Welcome to Voxel51’s bi-weekly digest of the latest trending AI, machine learning and computer vision news, events and resources! Subscribe to the email version.
📰 The Industry Pulse
Voxel51 Just Closed Its Series B!

Voxel51 just raised $30M in Series B funding led by Bessemer Venture Partners!
So, what are we gonna do with all that money? Make visual AI a reality! AI is moving fast, and visual AI will see massive growth and progress because of the abundance of image and video data. Now, more than ever, practitioners need tools to understand, explore, visualize, and curate datasets. We hope to make this more accessible for the community with FiftyOne.
The new funding will allow us to scale our team, support our open-source community, build a research team, and accelerate our product roadmap to support new data modalities and deeper integrations with the AI stack.
Hugging Face is the Robin Hood of GPUs

Ok, that’s probably not the best analogy because I’m sure they’re not robbing the rich. But they are giving to the poor…the GPU poor, that is.
Our friends at Hugging Face are investing $10 million in free shared GPUs through the ZeroGPU program to help developers, academics, and startups create new AI technologies!
Clem, the Hugging Face CEO, believes that if a few organizations dominate AI, it will be harder to fight later on. They hope to counter the centralization of AI advancements by tech giants like Google, OpenAI, and Anthropic, who have a significant advantage due to their vast computational resources. ZeroGPU lets multiple users or applications access shared GPUs concurrently, eliminating the need for dedicated GPUs and making them cost-effective and energy-efficient.
I hope this levels the playing field for smaller companies and GPU-poor indie hackers (like myself) who can’t commit to long-term contracts with cloud providers for GPU resources.
Investing in the community and promoting open-source AI is a win-win for everyone; it’s our greatest hope for a decentralized and accessible AI landscape.
California is pushing for safer AI!
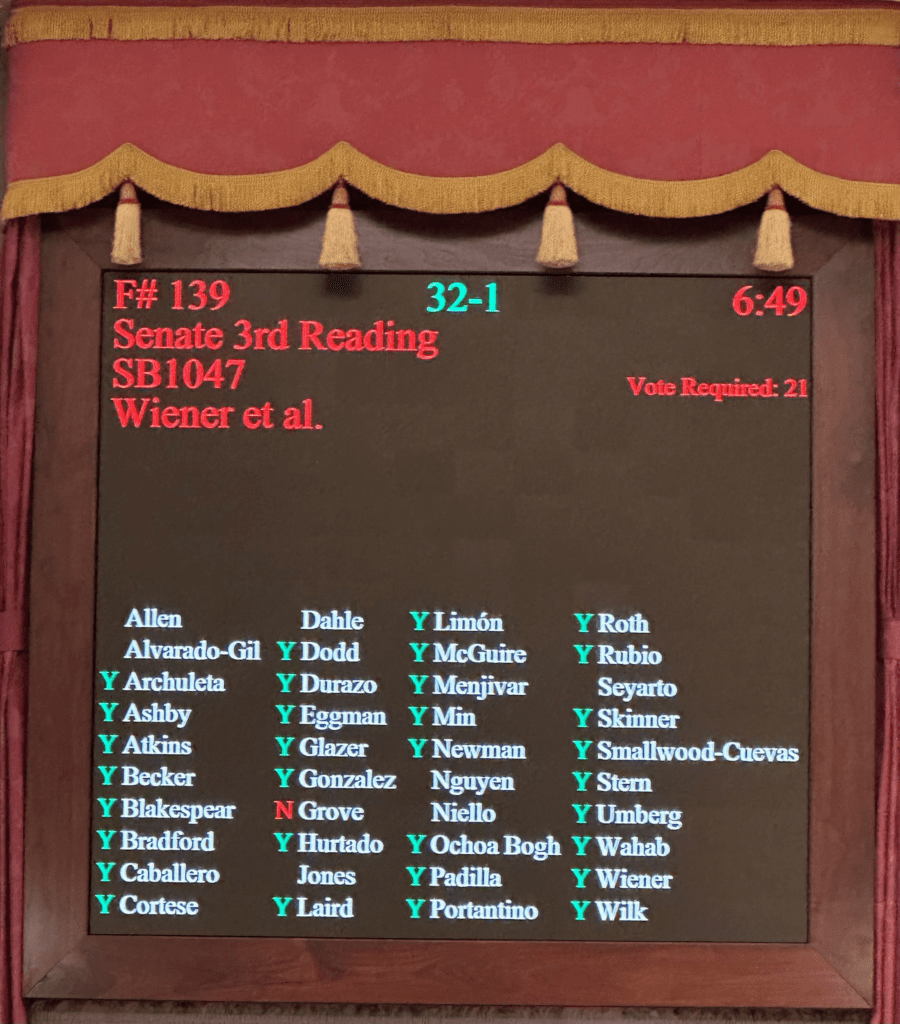
The Senate just passed SB 1047, dubbed the “Safe and Secure Innovation for Frontier Artificial Intelligence Models Act, a bill focused on ensuring the development of powerful AI is safe and responsible. Here’s the rundown:
- Strict Rules for Big AI: Companies making large, expensive AI models (think over $100 million to train) must follow specific safety rules. These include testing before release, strong cybersecurity, and monitoring after launch.
