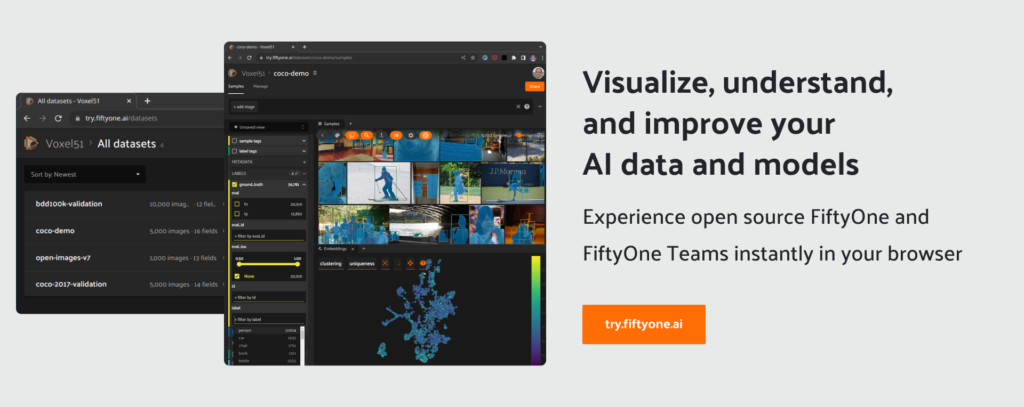
Now, you can easily try out FiftyOne Open Source and FiftyOne Teams in your browser and evaluate first hand where they fit into your AI Stack
When I was a grad student in the early 2000s, there was a framed picture on the wall of my lab that read: “Too many pixels, so little time.” I don’t know where my advisor found that nugget of wisdom, but it has run increasingly true over the last two decades. In those days, our datasets numbered in the hundreds of images or a few videos. And, we painstakingly combed through their pixels to map patterns in the data to specific capabilities and failures in our models while building deployable AI systems. Fast-forward a decade and we found datasets increasing in size by two or three orders of magnitude; it became quite difficult to continue that practice. Yet, it did not stop being important, or even critical, in developing highly performant AI systems.
Unstructured data is exceptional. It significantly outnumbers structured data on the internet, e.g., video alone accounted for 65% of internet traffic in 2021. It drives recent trends in areas like autonomous driving, large language models, and generative AI. Yet, in each case, understanding the nuances of a collection of unstructured data to unlock its intrinsic value and build a better AI system is no easy task.
Aggregate measures like accuracy, precision-recall, and others fail to close the loop when leveraging unstructured data in a task. They may provide a high-level overview of a model’s performance but do not lead to a better understanding of the overall data distribution or to actionable insights on how to improve weak performance. Imagine you go to the dentist to have a cavity filled. If the dentist worked like this, then she’d take the drill, close her eyes, drill away, apply the filling, and then go take an X-ray to see how well she did. Ridiculous you say? Yes, very ridiculous.
How would she actually work? She would constantly close the loop. She would look into your mouth, check the location, refer to the existing X-rays, etc. Over the last two decades, I’ve come to appreciate the need to work in a tight, closed-loop mindset in AI.
This need led to the creation of the open source FiftyOne toolset. FiftyOne helps AI scientists and engineers close the loop while building systems that leverage unstructured data. With FiftyOne you can semantically search and explore your datasets using the straightforward Python query language or, now, with natural language through VoxelGPT; you can visually analyze the distribution of your data both in aggregate, via, for example, embeddings, and in fine detail, via visualization at the individual sample-level; you can compare and evaluate multiple model runs on that data; and more.
People in the FiftyOne community have shared a variety metaphors to capture the amazingness of FiftyOne, including this one: FiftyOne is the (missing) debugger for the AI stack. The rationale? Many computer scientists consider the debugger as the most important tool of programming, second only to the compiler/interpreter.
And, now, you can more easily try out FiftyOne directly in your browser, without installing anything locally. Even more exciting, you can, for the first time, get a taste of FiftyOne Teams, our team-oriented Enterprise version of FiftyOne, in your browser too.
Get started instantly at try.fiftyone.ai!
Evaluating How FiftyOne Fits Into Your AI Stack
We released FiftyOne as open source software in August of 2020. FiftyOne was a one of a kind tool upon its release: it concurrently solved the need to visually inspect unstructured datasets and model performance on those data while also providing a schema-free mechanism to construct sophisticated semantic queries on those data and models to drill into the unstructured datasets making it more easy to uncover failure modes and corner cases. This article is not meant to be a comprehensive overview of FiftyOne. For that you can check out this recent playback of the Getting Started with FiftyOne Workshop, register for an upcoming live Workshop, or go explore the user guide.
Until now, there were two primary ways to try out FiftyOne. Both required some effort on the user. First, you could pip install fiftyone and then launch a quickstart, which would allow you to play in a locally deployed sandbox on a small dataset. Time to your first “Aha!” moment: 15 minutes.
Second, you could git clone https://github.com/voxel51/fiftyone and install a locally functional developer environment. Time to your first “Aha!” moment: 4 hours.
Even though these two routes have found wild success—pip install fiftyone has been executed 1,329,629 times as of this writing—we wanted to level up. For example, one limitation in these two approaches is that in order to try it on a dataset with more than a handful of samples requires learning the FiftyOne Dataset Zoo , or importing your own data.
Although not uncommon, for example, similar SaaS tools in our space like Scale AI’s Nucleus allow free trial usage for only a small number of data points. In all of these cases, it’s immensely difficult to get a real sense for how useful these tools will be for effective AI workflows without being able to evaluate them on larger datasets.
