Forging your own path as a novice ML engineer is a tumultuous journey with numerous obstacles to overcome. Regardless of where you currently stand in this adventure, you’re likely all too familiar with the feeling of investing countless hours into configuring data, creating bug-free evaluation scripts, or engaging in a relentless struggle to improve model accuracy by a mere one or two percent. However, after spending a week at Voxel51 and taking my first step into the world of FiftyOne, the open source toolkit for building high-quality datasets and computer vision models, I was astonished to discover how many of those hours I could instantly reclaim. In just five minutes, I will demonstrate three easy ways FiftyOne can save you hours, if not days, of work within your computer vision ML workflow.
Data Curation
The best way to start your workflow is with the piece of mind that the data you’re working with is formatted correctly and not corrupted. Images sideways or upside down? Labels off by one? How often do ML engineers even look at their dataset before training, outside maybe the first one or two images? Loading data into FiftyOne and having the sanity check that the data is up to standard is a great first step in your ML workflow. With a single snippet of code, FiftyOne can present your data in a clean and intuitive way.
import fiftyone as fo # The directory containing the dataset to import dataset_dir = "/path/to/dataset" # The type of the dataset being imported dataset_type = fo.types.COCODetectionDataset # for example # Import the dataset dataset = fo.Dataset.from_dir( dataset_dir=dataset_dir, dataset_type=dataset_type, ) session = fo.launch_app(dataset)
FiftyOne leverages powerful data ingestors so you can import datasets in more than 28(!) different formats ranging over all the most popular classification, detection, segmentation, and 3D data types. The tool even allows you to export datasets to any type for quick conversions from for example COCO to KITTI. With a quick spot check of your ground truths, FiftyOne can save immense amounts of time dealing with potential headaches down the line.
Model Evaluation in an Instant
There is no frustration like writing out a whole script only for the model or data type to change, forcing you to have to start all over again. Once again, I was blown away by how FiftyOne simplifies this entire process. After inferencing through your samples in your dataset, with FiftyOne you can easily add predictions to samples and evaluate them. FiftyOne provides a variety of builtin methods for evaluating model predictions, including regressions, classifications, detections, polygons, instance, and semantic segmentations. No more corralling detections or mass reformatting ground truth labels. Here you can see that evaluating detections, for example, with FiftyOne is as easy as four lines of code to get high quality evaluation results.
detections.append(
fo.Detection(
label=classes[label],
bounding_box=rel_box,
confidence=score
)
)
# Save predictions to dataset
sample["faster_rcnn"] = fo.Detections(detections=detections)
sample.save()
results = dataset.evaluate_detections(
"faster_rcnn",
gt_field="ground_truth",
eval_key="eval",
compute_mAP=True,
)
Results can even be presented in several ways to get full insight into your evaluation. For example, want the mAP of the results? Just ask:
print(results.mAP())
0.3941499578463119
Do you want the top 10 classes classification results? Easy:
# Get the 10 most common classes in the dataset
counts = dataset.count_values("ground_truth.detections.label")
classes_top10 = sorted(counts, key=counts.get, reverse=True)[:10]
# Print a classification report for the top-10 classes
results.print_report(classes=classes_top10)
precision recall f1-score support person 0.89 0.73 0.80 287 car 0.76 0.65 0.70 40 chair 0.36 0.27 0.31 15 book 0.64 0.31 0.42 45 bottle 0.90 0.75 0.82 36 cup 0.67 0.67 0.67 6 dining table 0.33 0.29 0.31 7 traffic light 0.60 0.38 0.46 16 bowl 0.71 0.71 0.71 7 handbag 1.00 0.09 0.17 11 micro avg 0.83 0.63 0.72 470 macro avg 0.69 0.48 0.54 470 weighted avg 0.82 0.63 0.71 470
All of this and more can be achieved by adding just a few extra lines to your existing scripts. You can find additional resources on achieving your ideal model evaluation workflow in the docs.
