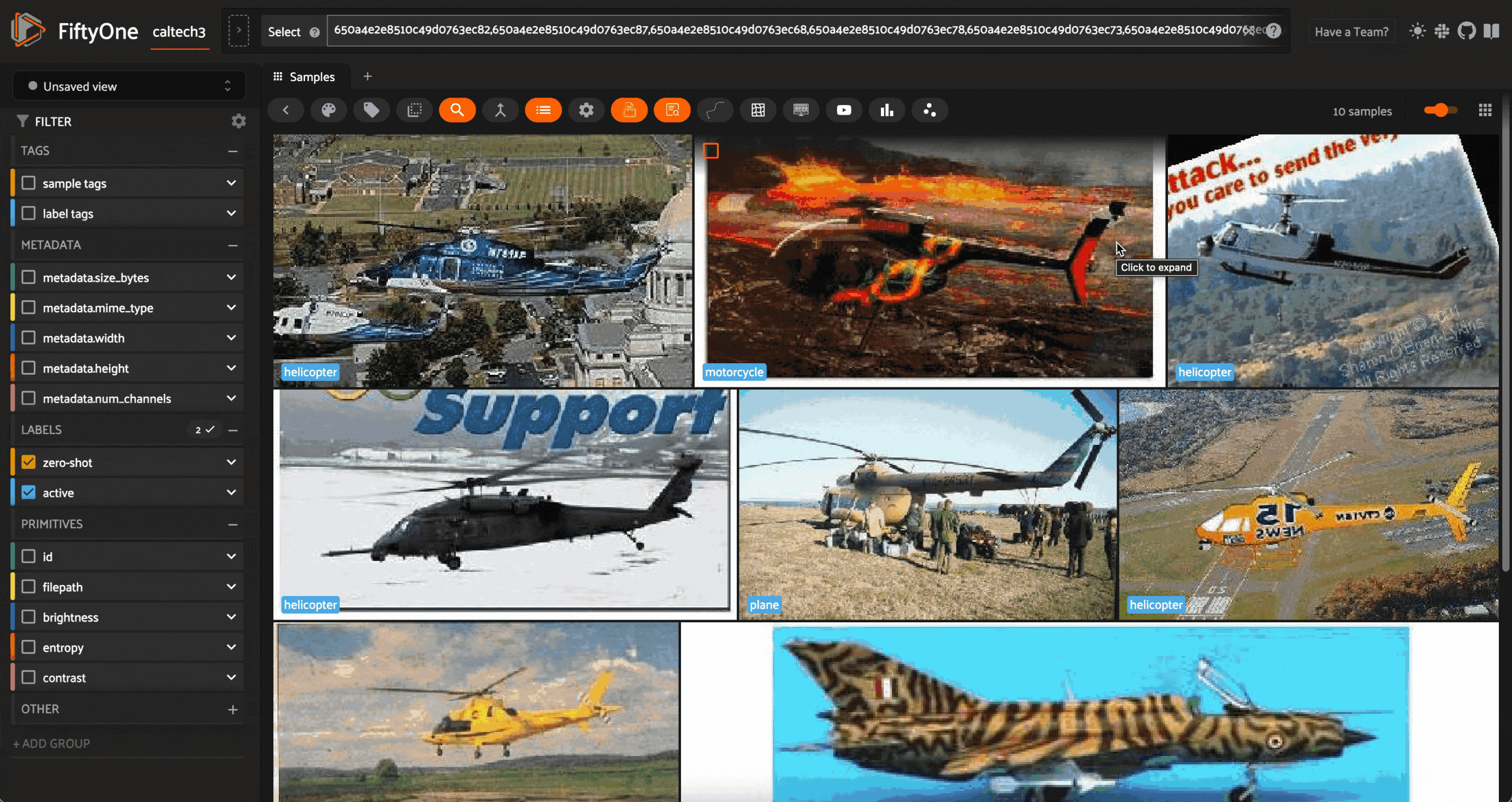
In this case, we can see that the model is least confident about some helicopter images, which it has labeled as a plane. This is likely due to the fact that the dataset has far more planes and motorcycles than helicopters, and helicopters are typically more similar to planes than to motorcycles.