- Whistleblower Protection: People working in AI labs will now have protection if they speak up about safety concerns.
- Fair Pricing: No more price gouging or unfair pricing practices for AI tech.
- CalCompute: The state will create a public cloud system called CalCompute, which will give startups and researchers the tools to work on big AI projects.
- Open-Source Support: A new advisory council will help guide the development of safe and secure open-source AI. I just hope they put the right people on this council because it would be a major mistake if they had people from the tech giants on it.
This bill has the backing of big names in AI, like Geoffrey Hinton and Yoshua Bengio. It still needs to pass in the Assembly by August 31st, so let’s see what happens!
GitHub Gems: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers

Imagine a single, powerful AI artist that can take your written descriptions and create stunning images, videos, and even 3D models. That’s what Lumina-T2X aims to be, and by sharing their work openly, the creators are inviting others to join them in pushing the boundaries of generative AI
While impressive, models like Sora and Stable Diffusion 3 lack detailed documentation and open-source code, making them hard to study and build upon. These models are often specialized for a single task (like image generation) and struggle to adapt to other modalities (like video). Lumina-T2X, however, transforms text into many modalities, resolutions, and durations using flow-based large diffusion transformers (Flag-DiT).
It’s also open source so researchers can study and build upon them! So, what is this model capable of? Check it out:
- Lumina-T2I (Text-to-Image): Generates realistic images at arbitrary resolutions and aspect ratios. It can even extrapolate to resolutions higher than those seen during training.
- Lumina-T2V (Text-to-Video): Creates 720p videos of varying lengths and aspect ratios, showing promise in generating coherent scenes and transitions
- 3D Object and Audio Generation: While less detailed in the paper and repo, they also note the potential for generating multi-view 3D objects and audio from text.
It can do this via some unique innovations:
- Flag-DiT Architecture: This core component is inspired by Large Language Models (LLMs) and incorporates techniques like RoPE, RMSNorm, and flow matching for improved stability, flexibility, and scalability.
- Flag-DiT supports up to 7 billion parameters, extends sequence lengths (up to 128,000 tokens) and has faster training convergence and stable training dynamics.
- Lumina-T2X cleverly represents different media types (images, videos, etc.) as sequences of tokens, similar to how LLMs process text. The model can encode any modality (images, videos, multi-views of 3D objects, spectrograms) into a unified 1-D token sequence at any resolution, aspect ratio, and temporal duration. This allows it to handle various modalities within a single framework. Honestly, this is wild. I can’t wait to write a more in-depth blog or tutorial with this plus FiftyOne.
- It’s very configurable, and you can experiment with different text encoders, DiT parameter sizes, inference methods, and features like 1D-RoPE and image enhancement.
- It supports resolution extrapolation, which enhances the resolution of images (or signals, in general) beyond the limits of the original captured data. This means you can generate images/videos with out-of-domain resolutions not encountered during training.
And also, look at the image above…you can synthesize images from emojis! That’s dope. You can learn more by checking out:
- The GitHub repository
- This YouTube Video
- The Lumina-T2X demo
- The Hugging Face Space (the same as the demo)
📙 Good Reads
Diffusion models feel like magic.
Over the last year, the magic has become increasingly real through impressive results in image synthesis. Now, this is being applied to the more challenging task of video generation. Video generation adds the complexity of requiring temporal consistency across frames and is limited by the difficulty of collecting large, high-quality video datasets.
In this super technical yet very approachable blog post by the incomparable Lilian Weng (from OpenAI), you’ll learn that diffusion models aren’t magic. They’re just a giant pile of linear algebra and computation!
The blog serves as a history and survey of diffusion models for video generation, which is a type of blog I absolutely love to read. Below are my main takeaways.
There are two main approaches to video generation with diffusion models:
1. Building from the Ground Up
This approach involves designing and training diffusion models specifically for video. Key techniques include:
- 3D U-Nets: Extending the successful 2D U-Net architecture to 3D by separating spatial and temporal processing. Spatial layers handle individual frames using 3D convolutions and attention, while temporal layers utilize attention mechanisms across frames to ensure smooth transitions.
