A guided walkthrough to tracking curation and evaluation
In the ever evolving field of computer vision and object tracking, working with tracking datasets has been a tough skill to master. Tracking datasets serve as the backbone for testing and validating the latest and greatest algorithms. However, the significant increase in metadata as well as the complexity of the annotations make it hard at times for researchers or engineers to drive insights into their dataset.
FiftyOne streamlines the experience of working with tracking datasets for you allowing you to easily load the videos and detections, compute and store statistics of the trajectories, visualize both ground truth and predicted trajectories and create an assessment using FiftyOne’s evaluation methods.
There is no better place to look for a tracking dataset to use as an example than MOT17. The Multi Object Tracking dataset has been a pillar of support in the CV tracking community for many years now due to its well defined dataset, and easy to load labels.
tl:dr
If you want to jump ahead, watch the video and/or download the notebook. Otherwise, follow along with the detailed steps in this post.
Let’s take a look at how we can load it into FiftyOne. First, download the dataset yourself first and unzip the files to get started.
Loading the Data
The dataset comes as image stacks. We will encode these image stacks into movies for use with FiftyOne.
DATA_DIR = "./MOT17"
mp4_dir = os.path.join(DATA_DIR,'movies')
!mkdir -p {mp4_dir}
# Movies numbers to encode
MOV_NUMS = [2,9]
for movi in MOV_NUMS:
mov_in = os.path.join(DATA_DIR,'train',f'MOT17-{movi:02}-FRCNN/img1/%06d.jpg')
mov_out = os.path.join(mp4_dir,f'MOT17-{movi:02}.mp4')
fouv.reencode_video(mov_in,mov_out)
Next we can create a FiftyOne dataset with our newly encoded videos easily with dataset.from_dir. We also call ensure_frames to pre-populate each of our samples with frames data. This allows us to work with both at the sample (video) level as well at the frame level.
dataset = fo.Dataset.from_dir(dataset_dir=mp4_dir,dataset_type=fo.types.VideoDirectory) dataset.ensure_frames()
Let’s name and set our dataset to persistent so we can come back to it later.
dataset.name = 'mots17' dataset.persistent = True
Printing our first sample shows us the metadata for the first video as well as the frames attribute attached to it. Frames are stored as an ordered dictionary containing Frames objects keyed by frame number.
sample = dataset.first() print(sample)
<Sample: {
'id': '654084daf5f90ee688fda4ae',
'media_type': 'video',
'filepath': '/home/dan/Documents/track/MOT17/movies/MOT17-02.mp4',
'tags': [],
'metadata': <VideoMetadata: {
'size_bytes': 19911561,
'mime_type': 'video/mp4',
'frame_width': 1920,
'frame_height': 1080,
'frame_rate': 25.0,
'total_frame_count': 600,
'duration': 24.0,
'encoding_str': 'avc1',
}>,
'frames': <Frames: 600>,
}>
💡 When indexing frames, make sure to use 1-based frame numbers
print(sample.frames[1])
<Frame: {'id': '65404f633efcd77d46bf152b', 'frame_number': 1}>
Loading Detections
With our videos ready in FiftyOne, next comes our detections! MOTS17 saves their detections in a csv file for each movie. The annotations include a bounding box, class, as well as an identity IDs. The identity ID make this problem a tracking problem and not just object detection. Detections must now be associated across frames as belonging to a certain object or trajectory.
Below we show how to load MOTS17 detection using a custom importer.The columns in the provided csv files, as well as the list of classes used, are as described in this paper. We are primarily interested in people, so we set some of the other class labels to “na”. We also replace the “Static person” class with simply “person” as we will not distinguish the two classes here. To start we define a function that will grab all of label data for the given frame.
