Last Thursday, Voxel51 hosted the March 2023 Computer Vision Meetup. In this blog post you’ll find the playback recordings, highlights from the presentations and Q&A, as well as the upcoming Meetup and events schedule so that you can join us in the future.
First, Thanks for Voting for Your Favorite Charity!
In lieu of swag, we gave Meetup attendees the opportunity to help guide our monthly donation to charitable causes. The charity that received the highest number of votes this month was The Foundation Fighting Blindness. We are sending this month’s charitable donation of $200 to them on behalf of the computer vision community!
Computer Vision Meetup Recap at a Glance
Jiajing Chen // Why Discard if You can Recycle?: A Recycling Max Pooling Module for 3D Point Cloud Analysis
Soumik Rakshit // Lighting Up Images in the Deep Learning Era
Sumanth P // Taking Computer Vision Models in Notebooks to Production
Next steps
- Computer Vision Meetup Locations
- Upcoming Computer Vision Meetup Speakers — April and May
- Get Involved!
Why Discard if You can Recycle?: A Recycling Max Pooling Module for 3D Point Cloud Analysis
Video replay
Presentation Summary
Jiajing Chen, a PhD student from Syracuse University, presents on this topic and research: Why Discard If You Can Recycle: A Recycling Max Pooling Module for 3D Point Cloud Analysis.
Jiajing opens up by explaining what 3D point cloud data is and where it comes from, along with ways to apply machine learning techniques to point clouds: classification, object detection, and segmentation.

Next, Jiajing shows a general network architecture of most point-based models and then explains how the limitations of traditional approaches motivated his work.
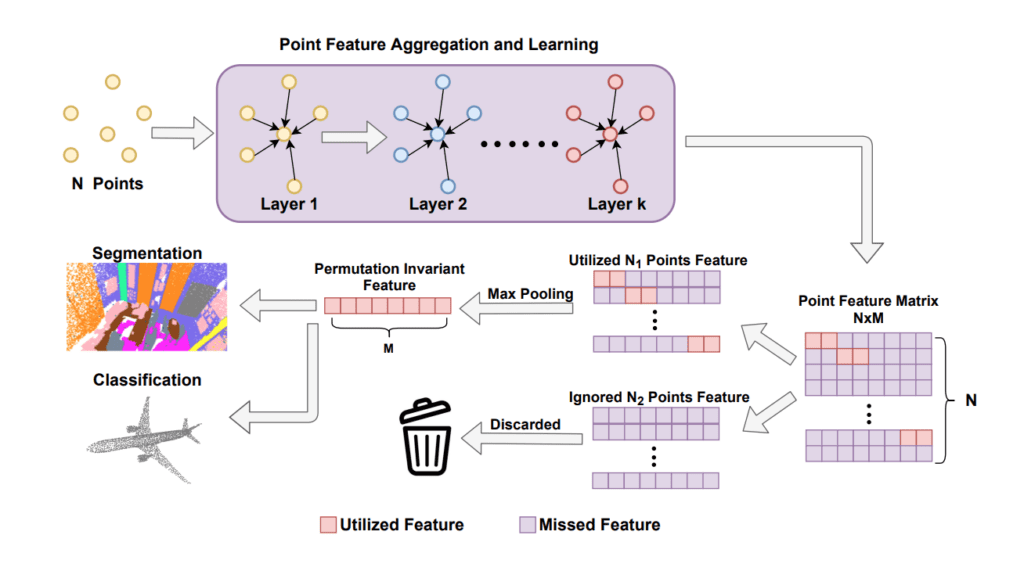
- Most 3D point cloud analysis models have focused on developing different point feature learning and neighbor feature aggregation modules
- One common theme with most of the existing approaches is their use of max-pooling to obtain permutation invariant features
- Yet traditional max-pooling causes only a fraction of 3D points (red boxes) to contribute to the permutation invariant features and discards the rest (all purple rows)
Jiajing, along with colleagues, set out on a research journey to see if they could find a way to recycle those discarded points to make the original network’s performance better. And indeed, they did! The research (available here) has shown that recycling the still useful discarded points can improve the original network’s performance. In the rest of the talk, Jiajing explains the series of experiments that were conducted, the key observations they made along the way, and the new proposed method for a recycling max pooling module.