- Diffusion Transformers (DiT): This architecture processes videos as sequences of spacetime patches, leveraging Transformers’ power to capture complex relationships within and across frames.
- Reconstruction Guidance: This method conditions the generation of subsequent frames on preceding ones, ensuring a coherent narrative flow.
2. Leveraging Image Power
This approach cleverly adapts pre-trained image diffusion models for video generation, capitalizing on the rich knowledge acquired from vast image datasets. This can be achieved through:
- Fine-tuning: Adding temporal convolution and attention layers to pre-trained image models and then fine-tuning them on video data, allowing the model to learn video-specific dynamics.
- Zero-Shot Adaptation: Ingenious techniques like motion dynamics sampling, cross-frame attention, and hierarchical sampling enable video generation from image models without additional training.
Beyond Architecture:
As always, curating a dataset is critical for video generation performance.
- Dataset Curation: Filtering for high-quality, captioned video clips is crucial for training effective models.
- Training Strategies: Pre-training on large image datasets before fine-tuning on video data significantly boosts performance.
Diffusion models show great promise for high-quality video generation. However, ongoing research focuses on enhancing efficiency, improving temporal consistency, and achieving finer control over the generated content. As these challenges are addressed, we can expect even more impressive and realistic videos generated by AI in the near future.
🎙️ Good Listens
Dwarkesh blesses us with another banger episode featuring OpenAI co-founder John Schulman.
This podcast episode takes you straight to the bleeding edge of AI with John Schulman, the mastermind behind ChatGPT and co-founder of OpenAI. It’s your chance to get a glimpse into the mind of one of the people shaping the future of, well, everything.
Admittedly, I have a mind that is easily blown, but…this is, indeed, a mind-blowing conversation about where AI is, where it’s going, and what happens when things intelligence gets general and AI becomes as intelligent as us. Spoiler alert: it involves a whole lot of careful planning and a little bit of freaking out.
John shares how OpenAI thinks about these challenges, from making sure AI stays in its lane to figuring out how to hit the brakes if things start moving too fast or swerving into oncoming traffic.
Here are some things they discuss on the show:
- Pre-training vs. Post-training: Schulman explains the difference between pre-training, where models learn to imitate internet content, and post-training, where they are refined for specific tasks like being helpful assistants.
- Future Capabilities: He predicts models will soon handle more complex, multi-step tasks, like coding projects, due to improved long-horizon coherence and sample efficiency.
- Generalization: Schulman highlights the remarkable ability of these models to generalize from limited data, such as learning to function in multiple languages or avoid making unrealistic claims.
- Path to AGI: While acknowledging the possibility of AGI emerging sooner than expected, Schulman emphasizes the need for caution and coordination among AI developers to ensure safe deployment.
- Safety and Alignment: He outlines potential safeguards, such as sandboxing, monitoring, and red-teaming, to mitigate risks associated with highly capable AI systems.
Hypothetical Scenario:
The interview goes into a hypothetical scenario where AGI arrives in the next few years. Schulman and Dwarkesh discuss the importance of:
- Pausing further training and deployment.
- Coordinating among AI labs to establish safety protocols.
- Developing robust testing and monitoring systems.
This conversation is a must-listen for anyone even remotely interested in the future that AI is building. Schulman doesn’t shy away from the big questions about AGI and its implications. He hints that incredibly powerful AI systems could become a reality sooner than we think while underscoring the immense responsibility that comes with this power.
If you’re reading this, chances are you’re likely not just passively observing the development of AI; you’re an active participant in shaping its trajectory. The choices made today by people like us – researchers, developers, practitioners and policymakers – will determine whether this powerful technology ushers in an era of unprecedented progress or leads us down a more dangerous path.
👨🏽🔬 Good Research: Deciphering the Code of Vision-Language Models: What Really Matters?
Modern Vision-Language Models (VLMs) have remarkable capabilities.
They can “see” an image, understand and answer complex questions, generate detailed captions, or even write a story inspired by the scene. However, building these powerful models involves navigating a maze of design choices, from choosing the right architecture to selecting the best pre-trained components and optimizing the training process.
The paper What matters when building vision-language models?, like its title, asks an important question: What truly matters when building high-performing VLMs?
Rather than relying on intuition or anecdotal evidence, the authors embark on a rigorous experimental journey to uncover the impact of key design decisions. Through extensive ablations and analysis, the authors share six findings that provide valuable guidance for VLM development:
- Pre-trained backbones matter, a lot: The quality of both vision and language backbones significantly impacts the final VLM performance. Notably, the language model’s quality matters more for a fixed parameter count. This highlights the importance of strong unimodal foundations.