GT_COLUMNS = ['frame','id','x0','y0','w','h','flag','class','visibility']
GT_CLASSES = ['na','person','na','na','na','na','vehicle','person', \
'na','na','na','occluded','na','crowd']
def read_detections(df, frame):
'''
Parse detections from MOTS17 csv/dataframe
df: dataframe containing GT detections
frame: frame (1-based) of interest
'''
#This grabs our bounding boxes for the frame
df_frame = df[df.frame==frame]
bbox_arr = df_frame[ ['x0','y0','w','h'] ].to_numpy().astype(np.float64)
bboxes = bbox_arr.tolist()
#This grabs the data such as classes visibility and track id
frame_rel = range(0,len(bboxes))
ids = df_frame['id'].to_list()
vis = df_frame['visibility'].to_list()
classes = df_frame['class'].to_list()
classes = [GT_CLASSES[i] for i in classes]
return zip(bboxes, ids, vis, classes, frame_rel)
After our function is created, we can iterate through our movies and for each frame, grab the labels, and then add them to our FiftyOne sample.frame.
for movi, samp in zip(MOV_NUMS,dataset):
print(f'Loading gt detections for {samp.filepath}')
# The ground-truth csv files are located under a particular detection method (like FRCNN),
# but are identical across the different detection types. We won't actually use the FRCNN detections.
gt_csv = os.path.join(DATA_DIR,'train',f'MOT17-{movi:02}-FRCNN/gt/gt.txt')
df_gt = pd.read_csv(gt_csv,names=GT_COLUMNS)
#Here we are noramlizing the bounding boxes
imw = samp.metadata.frame_width
imh = samp.metadata.frame_height
df_gt[['x0','w']] /= imw
df_gt[['y0','h']] /= imh
for frame_no, frame in samp.frames.items():
dets_gt = []
for bb, id, vis, cls, frm_rel in read_detections(df_gt, frame_no):
det = fo.Detection(bounding_box=bb, index=str(id), label=cls, visibility=vis)
dets_gt.append(det)
frame['gt'] = fo.Detections(detections=dets_gt)
if frame_no % 100 == 0:
print(f'frame {frame_no}')
samp.save()
A key line from this block of code is how we define our bounding box for the frame:
det = fo.Detection(bounding_box=bb, index=str(id), label=cls, visibility=vis)
Notice that because this is a tracking dataset, we supply the additional input index which allows for us to designate what the ID of the object is. This is what will be used to follow trajectories of people in our example.
