DreamSim bridges the gap between human and machine perceptual similarity

Have you ever heard the saying “one of these things is not like the other”? As a kid, I fondly remember watching the Sesame Street segment of the same name. Each round, the viewer was presented with four objects: three matched, but one was always different. Children tuning in from around the world were tasked with identifying the imposter, so to speak — determining which object was not like the others.
Silly as it sounds, this children’s game speaks to something remarkably profound: humans often demonstrate a shared sense of visual similarity. The red that you see may not be the red that I see — especially so because I’m colorblind(!) — but individuals of all ages, raised in disparate environments, are often united in their innate sense of perceptual similarity. This ability to perceive and understand similarities is a cornerstone of human cognition.

Computers, however, have long struggled at these types of tasks. For many years, the most successful approaches to computationally capturing notions of perceptual similarity involved comparing images on a pixel-by-pixel or patch-by-patch basis. But over the past half decade this picture has changed dramatically with the application of neural networks.
Now, a team of researchers from MIT, the Weizmann Institute, and Adobe seems to have cracked the code on human perceptual similarity judgements. Their perceptual similarity metric DreamSim achieves state-of-the-art levels across a wide spectrum of features. To train DreamSim, they developed a new benchmark dataset called NIGHTS (Novel Image Generations with Human-Tested Similarity).
You can play around with the dataset in your browser for free at try.fiftyone.ai/datasets/nights!
This article is organized as follows:
- The Spectrum of Similarity
- History of Perceptual Similarity Metrics
- NIGHTS Dataset
- DreamSim Metric
- DreamSim in Action
The Spectrum of Similarity

The path to DreamSim was paved with many partial successes as well as many perceptual gaps. There is a broad spectrum encompassing what it means for two images to be similar.
On one extreme, there are low-level distortions which affect the values of individual pixels. An example of this can be seen in the first image triplet in the above figure. These distortions are perceptual, and can be viewed as corruptions of the original image. On the other extreme, high-level distortions are more conceptual, as exemplified by the third triplet in the figure above.
The middle of the spectrum — so-called “mid-level” distortions — are perceptual like low-level distortions. Unlike low-level distortions, however, mid-level distortions are more semantic. For an example of such a mid-level distortion, see the center triplet in the above figure.
Dark Days: A History of Perceptual Similarity Metrics
Before diving into NIGHTS and DreamSim, it’s worth reviewing some influential steps toward representing similarity.
Peak Signal-to-Noise Ratio
The first and simplest attempt at approximating similarity in images was to use Peak Signal-to-Noise Ratio (PSNR). This approach, which borrows heavily from the field of signal processing, treats one image as a reference, uncorrupted image, and another as a corrupted or distorted image. The difference between reference and distorted image is calculated on a pixel-wise basis, so that two images have lower PSNR if the values of pixels at the same locations are more similar.
While PSNR can be effective in a limited range of scenarios (especially when working with compressed images), it generally fails to capture the complexities of human perceptual similarity. The similarity metric is sensitive to noise and high dynamic ranges in images, and it does not account for structural or semantic differences in images.
Note: PSNR is also intimately related to Mean Squared Error (MSE)
Structural Similarity
Proposed in 2004 as a measure for assessing image quality, structural similarity (SSIM) overcomes some of PSNR’s limitations, taking structural information into account. In particular, the structural similarity measure utilizes local luminance, contrast, and structure comparisons when assessing the quality of a given image with respect to a reference.
When used as a perceptual similarity metric, SSIM outperforms PSNR. Nevertheless, it still operates on the level of pixels, failing to capture notions of higher level structure in images. As a result, SSIM doesn’t always align with human perceptual judgements.
Learned Perceptual Image Patch Similarity
Motivated by successes in using deep neural network features in the training loss for image synthesis tasks, in 2018 a group of researchers from UC Berkeley, Adobe Research, and OpenAI trained a neural network to learn human perceptual judgements. Their metric, Learned Perceptual Image Patch Similarity (LPIPS), goes beyond individual pixels to compare 64×64 patches within images.
By encoding these patches in deep features, LPIPS is able to capture more nuanced notions of similarity. However, LPIPS is not designed to encode high level semantic information, so images with similar look and feel but highly disparate connotations can be regarded as “close”.

Image-level Embeddings
This, in turn, has led researchers to use image-level embeddings to capture semantic information. Models like CLIP and DINO have shown success at these image-to-image semantic tasks, but are not designed to distinguish fine-grained visual features within an image. CLIP, for instance, is trained to minimize the distance between the text embedding for a concept and an image that portrays the same concept. This places a premium at high level similarity, at the expense of low level similarity.
DreamSim bridges the gap between low level measures of similarity like LPIPS and high level, conceptual similarity obtained from full image embeddings!
NIGHTS Time: A Benchmark Dataset for Perceptual Similarity
As is often the case in machine learning, data has been a limiting factor in human perceptual similarity tasks. Previous datasets have typically focused exclusively on either low level perceptual differences or high level conceptual content.

