Find The Sentiment You’re Looking For 🔍🤔😀🚀
If you’ve ever used Google Docs, or Slack, you may have noticed that when you type a “:” immediately followed by another character, a list of emojis pops up:

Since I discovered this, I’ve been making major use out of the feature. I add emojis into way more of my messages, blog posts, and other written works than I ever imagined I would. I actually got so accustomed to this means of adding emojis that I installed Rocket — a free app that brings the same emoji searchability to all text boxes and text editors on the computer. It’s a game changer.
But as I’ve used these emoji search engines more and more, I’ve noticed a frustrating limitation: all of the searches are based on the exact text in your query and in the name and description of the emoji. Essentially, you need to search for something incredibly precisely for any results to show up.
Here’s an example: if we search for “audio”, not a single result shows up:

This isn’t because the set of emojis is lacking in the audio category. If we were to type in “music” or “speaker”, we would get a long list of results. Instead, it has to do with the fact that the specific string of text “audio” does not show up in the name or textual description associated with any of the emojis.

This relatively minor inconvenience bothered me so much that I decided to build this:

By “this”, I mean an open-source semantic emoji search engine, with both UI-centric and CLI versions. The Python CLI library can be found here, and the UI-centric version can be found here. You can also play around with a hosted (also free) version of the UI emoji search engine online here.

Command line version of the Semantic Emoji Search Engine
Building this was not as simple or straightforward as I initially hoped. It took a lot of experimentation, and a lot of ideas I thought were quite clever fell essentially flat. But in the end, I was able to create an emoji search engine that works fairly well.
Here’s how I built it, what worked, and what didn’t, and the lessons learned along the way.
- What is an Emoji
- The Data
- Emojis versus Images and Text
- Bridging the Modality Gap
- Using the Emoji Search Engine
What is an Emoji
Before building a semantic search engine for emojis, it’s worth briefly explaining what exactly an emoji is. The term emoji derives from the Japanese kanji 絵 (eh) meaning picture, and 文字 (mōji) meaning letter or character. Essentially, this means that an emoji is etymologically a pictogram, and while it is connected to the English word emotion, it is not an “emotion icon” — that is an emoticon.
Along with alphanumeric characters, African click sounds, mathematical and geometric symbols, dingbats, and computer control sequences, emojis can be represented as Unicode characters, making them computer-readable. Unlike alphanumeric characters and other symbols, however, emojis are maintained by the Unicode Consortium. The consortium solicits proposals for new emojis, and regularly selects which emojis will be added to the standard.
At the time of writing, in November 2023, there are more than 3,600 recognized emojis, symbolizing a wide range of ideas and sentiments. Some emojis are represented by a single unicode character, or code-point. For example, the “grinning face” emoji, 😀, is represented in unicode as U+1F600.
Others are represented with sequences of code-points. These sequences, which combine single code-point emojis with the zero-width-joiner unicode character, are known as ZWJ sequences, and allow for the combining of concepts, in much the same way as Chinese radicals can be combined to create a character that tells a story. As an example, the emoji 👨👩👧is a zero-width joining of the emojis for man 👨(U+1F468), woman 👩(U+1F469), and girl 👧(U+1F467), connected by the ZWJ code-point U+200D:
👨👩👧= U+1F468 U+200D U+1F469 U+200D U+1F467
According to the Unicode Consortium, 92% of the world’s online population uses emojis in their communications, and the ten most-used emojis in 2021 were: 😂 ❤️ 🤣 👍 😭 🙏 😘 🥰 😍 😊.
Starting with the Data
Given that emojis are pictographs of sorts, I wanted to utilize both textual and visual information in the search process. My initial hypothesis was that for many emojis, the name — the text string used to invoke the emoji — conveys but a fraction of its meaning. This can be due to many reasons, from the limitations of natural language, to the additional meanings imbued by cultures and visual similarities. In order to truly bring the full essence of the emoji to bear, I needed to make use of visual information.
I found this Kaggle Emojis dataset from 2021, which has data about 1816 emojis, including the emoji representation, the text associated with it, the unicode code (or codes), and a base64 encoded image. Here’s what the first few rows of the dataset look like, loaded as a pandas DataFrame:
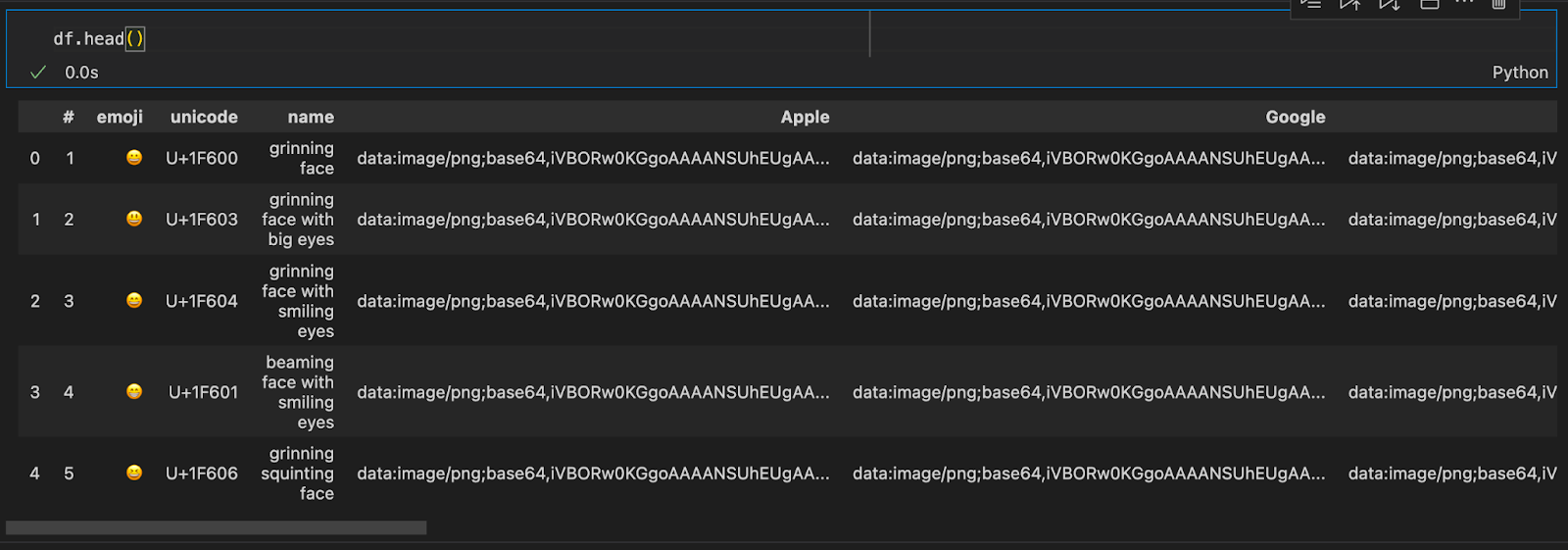
There are separate columns with names Apple, Google, Facebook, etc. because the emoji renders differently depending on the computer, website, or application. I decoded the images from base64 and converted them into Pillow images. Here is the first image from the Kaggle dataset (grinning face):
import base64
from io import BytesIO
from PIL import Image
## decode and convert first row Apple image
im_str = df.Apple[0].replace('data:image/png;base64,', '')
im = Image.open(BytesIO(base64.b64decode(im_str)))
im

Upon conversion, however, it became clear that the images were very low resolution. This one, for instance, is only 72×72 pixels. To improve the quality of the images that I was going to pass into downstream models, and to improve the quality of the experience in the eventual UI-based application, I passed all of these low-resolution images into Real-ESRGAN to 10x the resolution.