Let’s take a look at how the dataset came together!
session = fo.launch_app(dataset)
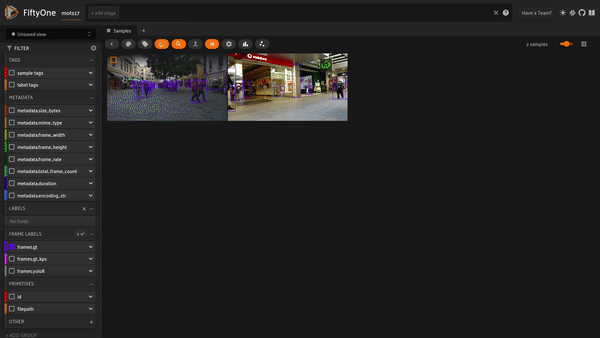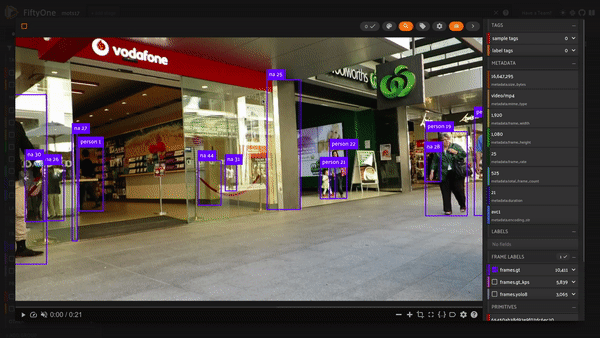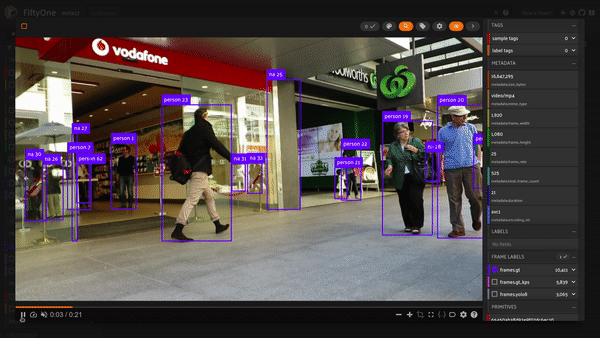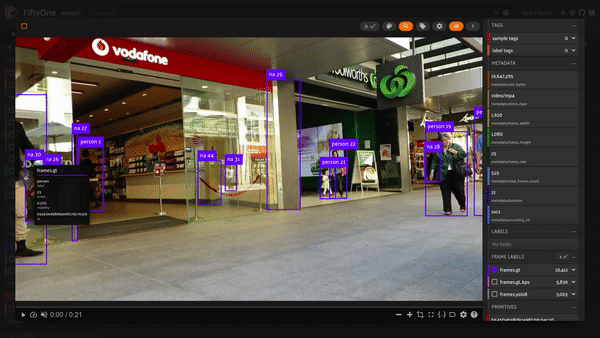
Let’s do some basic exploration of our trajectories. We’ll focus on the first movie by creating a view. The index field in our detections captures the trajectory identity; using the count_values aggregation gives us a count of the number of frames for each trajectory index:
view = dataset.limit(1)
traj_counts = view.count_values('frames.gt.detections.index')
num_trajs = len(traj_counts)
traj_lens = traj_counts.values()
print(f'There are {num_trajs} trajectories with min/max lengths of {min(traj_lens)}/{max(traj_lens)}')
print(traj_counts)
There are 83 trajectories with min/max lengths of 1/600
{54: 369, 63: 111, 79: 52, 26: 600, 36: 516, 57: 467, 44: 370, 28: 448, 72: 152, 37: 279, 65: 580, 80: 4, 76: 155, 81: 1, 83: 1, 21: 80, 68: 315, 33: 266, 47: 600, 69: 280, 58: 303, 59: 323, 34: 248, 35: 230, 45: 491, 49: 218, 7: 581, 74: 68, 11: 530, 25: 600, 38: 351, 3: 575, 5: 600, 23: 586, 2: 56, 22: 39, 62: 304, 20: 322, 46: 600, 18: 600, 40: 529, 77: 12, 29: 537, 30: 600, 60: 402, 53: 498, 16: 62, 9: 600, 15: 600, 43: 479, 73: 121, 82: 1, 70: 206, 51: 600, 67: 349, 12: 493, 41: 373, 6: 600, 24: 600, 61: 550, 4: 600, 1: 600, 32: 298, 71: 60, 42: 361, 75: 62, 8: 43, 17: 600, 48: 251, 64: 111, 10: 600, 66: 600, 50: 528, 52: 533, 39: 376, 13: 526, 19: 549, 31: 600, 78: 25, 55: 43, 27: 570, 56: 278, 14: 306}
On top of this, we can compute a basic statistic like speed of a trajectory and add it to our dataset. We’ll calculate this speed using the centroid of our detection boxes.
def centroid(bb): # Compute the centroid of a FiftyOne-style bounding box (in normalized image coordinates) x = bb[0] + bb[2]/2.0 y = bb[1] + bb[3]/2.0 return x,y
We can also add this centroid to our dataset as a keypoint label so that the centroids can be visualized. We’ll filter out our dataset so that this is only done on the person label.