We can then tag the mistakes with the correct labels, either within the app, or by sending these samples for reannotation. For the sake of simplicity, we will do so in the app:
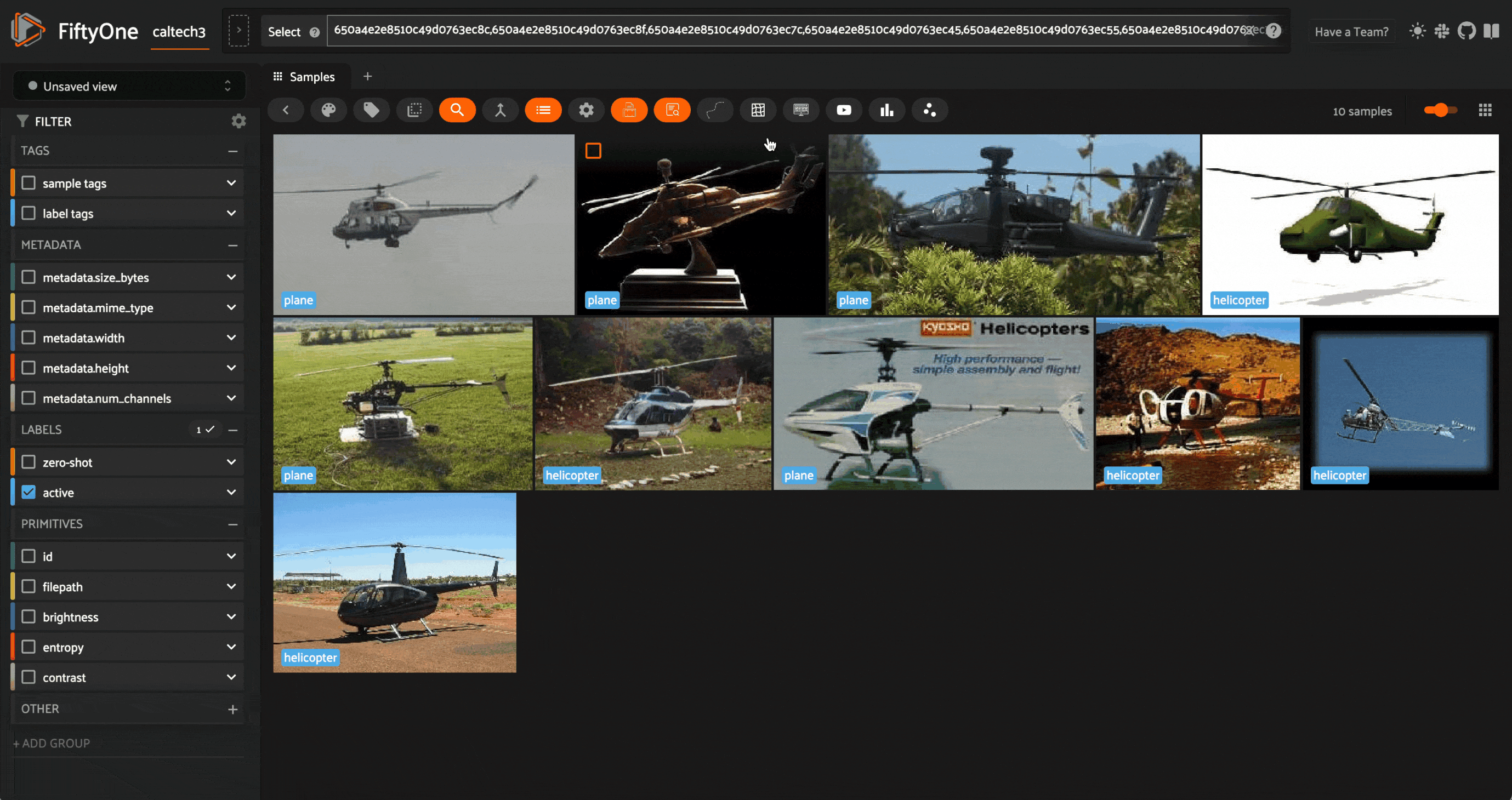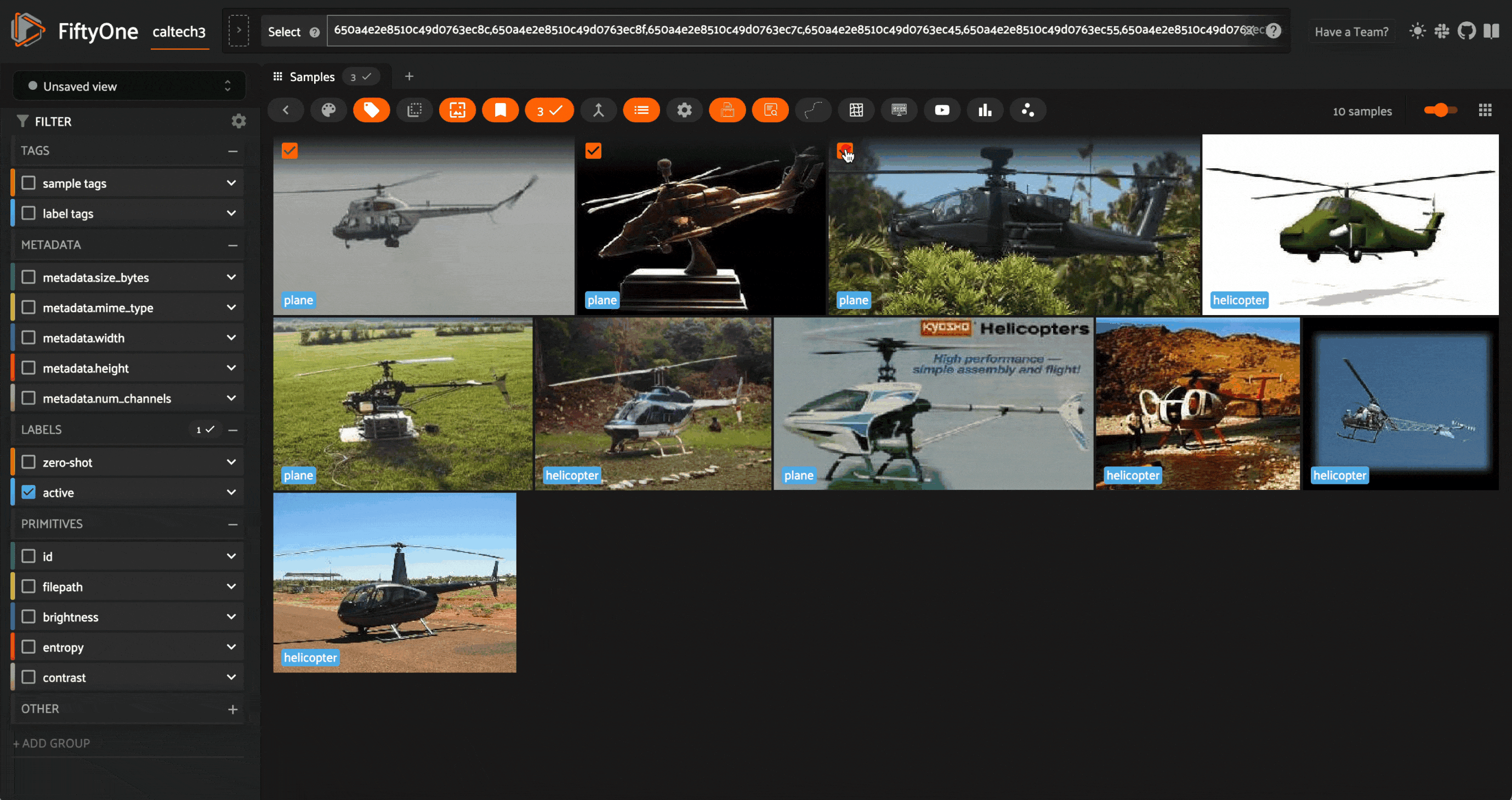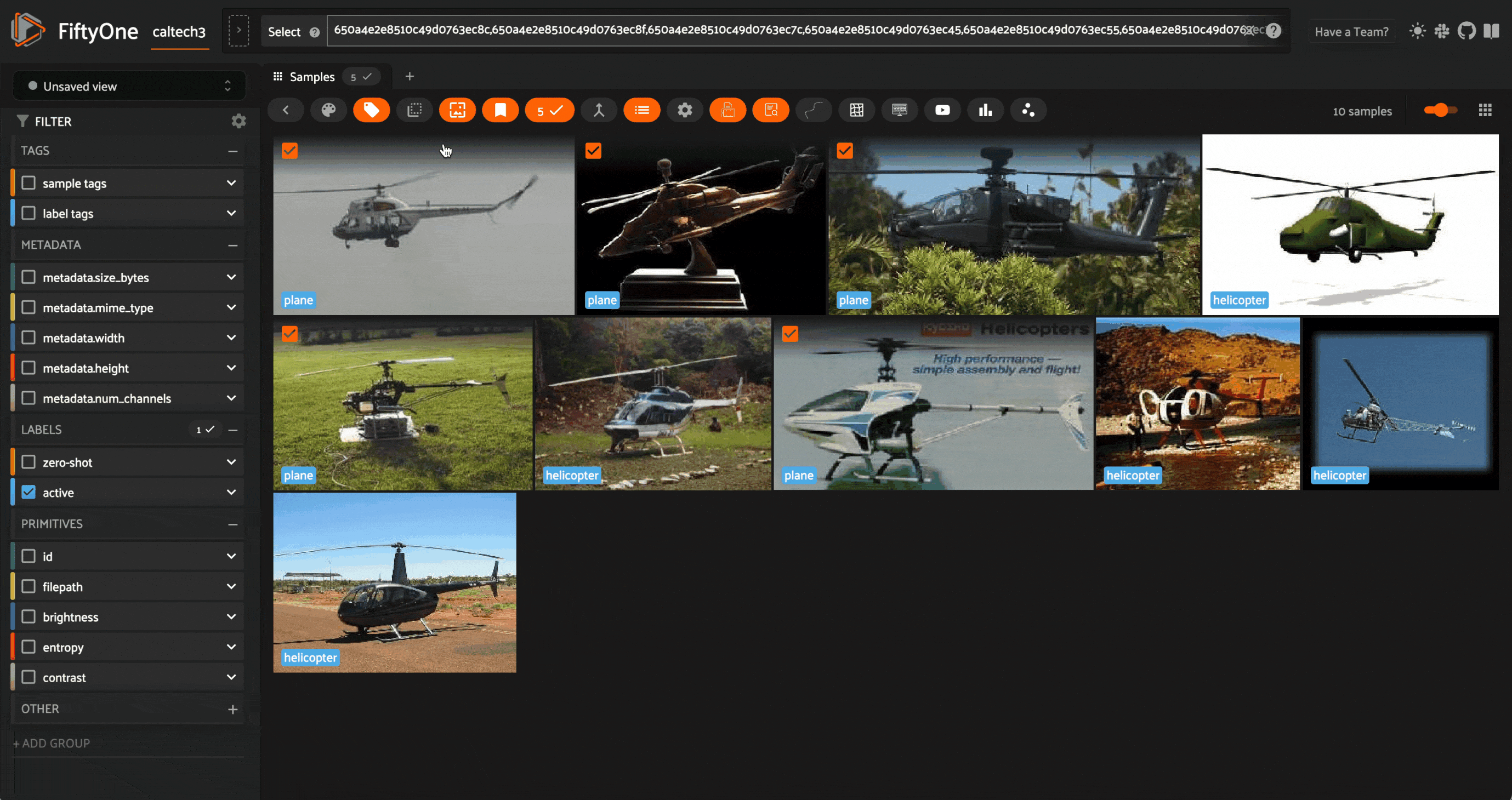