This is what the resulting images looked like:
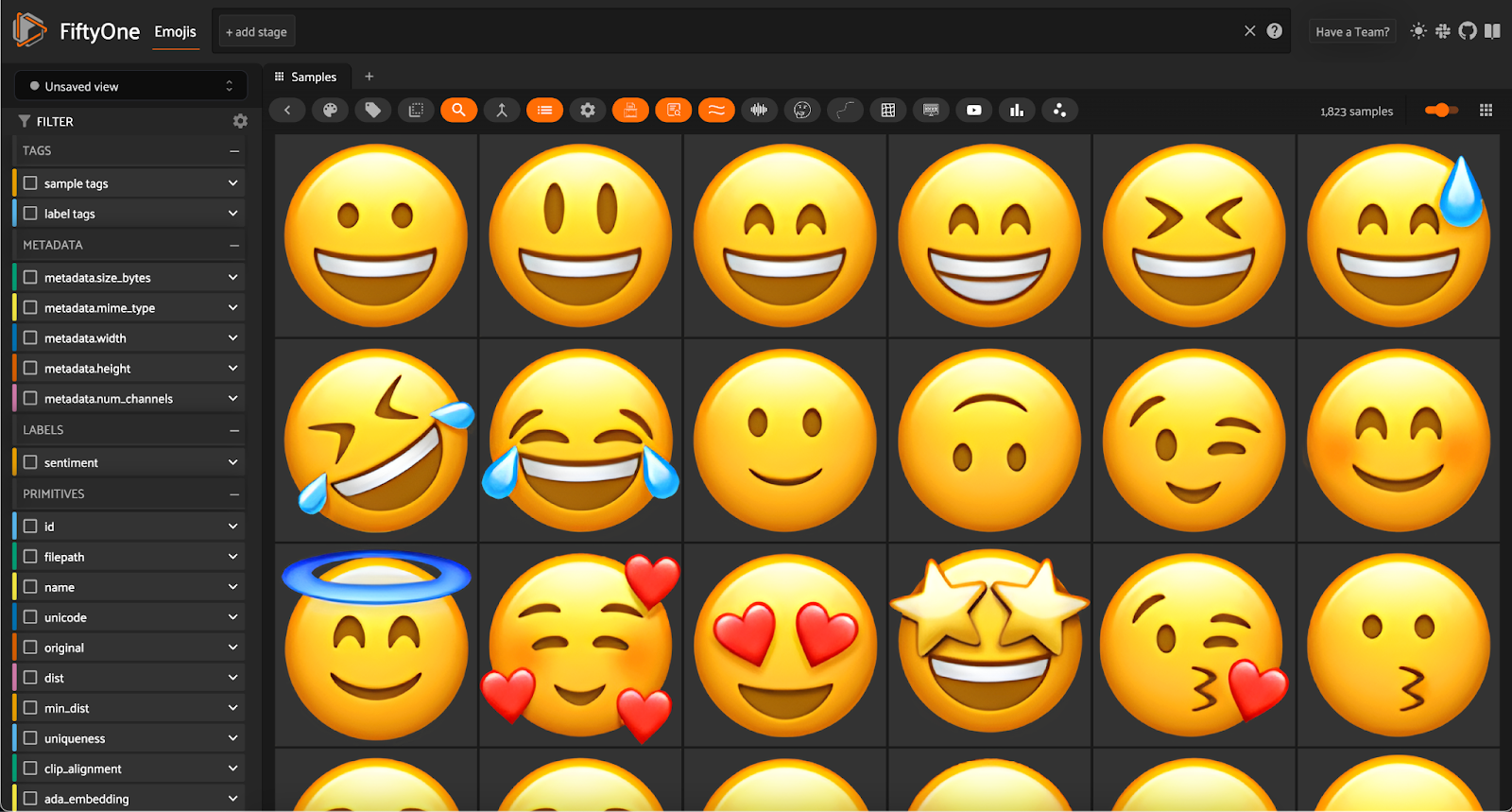
Not all of the emojis had images for all of the image columns in the pandas DataFrame, so I used the first viable base64 encoding for each row.