for samp in dataset.filter_labels('frames.gt',F('label')=='person').iter_samples(autosave=True):
imw = samp.metadata.frame_width
imh = samp.metadata.frame_height
last_seen = {}
for fno,frame in samp.frames.items():
dets = frame.gt.detections
kps = [fo.Keypoint(points=[centroid(x.bounding_box)],
label=x.label,index=x.index) for x in dets]
for kp in kps:
if fno>1 and kp.index in last_seen:
#Caluclate speed
pts0 = last_seen[kp.index]
pts1 = kp.points[0]
dx_px = imw * (pts1[0]-pts0[0])
dy_px = imh * (pts1[1]-pts0[1])
vel = np.hypot( dx_px, dy_px )
kp['speed'] = vel
else:
kp['speed'] = None
last_seen = {x.index: x.points[0] for x in kps}
frame['gt_kps'] = fo.Keypoints(keypoints=kps)
frame.save()
if fno % 100 ==0:
print(f' frame {fno}')
To visualize our new additions, we call add_dynamic_frame_fields on our dataset. By adding dynamic fields, we add speed to our dataset’s schema.
dataset.add_dynamic_frame_fields() session.dataset = dataset
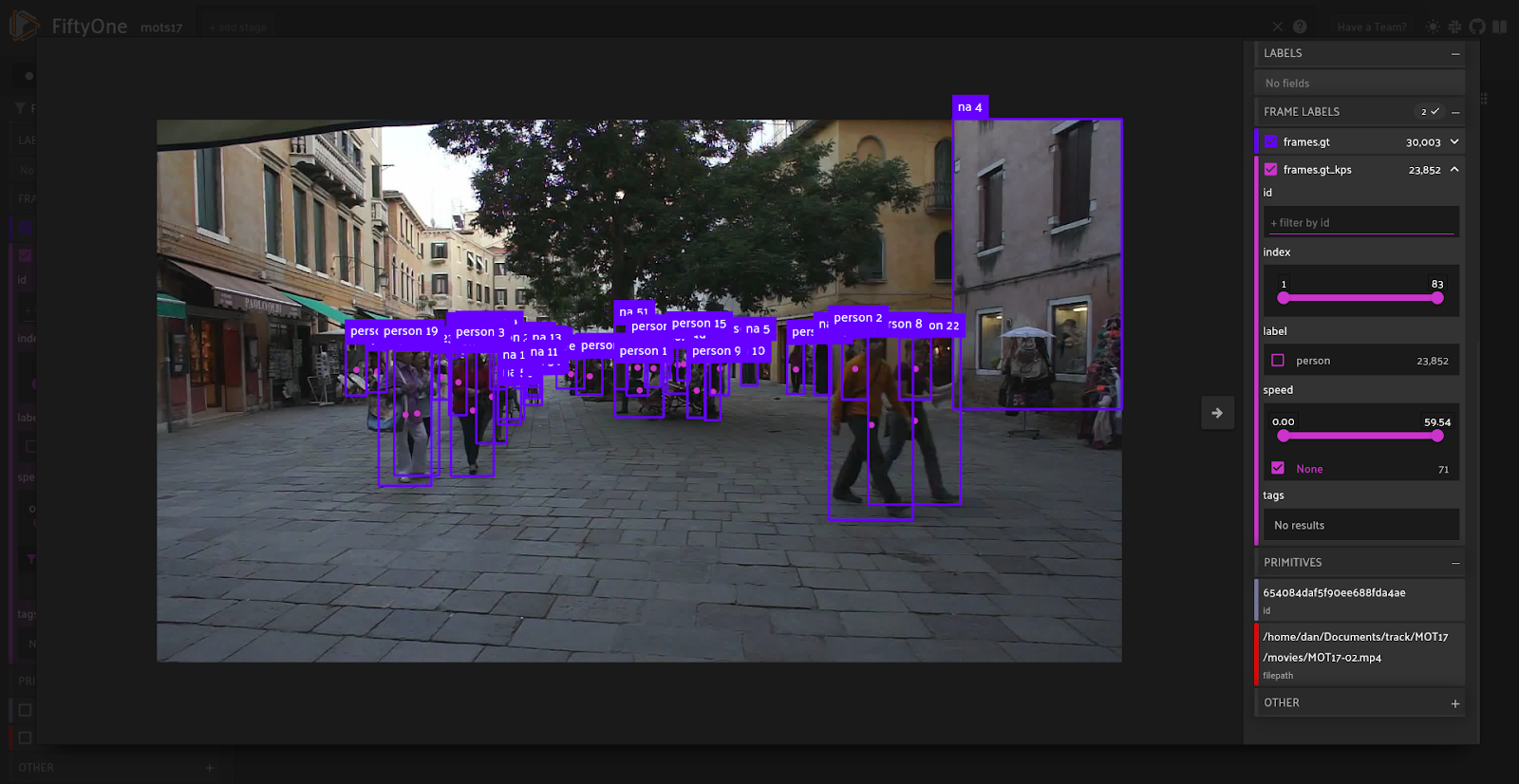
With the per-frame speeds saved on our detections, we can compute statistics like the average or maximum speed for each individual. To this, we’ll filter for each trajectory and use the values aggregation to obtain a list of speeds over all frames in its lifetime.
