Featuring active learning, transformers, eye gazes, distractions, FiftyOne, and more
In this blog, you’ll see how quick and easy it is to build a dataset, load it into FiftyOne and FiftyOne Teams, perform active learning techniques, integrate with transformers from Hugging Face, and ultimately get some pretty interesting revelations about the data. Although this blog post features an interior dataset for an in-cabin monitoring use case, the steps involved will work for any visual AI project. It’s intended for novices and advanced readers alike. Ok, let’s start our journey!
Who Am I?
My name is Robert Wright, I work in the Sales team at Voxel51 selling our FiftyOne Teams enterprise software to startups and Fortune 100 companies alike.
If you’re not yet familiar, Voxel51 is an open source AI startup that enables AI/ML builders to build better models through the lens of our data-centric visual AI solutions, which include:
- Open source FiftyOne with more than 2M downloads and nearly 7000 stars on GitHub
- FiftyOne Teams, which adds enterprise-ready collaboration, security, flexibility, automation, and support and is deployed at the heart of AI stacks across some of the world’s largest and most AI-forward companies, including global top five automotive, manufacturing, and tech powerhouses
Disclaimer 1—Before embarking on this project, I had never written a line of Python (or any code for that matter); however, by the end of this project, I was writing (copying and pasting) several lines of code to perform actions inside the FiftyOne platform.
Disclaimer 2—This post was not written by ChatGPT.
Disclaimer 3—My ML advisor and co-author on this post is Voxel51 ML engineer Allen Lee. You’ll hear from him later in the post!
Why Am I Writing This and What’s in it for You?
I do not particularly like writing, nor have I done it since writing my University Thesis 15 years ago. However, I felt compelled to write after seeing the incredible results of this project.
Really I was so blown away by:
- How ridiculously easy it was to use FiftyOne and FiftyOne Teams and…
- The amount of success I achieved in around 2 hours of work. I wanted to document this somewhere. Hence, this post.
In fact, I probably spent more time writing this blog than I did on the actual project itself… collecting, loading, curating, labeling, and applying models to my dataset inside of FiftyOne.
Also, I had more fun using FiftyOne, writing Python, and applying models than I have had in a very LONG TIME, e.g., even when I was in Vegas recently!
So, if you have a couple of hours to spend on curating and visualizing a dataset, you can use the lessons in this post to have more fun than Vegas using FiftyOne!
What Prompted the Project?
I received a request from a potential customer to showcase FiftyOne and how it works with interior (in-cabin) perception use cases. If you are unfamiliar with interior perception, it’s about perceiving and understanding what happens once drivers and passengers are inside a car, in order for automakers to build automated systems to solve problems like driver drowsiness or distractions whilst driving.
Now here comes our dilemma… We are proud to have multiple Tier 1 automotive companies as customers of the FiftyOne Teams enterprise solution to aid them in building AI systems for their interior perception use cases, but, the salesman’s dilemma:
- I cannot name them or have them demo to the new interested party
- I cannot use their datasets
So, naturally, the next step was to look for an open source in-cabin dataset I could load into FiftyOne Teams to demo the capabilities. But, ALAS, either my Google skills were so lacking that I needed to have a stern word with myself, or none existed. I was faced with the decision: Give up, OR… Go out and make my own dataset. Suffice to say I chose the latter.
Proper Planning and Preparation Prevents Piss-Poor Performance
Throughout my life, I have tried to live by the British military adage of the 6 P’s… So I knew I was going to have to have some kind of plan. Here are the high-level steps, which are explained in detail in the sections below:
- Collecting data—An iPhone has a pretty good camera, right? Ok, I better make sure I mount it well, so off to Target to purchase a $25 car mount. Thanks Apple for that EPIC iPhone camera!
- Loading data into FiftyOne—How on earth do I get this into our tool, do I load into our open source, our enterprise version, or both? Obviously, I did both. I took full advantage of the FiftyOne Docs and Slack channel.
- Gaining insights into my data—Now what? There is no way I am hand-labeling these videos/images, annotation is dead, right?… Ok, let’s apply some models.
- Explaining the findings—In-cabin monitoring use cases require techniques for: keypoints, embeddings, meshes, distractions, detections, mistakes, eye gaze, similarity, uniqueness, and more. Continue reading to see the eye-opening insights I found.
Data Collection
I used my wife’s iPhone 14 Pro Max to capture video, and I purchased an iOttie Easy One Touch 5 Dash * Windshield Mount – Black from Target for a whopping $25.
