
Welcome to our weekly FiftyOne tips and tricks blog where we recap interesting questions and answers that have recently popped up on Slack, GitHub, Stack Overflow, and Reddit.
Wait, what’s FiftyOne?
FiftyOne is an open source machine learning toolset that enables data science teams to improve the performance of their computer vision models by helping them curate high quality datasets, evaluate models, find mistakes, visualize embeddings, and get to production faster.

- If you like what you see on GitHub, give the project a star
- Get started! We’ve made it easy to get up and running in a few minutes
- Join the FiftyOne Slack community, we’re always happy to help
Ok, let’s dive into this week’s tips and tricks!
Filtering for media that doesn’t contain a tag
Community Slack member Nadav Ben-Haim asked,
“Is there an easy way to filter media in the FiftyOne App for all the media that does NOT contain a tag?”
Indeed there is! In the view bar use match_tags() where bool=False

Visualizing embeddings in FiftyOne
Community Slack member Suphanut Jamonnak asked,
“Is it possible to visualize embeddings using the FiftyOne App?”
The FiftyOne Brain component can help you visualize embeddings. So, instead of combing through individual images/videos and staring at aggregate performance metrics trying to figure out how to improve the performance of your model, you can use the FiftyOne Brain to visualize your dataset in a low-dimensional embedding space to reveal patterns and clusters in your data that can help you answer many important questions about your data, from identifying the most critical failure modes of your model, to isolating examples of critical scenarios, to recommending new samples to add to your training dataset.
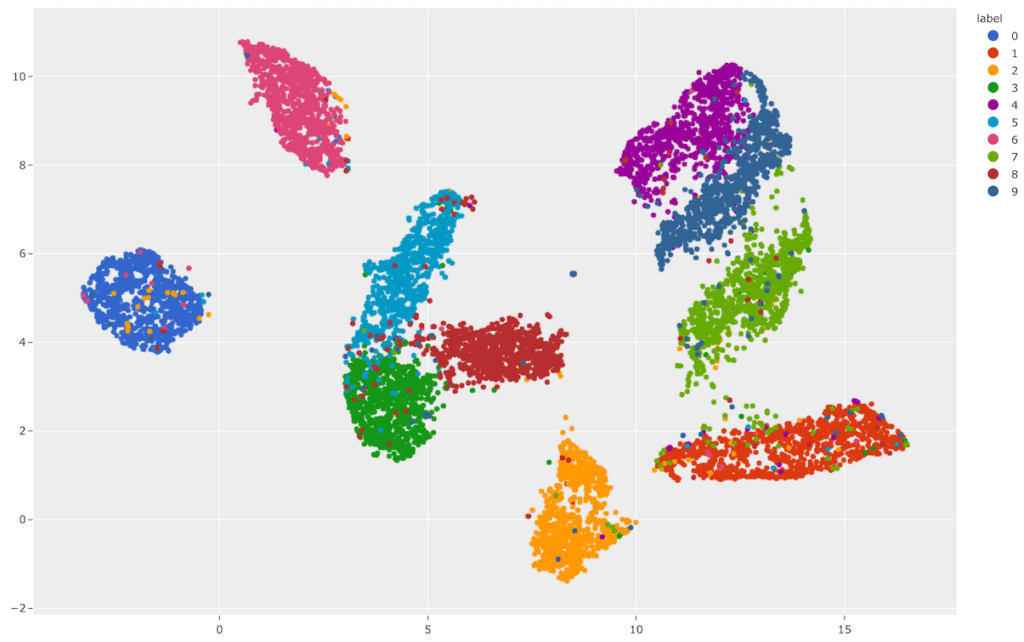
Learn more about how to visualize embeddings in the FiftyOne Docs.
Exporting labeled images
Community Slack member Tiffany Chen asked,
“How do I export labeled images from a dataset of keypoints?”
You’ll want to use draw_labels(). FiftyOne provides native support for rendering annotated versions of image and video samples with label fields overlaid on the source media. The interface for drawing labels on samples is exposed via the Python library and the CLI. You can easily annotate one or more label fields on entire datasets or arbitrary subsets of your datasets that you have identified by constructing a DatasetView.
Learn more about drawing labels on samples in the FiftyOne Docs.
Grouping multiple slices of image, video or point cloud samples
Community Slack member Marco Dal Farra Krsitensen asked,
“I have multiple slices of an MRI, is there a way to add multiple slices to one image and ideally see all (8 in my case) slices at the same time grouped in one observation?”
With the latest FiftyOne 0.17.0 release, there is now support for the creation of grouped datasets, which contain multiple slices of samples of possibly different modalities (image, video, or point cloud) that are organized into groups. Grouped datasets can be used to represent multiview scenes, where data for multiple perspectives of the same scene can be stored, visualized, and queried in ways that respect the relationships between the slices of data.
Grouped datasets may contain 3D samples, including point cloud data stored in .pcd format and associated 3D annotations (detections and polylines).