Finding Mistakes in Your Data
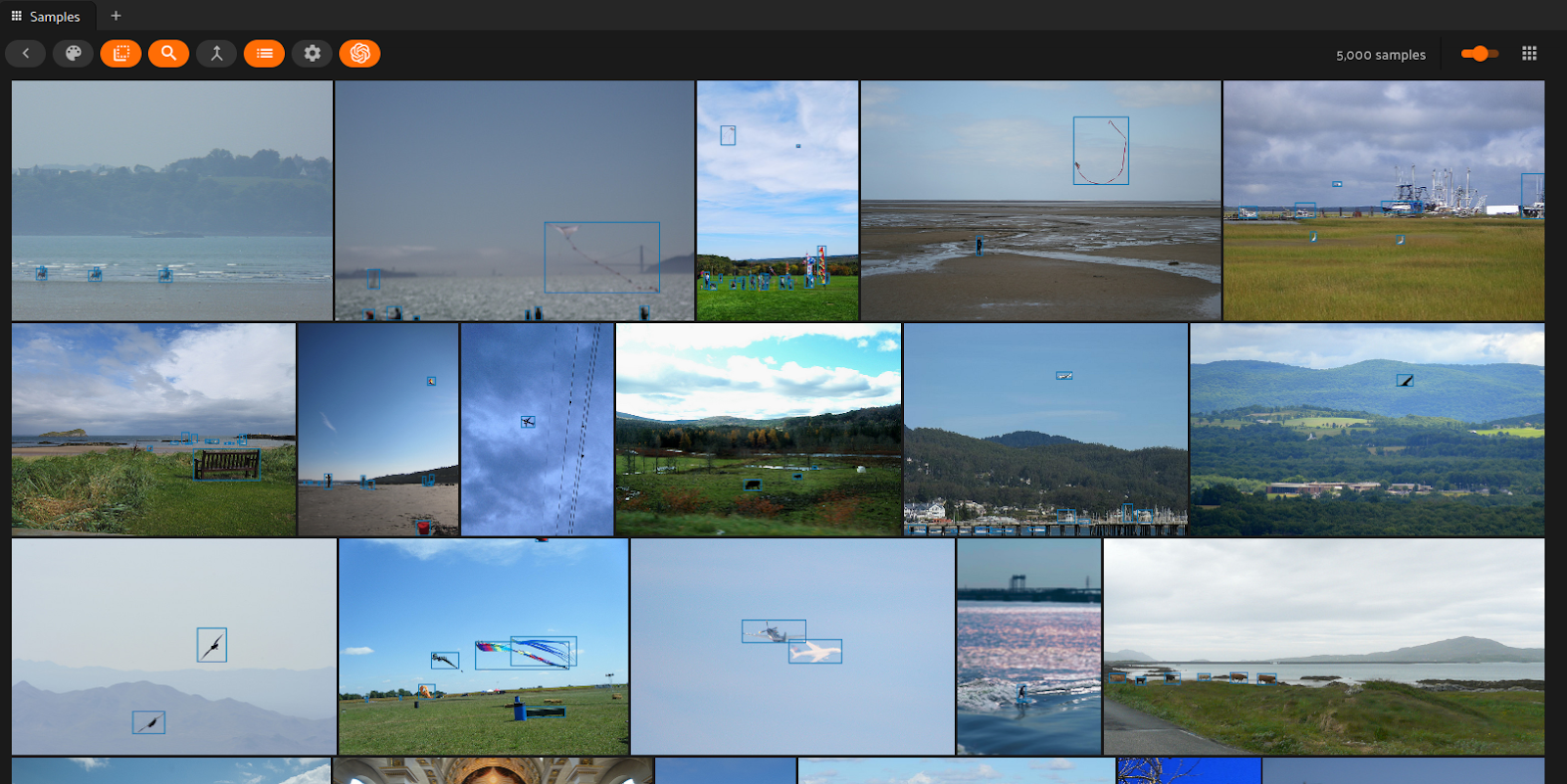
This last highlight is one that every ML engineer can benefit from. When you are fighting for that last one or two percent of accuracy on your model, and you have tweaked every hyperparameter imaginable, it is important not to underestimate the impact of data quality. Sitting on thousands if not millions of samples, sprinkled in there are labeling mistakes or duplicates. By hand they would be impossible to catch. But with FiftyOne’s builtin Brain technology, entire datasets can be inspected for any troublesome samples. For example, to find duplicates, use FiftyOne Brain’s compute_uniqueness() method:
import fiftyone.brain as fob
fob.compute_uniqueness(dataset)
# Sort in increasing order of uniqueness (least unique first)
dups_view = dataset.sort_by("uniqueness")
# Open view in the App
session.view = dups_view
Next if you want to find let’s say detection mistakes, use FiftyOne Brain’s compute_mistakenness() method:
from fiftyone import ViewField as F