My advisor to this project, Voxel51 ML Engineer Allen Lee, recommended that I rotate my screen sideways in landscape mode, so the data captures both the driver and the steering wheel. He also advised me to make sure my head is not occluded and that the video captures as much of my body as possible.
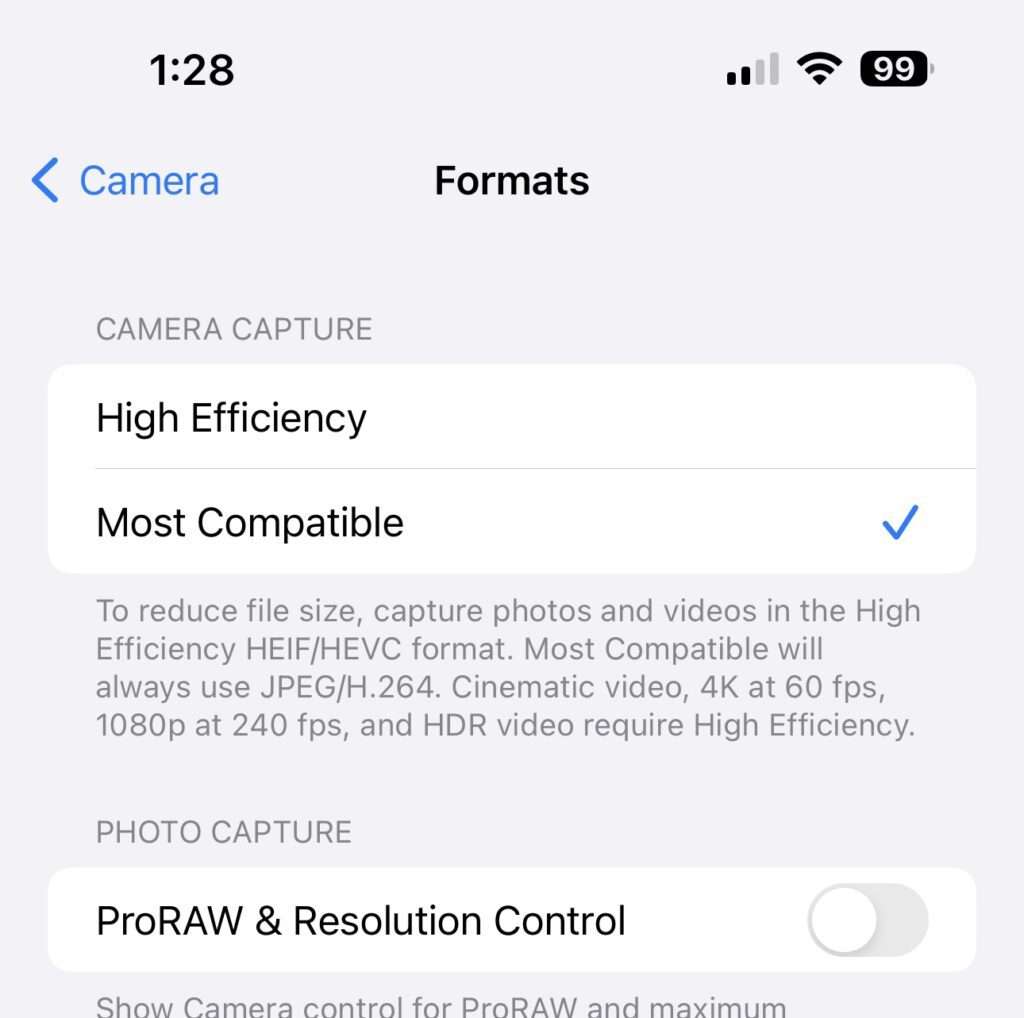
Also, as a side note, make sure you swap the camera capture to Most Compatible from High Efficiency: Settings, Camera, Camera Capture > select Most Compatible.

The next challenge was what data to collect. Obviously, I knew that we needed normal driving behavior but the entire point of an interior perception use case in a driver cabin is to SAVE LIVES.
This means we needed to capture behavior that included the following:
- Safety including driver distractions (phone/texting/playing with car radio/GPS)
- Safety including tiredness (eyes closing for x seconds)
- Driver positioning for comfort and protection
- Sensing of the entire vehicle to prohibit actions like people breaking into the vehicle
Now I didn’t particularly want to drive around with my eyes closed or drive around texting distracted for obvious reasons however to simulate these behaviors I did the following.