Emojis Versus Images and Text
Before diving any deeper, I want to emphasize one crucial element of emojis that makes them so special, and deserving of their own semantic search engine: in a sense, they are both images and text. From the human perspective, we can represent each emoji as a unicode character, on the same playing field as text characters, and we can represent it as a standalone image, both of which we saw in the previous section. Said another way, if we squint with one eye, we can see a pictogram as a picture, and if we squint with the other eye, we can see the same pictogram as text.
Computers, however, are not known for their ability to squint. While a computer may be able to display a unicode code-point as an emoji, a machine learning model may not have a good way of interpreting the emoji as text or images.
Whenever I’m working on semantic search applications that connect images and text, I start with a family of models known as contrastive language image pre-training (CLIP). These models are trained on image-text pairs to generate similar vector representations or embeddings for images and their captions, and dissimilar vectors when images are paired with other text strings. There are multiple CLIP-style models, including OpenCLIP and MetaCLIP, but for simplicity we’ll focus on the original CLIP model from OpenAI. No model is perfect, and at a fundamental level there is no right way to compare images and text, but CLIP certainly provides a good starting point.
Interpreting Emojis as Text
At a high level, language models process input text by converting it into an ordered sequence of tokens, and then encoding the tokens and positional information in a dense numerical vector. Each language model has its own vocabulary of tokens to decompose a text string into, spanning from individual letters to complete words. Some tokens are easily interpretable by a human, while others are not, and in the case of CLIP, the vocabulary has 49,408 entries.
Let’s see an explicit example. Assuming the CLIP library is installed, we can tokenize a text string “a dog” with:
import clip
text_tokens = clip.tokenize("a dog")
print(text_tokens)
tensor([[49406, 320, 1929, 49407, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0]], dtype=torch.int32)
The output tensor contains four nonzero entries: 49406, 320, 1929, and 49407. To make sense of these, we can map these values back to keys in the CLIP vocabulary dictionary. The first number, 49406, corresponds to the key “<|startoftext|>”, and the last number, 49407 corresponds to the key “<|endoftext|>”. These are special tokens denoting the beginning and end of the text string to be encoded. The second number, 320, maps back to “a</w>”, which signifies the character “a” followed by a new word. Finally, 1929 is the value for key “dog</w>”.
If we try to tokenize a string containing an emoji, however, we quickly run into a hitch: emojis don’t get tokenized in the same way as other characters do. Let’s start with the dog emoji 🐶:
clip.tokenize("🐶")
## [49406, 10631, 49407, 0, ...]
Doing a reverse lookup for the key associated with 10,631, we get the token “ðŁIJ¶</w>”. But if we pass this string into the tokenizer, we get a completely different set of token IDs:
clip.tokenize("ðŁIJ¶")
## [49406, 127, 108, 40419, 72, 329, 126, 370, 49407, 0, ...]
An even more curious case concerns the flag emojis. If we take the emoji for the flag of Cameroon, for instance, we get:
clip.tokenize("🇨🇲")
## [49406, 8989, 366, 49407, 0, ...]
The two non-start/end tokens here correspond to “ðŁĩ¨ðŁĩ” and “²</w>”. If we plug the first of these back into the tokenizer, we get another completely different set of token IDs, but the second maps back to itself.
Things get even more precarious when we start comparing embeddings of text strings with embeddings of emojis, parsed as text strings via this tokenizer. After all, we want to find the most relevant emojis given a text query. We can use the cosine distance as a way to measure how similar or different two vectors are — and by proxy the inputs that generated those embedding vectors are. A distance of 0 means that two vectors are completely aligned, and a distance of 1 implies that two vectors are orthogonal. If we wanted to treat emojis as text, we would want the name for an emoji to be relatively close to the tokenized emoji in the embedding space, but this is not always the case!
The utility below will compare an emoji and a list of text prompts:
!pip install fiftyone
from scipy.spatial.distance import cosine
import fiftyone.zoo as foz
model = foz.load_zoo_model("clip-vit-base32-torch")
def compare_emoji_to_texts(emoji, texts):
emoji_embedding = model.embed_prompt(emoji)
text_embeddings = model.embed_prompts(texts)
for text, text_embedding in zip(texts, text_embeddings):
print(f"Dist b/w {emoji} and {text}: {cosine(emoji_embedding, text_embedding):.4f}")
Here’s an example, where according to CLIP, the encoding for the “birthday” emoji 🎂is closer to “man” than “birthday”, closer to “dog” than “birthday present”, and closer to “car” than “candle”, “date”, or “holiday”:
texts=["birthday", "birthday present", "cake", "candle", "car", "date", "dog", "holiday", "man"]
compare_emoji_to_texts("🎂", texts)
Dist b/w 🎂 and birthday: 0.1205 Dist b/w 🎂 and birthday present: 0.1385 Dist b/w 🎂 and cake: 0.1238 Dist b/w 🎂 and candle: 0.2030 Dist b/w 🎂 and car: 0.1610 Dist b/w 🎂 and date: 0.1921 Dist b/w 🎂 and dog: 0.1344 Dist b/w 🎂 and holiday: 0.1844 Dist b/w 🎂 and man: 0.0849
Sometimes, the emoji and its name (and similar concepts) are close together in the embedding space, but sometimes they are most certainly not.
We can also go the other way and retrieve the emojis whose embeddings most closely match the embedding of an input text prompt. For instance, for the input “love”, we get the following:

Of course, we can do way better than this!
Interpreting Emojis as Images
The high-resolution images of emojis that we generated using Real-ESRGAN provide an alternative pathway to searching through our emojis: treating emojis as images. We can use CLIP’s vision encoder to embed the images into the same vector space, and then query these image embeddings with our input text prompt.
For applications like cross-modal retrieval (or semantically searching images with text), CLIP typically works best when the image embeddings are compared to a text prompt that is the user’s query wrapped in the phrase “A photo of <query>”. As an example, the image embedding for a photo of a dog will be closer (in terms of the angle between the vectors) to the embedding of “A photo of a dog” than the embedding of the raw query “dog”.