- Fully autoregressive vs. cross-attention: While cross-attention architectures excel when backbones are frozen, fully autoregressive models outperform them when backbones are trained, even with fewer parameters. However, training fully autoregressive models with unfrozen backbones can be unstable.
- LoRA for Stability and Efficiency: Low-rank adaptation (LoRA) stabilizes the training of fully autoregressive models with unfrozen backbones and allows for training with a lower memory footprint.
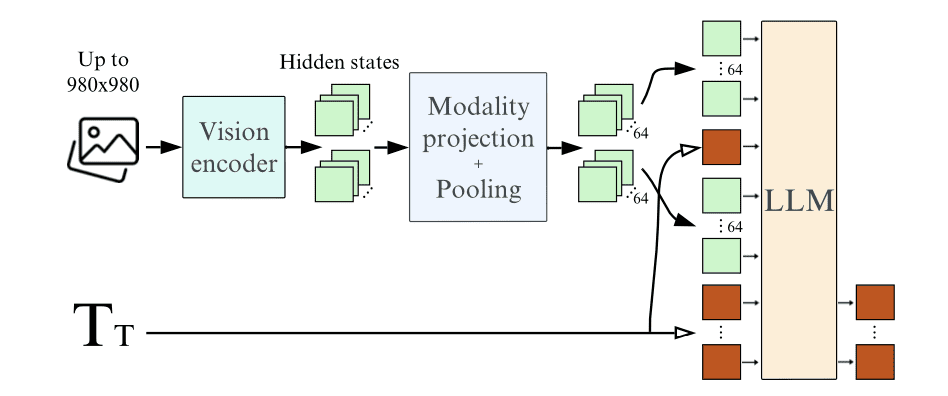
- Learned Pooling for Efficiency: Reducing the number of visual tokens through learned pooling significantly improves training and inference efficiency without sacrificing performance. This contrasts with previous findings that more visual tokens lead to better results.
- Preserving Aspect Ratio and Resolution: Adapting vision encoders to handle variable image sizes and aspect ratios maintains performance while offering flexibility and efficiency during training and inference.
- Image Splitting for Performance: Splitting images into sub-images during training boosts performance, especially for tasks involving text extraction, at the cost of increased computational cost.
The authors use these findings to build the Idefics2-8B model. By the way, I just added support for Idefics2-8B via the Replicate API to our VQA Plug-in for FiftyOne!
Now, I’ll summarize the paper using the PACES method.
Problem
The main problem the paper tackles is the lack of clarity and systematic understanding regarding which design choices truly contribute to better performance in Vision-Language Models (VLMs). The authors aim to bring more rigorous experimental evidence to the field of VLMs. They investigate existing architectural and training choices to determine their impact on VLM performance. They then use these findings to guide the development of their high-performing Idefics2 model.
The paper focuses on improving the design and training of VLMs through a better understanding of existing techniques and their practical implications.
Approach
The paper investigates the impact of different design choices in Vision-Language Models (VLMs) by conducting extensive ablation studies on model architectures, pre-trained backbones, and training procedures. Using a fully autoregressive architecture with LoRA for training stability, learned pooling for efficiency, and carefully chosen pre-trained backbones leads to superior VLM performance, as demonstrated by their Idefics2 model.
Claim
The authors claim that their rigorous analysis of various design choices in Vision-Language Models provides much-needed clarity and experimentally-backed guidance for building higher-performing VLMs.
Evaluation
The paper evaluates its approach by conducting controlled experiments (ablations) to compare different design choices in VLMs.
They use four main benchmarks for evaluation: VQAv2, TextVQA, OKVQA, and COCO, covering visual question answering, OCR abilities, external knowledge, and image captioning. The baselines consist of different configurations of VLMs, varying architecture, pre-trained backbones, and training methods. The evaluation setup seems sound and aligns well with the paper’s goal of understanding the impact of design choices on VLM performance. They primarily focus on 4-shot performance, emphasizing few-shot learning capabilities.
One potential limitation is the reliance on a relatively small number of benchmarks, which might not fully capture the nuances of different design choices across a wider range of VLM tasks.
Substantiation
The paper successfully substantiates its claim by demonstrating through empirical evidence that carefully considering architectural and training choices significantly impacts VLM performance. The authors’ rigorous ablations and the resulting high-performing Idefics2 model provide valuable, practical guidance for the VLM research community.
This research provides a data-driven roadmap for building better VLMs, moving beyond intuition to understand what drives performance. The authors’ rigorous evaluations and the resulting Idefics2-8B model empower researchers to build more capable and efficient VLMs, pushing the boundaries of machine perception.
🗓️. Upcoming Events
Check out these upcoming AI, machine learning and computer vision events! View the full calendar and register for an event.