I found an area of my neighborhood where the road was closed. I spoke to the building/contractor and asked permission to use the closed road so that I could capture some of this behavior, and he allowed me to (for the mission of saving lives) drive around for a few minutes. I acted out texting- and radio-distracted behavior (I should get an Oscar I know), and I knew that our data would pick up blinking, which meant I could apply a model to detect whether or not my eyes were closed.
I did three 10-minute driving stints, changing outfits in each 10-minute drive. In two drives I had glasses on, and in one I had glasses off.
Now the next part will make you laugh… This was the hardest part (for me anyway) of the entire experiment. Getting 3x 1GB+ files from my wife’s phone onto my hard drive/cloud. The process involved:
- Uploading the files to her personal Google Drive… (this took what felt like the longest time in the world, in fact was probably only 20 minutes, perhaps I should upgrade my home internet)
- Emailing me the Google Drive link
- Downloading the files to my Macbook Pro hard disk
- Uploading the files to our internal GCP buckets, because I knew that once I had tested the data in open source FiftyOne, I would inevitably load the data into our FiftyOne Teams demo environment via our GCP integration
Loading Data in
The moment of truth. I have been telling all of my prospects and customers this past year that using the open source version of FiftyOne was very easy… I can finally sleep at night with no guilt as YES in fact if you know Python this is incredibly easy and requires literally a few lines of code, which cue my ML advisor Allen Lee to the rescue, who provided me with the following:
brew install ffmpeg python3 -m venv env source env/bin/activate pip install -U pip setuptools wheel pip install fiftyone pip install ultralytics "torch>=1.8"
I asked Allen: WAIT WHAT… I need to set up a what… Python virtual environment and install Brew, FFmpeg, and Ultralytics Torch on my Mac to get this running?
Here was Allen’s reply:
“Hey all, Allen here. Robert is a super-fun guy, the British Bulldog, a former boxer, and an absolute tech sales machine! He brightens up all of our busy days at Voxel51 and also has way more technical insight than he lets on.
So well yes, installing in a virtual environment isn’t so strange, and we did need ffmpeg since we would be working with a video dataset. Meanwhile, we installed Ultralytics so we could try running Yolo.”
fiftyone app launch
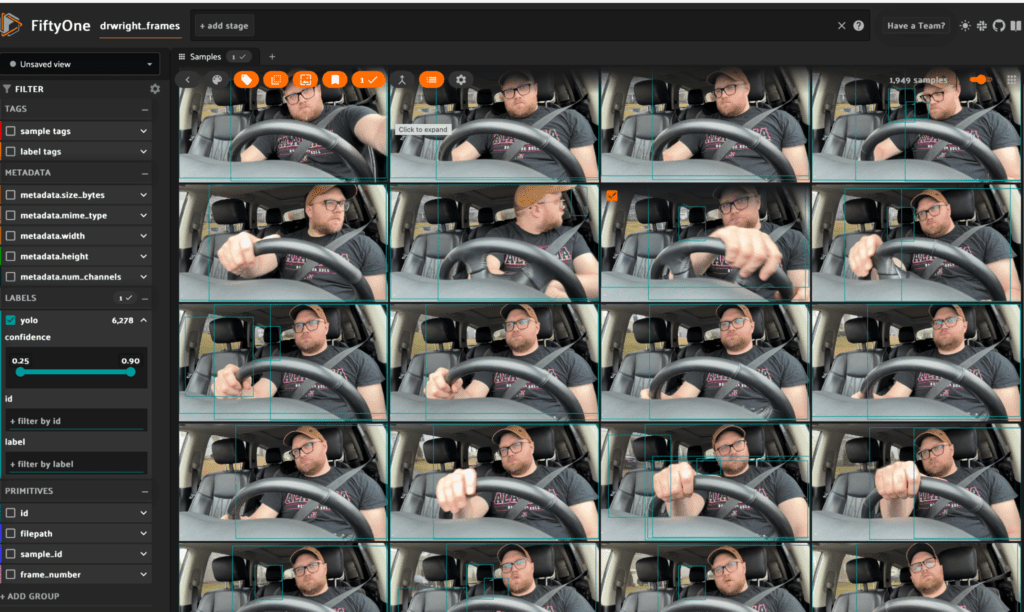
Ok, so the initial euphoria of copying and pasting code from Allen and seeing my dataset loaded in started to pass… The detections that YoloV5 was giving were somewhat OK but I knew I wanted to do so much more.