In the first experiment, Jiajing and his colleagues set out to verify whether or not the number of utilized points has a correlation with the final accuracy. They selected three milestone networks for the experiments, PointNet, PointNet++, and DGCNN, and studied point utilization during prediction, both before training and after training. What they found was that at the end of the training the number of points kept after the max-pooling increased. Therefore the first key observation was: prediction accuracy is positively correlated with the point utilization percentage, indicating that recycling the discarded points has promise. (You can watch this part of the presentation from ~4:11 – 6:05 in the video playback.)
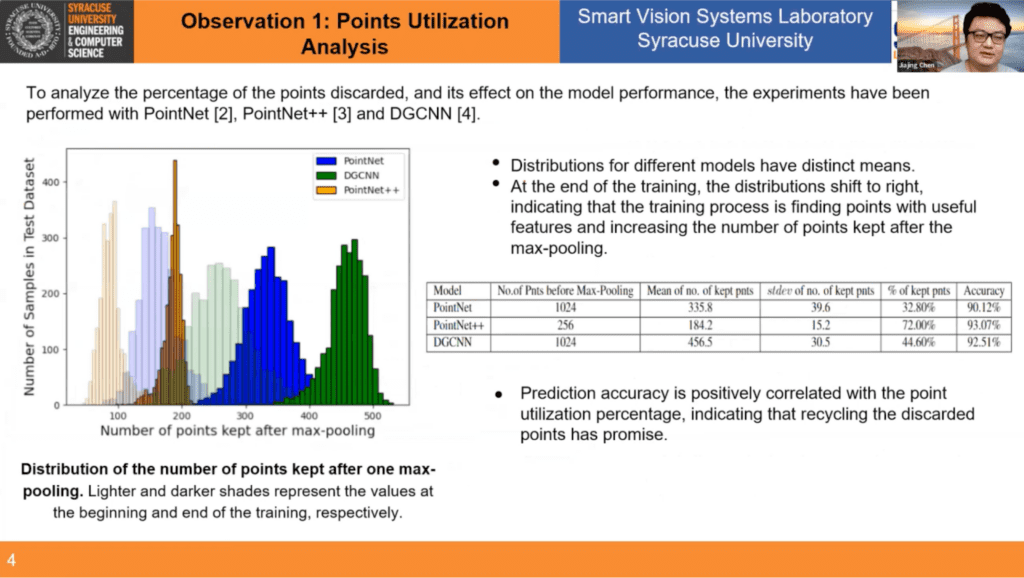
Moving onto the second observation, analysis of the potential of discarded points, Jiajing presents the information to us NFL-play-by-play style (which you can watch from ~6:05 – 8:49 in the video playback). The research team ultimately observes that applying recycling to max pooling (shown in the slide below as F2 and F3) does result in a drop in accuracy, but it’s not really that much, which means these discarded points indeed do have useful features that should be recycled.
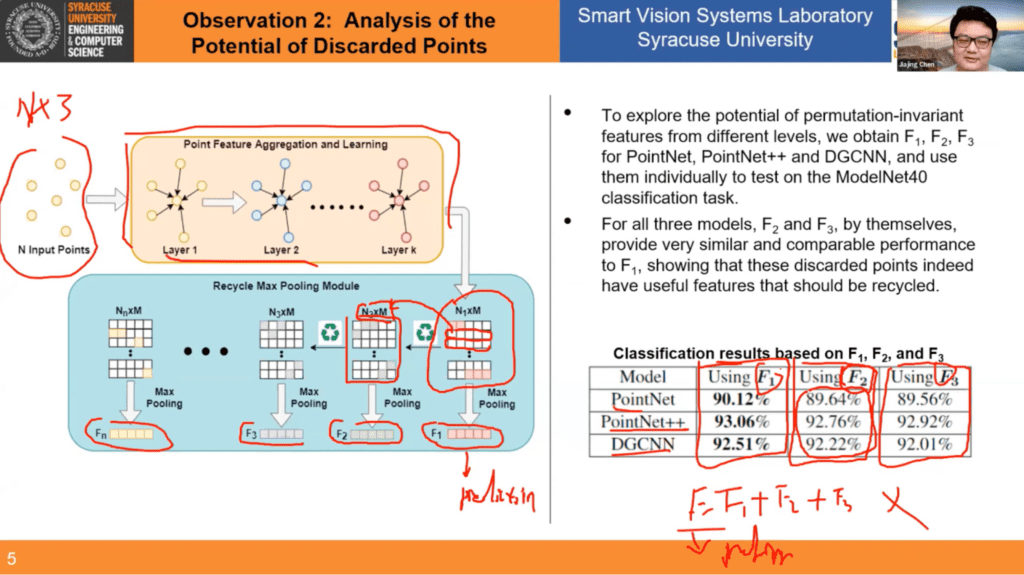
Next, Jiajing gives us an in-depth tour of the proposed method: a new module, referred to as the Recycling Max-Pooling (RMP) module, to recycle and utilize the features of some of the discarded points (you can watch the replay from ~8:59 to 12:48 in the video).
