Welcome to our weekly FiftyOne tips and tricks blog where we give practical pointers for using FiftyOne on topics inspired by discussions in the open source community. This week we’ll cover some tips and tricks that will help you accelerate your computer vision workflows using FiftyOne.
Wait, What’s FiftyOne?
FiftyOne is an open source machine learning toolset that enables data science teams to improve the performance of their computer vision models by helping them curate high quality datasets, evaluate models, find mistakes, visualize embeddings, and get to production faster.

- If you like what you see on GitHub, give the project a star.
- Get started! We’ve made it easy to get up and running in a few minutes.
- Join the FiftyOne Slack community, we’re always happy to help.
Ok, let’s dive into this week’s tips and tricks!
Load data into FiftyOne faster
One of the great features of PyTorch is the DataLoader class, which makes it easy to efficiently load and process data. This becomes especially useful when dealing with large datasets, where it can be inefficient or impossible to load the entire dataset into memory at once.
When you’re working with PyTorch data in FiftyOne, you can leverage the speed and simplicity of your PyTorch DataLoader to import your data into and analyze that data in FiftyOne.
Here’s an example using the test split of the CIFAR-10 dataset:
First, we create the TorchVision dataset and instantiate a DataLoader for the dataset.
import torch
import torchvision
# Downloads dataset and prepares it for loading in a DataLoader
dataset = torchvision.datasets.CIFAR10(
"/tmp/fiftyone/custom-parser/pytorch",
train=False,
download=True,
transform=torchvision.transforms.ToTensor(),
)
classes = dataset.classes
data_loader = torch.utils.data.DataLoader(dataset, batch_size=1)
Then we create the FiftyOne Dataset for this data and specify the directory in which we will store the images.
import fiftyone as fo
dataset = fo.Dataset("cifar10-samples")
# The directory to use to store the individual images on disk
dataset_dir = "/tmp/fiftyone/custom-parser/fiftyone"
Finally, we create a sample parser and use the PyTorch DataLoader with FiftyOne’s ingest_labeled_images() method to fill our FiftyOne Dataset with the PyTorch data.
sample_parser = PyTorchClassificationDatasetSampleParser(classes)
dataset.ingest_labeled_images(
data_loader,
sample_parser,
dataset_dir=dataset_dir
)
Once you have PyTorch data loaded into FiftyOne, it is also easy to train Lightning Flash tasks on your FiftyOne data and add model predictions to FiftyOne!
Learn more about FiftyOne’s PyTorch Lightning Flash integration in the FiftyOne Docs.
For other ways to add samples, check out the docs for adding samples manually or using dataset importers to load data into FiftyOne.
Peruse through samples faster
If you’re working with high-resolution media files like satellite imagery or photo-realistic AI-generated data, you might notice some slight delays in rendering when you scroll through samples in the sample grid in the FiftyOne App. This is because, by default, the app is rendering the high-resolution media files in real time.
If you’re experiencing this buffering, you might get a speed boost by configuring the app to use thumbnail images! By modifying the App Config, you can enable multiple media fields and choose which media field is displayed in the sample grid. One common workflow is creating lower resolution, downscaled images for each sample, and configuring the app to display these in the sample grid.
This way you retain the depth of information in your high-resolution media files for downstream workflows without sacrificing speed while investigating your data. When you click on a thumbnail in the sample grid, the media file in the resulting full-screen modal will be the high-resolution version!
Here’s an example of how you might accomplish this effect:
First, we create thumbnail images and store their paths in a thumbnail_path field:
import fiftyone as fo
import fiftyone.utils.image as foui
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
# Generate some thumbnail images
foui.transform_images(
dataset,
size=(-1, 32),
output_field="thumbnail_path",
output_dir="/tmp/thumbnails",
)
Then we modify the dataset’s App config to expose these thumbnails in the sample grid and create a session:
# Modify the dataset's App config dataset.app_config.media_fields = ["filepath", "thumbnail_path"] dataset.app_config.grid_media_field = "thumbnail_path" dataset.save() # must save after edits session = fo.launch_app(dataset)
Learn more about configuring the FiftyOne App in the FiftyOne Docs.
Filter samples faster
Another way to accelerate visually inspection of your data in the FiftyOne App is by setting the sidebar mode to ”fast”. When filtering and matching via the sidebar in the App, the sidebar_mode property in the App Config allows you to specify whether these operations should be applied to all samples in the view and all of the relevant fields, or just the samples visible in the sample grid and fields that are expanded in the filter tray. This can be a dramatic time-saver for datasets with many samples, many fields, or both.