The open source FiftyOne tool is amazing and designed for one user, and more explicitly, an experienced Python user… (Now, whilst I was a single user my Python experience was close to zero.)
However much I tried to continue I knew that my days were numbered; I needed a platform that I could collaborate in. Obviously, I knew that our enterprise tool FiftyOne Teams enabled that so….. Cue Allen again who is the real genius of the operation… I roped Allen into helping me here (he had already given me the OSS command strings.) So I thought a little more help wouldn’t hurt.
However, before I roped Allen into my science experiment I wanted to load the data into FiftyOne Teams myself which is as easy as this:
- Create a new dataset
- Use our I/O plugin to ‘import samples’
- Then find the right Google Bucket string and import the folder. (That also took a newbie like me a few minutes as I had never used GCP or any cloud storage for that matter.)

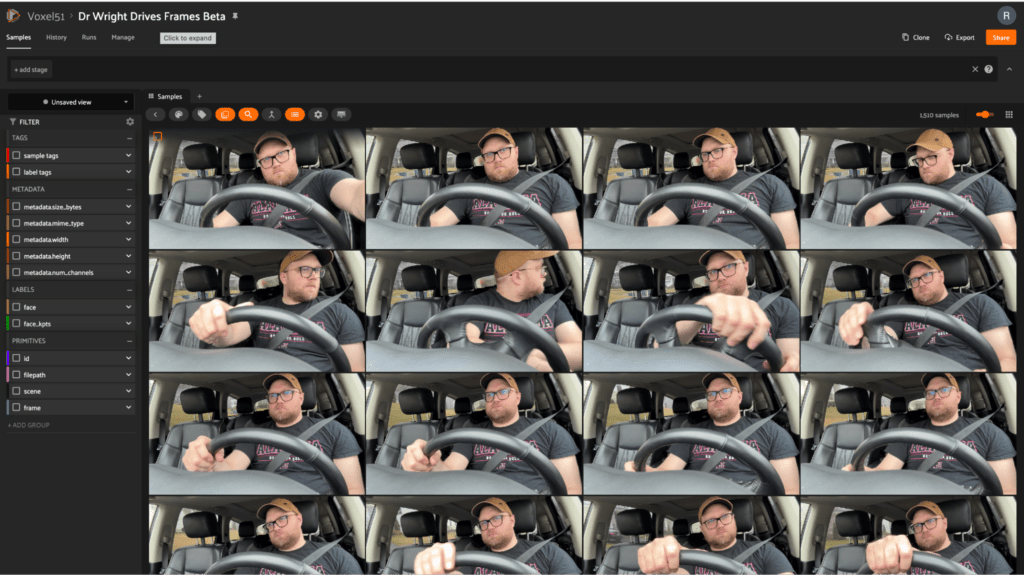
Now What? Gaining Insights into my Data.
Now comes the real fun… we ran a bunch of models!
Here’s Allen’s take on the process:
“Yes, definitely. Well, we were just playing around and wanted to show the art of the possible in a quick timeframe. So we looked around for off-the-shelf models that might work for face or gaze detection and pose estimation. We came across MediaPipe which seemed user-friendly and had some pre-trained models.
Important Note! As discussed in the Model Cards MediaPipe BlazeFace (Short Range) and MediaPipe Face Mesh, these models are definitely for prototyping and experimentation only!
First, we played with the Face Detection pipeline. This pipeline uses the BlazeFace short-range model, which is optimized for close-range selfie-shot-style images from a phone camera. It seemed pretty similar to our data. This API also supports sequential images sampled from a video stream via its running_mode configuration option, which was a nice touch.
This model outputs bounding boxes for all faces detected in the input images, as well as a set of six facial keypoints.”