Finally, Jiajing shares the experiment results to show us how the RMP module performed (from ~12:48 – 14:15 in the video playback).
The first round of experiments were performed on ScanObjectNN and ModelNet40 datasets for the point cloud classification task across a variety of milestone networks and state-of-the-art networks (PointNet, PointNet++, DGCNN, GDANet, DPFA, and CurveNet). Applying the RMP module resulted in performance improvements for all networks.
Experiments were also performed for the point cloud segmentation task using the S3DIS dataset. This dataset is an indoor dataset that contains six areas covering about 271 rooms and each point belongs to one of 13 classes. The experiments were performed on the PointNet, DGCNN, and DPFA networks by applying the RMP module to them (and comparing the results to the experiments without the RMP module applied). The RMP module brought improvements in overall accuracy and the mean IoU!
Additional Resources
Check out the additional resources on the presentation:
Thank you Jiajing for sharing your research and information about the recycling max pooling module for 3D point clouds with us!
Lighting Up Images in the Deep Learning Era
Video Replay
Presentation Summary
Soumik Rakshit, Machine Learning Engineer at Weights & Biases, gives a talk on image restoration, with a focus on how low light enhancement is addressed in the deep learning era.
Why do we need to lighten up images at all? Soumik answers: images are often taken under sub-optimal lighting conditions, in uneven light, dim light, and in scenarios where the light is shining from behind the subject (backlit subjects). He further explains: “it turns out that such poorly lit images suffer a lot from not just compromised aesthetic quality, but also from diminished performance on high level computer tasks like object detection, object recognition, image segmentation, and other operations.”
Soumik provides examples of how low light enhancements can be used in computer vision. First he shows how applying YOLOv8-large on a lightened image resulted in more detected objects than applying YOLOv8-large on the original low light image. Other applications for low light image enhancements are: visual surveillance, autonomous driving, and computational photography – in particular, smartphone photography, where it’s possible to turn your device into a night-vision system.
Traditional methods for low light enhancement can be broadly categorized as Histogram Equalization and Retinex Models. But these traditional methods have some limitations: they are noisy, have high computational complexity, and require manual tweaking.
Deep learning offers promise for improvements over traditional methods. Since the publication of LLNet in 2017, recent years have witnessed the compelling success of deep learning-based approaches for low light image enhancement.
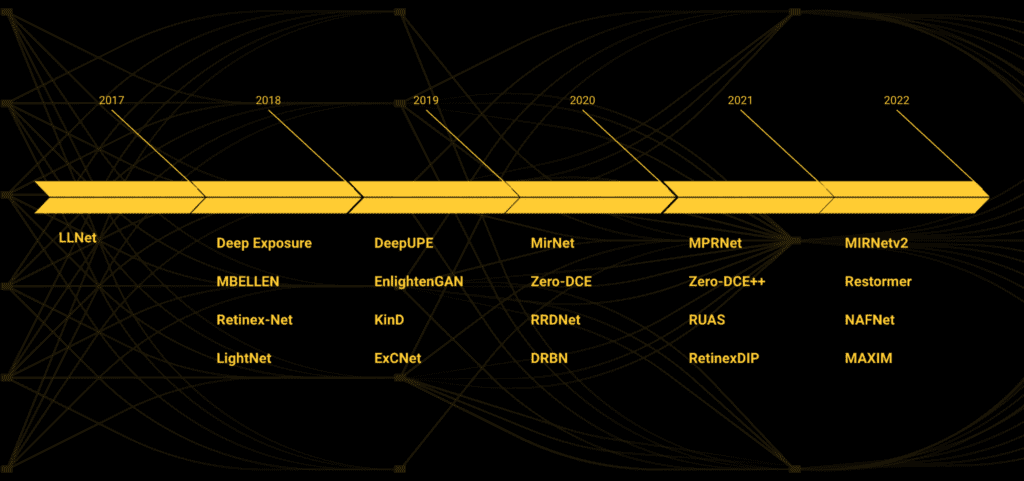
In the rest of talk, Soumik explores three of the models listed in the image above (MIRNet-v2, NAFNet, and Zero-DCE), including their architectures, as well as how to train them, evaluate them, and see how they perform on a few real-world images.