#Get Distinct trajectories
traj_indices = view.distinct('frames.gt.detections.index')
traj_avspeeds = []
traj_maxspeeds = []
#Grab all the speeds per trajectory
for idx in traj_indices:
speeds = view.filter_labels('frames.gt_kps',F('index')==idx).values('frames[].gt_kps.keypoints[].speed')
speeds = speeds[1:] # clip off leading None
if len(speeds)==0:
speeds = [np.nan]
traj_avspeeds.append(np.mean(speeds))
traj_maxspeeds.append(np.max(speeds))
idx = np.nanargmin(traj_avspeeds)
print(f'(min av speed is {traj_avspeeds[idx]:.2f}, achieved by traj {traj_indices[idx]}')
index_minavspeed = traj_indices[idx]
idx = np.nanargmax(traj_maxspeeds)
print(f'(max speed achieved is {traj_maxspeeds[idx]:.2f}, achieved by traj {traj_indices[idx]}')
index_maxspeed = traj_indices[idx]
(min av speed is 0.00, achieved by traj 1 (max speed achieved is 59.54, achieved by traj 16
Let’s take a look at these two trajectories in the video! To do this, we can use to_trajectories to generate a clip view focusing on single trajectories:
# Create a trajectories view for the vehicles in the dataset
trajectories = (
view
.filter_labels("frames.gt", F("index").is_in([index_minavspeed, index_maxspeed]) )
.to_trajectories("frames.gt")
)
print(trajectories)
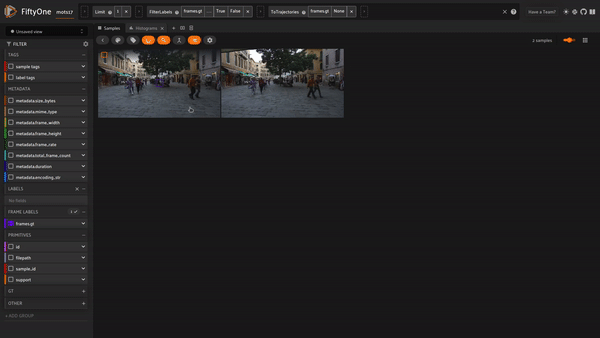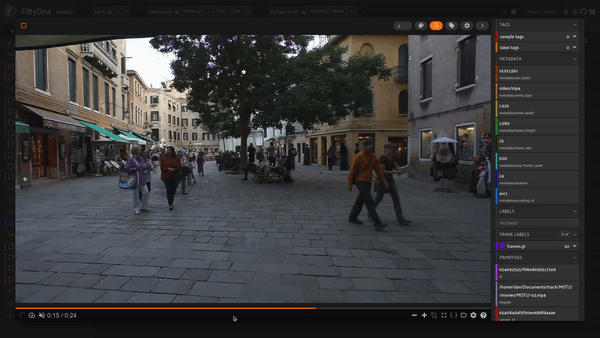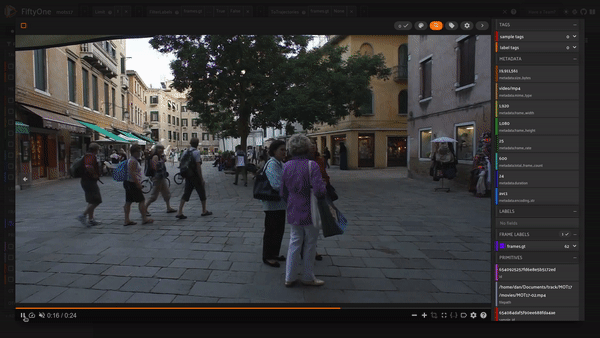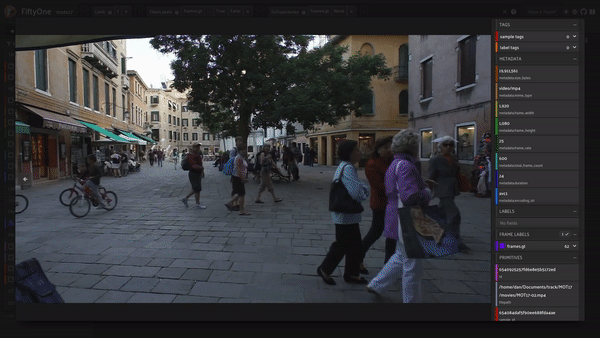
We can see the slowest person is someone sitting down while the fastest person whips by close to the camera!