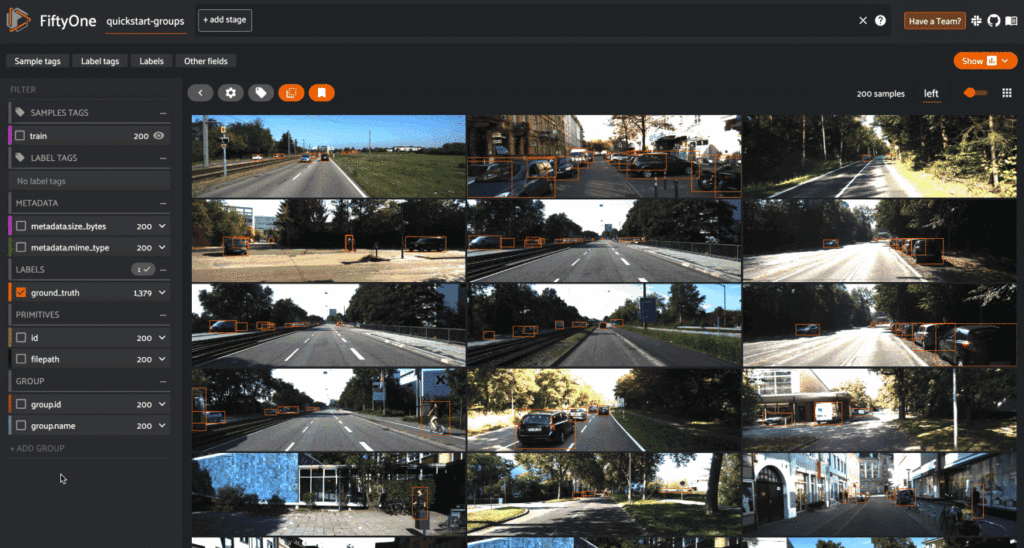
Learn more about grouped datasets in the FiftyOne Docs.
Creating views for samples that contain just the bounding box
Community Slack member Alex Thaman asked,
“I would like to have a view that, for each bounding box in the dataset, there is a sample that contains just that bounding box. However, unlike to_patches, I would like the entire image. So basically, for any image in the dataset, there should be N samples of each image, where each sample is the entire image, but contains only one bounding box label. Any tips on how to do this?”
For background, it can be beneficial to view every object as an individual sample, especially when there are multiple overlapping detections in an image. In FiftyOne this is called a “patches view” and can be created through Python or directly in the App.
In regards to Alex’s question, if you clone the patches view, you’ll have an ordinary dataset with the content that he describes:
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
patches_view = dataset.to_patches("ground_truth")
non_patch_dataset = patches_view.clone()
print(len(non_patch_dataset))
# 1232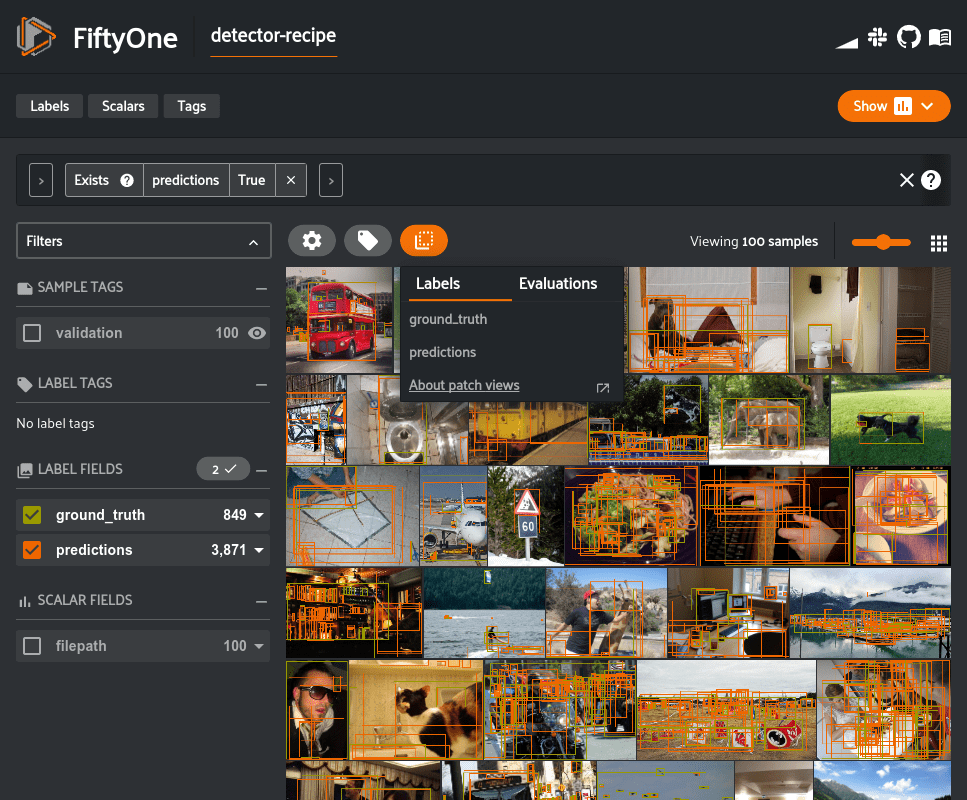
Learn more about using the patches view in the FiftyOne Docs.
What’s next?
- If you like what you see on GitHub, give the project a star
- Get started! We’ve made it easy to get up and running in a few minutes
- Join the FiftyOne Slack community, we’re always happy to help