But first, Soumik notes that the process starts with a dataset: the LoL dataset or LOw Light paired dataset [Original Source | Kaggle Dataset] which was created for training supervised models for low-light image enhancements. This dataset provides 485 images for training and 15 for testing. Each image pair in the dataset consists of a low light input image and its corresponding well-exposed reference image.
Soumik builds out an input pipeline on the LoL dataset using restorers and wandb. Restorers is an open source tool written using TensorFlow and Keras that provides out-of-the-box TensorFlow implementations of state-of-the-art (SOTA) image and video restoration models for tasks such as low light enhancement, denoising, deblurring, super-resolution, and more. Weights & Biases (wandb) is an open source tool for visualizing and tracking your machine learning experiments.
Now, Soumik dives into three models.
“MIRNet-v2, as proposed by the paper Learning Enriched Features for Fast Image Restoration and Enhancement is a fully convolutional architecture that learns enriched feature representations for image restoration and enhancement. It is based on a recursive residual design with the multi-scale residual block or MRB at its core.”[1]
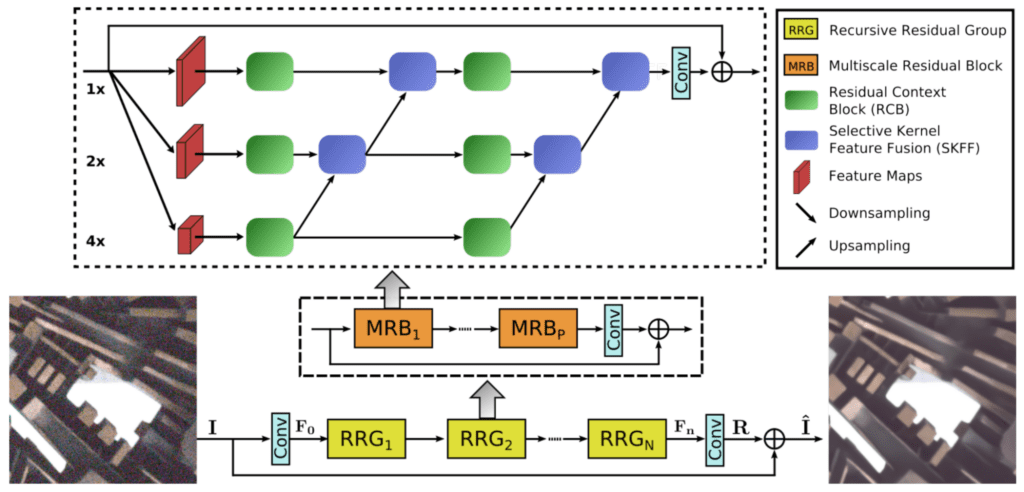
To watch Soumik train the MIRNet-v2 model for low-light enhancement model using restorers and wandb, visit this portion of the video playback: ~14:29 – 24:07. For the code, you can refer to this Colab notebook.
Next, Soumik explains what the NAFNet model is. “NAFNet or the Nonlinear Activation Free Network is a simple baseline model for all kinds of image restoration tasks as proposed by the paper Simple Baselines for Image Restoration. The aim of the authors was to create a simple baseline that exceeds the then SOTA methods in terms of performance and is also computationally efficient. To further simplify the baseline, the authors reveal that nonlinear activation functions, e.g. Sigmoid, ReLU, GELU, Softmax, etc. are not necessary: they could be replaced by multiplication or removed.”[1]
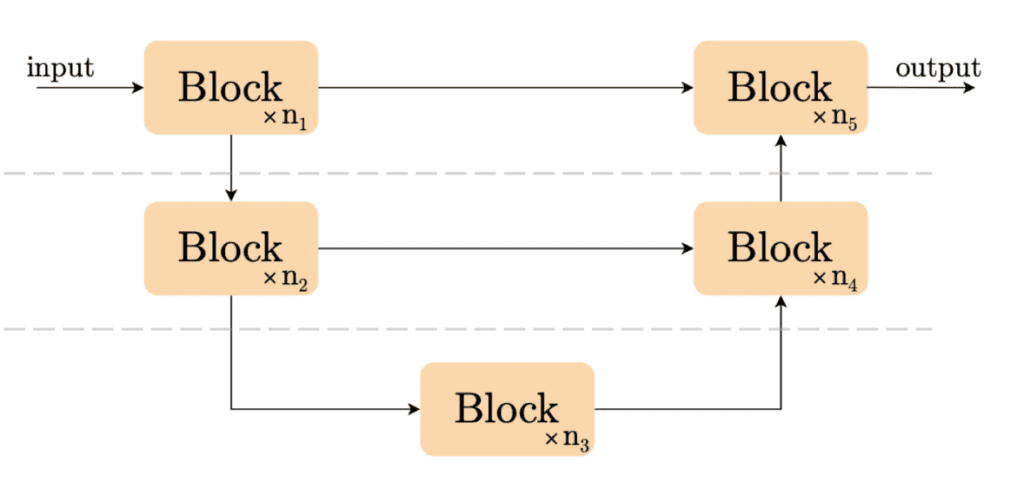
Learn more about NAFNet, including how to train it using restorers and wandb from ~24:29 – 31:33 in the video replay. For the code, you can refer to this Colab notebook.