Tracking with Yolov8 + BoT-SORT
Time to track! We will use Ultralytics tracking to generate some object tracking predictions. By using YOLOv8 with a second stage to associate detections to trajectories, we can start generating tracking predictions!
import ultralytics
view = dataset.skip(1)
mov_track = view.first().filepath
print(f'Tracking movie {mov_track}')
model = ultralytics.YOLO('yolov8n.pt')
results = model.track(mov_track,show=False)
Afterwards, we can load all of our detections into FiftyOne to view them!
imw = view.first().metadata.frame_width
imh = view.first().metadata.frame_height
for frm,resobj in enumerate(results):
f = view.first().frames[frm+1]
try:
if f.yolo8 is None:
f.yolo8 = fo.Detections()
except AttributeError:
f['yolo8'] = fo.Detections()
boxes = resobj.boxes
is_person = boxes.cls.numpy() == 0
bxs = boxes.data.numpy()[is_person]
#Add our detections
for b in bxs:
bb = b[:4].tolist()
bb = [bb[0]/imw, bb[1]/imh, (bb[2]-bb[0])/imw, (bb[3]-bb[1])/imh]
idx = int(b[4])
conf = float(b[5])
det = fo.Detection(label='person',bounding_box=bb,index=idx,confidence=conf)
f.yolo8.detections.append(det)
f.save()
if frm % 50==0:
print(f'frame {frm}, {len(bxs)} detections')
session.view = view
Evaluate Our Tracking
The tracker has generated detections and also stitched them into trajectories, typically by utilizing some combination of a motion and appearance/reID model. How can we gain insight into the quality of the tracking?
One step is to evaluate false positive and false negative detections. This can be done using FiftyOne’s built-in evaluate_detections method, which supports video datasets and will compute evaluation statistics on frame-level detections.
For multiple object tracking in video, false positive and false negative detections do not tell the whole story. Various metrics (TrackEval can be defined to assess different aspects of this problem. We’ll leave a deep dive into this type of evaluation for another time. Here, we focus on finding identity swaps in the tracking. One type of identity swap occurs when a predicted trajectory jumps from one individual to another. This can occur when two trajectories cross paths and occlude each other, for example. (We use the term “identity swap” informally; more careful definitions can be made, eg in this article).
One of FiftyOne’s strengths when working with video is that it is easy to switch between data modalities. We can convert full videos to individual clips, for instance, or from videos to images. In this next analysis, we’ll convert our tracked video to individual frames and work with image samples.
Since we only included people during tracking, we’ll filter our view to include only the person class from the ground_truth.