For datasets with more than 10,000 samples, the FiftyOne App’s default behavior is ”fast”, but if you want to make this the default for all of your datasets, you can set this in the App Config with:
import fiftyone as fo fo.app_config.sidebar_mode = “fast”
Alternatively, if you want to set this only for a specific dataset, you can modify the dataset’s app config:
import fiftyone as fo
import fiftyone.zoo as foz
# load in dataset
dataset = foz.load_zoo_dataset("quickstart")
dataset.app_config.sidebar_mode = “fast”
Learn more about using the sidebar in the FiftyOne Docs.
Start with most unique samples
In many machine learning workflows, some samples matter more than others. Whether you are deciding what subsets of your dataset to send out for annotation, or identifying edge cases and failure modes of your models, it helps to focus your attention.
One trick you can use to explore a broad range of samples rather than scrolling through a bunch of similar examples is to look at the most “unique” samples first.
With the FiftyOne Brain, you can use embeddings to compute a score for each sample in your dataset that tells you how unique that sample is, relative to all of the other samples.
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
# load in dataset
dataset = foz.load_zoo_dataset("quickstart")
# compute uniqueness using default (CLIP) embedding
fob.compute_uniqueness(dataset)
You can then sort your samples by uniqueness, passing in reverse=True so that the most unique samples (highest values in uniqueness field) appear first:
unique_view = dataset.sort_by("uniqueness", reverse=True)
Then you can save time by looking at the most unique samples in your dataset first!
session = fo.launch_app(unique_view)
Learn more about the FiftyOne Brain and image uniqueness in the FiftyOne Docs.
Pre-annotate with embeddings
Embeddings can also save you precious time by helping you pre-annotate your computer vision data. Labeling and annotation of ground truth data often represents one of the most tedious and time-intensive tasks in computer vision workflows. In addition to hours or days spent, annotation can also be quite expensive.
Fortunately, for some datasets it is possible to use the structure uncovered by embeddings to do a coarse first pass through the data.
With the MNIST dataset, for instance, computing embeddings and then using dimensionality reduction techniques like tSNE, you can uncover multiple mostly-distinct clusters of samples. Using the lasso to interact with this visualization and view each cluster in the FiftyOne App, it quickly becomes clear that these clusters roughly correspond to different numerals. The MNIST dataset of course already has ground truth labels, but if it didn’t, you could leverage these clusters to tag samples with pre-annotations.
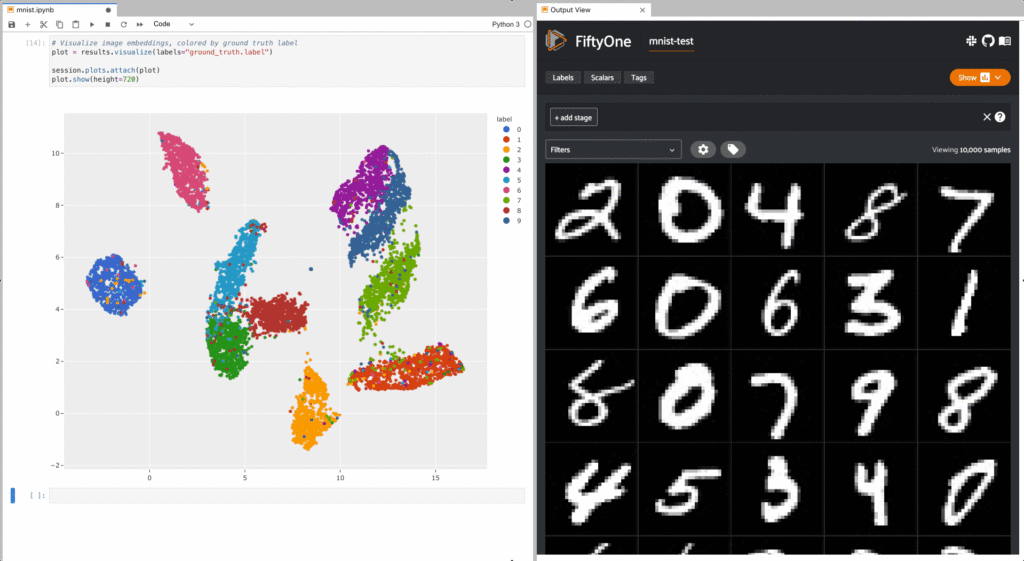
Learn more about using image embeddings and pre-annotating samples in the FiftyOne Docs.
Join the FiftyOne community!
Join the thousands of engineers and data scientists already using FiftyOne to solve some of the most challenging problems in computer vision today!
- 1,400+ FiftyOne Slack members
- 2,600+ stars on GitHub
- 3,400+ Meetup members
- Used by 256+ repositories
- 57+ contributors