Soumik explains the last of the three models that he will feature in this presentation. “Zero-Reference Deep Curve Estimation or Zero-DCE formulates low-light image enhancement as the task of estimating an image-specific tonal curve) with a deep neural network. Instead of performing image-to-image mapping, in the case of Zero-DCE, the problem is reformulated as an image-specific curve estimation problem. In particular, the proposed method takes a low-light image as input and produces high-order curves as its output. These curves are then used for pixel-wise adjustment on the dynamic range of the input to obtain an enhanced image. A unique advantage of this approach is that it is zero-reference, i.e., it does not require any paired or even unpaired data in the training process as in existing CNN-based (such as MIRNet) and GAN-based methods (such as EnlightenGAN).”[1]
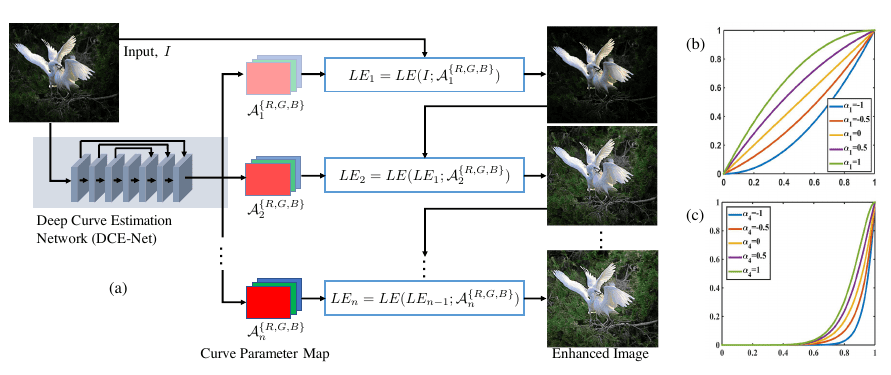
Learn more about Zero-DCE, including how to train it using restorers and wandb from ~31:33 – 37:02 in the video replay. For the code, check out this Colab notebook.
Now that Soumik has shown us how to train low light enhancement models, he shows us how to evaluate them on the LoL dataset using the restorers.evaluation API, and how to log the results in a Weights & Biases dashboard. For the code, check out this Colab notebook.
While upon first glance, it seems like NAFNet is the most performant model according to the number of trainable parameters, and especially compared to MIRNet-v2, Soumik next runs inference on the models and shows examples of poorly lit images so we can see how the models perform. (You can follow along with this part from ~40:09 – 44:35 in the video playback.)
What do we see? NAFNet produces some great images, but it can also introduce weird artifacts in your image. This won’t work for a scenario where a low light enhancement model is used as a pre-processing step for object detection models. Soumik has already dismissed MIRNet-v2 because it was too slow and too large of a model. But Zero-DCE is looking really good.