Then, we’ll call to_frames which will convert our view to an image/frame-based dataset.
from fiftyone import ViewField as F
view_frames = view.to_frames(sample_frames=True) \
.filter_labels('gt',F('label').is_in(['person','person_static']))
ds_frames = view_frames.clone()
ds_frames.name = view_frames.dataset_name + '_frames'
ds_frames.persistent = True
To investigate identity swaps, predicted and ground truth trajectories must be associated with each other, as their trajectory indices have been generated independently. We’ll do a very simple greedy matching process for illustrative purposes. A more rigorous approach might use the Hungarian algorithm to match detections, or even entire trajectories.
We’ll take the midpoint of each predicted trajectory and look for the ground truth bounding box that minimizes an L2 distance with the predicted bounding box in that frame. We assign that ground truth index to the predicted trajectory for all of its frames. We use the midpoint of the trajectory rather than its endpoints, as trajectory endpoints may involve more noise due to occlusions or people entering/exiting the scene.
yolo_to_gt = {}
idxs = ds_frames.distinct('yolo8.detections.index')
for idx in idxs:
frms = ds_frames.filter_labels('yolo8',F('index')==idx,only_matches=True) \
.values('frame_number')
mid_idx = len(frms) // 2
frm_mid = frms[mid_idx]
samp_mid = ds_frames.match(F('frame_number')==frm_mid)
assert len(samp_mid)==1
gt_bbs,gt_idxs = samp_mid.values(['gt.detections.bounding_box', 'gt.detections.index'])
gt_bbs = gt_bbs[0]
gt_idxs = gt_idxs[0]
bbs_gt = np.array(gt_bbs)
bbs_gt[:,2] += bbs_gt[:,0]
bbs_gt[:,3] += bbs_gt[:,1]
bb_pred = samp_mid.filter_labels('yolo8',F('index')==idx).values('yolo8.detections.bounding_box')
assert len(bb_pred)==1
bb = np.array(bb_pred[0])
bb[:,2] += bb[:,0]
bb[:,3] += bb[:,1]
dists = np.linalg.norm(bbs_gt-bb,axis=1)
gt_idx_argmin = np.argmin(dists)
gt_idx = gt_idxs[gt_idx_argmin]
yolo_to_gt[idx] = gt_idx
print(f'Frame {frm_mid}: Yolo index {idx} -> GT index {gt_idx}, dist is {dists[gt_idx_argmin]:.2f}')
We now update our labels to account for the trajectory index. In effect, we create classes like person00, person01, etc based on the tracked individuals. With the classes updated in this way, we can run FiftyOne’s object detection evaluation out of the box.
for s in ds_frames:
for det in s.gt.detections:
det.label = f'{det.label}{det.index:02}'
for det in s.yolo8.detections:
new_index = yolo_to_gt[det.index]
det.label = f'{det.label}{new_index:02}'
s.save()
eval_res = ds_frames.evaluate_detections('yolo8',gt_field='gt',eval_key='eval')
In the evaluation patches view, false positives often represent an identity swap where the assigned and ground truth individuals (classes) do not match.
Let’s examine evaluation patches that are false positives. For simplicity we focus on large detections where the bounding box exceeds a certain size.