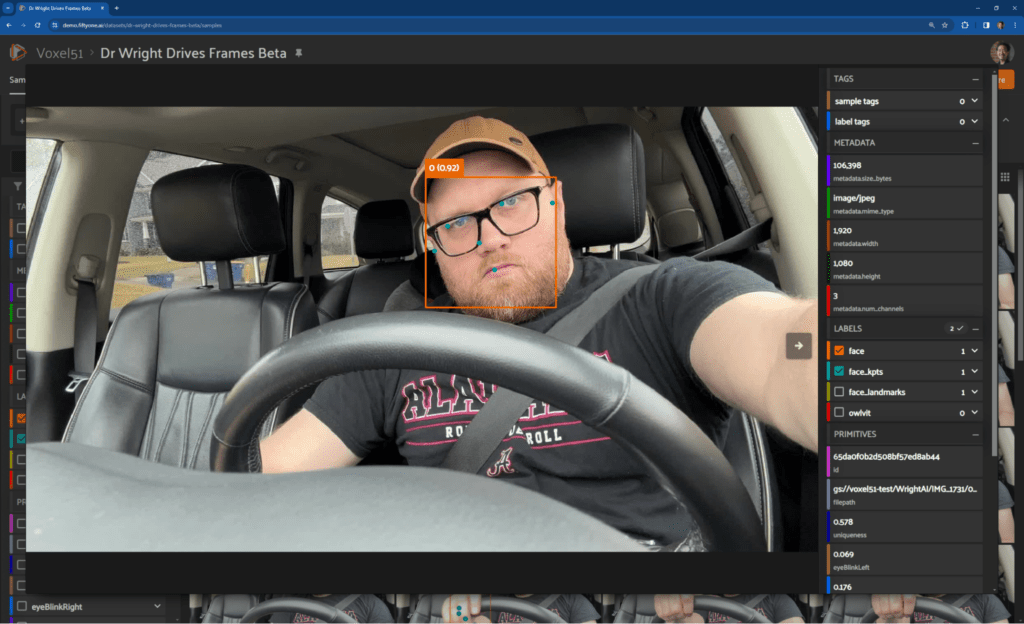
Allen continued:
“Next up was the Face Landmarker pipeline. This pipeline is a superset of the Detector pipeline, which adds detection of a dense 478-point facial mesh as well as 52 blendshape scores, which measure various facial expressions. We thought the keypoints from the facial mesh might give a better location of gaze compared to the Detector model; meanwhile, would the blendshapes catch Robert asleep (not literally, of course!) at the wheel?
The full mesh model predictions looked quite good! When this mesh was overlaid on top of Robert’s face during video playback, Robert was turned into a fearsome futuristic cyborg:
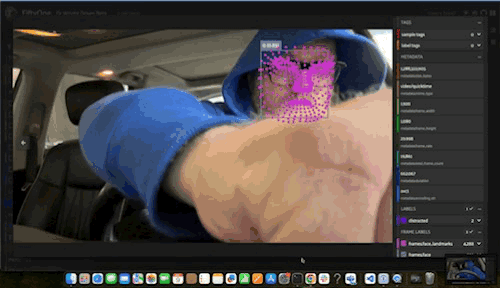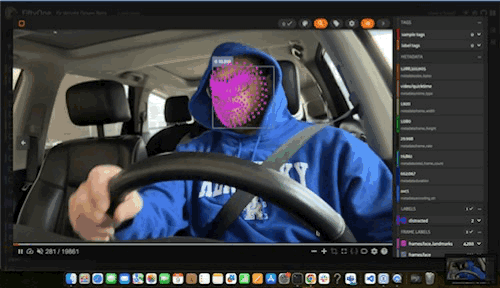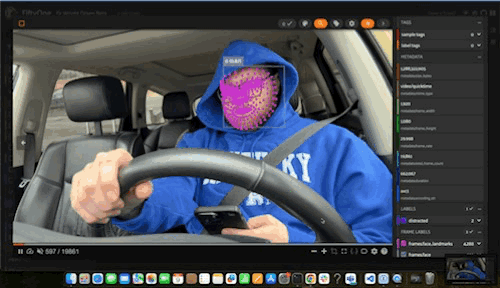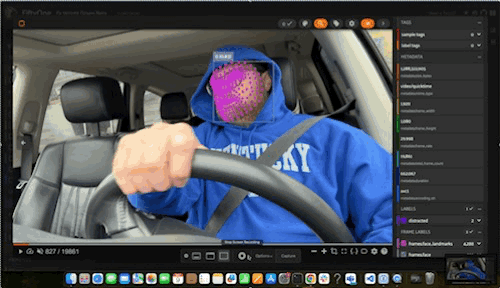
Meanwhile, for the image datasets, we kept a more restricted subset of points for easier visibility. Indeed, the eyes seemed to be better localized with the mesh, when compared to the Face Detector’s predictions.”
Asleep at the Wheel?