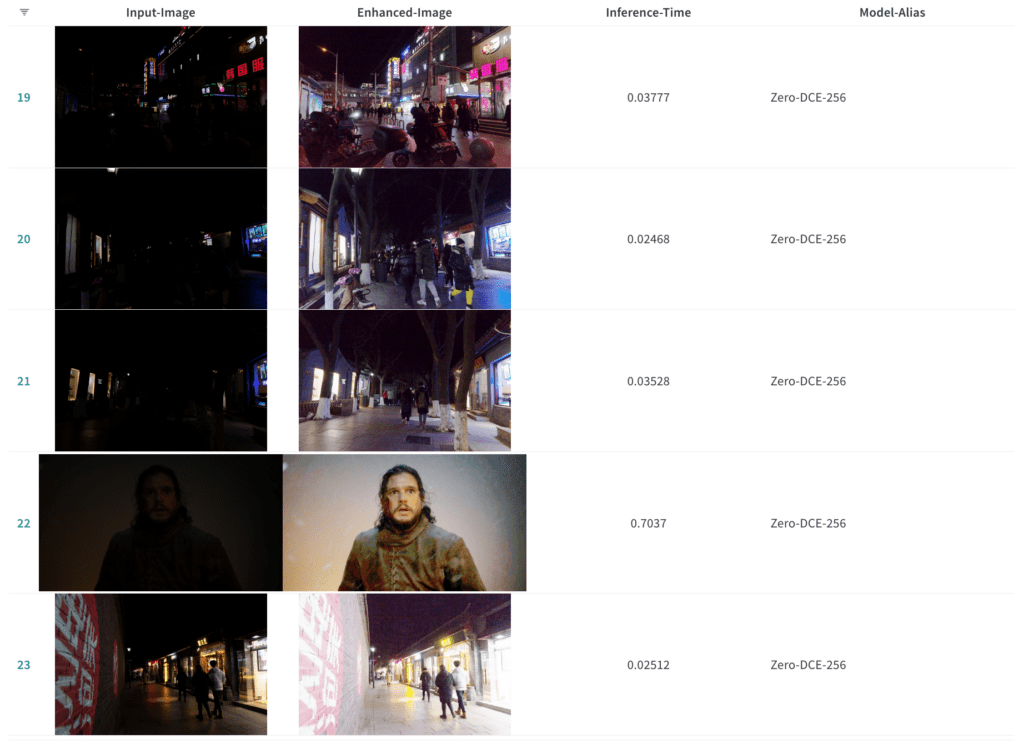
Zero-DCE is a lightweight model (less than 1MB) which makes it the best candidate to be applied for a low light enhancement model as a pre-processing step for computer vision tasks. Zero-DCE is quick and easy to train and it produces images that are visually pleasing. Soumik ends the presentation with this conclusion: all of these factors make Zero-DCE one of the most desirable models to be taken into production for low light image enhancement.
Q&A Recap
The unsupervised model is cool…but what would be the benefit over just applying the contrast and pixel distribution ops to the images “manually”?
In the presentation, we briefly touched on the pitfalls of traditional auto contrast algorithms, which are summarized here. In addition to that, they do not perform as well as Zero-DCE. When I created this tutorial for Zero-DCE over on keras.io, François Chollet, the creator of Keras, on a PR thread performed an interesting benchmark. You can see the original low light image compared to the result by a traditional auto contrast algorithm, and then the result that was spewed out by Zero-DCE. You can clearly see that the auto contrast models do not actually perform very well.

Are the test models from a totally new scene? Or related to trained data?
The models are not being tested on trained data. If we look at the results for evaluation, you can see the distinction. The top panels show the results on the training dataset. And the panels in the second row show the results on completely new data, which the model hasn’t seen at all.
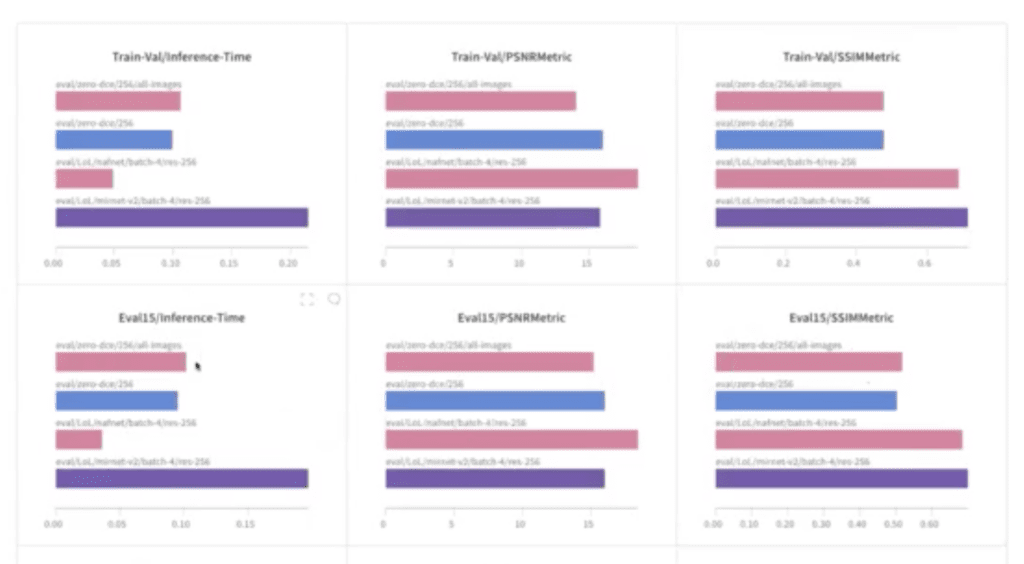
In terms of qualitative analysis, Zero-DCE has already shown that it’s capable of holding its own against the larger models like NAFNet or MIRNet-v2. Also the images that we show in the “usage section” of the online tutorial are completely out of distribution images from different datasets (some are from the Dark Face dataset, which is actually for object detection in incredibly low light conditions; and I tossed in some other ones as well).