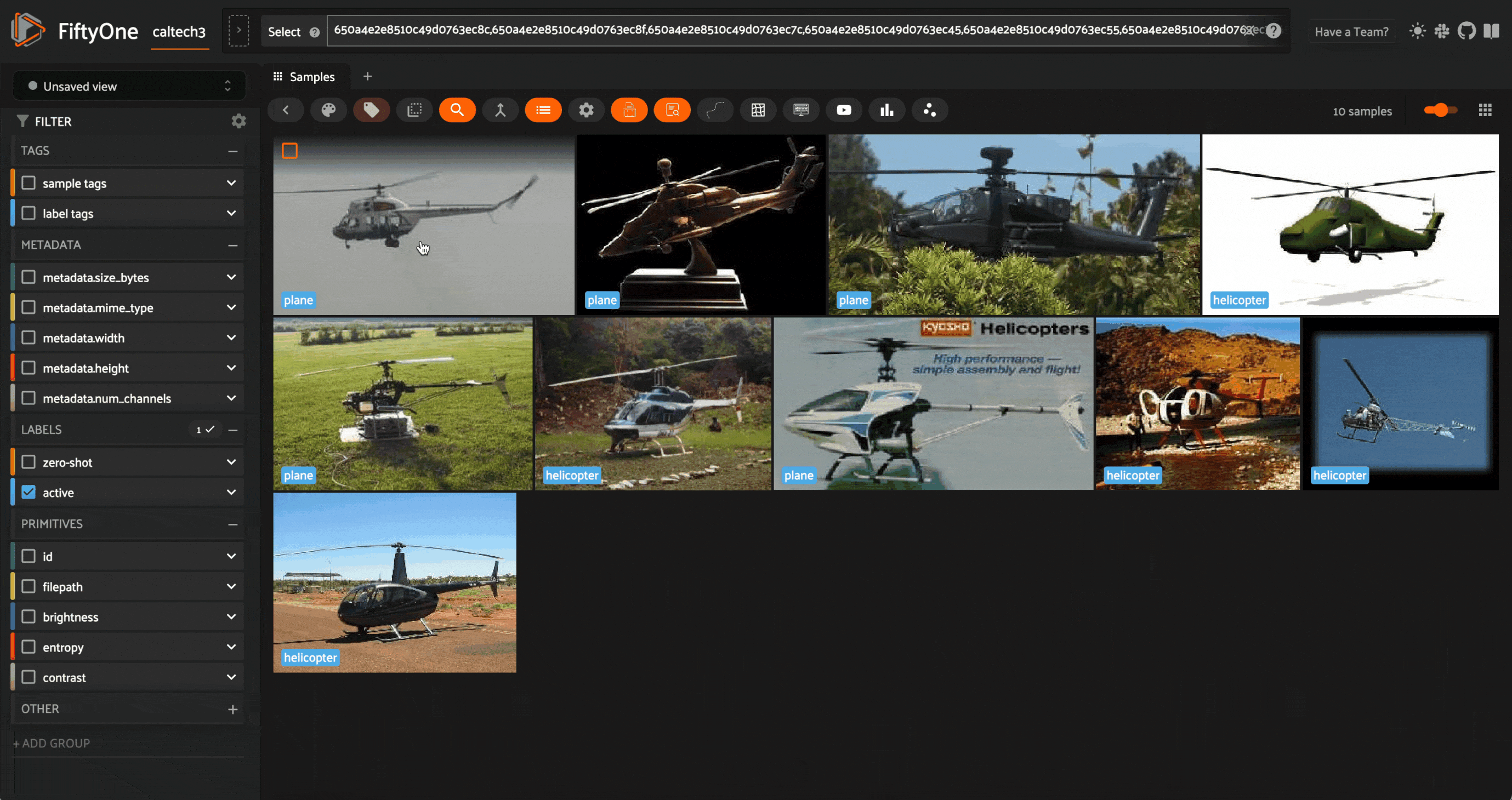
All samples that are not tagged are treated as having the correct labels when used to teach the learner.