view_eval = ds_frames.to_evaluation_patches(eval_key='eval',config=None)
bbox_area = F('bounding_box')[2] * F('bounding_box')[3]
large_boxes = F('yolo8.detections').filter(bbox_area>0.05)
view_eval_fps_large = view_eval.match(F('type')=='fp').match(large_boxes.length()>0)
session.view = view_eval_fps_large
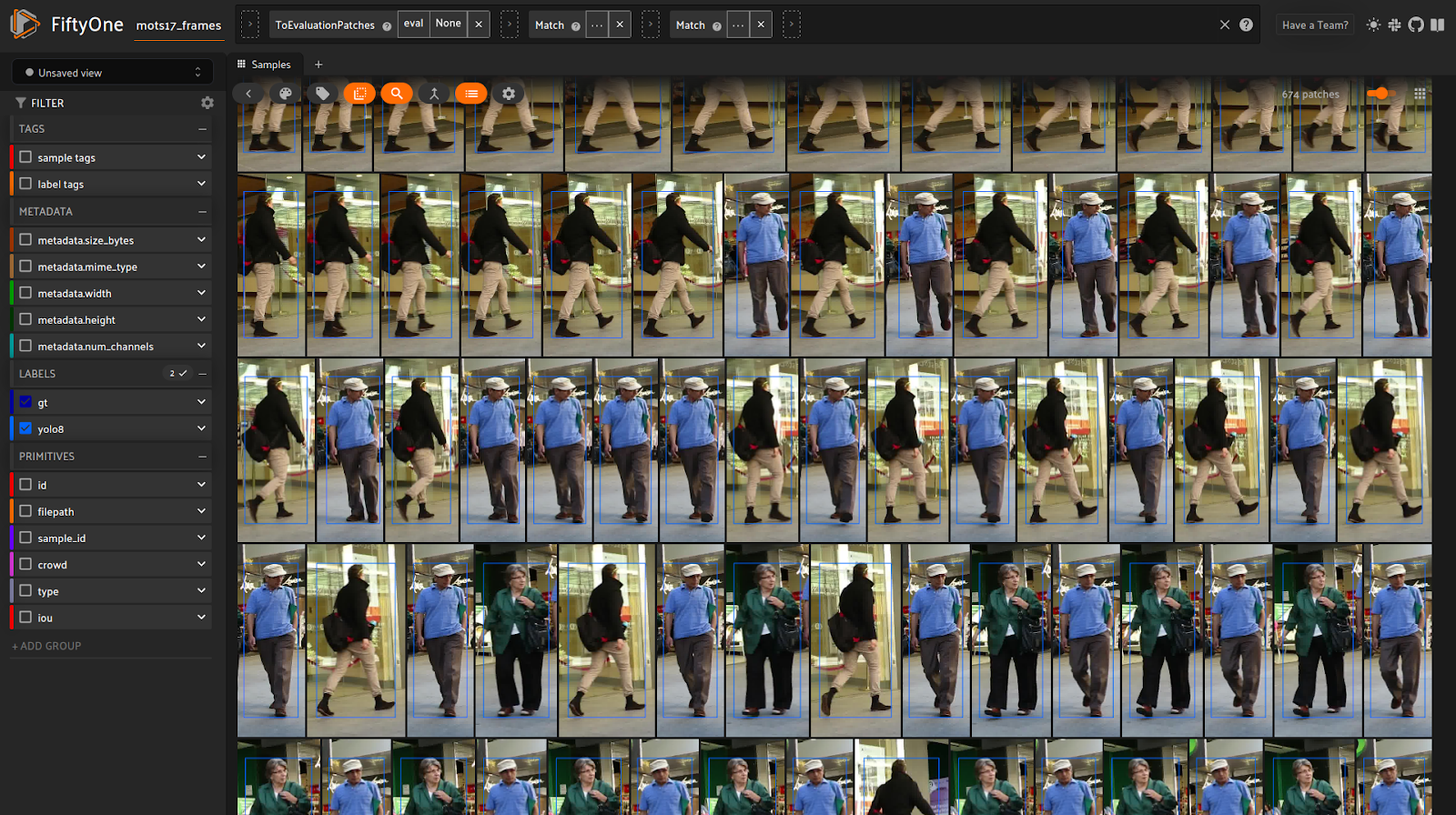
Here we can begin to see our trajectory switching targets often at the end instead of sticking with one. A mistake, but luckily we were able to find it and gain understanding of how our model is performing.
Conclusion
Using FiftyOne we were able to accomplish:
- Loading a video dataset with detections and trajectories into FiftyOne
- Computing, storing, and analyzing perframe trajectory statistics
- Visualizing interesting object trajectories
- Running a pedestrian tracker on the dataset and loading the results
- Assessing our tracking using FiftyOne’s evaluation methods
There are many different approaches you can bring to evaluating a model on a tracking dataset. FiftyOne provides not only powerful visualization of trajectories, but also allows you to create complex fields or evaluation methods to add even more insights into your dataset.
By starting with FiftyOne the next time you start working with video datasets, you are on the track to success!