Here’s the answer to that question from Allen:
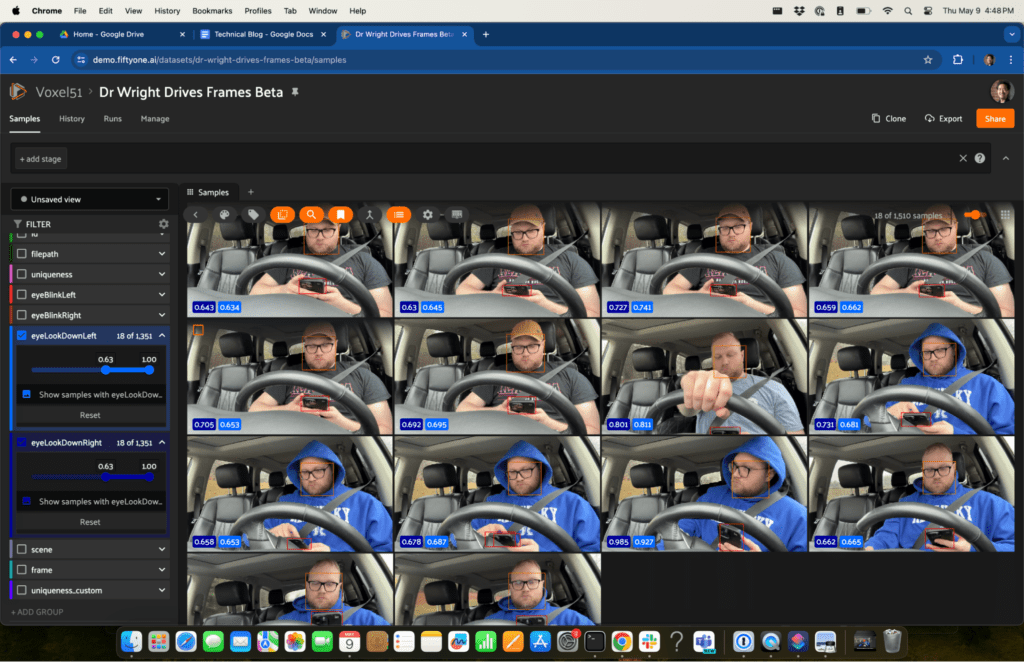
“This was really neat, but one of our original goals was to see if we could use this camera data to determine when the driver was distracted. The Landmarker pipeline’s blendshape scores provide a set of quick statistics to consider. In FiftyOne, filtering for high scores among any of these statistics is as easy as adjusting a slider:
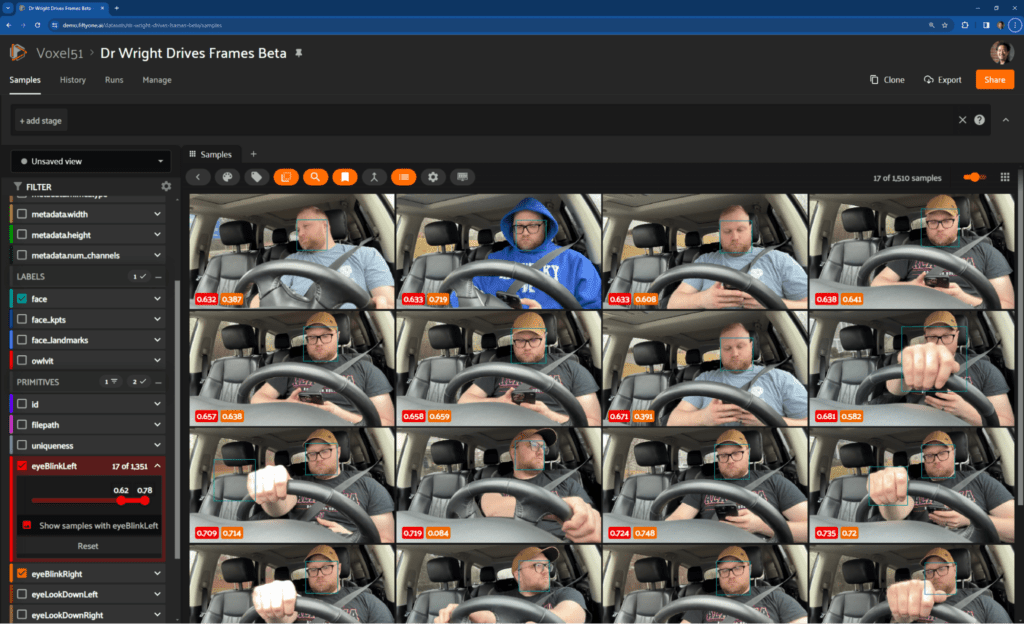
As it turns out, eyeBlinkLeft and eyeBlinkRight seemed to have a high correlation with Robert looking down and away from the windshield. Hey Robert, pay attention to the road!