Teaching the Active Learner
After correcting the incorrect query labels, we can update our active learner by “teaching” it this new information:
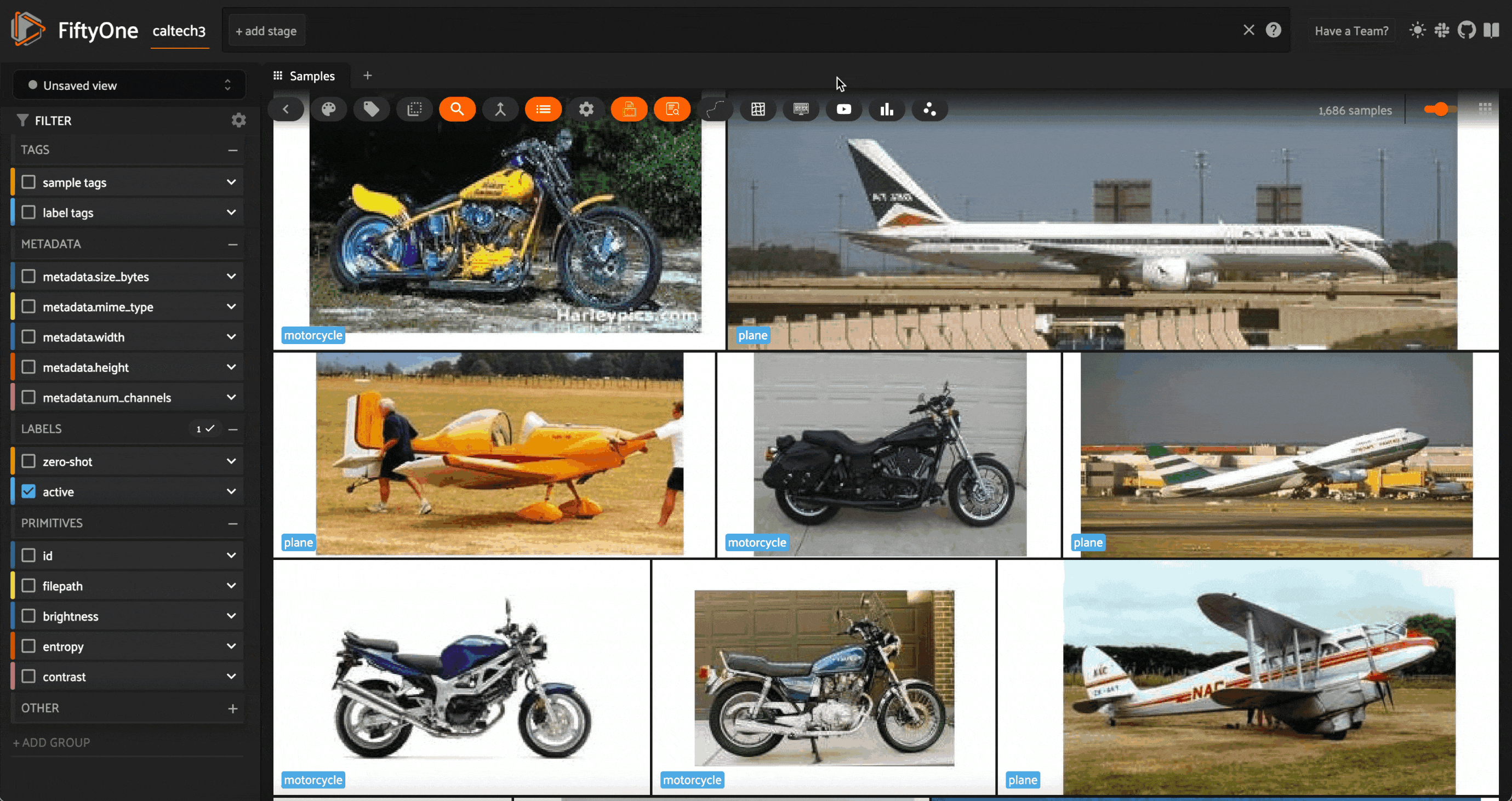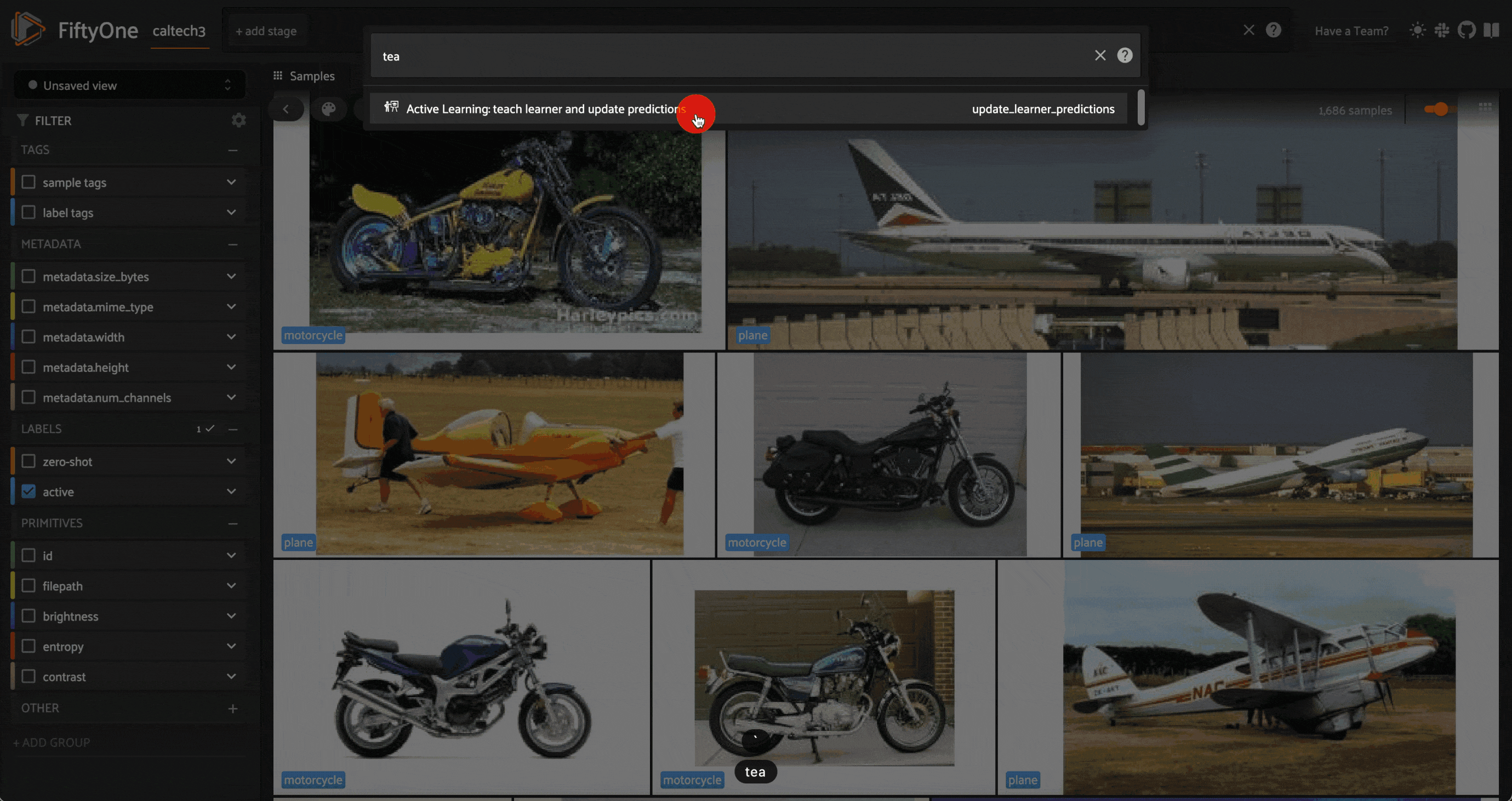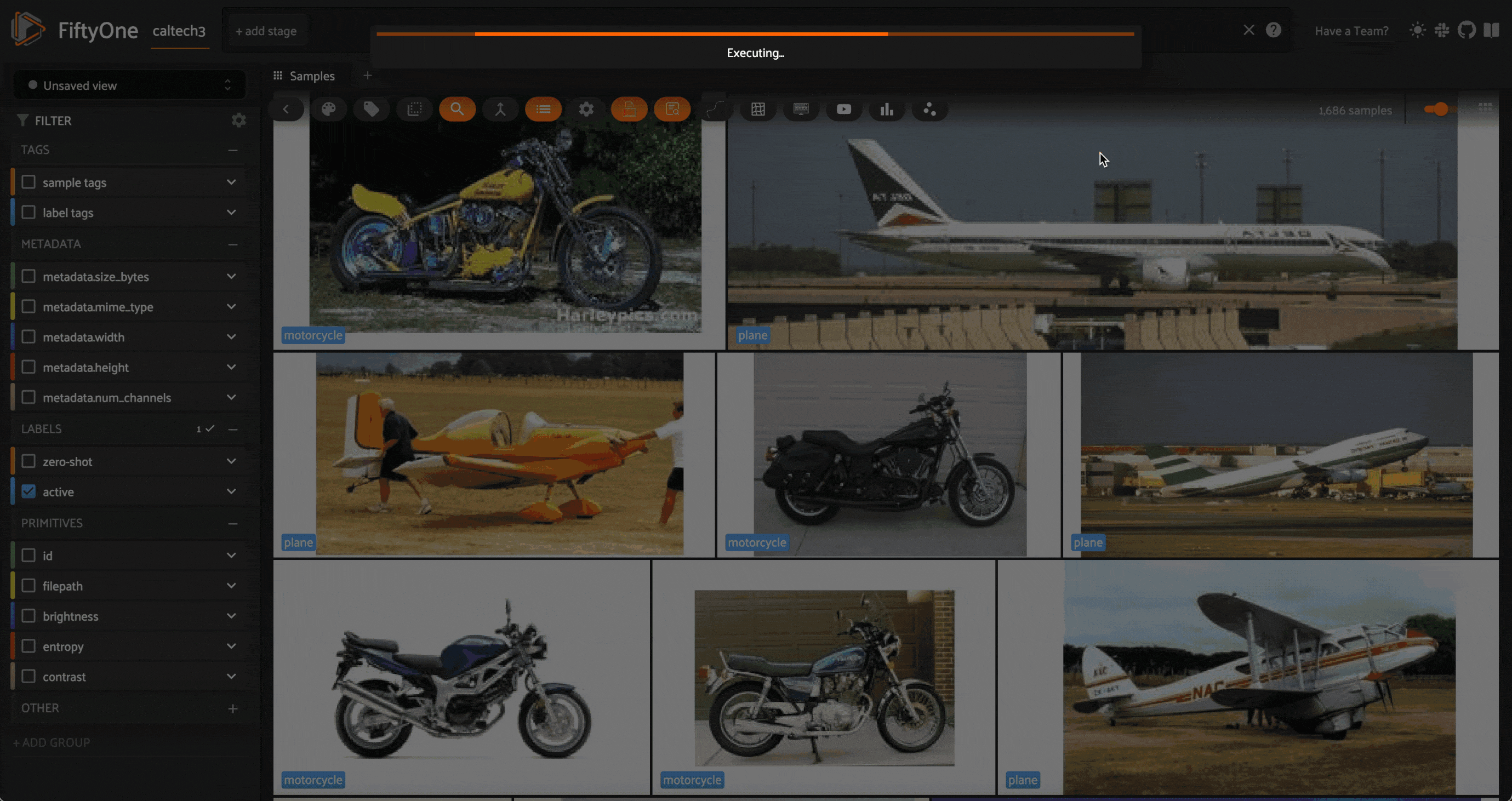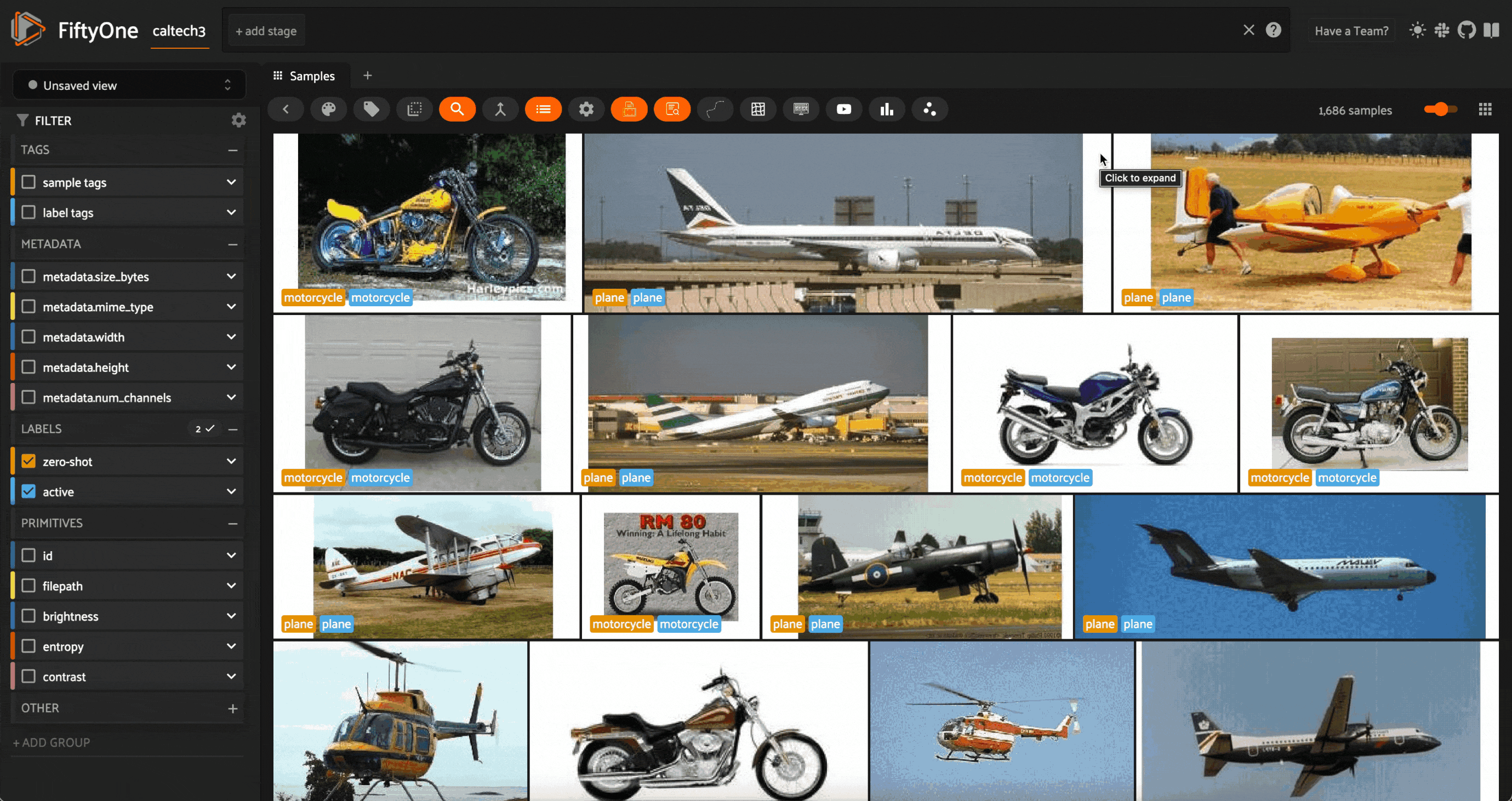
Running this operator updates our active learning model, updates the label field with new predictions, and reloads the app.
If we were to query the learner again, we would see that the samples in this new query are completely different from the samples in the first query:
We can go through this process as many times as we need to until we are confident in our labels. Because this uses uncertainty sampling, rather than random sampling, we should converge to a set of accurate labels very efficiently!
Installing the Plugin