For low-level similarity, the most popular dataset is the Berkeley-Adobe Perceptual Patch Similarity (BAPPS) dataset, which was introduced in concert with LPIPS. The BAPPS dataset consists of two types of human perceptual judgment. In the first set, dubbed two alternative forced choices (2AFC), human evaluators were given a reference patch and two distorted patches, and asked to select the distorted patch that most closely matched the reference.
To validate the 2AFC judgments, the second set of experiments asked humans to make a split-second decision about whether two image patches (one reference, one distortion) were the same. This second variety is referred to as just noticeable differences (JND).

For conceptual similarity in images, the gold standard is THINGS, which consists of 4.7 million image triplets spanning 1,854 object and concept categories. Each triplet was evaluated by a single human in odd-one-out fashion: in other words, one of these things is not like the others!
To develop their state-of-the-art perceptual similarity metric, the DreamSim team created the most comprehensive perceptual similarity dataset to date: NIGHTS. The researchers used stable diffusion to generate images in the label classes of common datasets like ImageNet, and then generate variations for these base images across a variety of axes, including pose, perspective, and shape. Importantly, the base images and their variations share semantic commonality: the differences only span mid-level variations. Using this procedure, the team generated 100,000 image triplets.
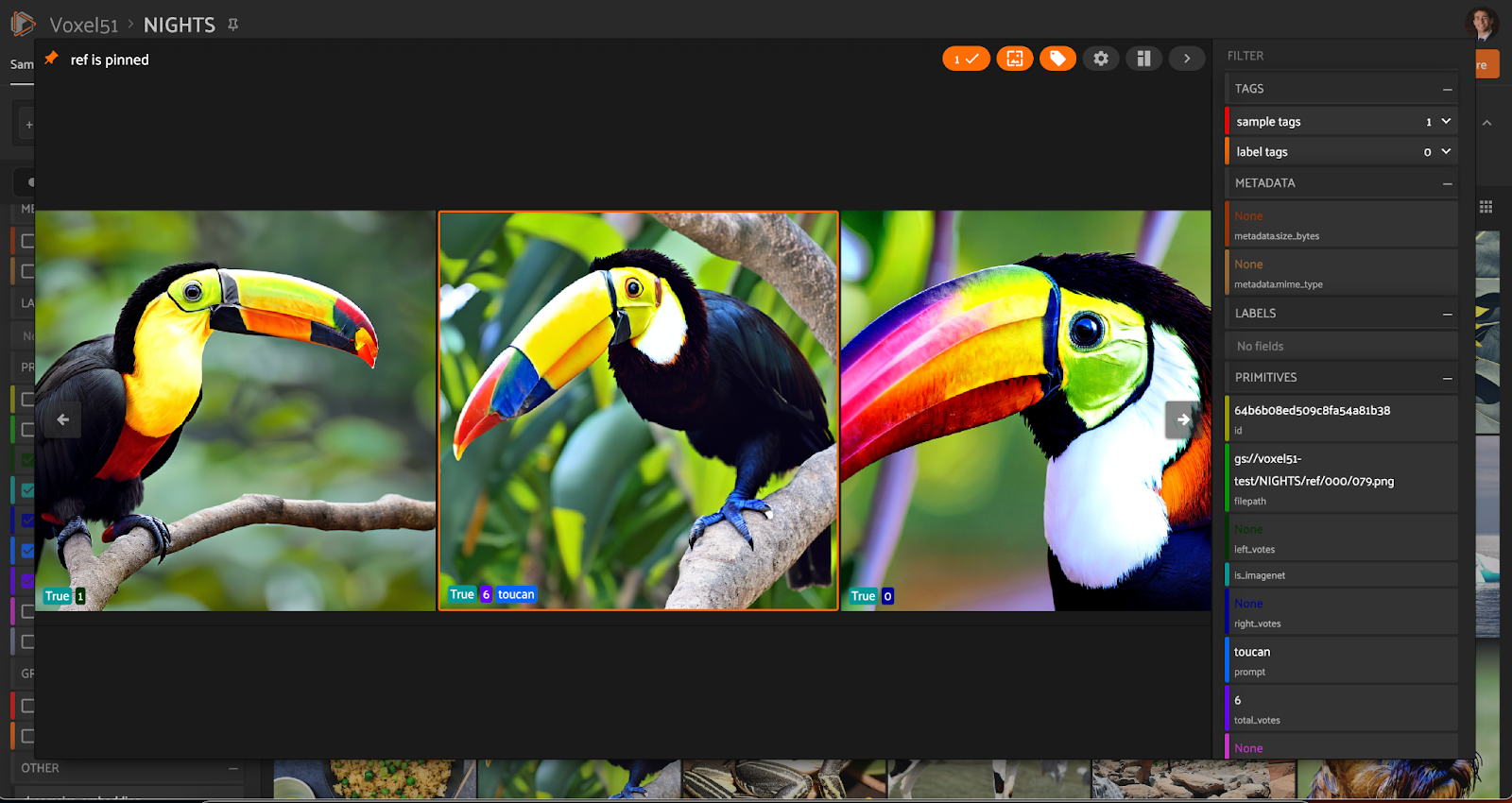
6 on the reference image (center) denotes that six humans were given this triplet as a 2AFC task. The 1 on the left image (and 0 on the right image) denote that all six of these humans judged the left image to be more similar than the right image to the reference.From there, the team collected 2AFC judgements from human evaluators on MTurk. Each triplet was given to multiple human evaluators, and only the triplets with unanimous human judgements were retained. These triplets are referred to as cognitively impenetrable, and only these are kept in an effort to capture something shared across humans, automatic (requiring little, if any cognition) and stable over time. After filtering for only cognitively impenetrable triplets, the team was left with 20,019 high quality triplets. They also ran a number of JND evaluations and observed strong alignment between the two methods of attaining perceptual judgments.
What Dreams Are Made Of

