Voxel51 in conjunction with the FiftyOne community is excited to announce the general availability of FiftyOne 0.20. This release is packed with new features for indexing and searching your datasets, enabling you to build workflows to co-develop your datasets and machine learning models. How? Read on!
Wait, what’s FiftyOne?
FiftyOne is the open source machine learning toolset that enables data science teams to improve the performance of their computer vision models by helping them curate high quality datasets, evaluate models, find mistakes, visualize embeddings, and get to production faster.
- If you like what you see on GitHub, give the project a star.
- Get started! We’ve made it easy to get up and running in a few minutes.
- Join the FiftyOne Slack community, we’re always happy to help.
Ok, let’s dive into the release.
tl;dr: What’s new in FiftyOne 0.20?
This release includes:
- Natural language search: you can now perform arbitrary search-by-text queries natively in the FiftyOne App and Python SDK, leveraging multimodal vector indexes on your datasets under-the-hood
- Similarity API: significant upgrades to the FiftyOne Brain’s similarity API, including configurable vector database backends and the ability to modify existing indexes
- Qdrant and Pinecone integrations: introduced integrations with Qdrant and Pinecone to power text/image similarity queries
- Point cloud-only datasets: you can now create datasets composed only of point cloud samples and visualize them in the App’s grid view
Check out the release notes for a full rundown of additional enhancements and bugfixes in FiftyOne 0.20.
By the way, FiftyOne Teams 1.2 is also generally available! Check out the FiftyOne Teams 1.2 release blog post to explore what’s new (it’s fully compatible with your existing FiftyOne workflows).
Join us for a live demo and AMA on April 20 @ 10 AM PT
We demoed all of the new features in FiftyOne 0.20, and now that the event has passed, you can see all of the new features in action in the blog post recap and webinar playback!
Now, here’s a quick overview of some of the new features we packed into this release.
Natural language search
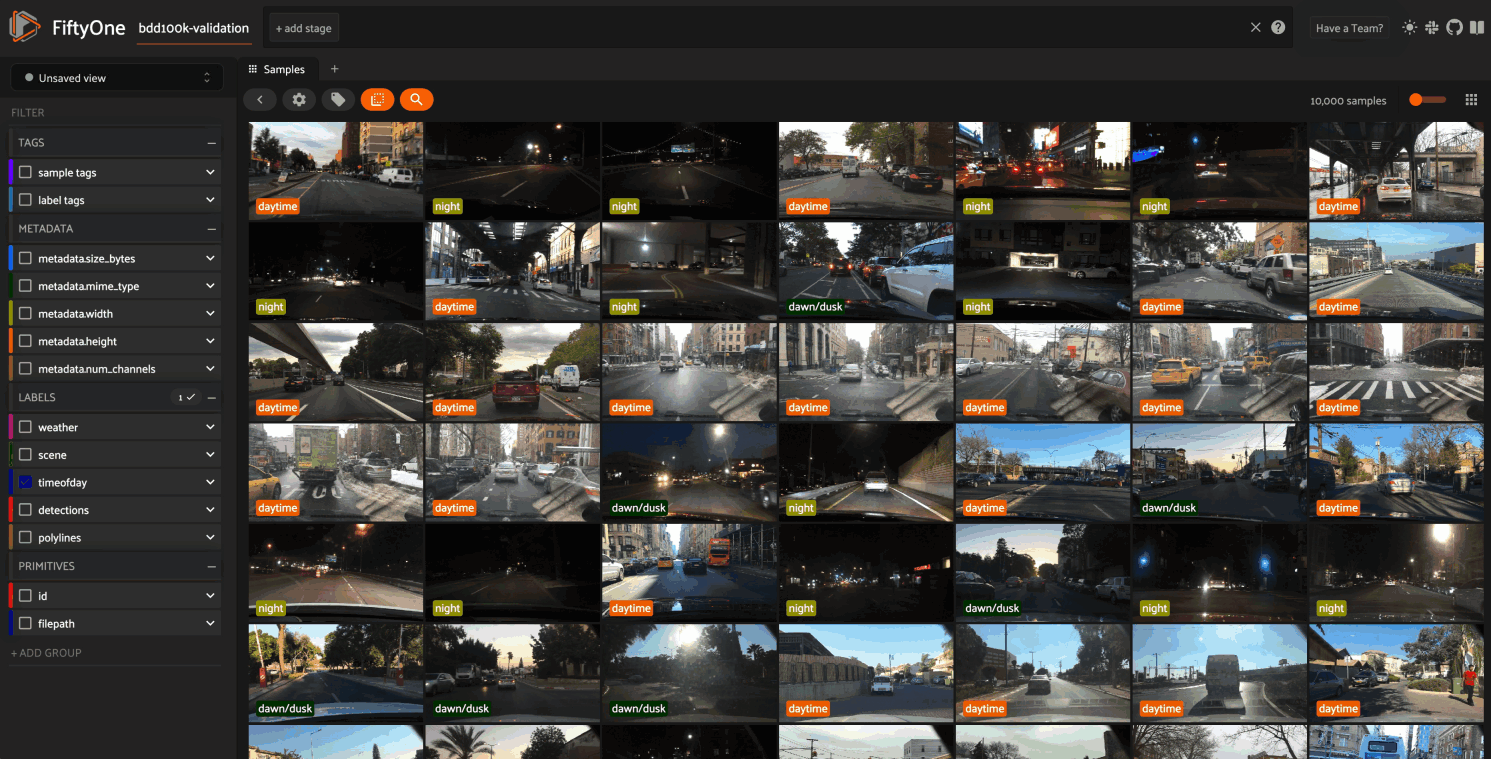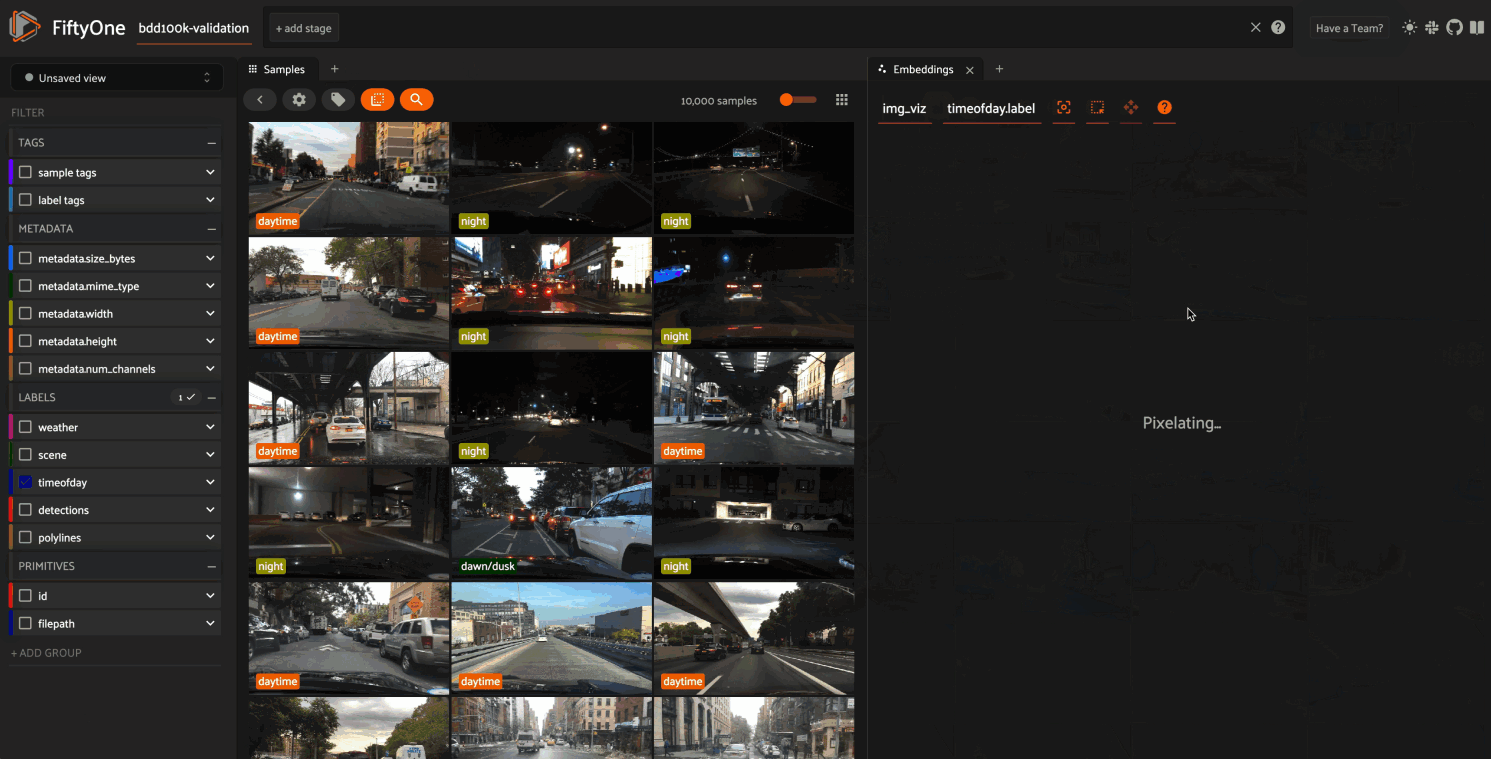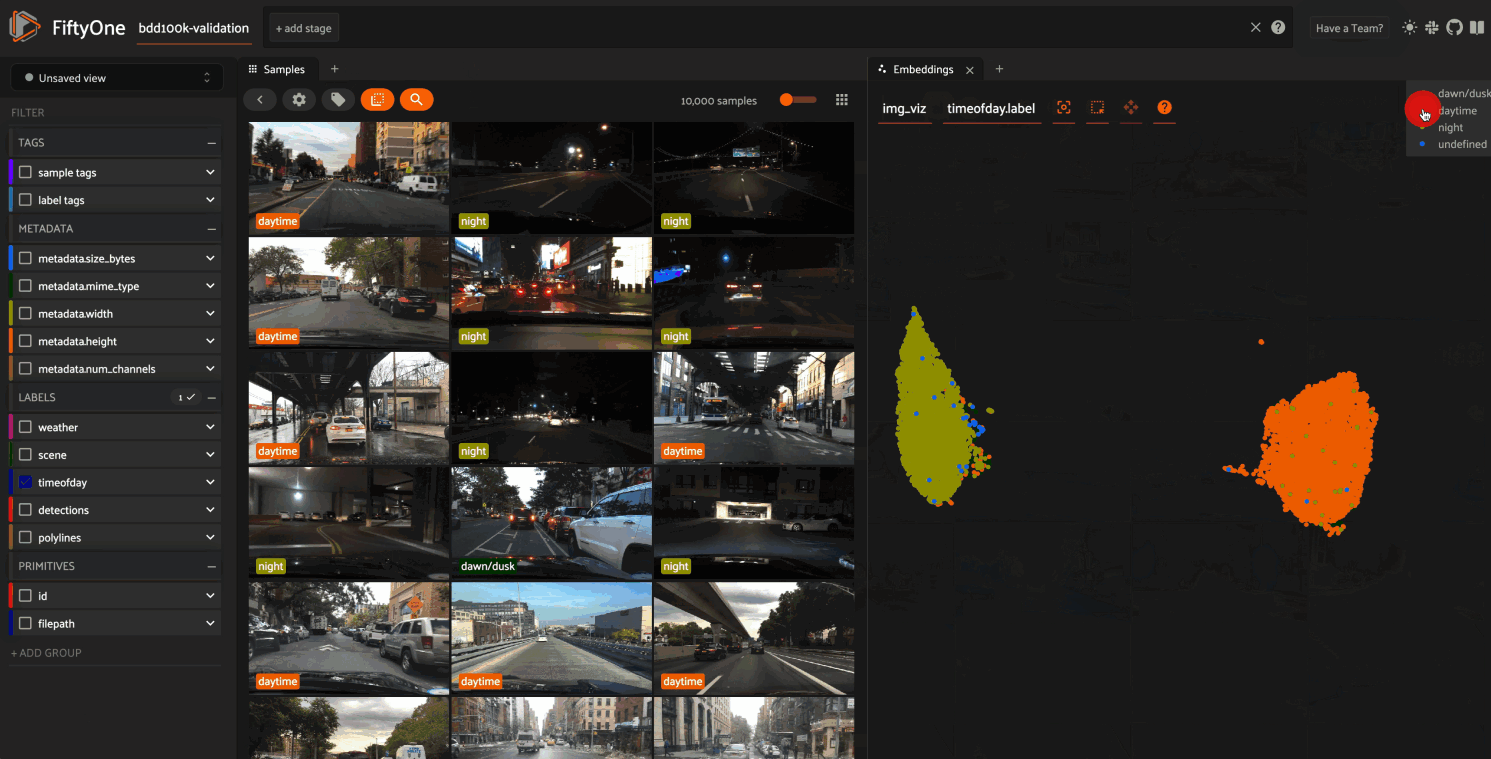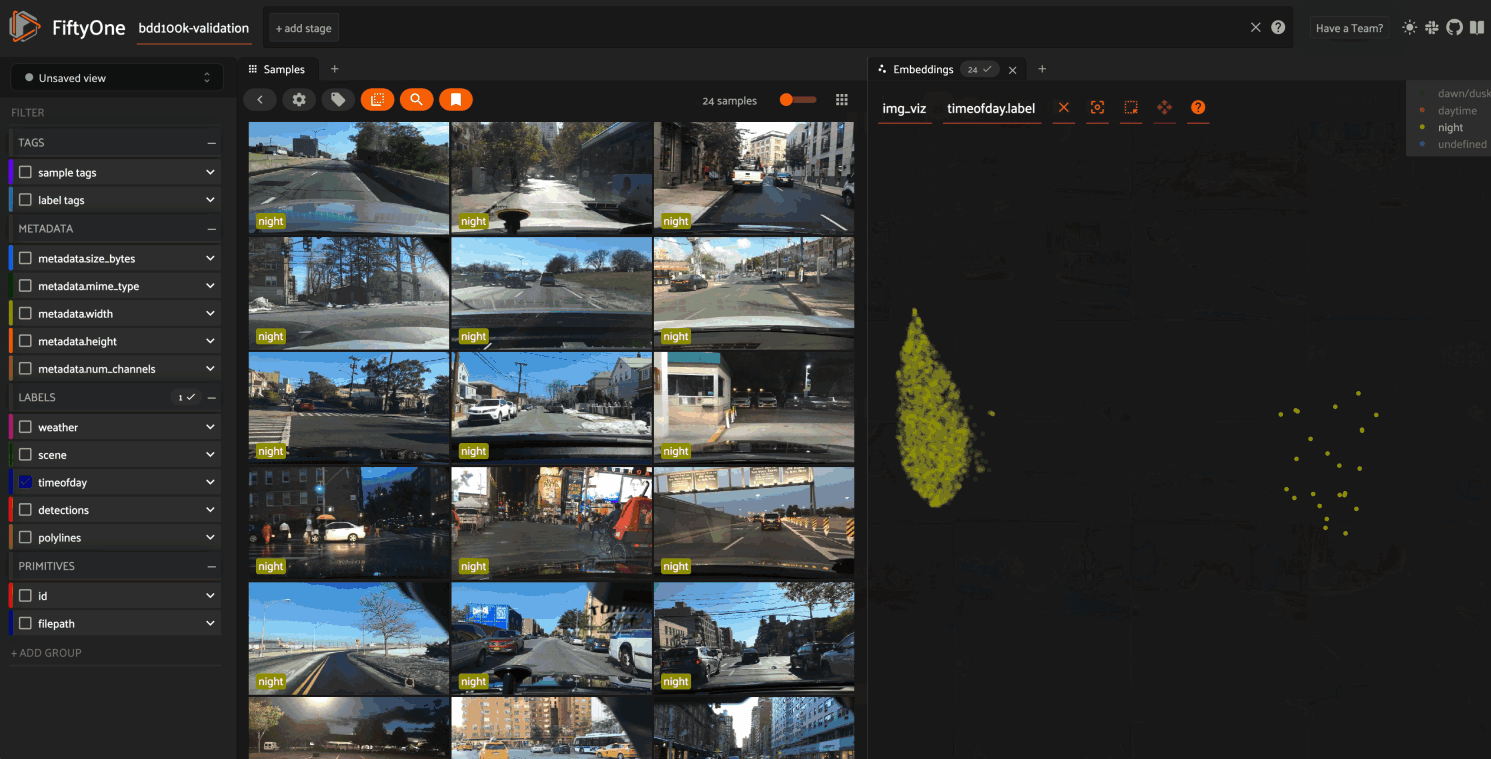
FiftyOne 0.20 introduces the ability to query your datasets by arbitrary text, enabling you to explore the content of your datasets with amazing fidelity in a completely unsupervised manner. You’ve gotta try it!
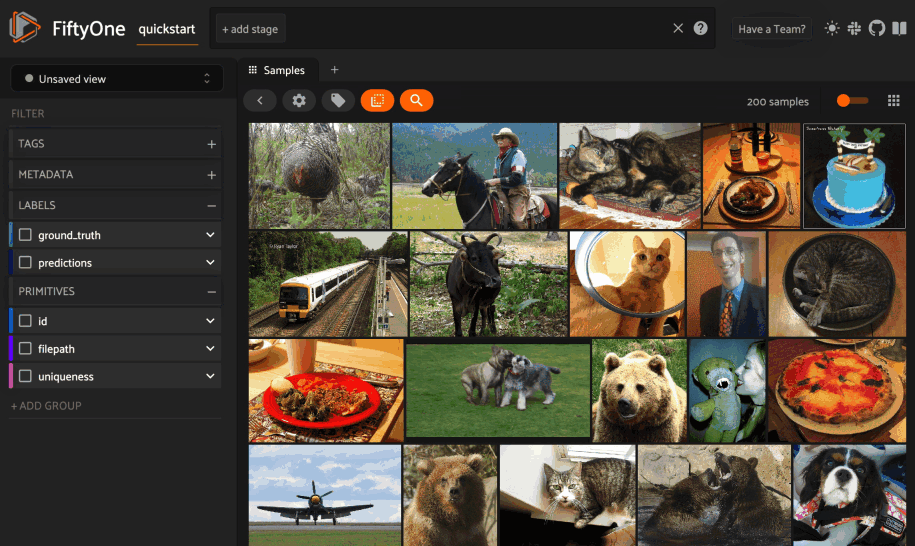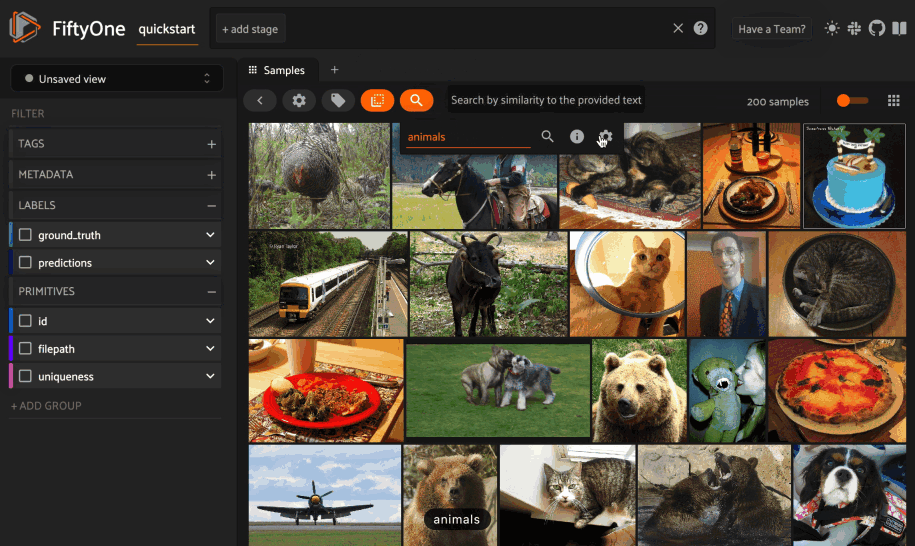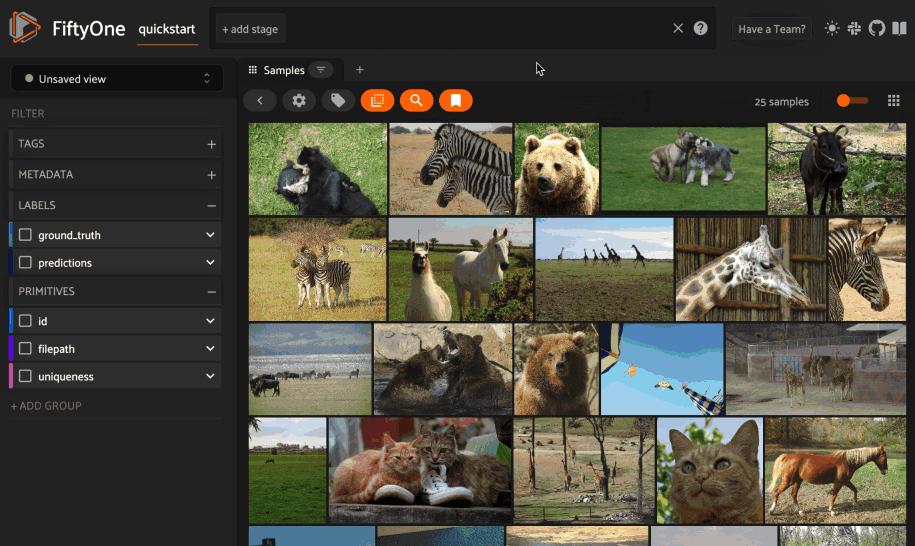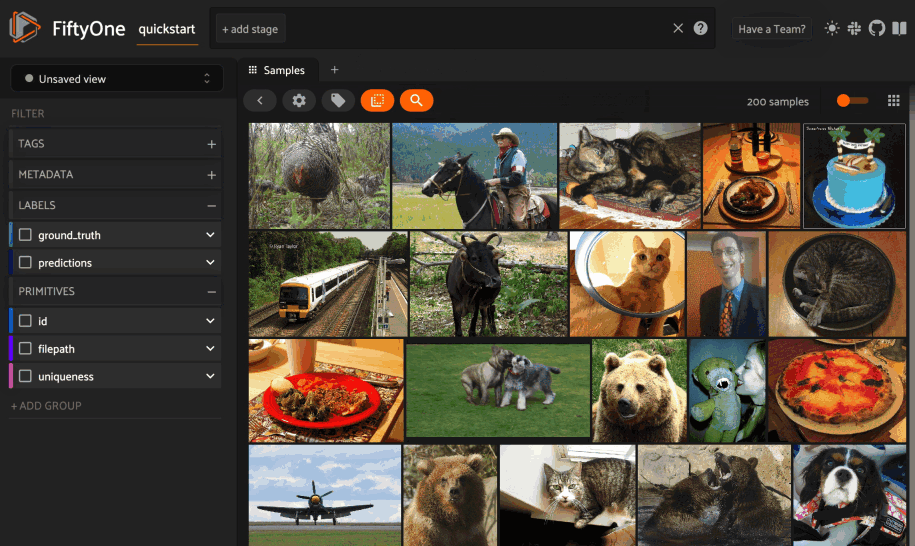
To enable natural language search on your datasets, simply follow these instructions to add multimodal embeddings to your dataset:
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
# Index images
fob.compute_similarity(
dataset,
model="clip-vit-base32-torch",
brain_key="img_sim",
)
session = fo.launch_app(dataset)
Whenever your dataset has one or more similarity indexes that contain multimodal embeddings, you can search your current dataset or view by typing anything into the text prompt above the App’s grid.
You can also specifically index the object patches in a field of your dataset:
# Index object patches in `ground_truth` field
fob.compute_similarity(
dataset,
patches_field="ground_truth",
model="clip-vit-base32-torch",
brain_key="gt_sim",
)
And then query the patches by natural language via the same workflow in the App whenever you’re working with a patches view:
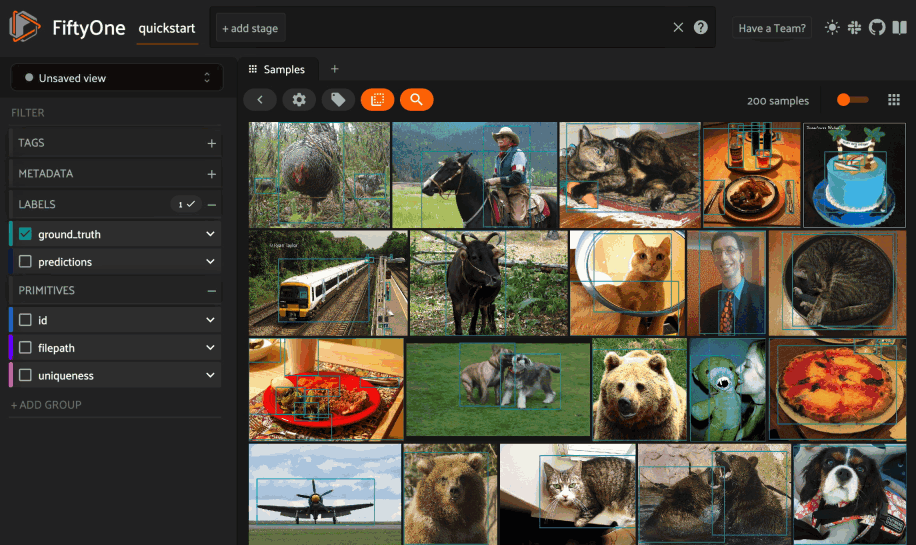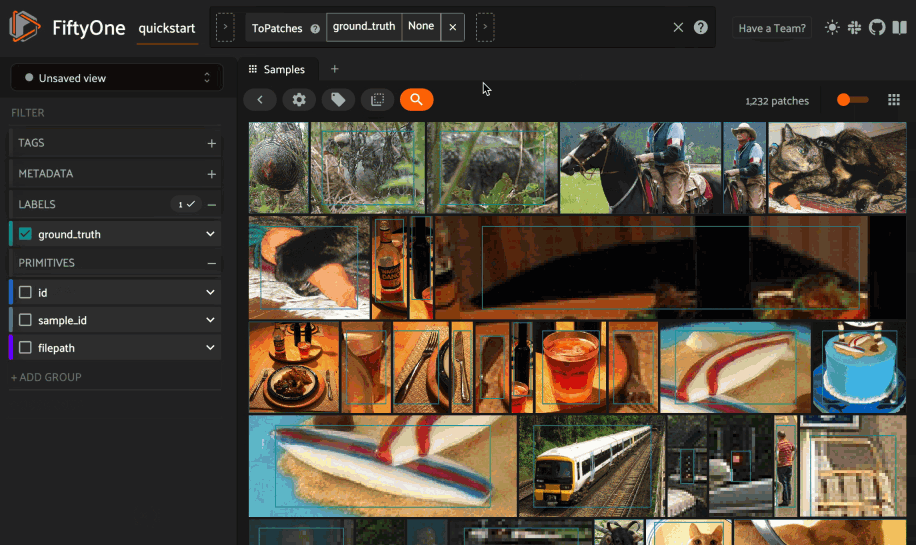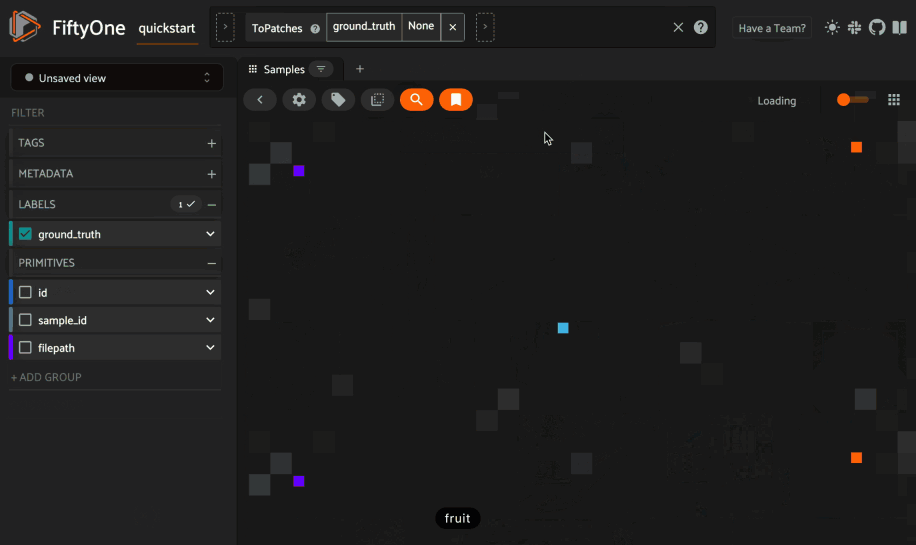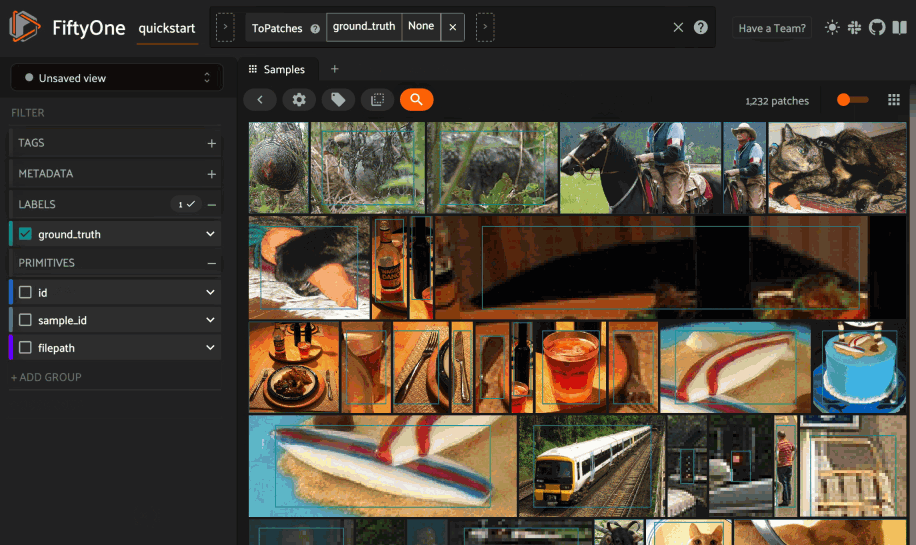
As usual, you can also perform natural language queries natively from Python:
# Text query on entire images
query = "kites high in the air"
view = dataset.sort_by_similarity(query, k=15, brain_key="img_sim")
# Text query on object patches
query = "cute puppies"
patches = dataset.to_patches("ground_truth")
view = patches.sort_by_similarity(query, k=15, brain_key="gt_sim")
# Load view in the App
session.view = view