However, when I used this template, the results were underwhelming. For instance, here are the 25 top results for the query “A photo of a dog”:
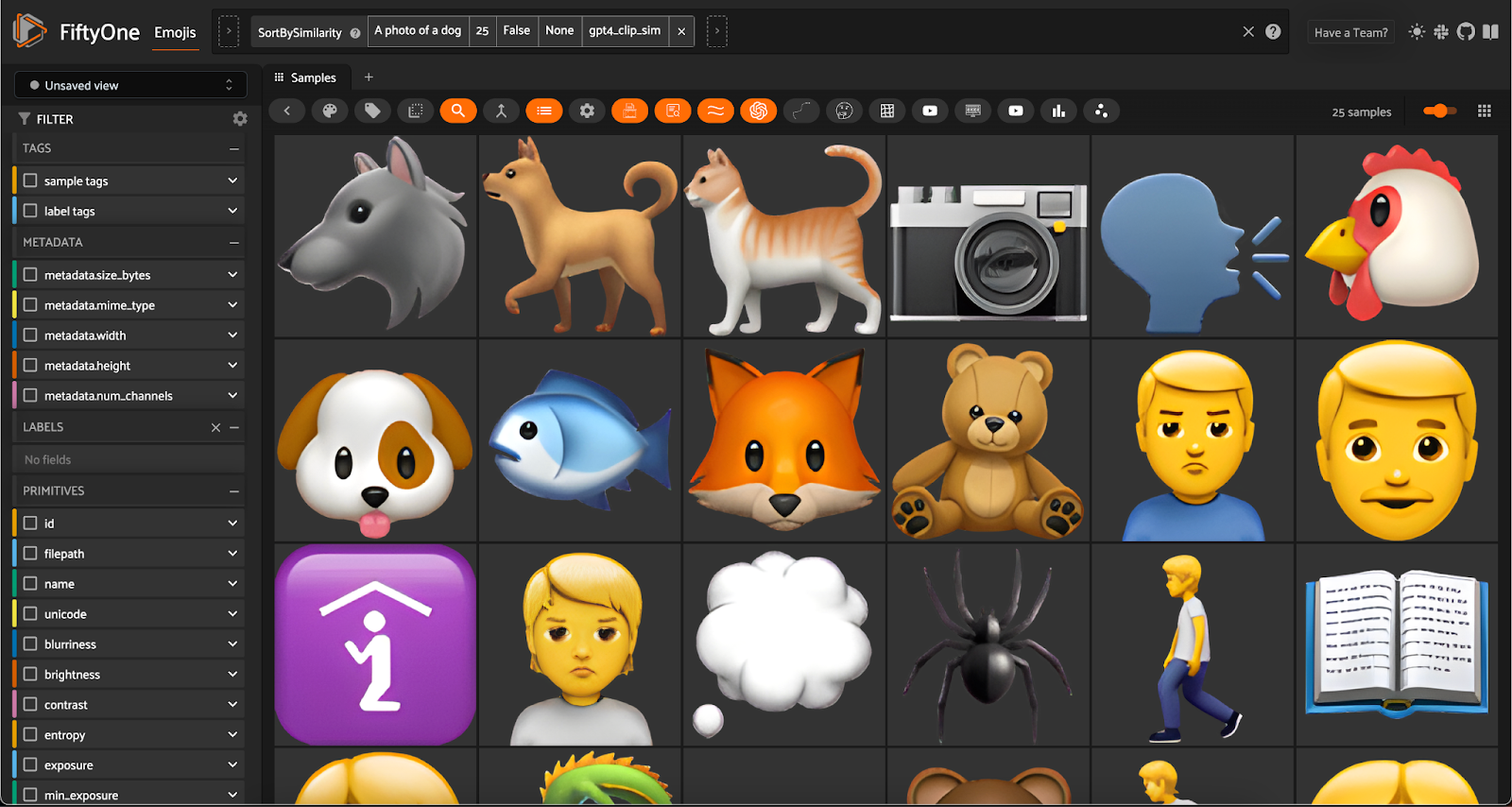
Because emojis aren’t exactly photos, I decided to dig a little deeper into this and try out a few templating, or wrapping strategies. To cover my bases, I test five formats for text prompts:
- <emoji_name>
- A photo of a <emoji_name>
- An emoji of <emoji_name>
- A photo of a <emoji_name> emoji
- A <emoji_name> emoji
I generated embeddings for all 1816 emojis with each of these methods, and computed the CLIPScore (cosine similarity multiplied by 100) of these vectors with the corresponding image embedding vectors.
Here were the aggregate results:
Method Min Mean Max A 16.96 29.04 37.49 B 15.85 29.47 38.43 C 18.94 33.25 44.60 D 19.47 32.59 42.57 E 18.95 31.83 43.35
From these statistics, I thought that the “An emoji of” descriptors were the best fit of the bunch, as they had the highest mean and max. But when I tried to use this, the results were again less than ideal. They seemed to preference faces (e.g. 😄😢🙃👦👧), to the detriment of other emojis like symbols, animals, and flags. When it came to semantic emoji searches, I found that entering the raw text tended to work best. In other words, the CLIP embedding of “dog” worked better than “A photo of a dog”, or “An emoji of a dog”.
There were a few takeaways from this:
- Overall image-text “alignment” isn’t necessarily important for semantic search
- The images of the emojis encode (to some degree) the fact that they are not photos
- The word “emoji” biases CLIP toward faces
Bridging the Modality Gap
By this point, I had come to the conclusion that treating emojis as just images or just text leaves a lot of rich information on the table. To build a robust semantic emoji search engine, I wanted to incorporate both textual and image information, and bridge the gap between these two modalities.
I tried generating descriptions of the emoji images using Adept’s multimodal Fuyu-8b model, but these descriptions proved far too detailed; I tried using other CLIP-style models like MetaCLIP, but saw the same behavior as in CLIP; I even tried using GPT-4V to generate captions for the emoji images, but was cut off by OpenAI because the rate limit for the model is 100 queries per day.