With their novel NIGHTS dataset created and curated, the researchers were ready to revisit the task of computationally representing human perceptual similarity. As with LPIPS, they set out to learn a similarity metric.
For each triplet, the team computed the cosine distance (a measure of directional agreement) between the model’s embedding for the reference image and each of the distorted images. These scalar distances were then passed into a hinge loss function — a standard loss function used for training binary classifiers like support vector machines — treating the human-preferred distortion as positive and the non-preferred distortion as the negative classification. Training a model then boiled down to minimizing this loss.
As a starting point for DreamSim, the researchers took three of the most powerful vision foundation models: CLIP, OpenCLIP, and DINO. They then experimented with different fine-tuning strategies on these base models, and found tremendous success with a recent technique called LoRA, which reduces the number of parameters to be fine tuned, and leverages the existing representational power of the base models.
In the end, the team found that the best performing model was an ensemble obtained by concatenating the embedding vectors for fine-tuned versions of CLIP, OpenCLIP, and DINO. The resulting model, called DreamSim, coincides with human judgment more than 96% of the time on perceptual similarity tasks!
DreamSim in Action
To get started working with DreamSim, you can install the Python library on a CUDA-enabled GPU with:
pip install dreamsim
You can then import the DreamSim model from the library with:
from dreamsim import dreamsim
If you have two images (in PIL format) and you want to compute the distance between them according to DreamSim — the cosine distance between their embeddings — you can do so by running:
from PIL import Image
model, preprocess = dreamsim(pretrained=True)
img1 = preprocess(Image.open("img1_path")).to("cuda")
img2 = preprocess(Image.open("img2_path")).to("cuda")
distance = model(img1, img2)
For a performance speedup, you can also use one of the single-branch versions of DreamSim (fine tuned CLIP, OpenCLIP, and DINO). To use the fine tuned DINO branch for instance, you can run the following:
dreamsim_dino_model, preprocess = dreamsim(pretrained=True, dreamsim_type="dino_vitb16")
One of the ancillary benefits of learned similarity metrics like DreamSim over traditional similarity metrics like PSNR and SSIM is that they allow for quick nearest neighbor search. If you want to find the most similar images to a reference image with SSIM, you need to compute the SSIM of the reference image with each candidate image separately. This can become unwieldy as the size of your dataset grows. With a learned similarity metric, however, you can circumvent this scaling problem by computing the embedding for each image once and then using vector search to find approximate nearest neighbors.
With vector search plus DreamSim, finding similar images is finally possible and tractable!
You can try this out in your browser for yourself, for free, at try.fiftyone.ai/datasets/nights.
If you want to work with the NIGHTS dataset locally — including precomputed DreamSim embeddings — you can do so as follows:
- Download the raw images by running the script here
- Install FiftyOne with
pip install fiftyone - Download the FiftyOne dataset info here and unzip the folder
- Load the FiftyOne dataset from this file with
dataset = fo.Dataset.from_dir(“/path/to/downloaded/folder”) - Adjust the image paths on the dataset’s samples (
sample.filepath) to match the location of the downloaded images
From there, you can generate a new similarity index from the embeddings of any image model you’d like, and compare reverse image search results with DreamSim.
The FiftyOne dataset comes with precomputed similarity indexes for ResNet50 (a pixels and patches model) and CLIP (a semantic model). As an illustrative example of DreamSim’s power, let’s look at how these three models fare at a reverse image search task starting from an image of a bowl of ramen.
ResNet50

For a pixels-and-patches models like ResNet50, the images returned as most similar are good textural and color matches with the reference image, but semantically there are some significant differences: pork, steak, and chicken are not that close to ramen conceptually.
CLIP

On the other extreme, for a semantic similarity model like CLIP, the results returned by the similarity search are conceptually quite close: each image has a bowl with either ramen or rice and vegetables, and most even have a fried egg. However, there are some textural differences: some of the images have a wooden backdrop whereas others have a slate backdrop.
DreamSim

DreamSim combines the best of both worlds. It isn’t perfect — there are a few images with wooden backdrops in the top 25 results — but DreamSim achieves a much better balance of low and mid-level similarity.