With try.fiftyone.ai you instead can interact easily with larger datasets directly within your browser. No download required. Full evaluative, read-only functionality.
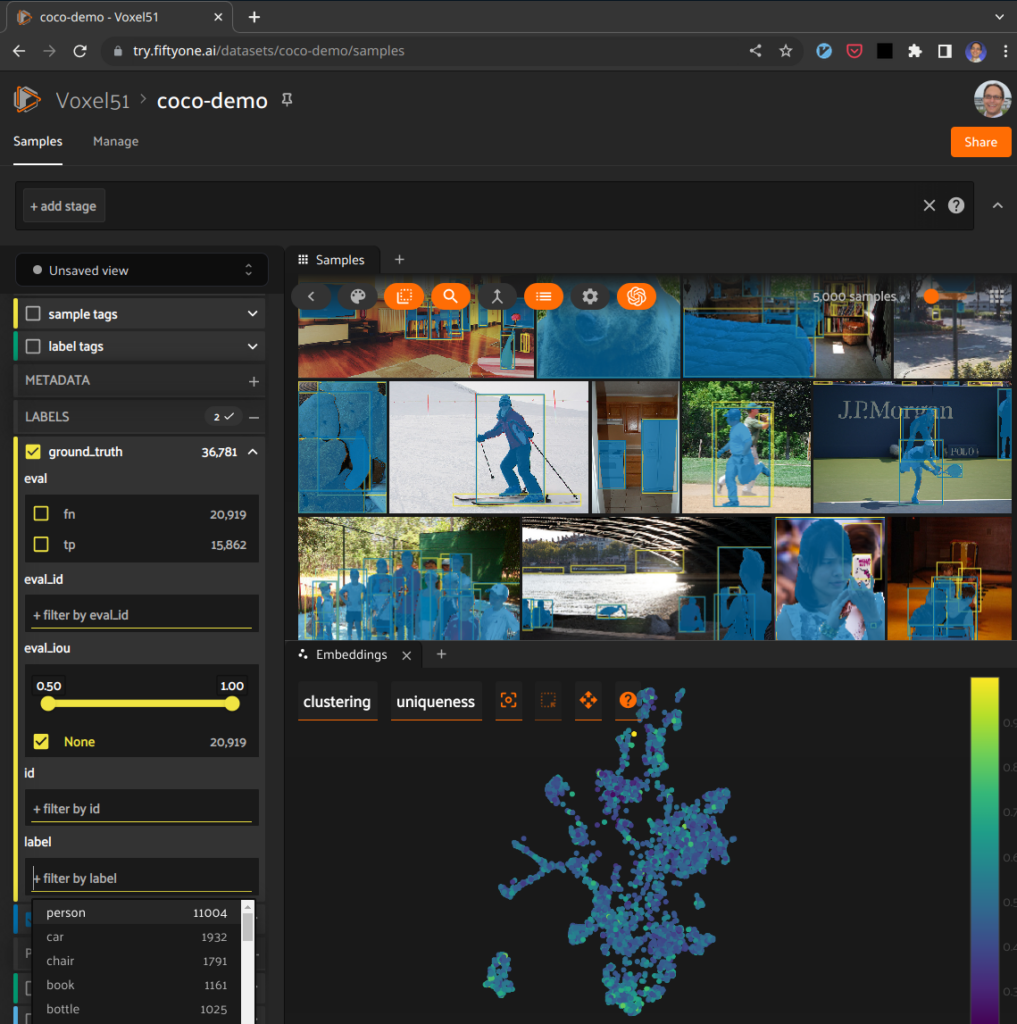
You can try out various functionality like exploring embeddings, interacting with natural language queries through VoxelGPT, visually inspecting annotations, and more. See it for yourself right now! Simply visit try.fiftyone.ai, click on the coco-2017-validation dataset as an example, open the embeddings tab, select clustering and color by uniqueness, and then lasso the most interesting looking cluster.
I couldn’t be more excited that it’s now possible to directly evaluate FiftyOne in your browser!
FiftyOne Teams: Leveling Up with Collaboration and Security
You may not realize it, but with try.fiftyone.ai you’re actually getting a taste of FiftyOne Teams, the multiuser, collaborative version of FiftyOne.
Open source FiftyOne was designed with the individual AI scientist in mind. It speeds up workflows and leads to measurably better models faster. It assumes all data is local. It assumes that this scientist is managing a specific computer instance and running FiftyOne there. In fact, this enabled us to create a unique bidirectional stateful relationship between a state of the art user interface and an underlying Python session.
But, open source FiftyOne does not support multiple users. It has no notion of security. No notion of “sign on” let alone single sign-on. No notion of roles or usage rights. No notion of collaboration. AI teams need all of these capabilities to function in the Enterprise environment.
What can AI teams do? FiftyOne Teams is the answer. We rebuilt FiftyOne’s system layer from the ground up while maintaining full backwards compatibility to the data model and retaining the dataset browser experience. FiftyOne Teams adds Enterprise security; single sign-on; role-based access control; collaboration functionality; sharing of datasets and models; full interactive export functionality; cloud-backed media; and more. By way of analogy, FiftyOne is git, and FiftyOne Teams is GitHub. You can read more about FiftyOne Teams in the docs.
With try.fiftyone.ai, you can now try certain aspects of these multi-user, collaboration experiences directly within your browser, such as the cloud-backed media, SSO, collaboration, and sharing. For example, when you connect to the site, you will use a single-sign-on functionality to connect a social login to allow access. Then, you will see the list of datasets shared with you.
The demo site is currently read-only where datasets are set to ‘Can view’ for all users, so if you want to check out the full user roles and permissions experience within FiftyOne Teams, reach out to us and we’ll be in touch!