What else could we do? Well, cellphones are probably the top cause of distracted driving these days. And meanwhile, FiftyOne comes with extensive similarity search functionality built right in. So, we went ahead, computed some embeddings, and searched for “cellphone” to see if we could detect Robert using his phone behind the wheel.
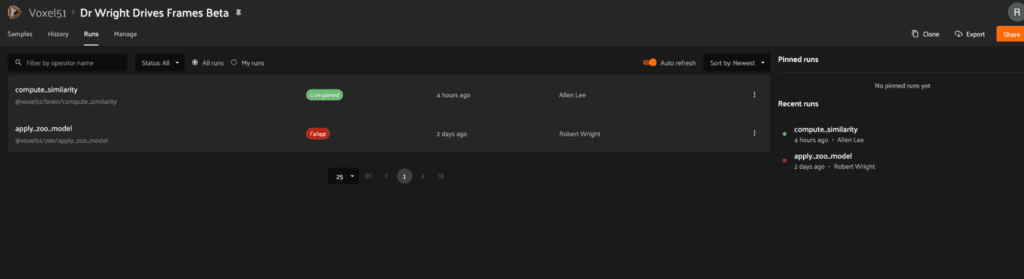
FiftyOne Teams takes computing embeddings and running similarity search to the next level using Delegated Operators, its built-in workflow orchestration functionality:
Finally, we recently added a HuggingFace integration. Rather than just searching for cellphones in the entire image, we tried running OwlViT to combine search with object detection, to both find and localize cellphones:”
import fiftyone as fo
import fiftyone.zoo as foz
dataset = fo.load_dataset("Dr Wright Drives Frames Beta")
model = foz.load_zoo_model(
"zero-shot-detection-transformer-torch",
name_or_path="google/owlvit-base-patch32",
classes=["phone", "cup"]
)
dataset.apply_model(model, label_field="owlvit")
Putting It All Together
Now that we have done this we were able to find the following:
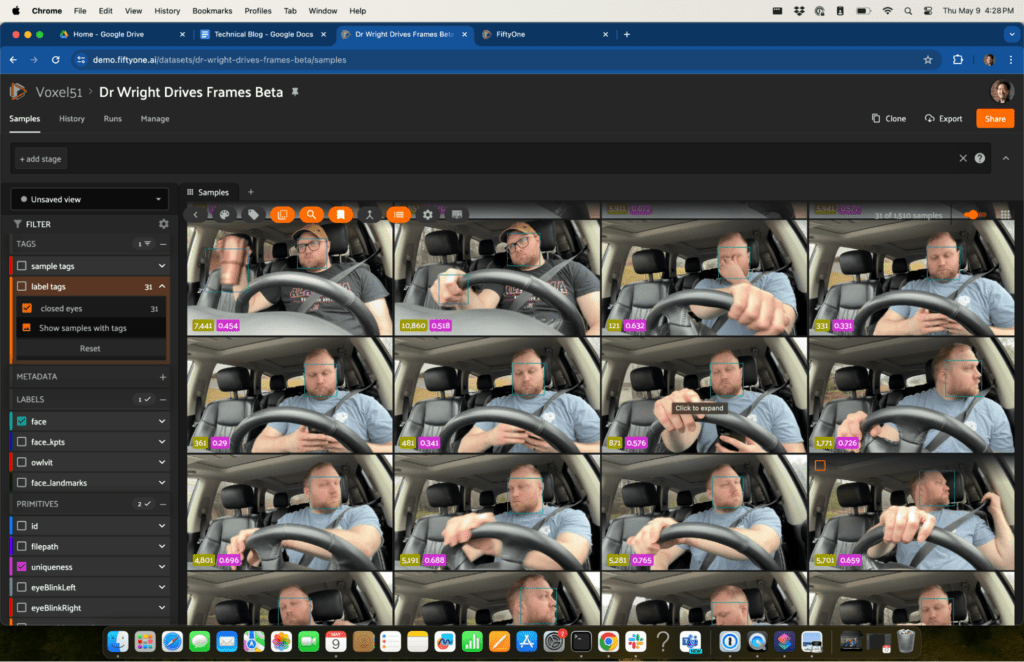
All of the samples with my eyes closed and label them…
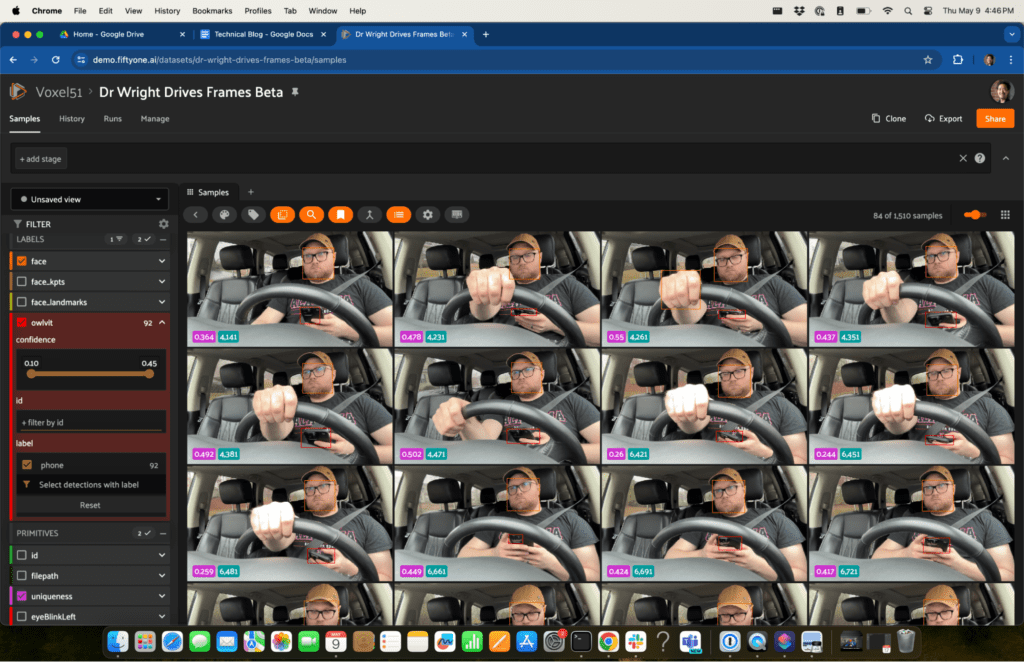
All of the samples with my phone in my hand…
All of the samples with my eyes looking down…
Using FiftyOne’s Embeddings panel, I could also find incorrectly labeled samples where it says phone but, in fact, was incorrectly labeled, so that we can fix these incorrect labels.
What’s Next
We could continue by adding new samples to the dataset, such as:
- Add in samples with sunglasses
- Add samples at night
- Vary the dataset by adding people of different genders and races into the dataset