In the end, I was able to pass the emoji unicode characters into the base GPT-4 API with the prompt:
QUERY_TEXT = """
Your task is to write a brief description of the emoji {emoji}, in the format 'A photo of a ...'. For example, 'A photo of a dog'. Do not include the emoji name or unicode in your description. Do not include the skin tone of the emoji. Do not include the word yellow in your response. You may include the word 'emoji' in your description, but it is not necessary. Your description should be a single phrase, of no more than 10 words.
"""
After post-processing these captions, I removed the “A photo of” prefix and used these descriptions in the semantic search pipeline.
The emoji search engine works as follows, taking in an input query:
- Generate a set of 100 candidate emojis (out of 1816) with an image similarity search that compares the image embeddings to the query embedding. Save this ordering, clip_image_ordering.
- Order these candidate emojis by the similarity of the CLIP embeddings of the emoji names to the query’s embedding (clip_name_ordering).
- Using a cross-encoder, order the emojis based on the similarity of their name (cross_encoder_name_ordering) and their description generated by GPT-4 (cross_encoder_description_ordering) to the query.
- Combine all four orderings using reciprocal rank fusion, and return the top results!
The resulting search engine isn’t perfect, but it does a decent job at incorporating textual and visual information. Because using a cross-encoder is more computationally expensive (and higher latency), this is reserved for the pared-down set of candidates. I use the distilroberta-base checkpoint with the CrossEncoder class from the Sentence Transformers library.
When all of these steps are combined, this is the result:
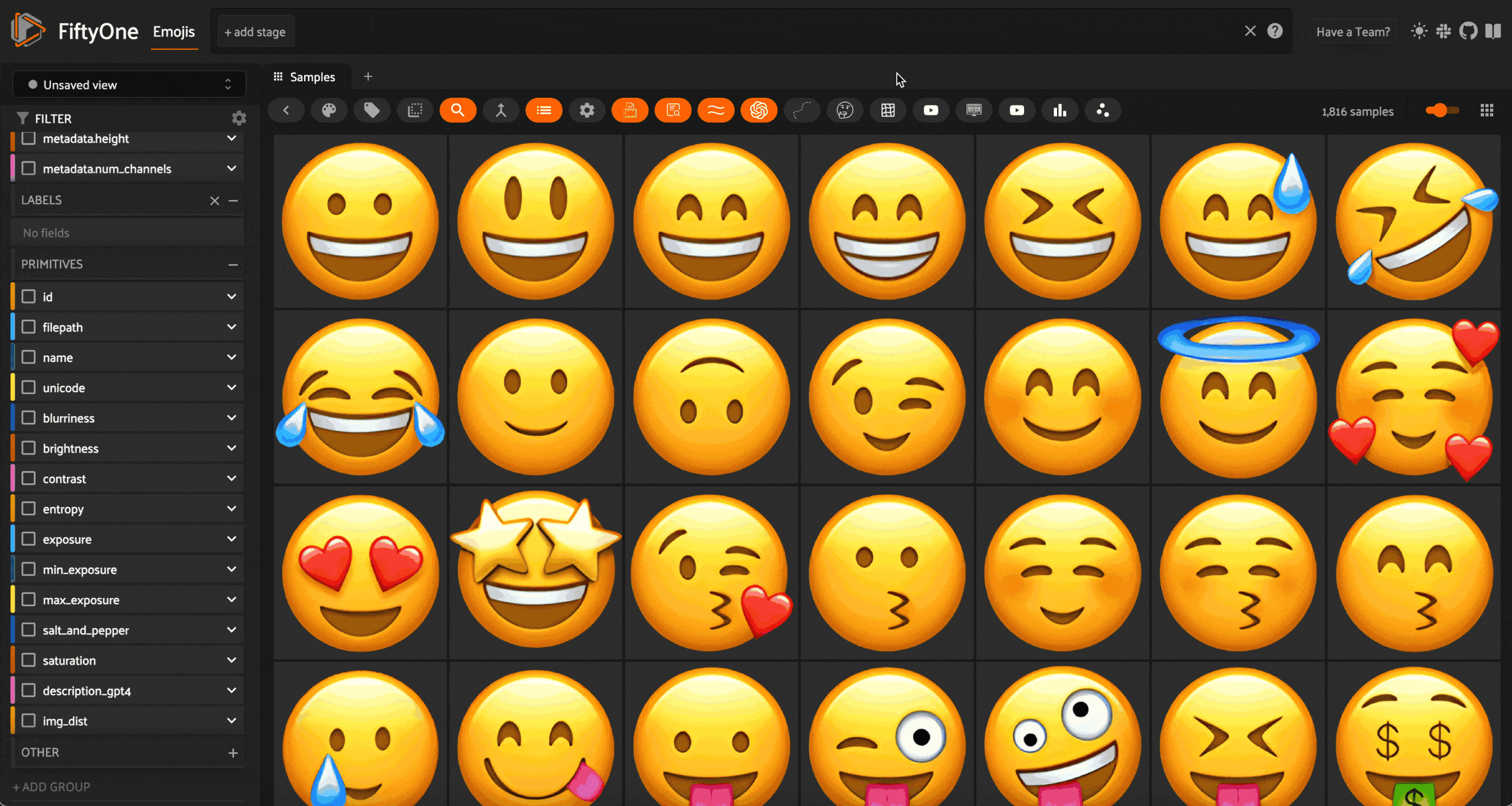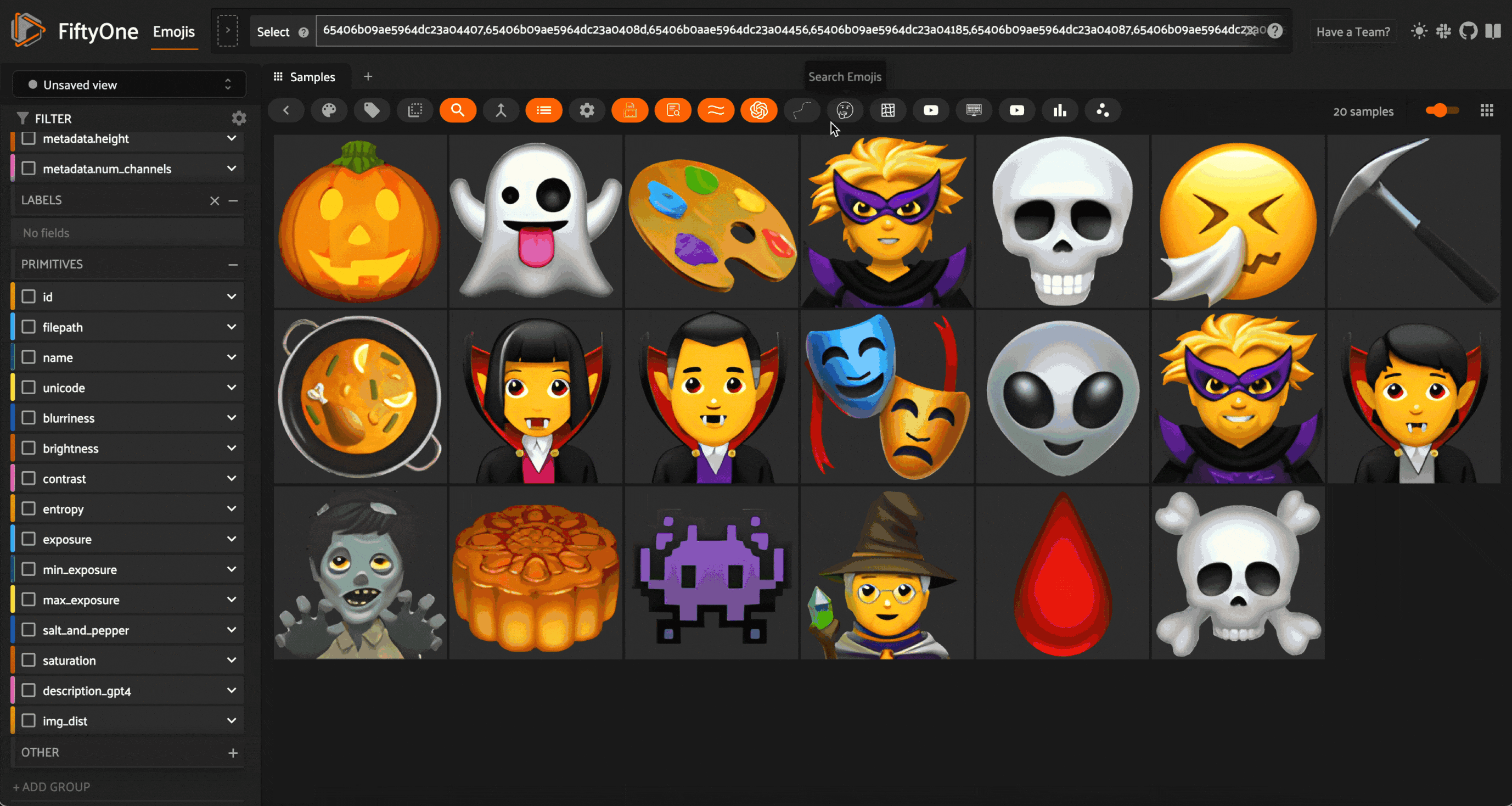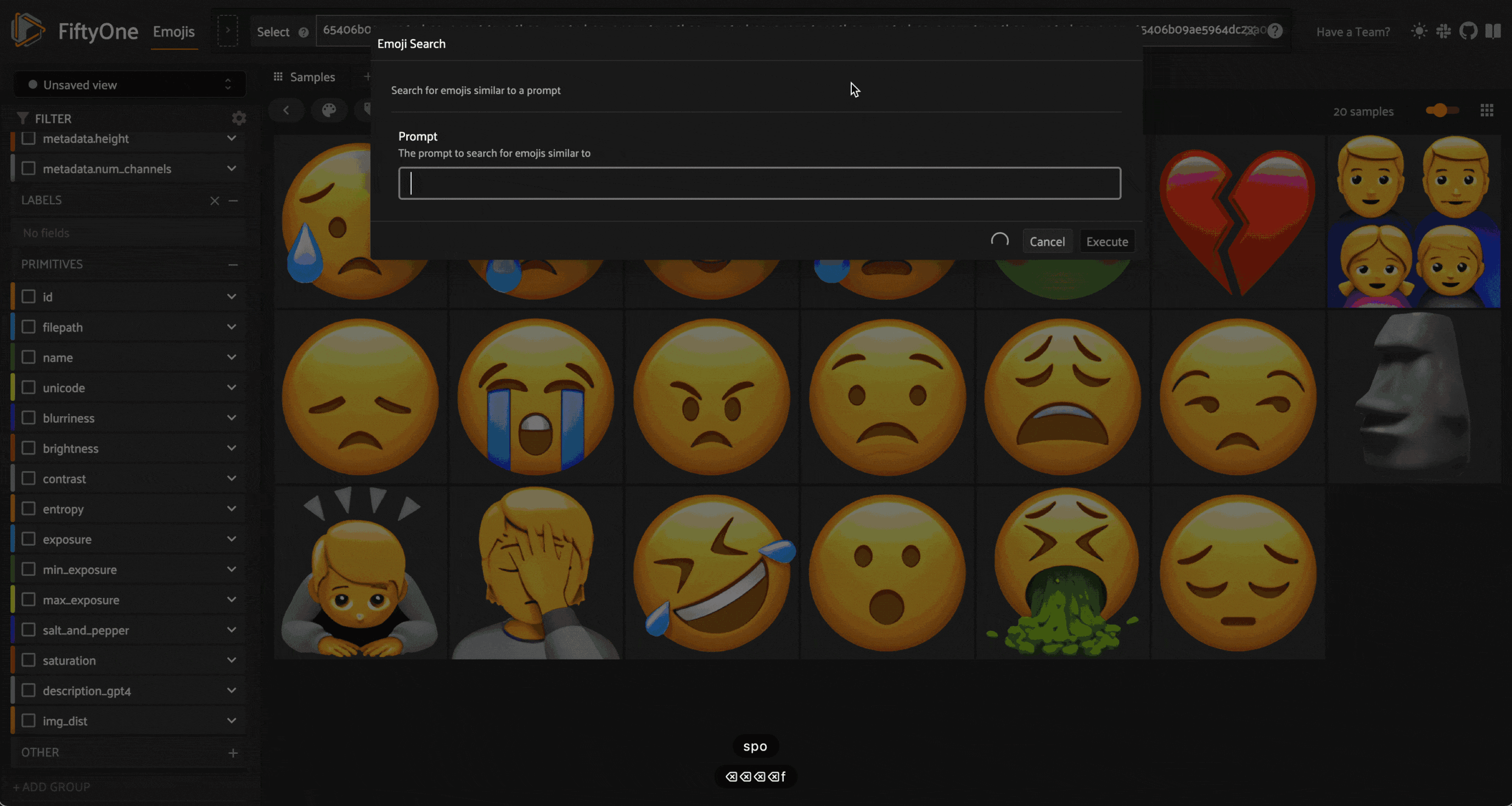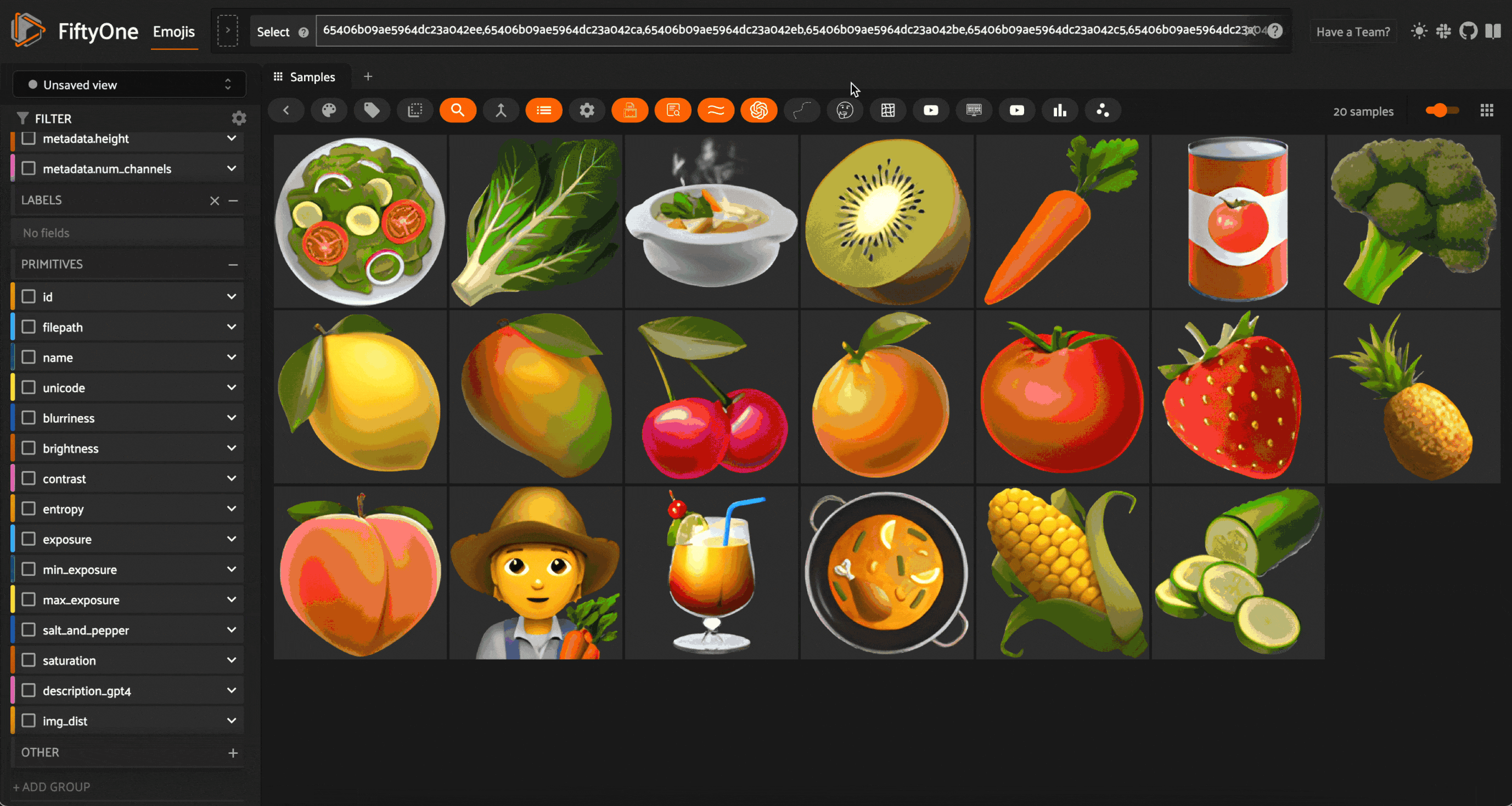
Again, it isn’t perfect. But it’s not bad!
Using the Emoji Search Engine
There are three ways to use this emoji search engine: hosted (free), locally via UI (open source), or locally via command line (also open source). All three options are quite easy!
Online
Head over to try.fiftyone.ai/datasets/emojis, sign in (it’s free), and click on the emoji button in the menu above the grid of images. That’s it!
Locally via the UI
If you want to perform emoji searches locally with the same visual interface, you can do so with the Emoji Search plugin for FiftyOne.
First, install FiftyOne:
pip install fiftyone
Then download the Emoji Search plugin and install its requirements:
fiftyone plugins download https://github.com/jacobmarks/emoji-search-plugin fiftyone plugins requirements @jacobmarks/emoji_search --install
Launch the FiftyOne App:
fiftyone app launch
Click on the “browse operations” text, search for “emoji”, and click on the entry “Create Emoji Dataset”. This will download the high-resolution images of the emojis, along with embeddings and all other relevant data. At the top left of the app, click in the “Select dataset” box and select “Emojis”. Now you should see the same UI as in the hosted version.