Check out the docs for more information about using natural language search on your datasets.
Similarity API
FiftyOne 0.20 brings significant upgrades to the FiftyOne Brain’s similarity API, which provides the backbone on which features like natural language search are implemented.
Previously, similarity indexes were static objects that could not be edited in-place once they were created. FiftyOne 0.20 introduces new syntaxes and methods to create, customize, and edit your similarity indexes:
1. Initialize an empty index (with a customizable backend!)
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
image_index = fob.compute_similarity(
dataset,
model="clip-vit-base32-torch", # custom model
embeddings=False, # add embeddings later
backend="sklearn", # custom backend
brain_key="img_sim",
)
2. Add vectors to an existing index:
image_index.add_to_index(embeddings, sample_ids)
3. Retrieve vectors from an index:
ids = dataset.take(50).values("id")
embeddings, sample_ids, _ = image_index.get_embeddings(sample_ids=ids)
4. Remove vectors from an index:
image_index.remove_from_index(sample_ids=ids)
Check out the docs for more information about creating, customizing, and editing similarity indexes on your datasets.
Qdrant and Pinecone integrations
Qdrant and Pinecone are two of the most popular vector search databases available, and FiftyOne 0.20 introduces native integrations with these tools that make it easy to use an external vector database to power similarity searches on your FiftyOne datasets!
Once you’ve configured your backend (Qdrant|Pinecone), connecting to your vector database is as simple as providing the optional backend parameter when creating a new similarity index:
import fiftyone.brain as fob
index = fob.compute_similarity(
dataset,
...,
backend="qdrant|pinecone",
brain_key="img_sim",
)
Once the index is created, you can run any of the workflows we’ve already covered and the necessary nearest neighbor queries will be automatically performed against the external service.
For more information about connecting to an external vector database, check out the integration docs below:
And, for a deep dive into a vector search use case, check out the blog post tutorial: A Google Search Experience for Computer Vision Data: How to Use Vector Search Engines, NLP, and OpenAI’s CLIP in FiftyOne.
Point cloud-only datasets
FiftyOne 0.20 also includes some key enhancements for 3D tasks.
In previous FiftyOne versions, the only way to work with point cloud datasets in the App was to add point cloud samples as slices of grouped datasets that also contain other media modalities (image, video, etc). However, in FiftyOne 0.20 you can now create datasets that contain only point cloud samples and work with them natively in the App’s grid and modal views.