- Add samples with the driver not wearing a seatbelt to detect no seatbelt and alert the driver
- Add 3D data and point cloud lidar/radar data to detect motion
We could train our own “Distraction” model that provides the driver with an alert when distracted/falling asleep.
We could add samples with time series data of eyes shut for X number of seconds—the feasibility of doing this from a safety point of view may require some more thinking…
Conclusion
This was a heap of fun! Not only did it teach me more about open source FiftyOne and FiftyOne Teams, it also taught me how to run a small ML project from start to finish—from data collection to building a dataset to applying a model both in the command line and in FiftyOne Teams.
Whilst I had demoed the tool hundreds of times with our current datasets, I had never built one from scratch, until now.
If you’re interested, you can view my dataset instantly in your browser at https://try.fiftyone.ai/datasets/dr-wright-drives-frames/samples. It’s the in-cabin perception dataset I discussed in this blog post made available in a read-only version of FiftyOne Teams. Try filtering the data using the left sidebar. Or click ‘+’ next to ‘Samples’, select ‘Embeddings’, and choose a key. Now, lasso-select points of interest. What trends do you see?
If you would like to learn more about this project, what went well, and what didn’t, reach out to me on LinkedIn and I would love to chat!
Also, if you have an idea about another use case or dataset we can create and explore together, I would love to collaborate with you, so please reach out!
PS. Special thanks to Allen Lee who provided me with guidance including but not limited to… how to collect the data, write FiftyOne & Python code scripts, curate the dataset once inside FiftyOne Teams and apply the models!