Locally via the CLI
Finally, you can search via the command line using the Emoji Search Python CLI library. Install the package from GitHub repository with:
pip install git+https://github.com/jacobmarks/emoji_search.git
Then you can start searching using the emoji-search command, followed by the text query (with or without quotation marks).
emoji-search beautiful sunset
+-------+-----------------+---------+ | Emoji | Name Unicode | +-------+-----------------+---------+ | 🌞 | sun with face | U+1F31E | | 🌇 | sunset | U+1F307 | | 🌅 | sunrise | U+1F305 | | 🔆 | bright button | U+1F506 | | 🌆 |cityscape at dusk| U+1F306 | +-------+-----------------+---------+
The first search you perform will download embeddings to your device if necessary.
All three versions support copying an emoji to clipboard with pyperclip. In the UI, click on the image for an emoji, and you’ll see a copy button appear in the menu. In the CLI, pass the -c argument to copy the top result to clipboard.
Conclusion
Emojis might seem like a silly subject to obsess over. And in practice, the utility of a semantic emoji search engine over lexical emoji search may be somewhat limited. The real value in this endeavor is in understanding the boundaries and overlaps between two modalities we traditionally think of as distinct: images and text. Emojis sit squarely in this intersection and as such, they allow us to probe the strengths and weaknesses — the capabilities and limitations of today’s multimodal models.
The Semantic Emoji Search Engine I ended up building is far from perfect. Frankly, emojis have subjectivity, connoting different things for different people, that is impossible to precisely bottle up. But going back to the motivating example, when I type in “an audio player”, I get some solid results:
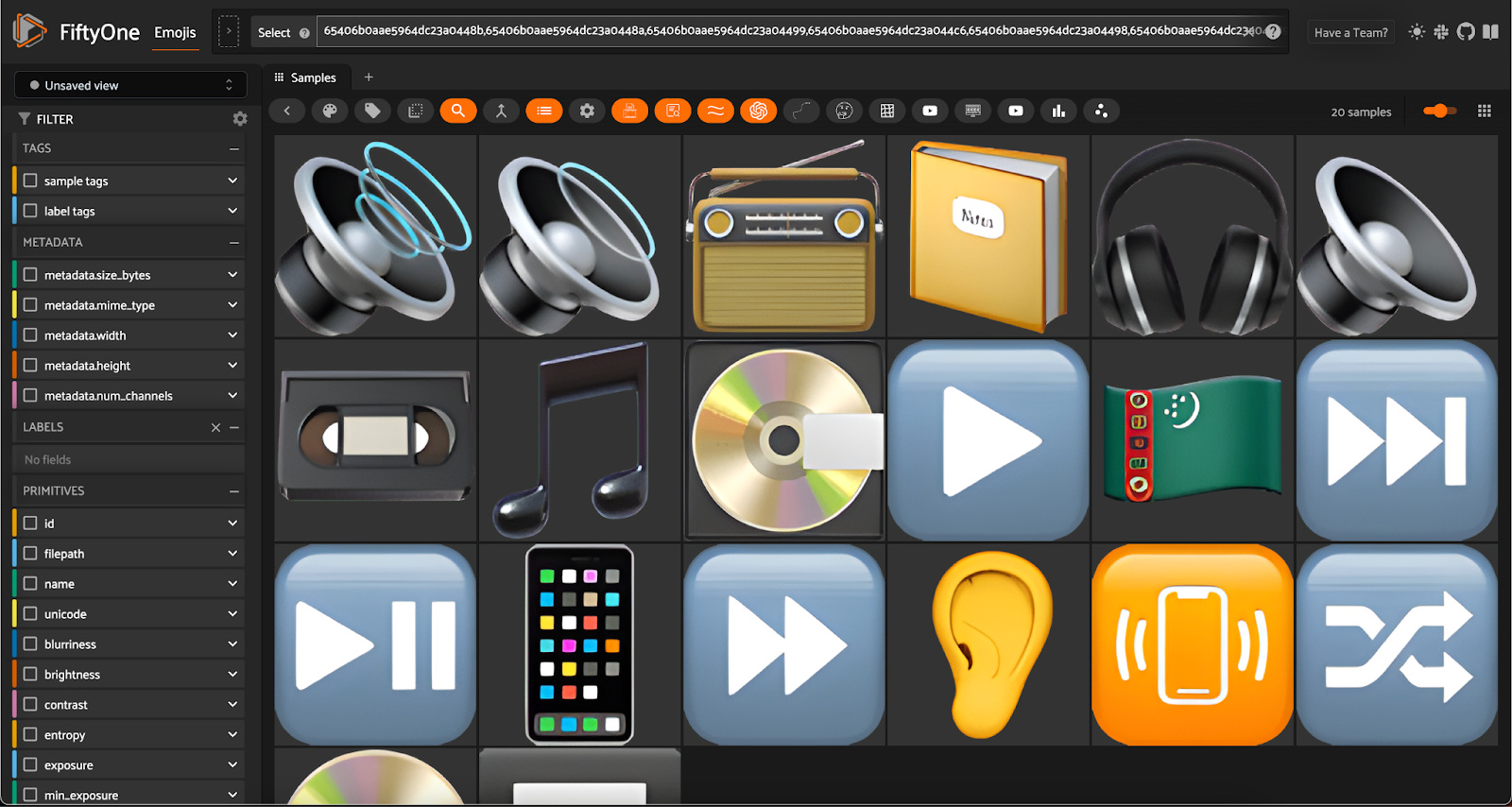
I’ll end with a quote from Nancy Gibbs, a Professor at the Harvard Kennedy School and former managing editor for TIME magazine:
What makes emojis special is the fact that [they have] helped millions express themselves better than even the wide array of words in the Oxford dictionary [could].
Nancy Gibbs