In order to visualize your point cloud samples in the App’s grid view (standalone or grouped datasets), use the builtin compute_orthographic_projection_images() utility to generate projections of your point clouds:
import fiftyone as fo
import fiftyone.utils.utils3d as fou3d
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart-groups")
fou3d.compute_orthographic_projection_images(dataset, (-1, 512), "/tmp/proj")
session = fo.launch_app(dataset)
When available, orthographic projections are automatically used by the App to render point cloud data in the grid. Any 3D detections or 3D polylines on your dataset are dynamically overlaid on the projections as well, and you can filter by/toggle visibility of these fields just as you do with image/video datasets:
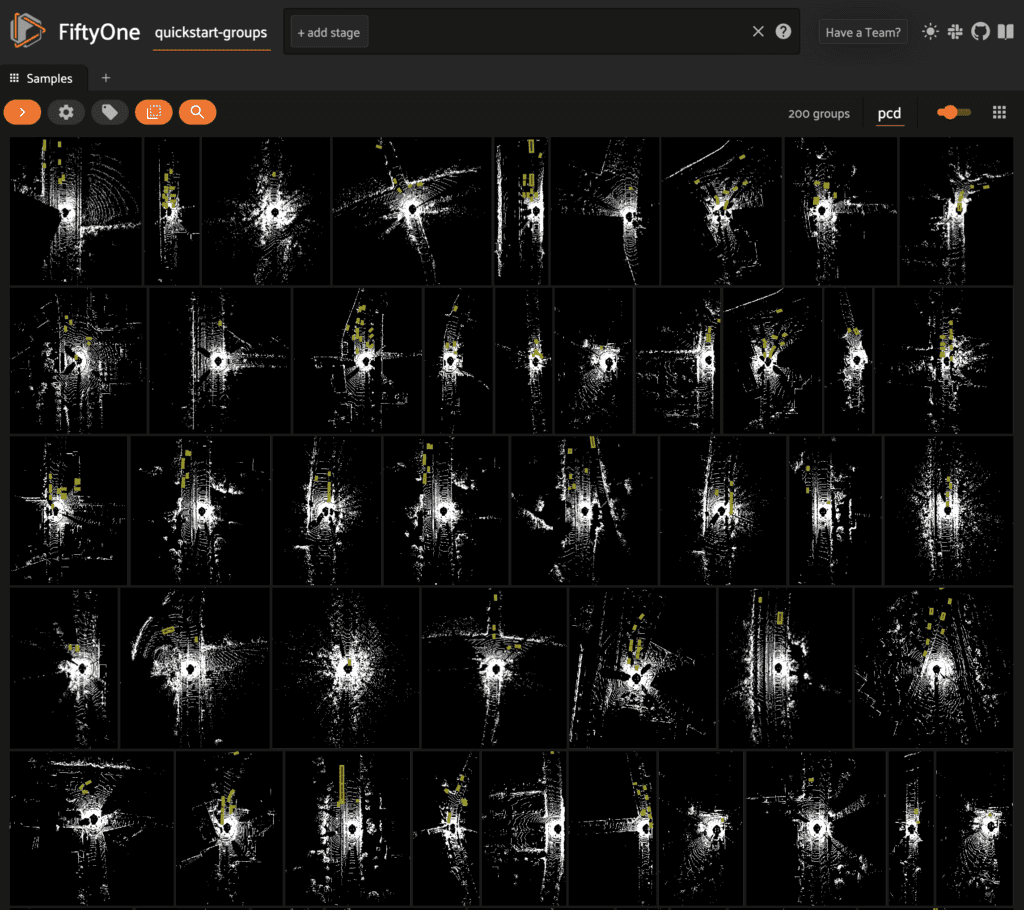
Other enhancements to the 3D experience in the App include:
- Support for adjusting the point size of point clouds in the 3D Visualizer
- Support for rendering a grid floor in the 3D Visualizer
- Support for showing/hiding individual sections of the grouped viewer
- The App will now remember your 3D Visualizer settings between sessions!
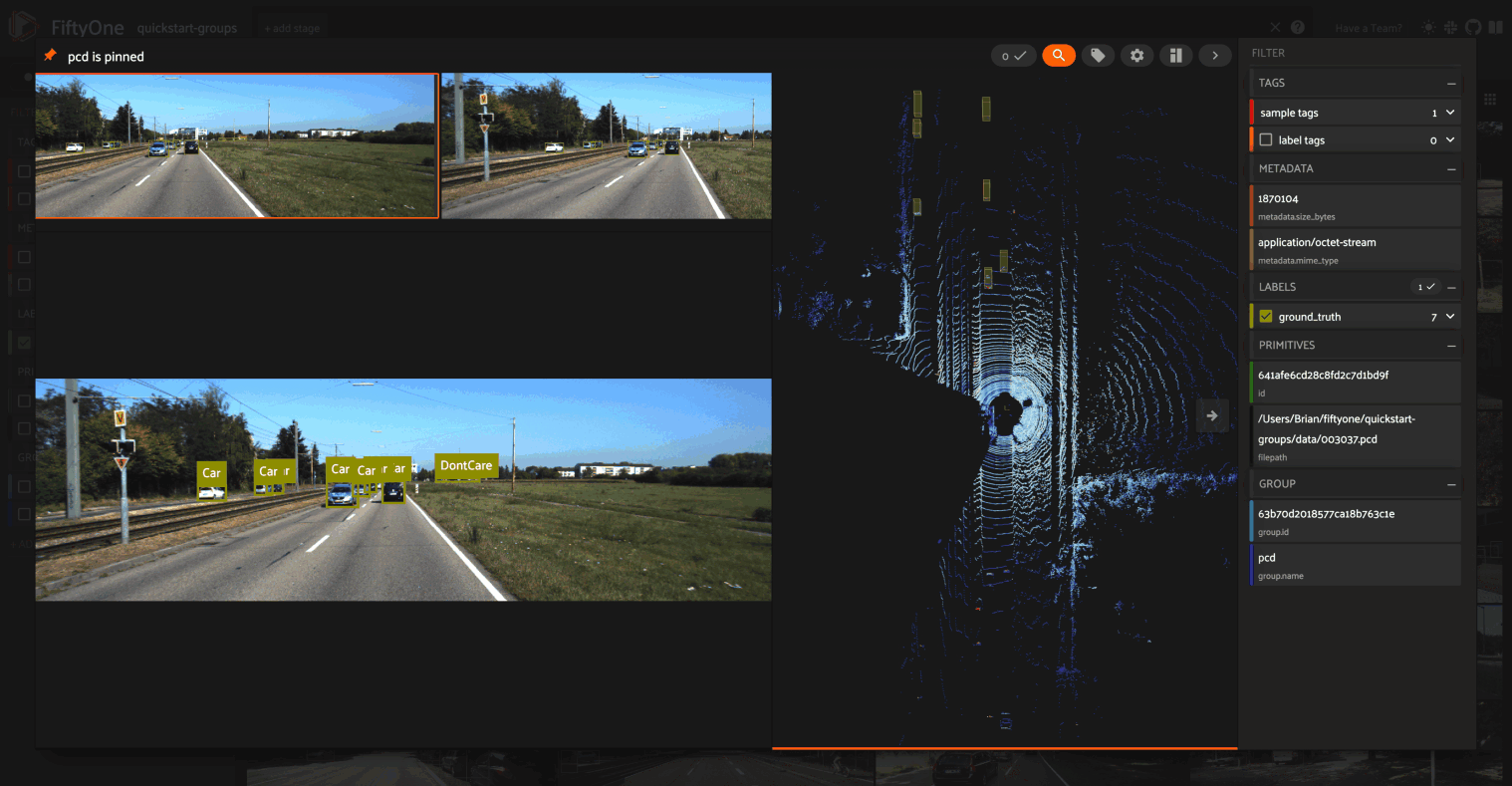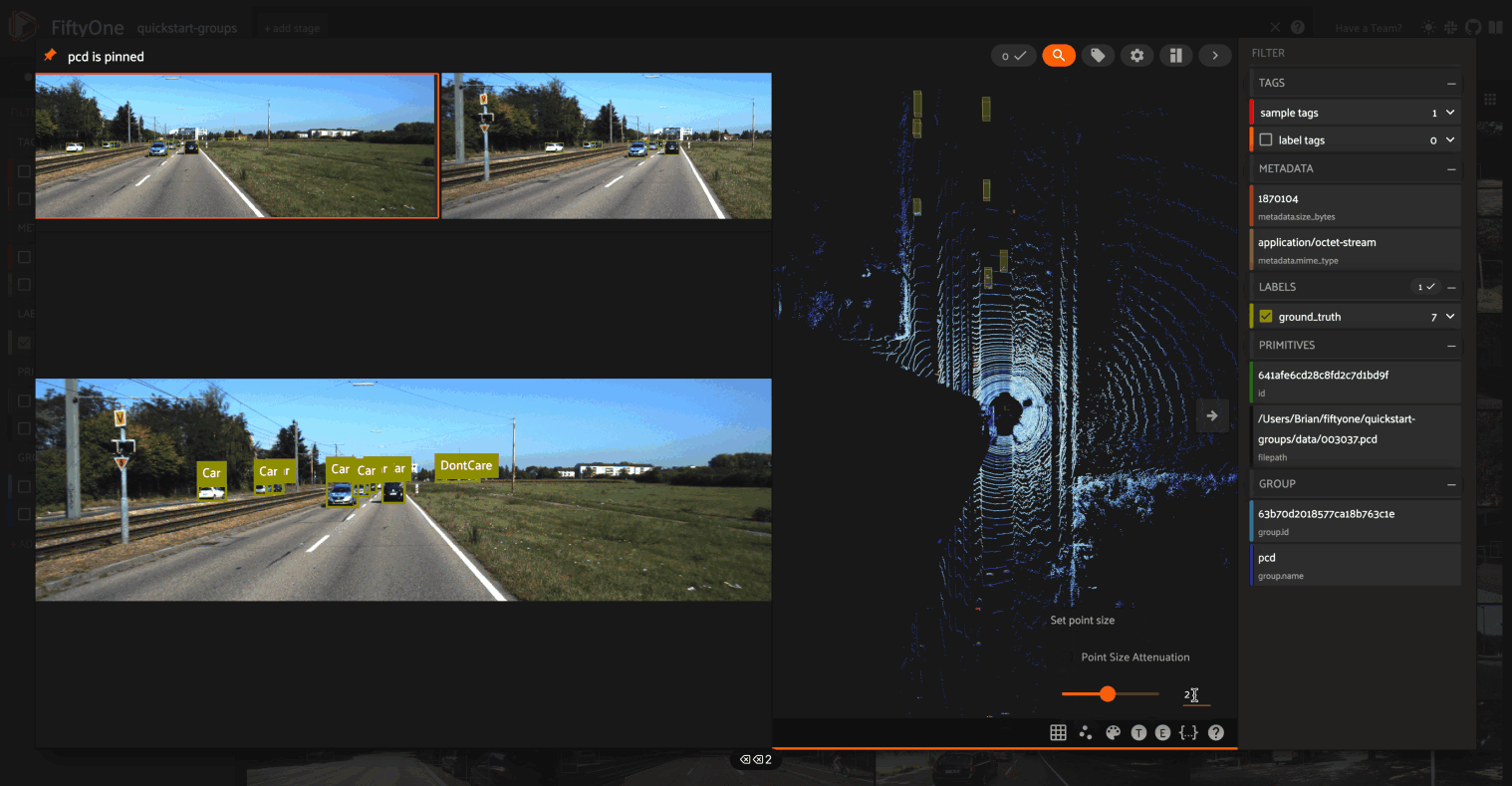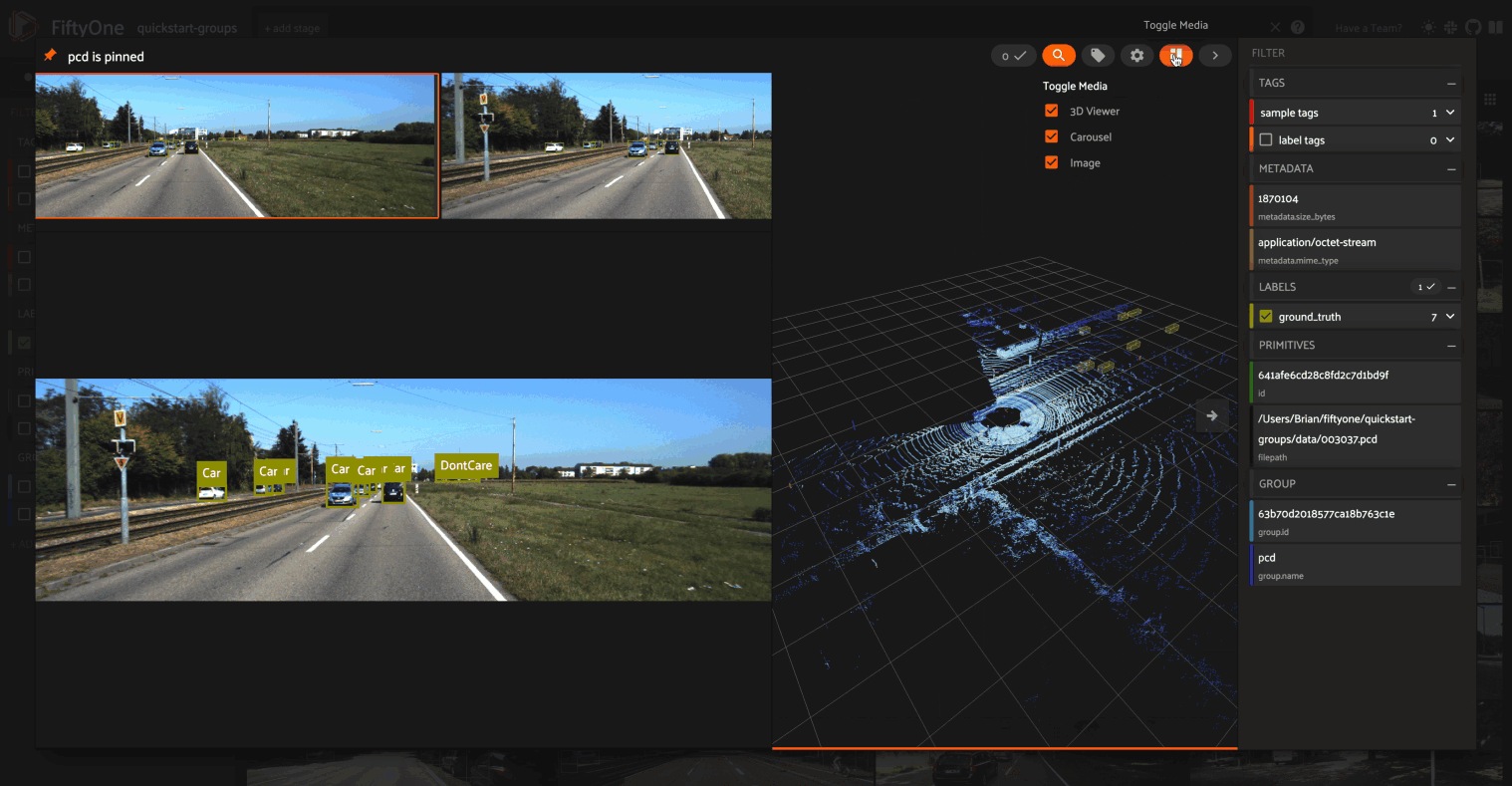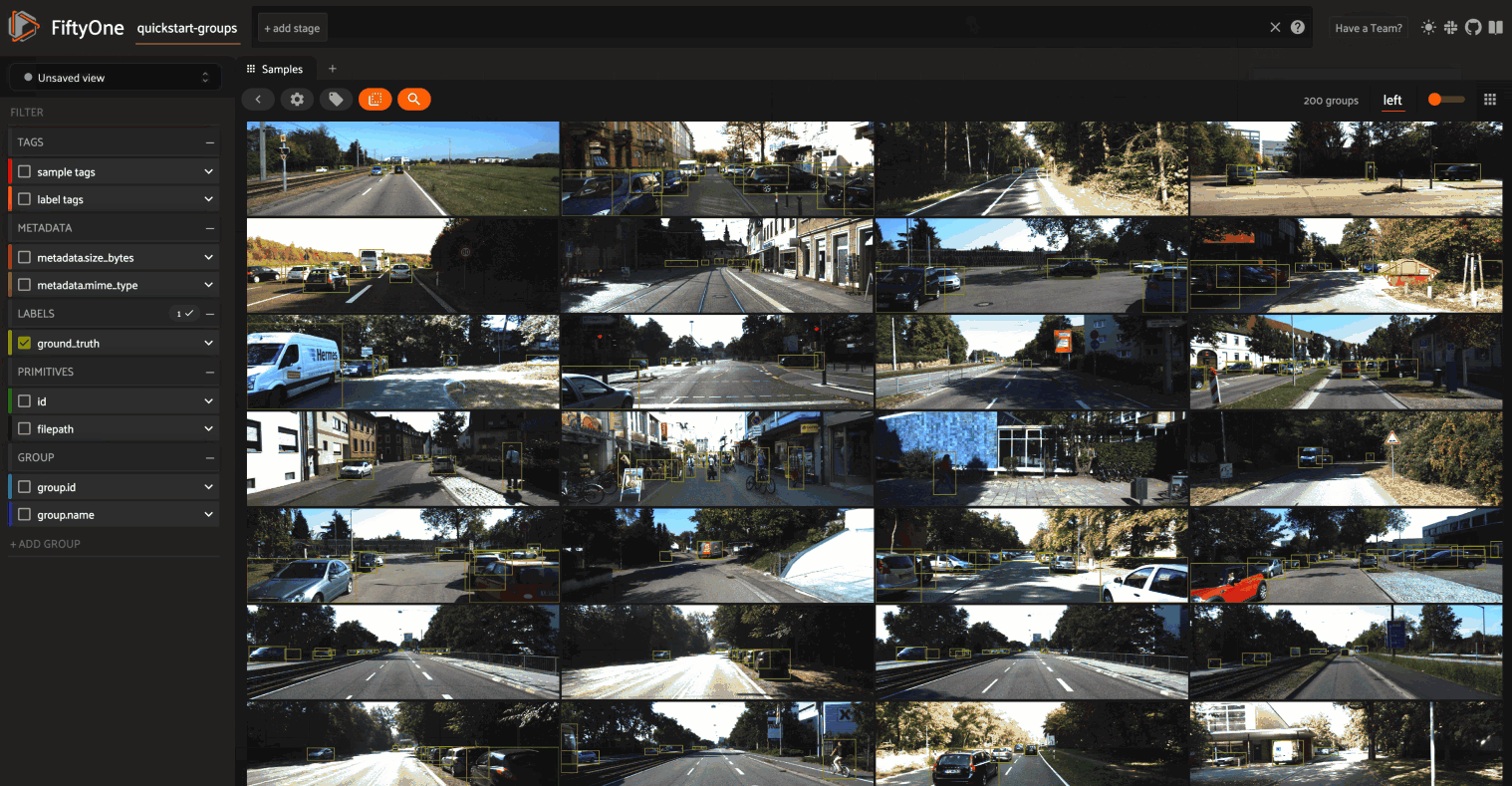
Check out the docs for more information about adding point cloud samples and orthographic projections to your FiftyOne datasets and visualizing them in the App.
Curious to see how point cloud data is used in practice? Check out our new blog post tutorial: A Better Way to Visualize 3D Point Clouds and Work with OpenAI’s Point-E.
Community contributions
Shoutout to the following community members who contributed to this release!
- Joy Timmermans contributed #2716- Adding ability to pass CVAT organization for annotations
- Akshit Priyesh contributed #2774 – fix app crash while filtering keypoints
- Kishan Savant contributed #2771 – fix broken torchvision dataset links
FiftyOne community updates
The FiftyOne community continues to grow!
- 1,450+ FiftyOne Slack members
- 2,700+ stars on GitHub
- 3,400+ Meetup members
- Used by 264+ repositories
- 58+ contributors