Additional Resources
Check out these additional resources:
- Talk transcript
- Presentation slides
- [1] Online tutorial
- Weights & Biases is hosting Fully Connected, The ML Conference for practitioners, by practitioners. Register to hear from the teams building the most impactful large models & production-ready ML models with speakers from Stability AI, Spotify, NVIDIA, fast.ai and many more.
- Would you like to learn more about Weights & Biases? Request a demo here.
A big thank you to Soumik on behalf of the entire Computer Vision Meetup community for enlightening us on how to light up low light images in the deep learning era!
Taking Computer Vision Models in Notebooks to Production
Video Replay
Presentation Summary
Sumanth’s presentation is all about taking models to production. As a machine learning engineer or data scientist, it’s not the case that your job is done when you create a model and deploy it. The machine learning lifecycle is continuous. You need to continuously monitor your model and iterate on it, whether it is retraining the model, collecting more data, or other important tasks with the goal of creating an end-to-end model. To be successful creating a process that works end-to-end all the way through production, you need to keep track of your data, your steps, and your environment.
Sumanth explores some common problems after deployment, and ways to address them, including, with the biggest issue being data drift. Data drift is a common problem faced in machine learning that causes the model quality to decrease over time. This is because there are gaps in your data. Maybe there are cases your data didn’t cover when you were building the model, but you are now seeing when your model is in production. Ex: maybe the data you initially collected was from “summer” but now your model is operating in “winter”. Different types of data drift include covariate shift, label shift, and domain shift.
To avoid pitfalls when taking models into production, there are some best practices: data versioning, data & model validation, experiment tracking, scalable pipelines, and continuous monitoring.
The good news is that there are many open source tools that will help you address the common problems across the machine learning lifecycle. Sumanth explores some examples:
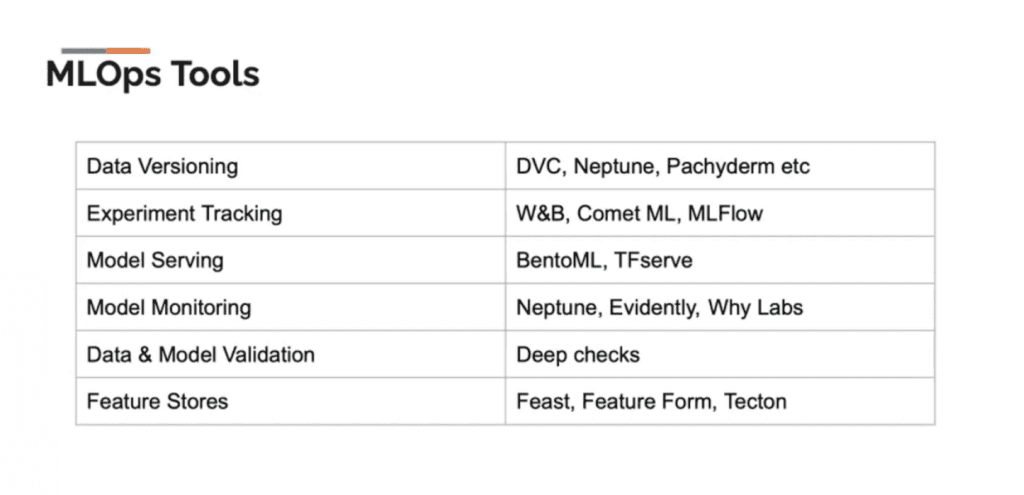
But after you have all these disparate open source tools running, how do you manage them? And what if you switch a tool? You don’t want to have to rewrite your code. So how can we create reproducible, maintainable, and modular data science code?
Enter ZenML. Sumanth loves this tool and demonstrates it in the presentation (from ~25:26 – 35:01). (He also notes that alternatives include Kedro and Flyte in case you want to check them out).