If you haven’t already done so, install FiftyOne:
pip install fiftyone
Then you can download this plugin from the command line with:
fiftyone plugins download https://github.com/jacobmarks/active-learning-plugin
Refresh the FiftyOne App, and you should see the three operators in your operators list when you press the “`” key.
You can install the plugin’s requirements (modAL) by running
fiftyone plugins requirements @jacobmarks/active-learning-plugin --install
Lessons Learned
The Active Learning plugin is a Python Plugin with the usual structure:
_init__.py: defining operatorsfiftyone.yml: registering operatorsREADME.md: explaining the plugin, and giving install instructionsassetsfolder: storeroom for iconsrequirements.txt: list of required Python packages
Additionally, the plugin has an active_learning.py file, which implements the active learning logic using modAL.
Caching is King
This plugin uses the same caching mechanism from the Keyword Search plugin. For keyword search, we were storing a user’s preference, which made the user’s life easier but was not strictly essential. For Active Learning, however, statefulness is critical. The learner is learning, so we need to keep track of its current state, as well as which samples it has seen before.
In theory, this could be done by adding fields onto the dataset to keep track of this information. If you want to implement this version of the Active Learning plugin, I encourage you to do so!!
Don’t Reinvent the Wheel
When I set out to make an Active Learning plugin, I initially tried to implement everything from scratch. Sometimes this is necessary. But in other cases, including this one, robust solutions already exist.
FiftyOne is flexible enough to bend and weave into workflows with tons of existing tools. Rather than spending your time reinventing the wheel, integrate these libraries into your FiftyOne Plugins so you can combine the strengths of other special-purpose libraries with FiftyOne’s data management and visualization infrastructure!
Conclusion
In the fast-paced world of machine learning and computer vision, efficiency and effectiveness are of the essence. By intelligently selecting the most crucial samples for labeling, this plugin will help you save time, reduce costs, and enhance the overall quality of your models. Happy learning!
Stay tuned over the remaining weeks in the Ten Weeks of FiftyOne Plugins while we continue to pump out a killer lineup of plugins! You can track our journey in our ten-weeks-of-plugins repo — and I encourage you to fork the repo and join me on this journey!