fob.compute_mistakenness(dataset, "predictions", label_field="ground_truth")
# Sort by likelihood of mistake (most likely first)
mistake_view = dataset.sort_by("mistakenness", reverse=True)
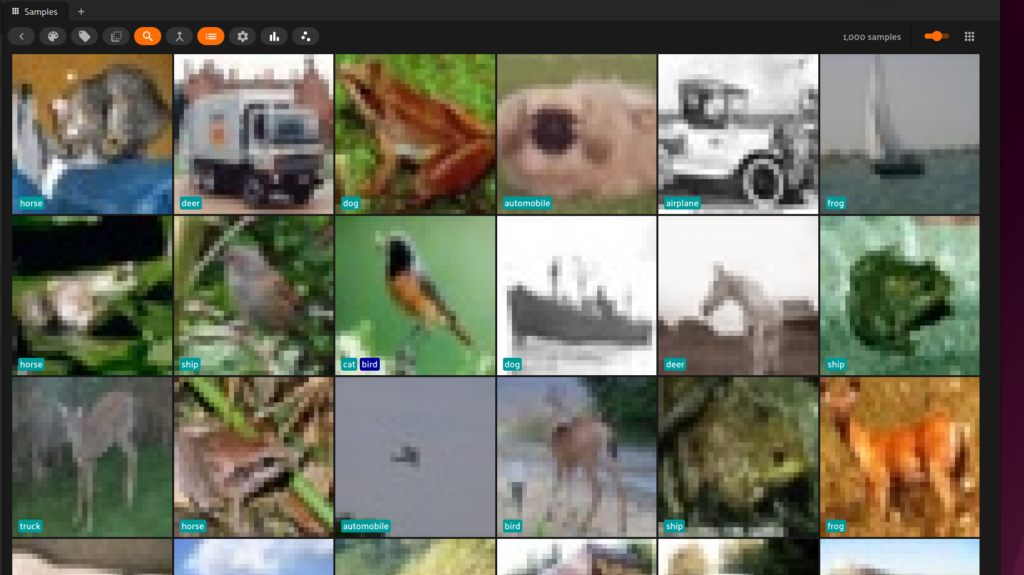
It can not be understated how game changing this is. Any dataset can be transformed to the highest quality easily with no custom scripts. Poor annotations can even be tagged and automatically sent to CVAT (here’s a FiftyOne+CVAT tutorial on how to do that) or another annotation tool of your choice in a matter of seconds after finding them.
tagged_view = dataset.match_tags("requires_annotation")
anno_key = "tagged_anno"
tagged_view.annotate(anno_key, label_field="ground_truth", launch_editor=True)
Join the FiftyOne Community!
Join the thousands of engineers and data scientists already using FiftyOne to solve some of the most challenging problems in computer vision today!
- 2,000+ FiftyOne Slack members
- 4,000+ stars on GitHub
- 5,000+ Meetup members
- Used by 360+ repositories
- 60+ contributors