ZenML has a notion of stacks, which represent a set of configurations for your ML Ops tools and infrastructure. For examples, you can do all this with ZenML stacks:
- Orchestrate your ML workflows with Kubeflow
- Save ML artifacts in an Amazon S3 bucket
- Track your experiments with Weights & Biases
- Deploy models on Kubernetes with BentoML
Sumanth explains that ZenML makes all this easy. Plus you can change flavors, which means easily change and switch between the tools you want to use, easily in ZenML too.
In summary: there are common challenges in the ML lifecycle that give rise to best practices, and there are a bunch of open source tools to help you along the way. Simply select the right one for your use case, and if you need to switch tools, there are tools to help you do that easily, too.
Q&A Recap
Are there tools to automate the measurement of label shift?
Yes, you’re able to track this by tracking the model after you deploy it. The tool I use for this is Deepchecks for continuous data and model validation.
How important is the evaluation of “Neural network verification” in model evaluation?
It’s important. Once you create a model, it’s general practice to evaluate the model. You have to find the model that performs the best for your use case, so it should always be done.
One of the toughest “drift” problems I’ve had in the past in production I had to investigate – it turned out that some training data started to leak into the test set (both were evolving). What methods or tools would you recommend for preventing this issue?
I’ve seen problems with data leakage as well, mostly due to trying to divide a dataset for train, test, and validation. One suggestion here is to follow the best practices for splitting data into the different sets; these little things can also have an impact on reducing or stopping data leaks.
What’s the best way to deploy a CV model?
There are really cool tools for this based on your specific use case, and some examples are: BentoML, KServe, and others like MLflow and Seldon Core. Each of these has its own advantages so I encourage you to check them out, as well as the open source communities around them.
Additional Resources
Check out the talk transcript.
Also, thank you to Sumanth for all the great information on taking computer vision models to production!
Computer Vision Meetup Locations
Computer Vision Meetup membership has grown to nearly 3,300+ members in just a few months! The goal of the meetups is to bring together communities of data scientists, machine learning engineers, and open source enthusiasts who want to share and expand their knowledge of computer vision and complementary technologies.
We invite you to join one of the 13 Computer Vision Meetup locations closest to your timezone:
- Ann Arbor
- Austin
- Bangalore
- Boston
- Chicago
- London
- New York
- Peninsula
- San Francisco
- Seattle
- Silicon Valley
- Singapore
- Toronto
Upcoming Computer Vision Meetup Speakers & Schedule
We have other exciting speakers already signed up for the next several Computer Vision Meetups! Become a member of the Computer Vision Meetup closest to you to get details about the meetups already scheduled and be one of the first to receive new meetup details as they become available.
April 13 @ 10AM PT
- Generating Diverse and Natural 3D Human Motions from Texts – Chuan Guo (University of Alberta)
- Emergence of Maps in the Memories of Blind Navigation Agents – Dhruv Batra (Meta & Georgia Tech)
- Using Computer Vision to Understand Biological Vision – Benjamin Lahner (MIT)
- Here’s the Zoom Link to register
April 26 @ 9:30 PM PT (APAC)
- Leveraging Attention for Improved Accuracy and Robustness – Hila Chefer (Tel Aviv University)
- AI Deployments at the Edge with OpenVINO – Zhuo Wu (Intel)
- Here’s the Zoom Link to register
May 11 @ 10AM PT
- The Role of Symmetry in Human and Computer Vision – Sven Dickinson (University of Toronto & Samsung)
- Machine Learning for Fast, Motion-Robust MRI – Nalini Singh (MIT)
- Here’s the Zoom Link to register
Get Involved!
There are a lot of ways to get involved in the Computer Vision Meetups. Reach out if you identify with any of these:
- You’d like to speak at an upcoming Meetup
- You have a physical meeting space in one of the Meetup locations and would like to make it available for a Meetup
- You’d like to co-organize a Meetup
- You’d like to co-sponsor a Meetup
Reach out to Meetup co-organizer Jimmy Guerrero on Meetup.com or ping him over LinkedIn to discuss how to get you plugged in.
The Computer Vision Meetup network is sponsored by Voxel51, the company behind the open source FiftyOne computer vision toolset. FiftyOne enables data science teams to improve the performance of their computer vision models by helping them curate high quality datasets, evaluate models, find mistakes, visualize embeddings, and get to production faster. It’s easy to get started, in just a few minutes.

