Earlier this week, Jacob Marks, PhD and Machine Learning Engineer at Voxel51, presented the workshop: Getting Started with FiftyOne. This workshop was the first in a series of hands-on, educational events focused on showing you step-by-step how to use FiftyOne. In this post, we summarize the workshop, recap the questions and their answers that came up during the event, and share upcoming dates for the workshop in case you want to join or share them with colleagues.
Wait, what’s FiftyOne?
The Getting Started with FiftyOne Workshop is all about the FiftyOne toolset. But if you’re new to FiftyOne – you may be wondering, what is it? Data engineers and scientists need the right tools to visualize datasets and interpret models faster and more effectively. FiftyOne does just that – it is the open source machine learning toolkit that enables you to build better computer vision workflows by improving the quality of your datasets and delivering insights about your models, so that you can get to production faster.

New workshops announced!
We are excited to announce the dates and times for three more Getting Started with FiftyOne Workshops!
- April 26 @ 9:00 AM IST [1:30 PM AEST / 03:30 UTC]
- May 31 @ 4 PM BST [11 AM EDT / 15:00 UTC]
- June 28 @ 10 AM PDT [1 PM EDT / 17:00 UTC]
In addition to the Getting Started with FiftyOne Workshops, we are also building out a catalog of advanced workshops to take you beyond the basics of getting started and into deeper ways FiftyOne can enhance and streamline your computer vision workflows. Stay tuned for future announcements with the schedule of advanced topics.

Workshop summary
We created the “Getting Started with FiftyOne” workshop to help you gain greater visibility into the quality of your computer vision datasets and models. The workshop was half lecture and half lab so that you would walk away with a solid understanding of the basics of the FiftyOne toolset, architecture, and popular workflows, as well as learn how to install FiftyOne, work with the Python SDK and App, and perform basic tasks like importing datasets, creating views, and drawing out insights from your data and models.
Lecture: Get up-to-speed on the basics
Jacob kicked off the workshop promptly at 51 o’clock 😂 and explained FiftyOne at a high level: “It helps you to visualize, clean, and curate your data, find hidden structure in that data, evaluate model predictions on your datasets, as well as different subsets of your datasets. And its design philosophy is all about flexibility and customizability. So FiftyOne is all about giving you the power to explore and understand your data, regardless of your specific workflow or machine learning pipeline.”
Jacob then thoroughly walked us through the basic concepts summarized below.
Curate data
In the workshop, Jacob demonstrated some of the ways FiftyOne helps you to curate data:
- Find: filter, match, sort, select
- Remove: duplicates
- Add: tags, metadata, predictions
- Correct: annotation mistakes
- Save: interesting “views”

Understand data
Jacob also covered how FiftyOne helps you understand your data with:
- Aggregate statistics: FiftyOne supports a variety of histograms and all of the traditional aggregations for numerical quantities you would expect: min, max, mean, standard aviation, and more.
- Embeddings: Embeddings are numerical vector representations of certain aspects of the properties of our data. And those help us to understand our data in a lot of different ways. In the workshop, Jacob explored the Berkeley Deep Drive (BDD) dataset to show embeddings in action, including clusters of daytime images and nighttime images. Embeddings can help identify hidden structures in datasets that we may not otherwise be aware of.
- Interactive visualization: Jacob noted that all these visualizations have been and are interactive. Examples: if you lasso points in an embeddings plot, then you’ll see just those samples; if you explore a cell in a confusion matrix, you can see just those samples.
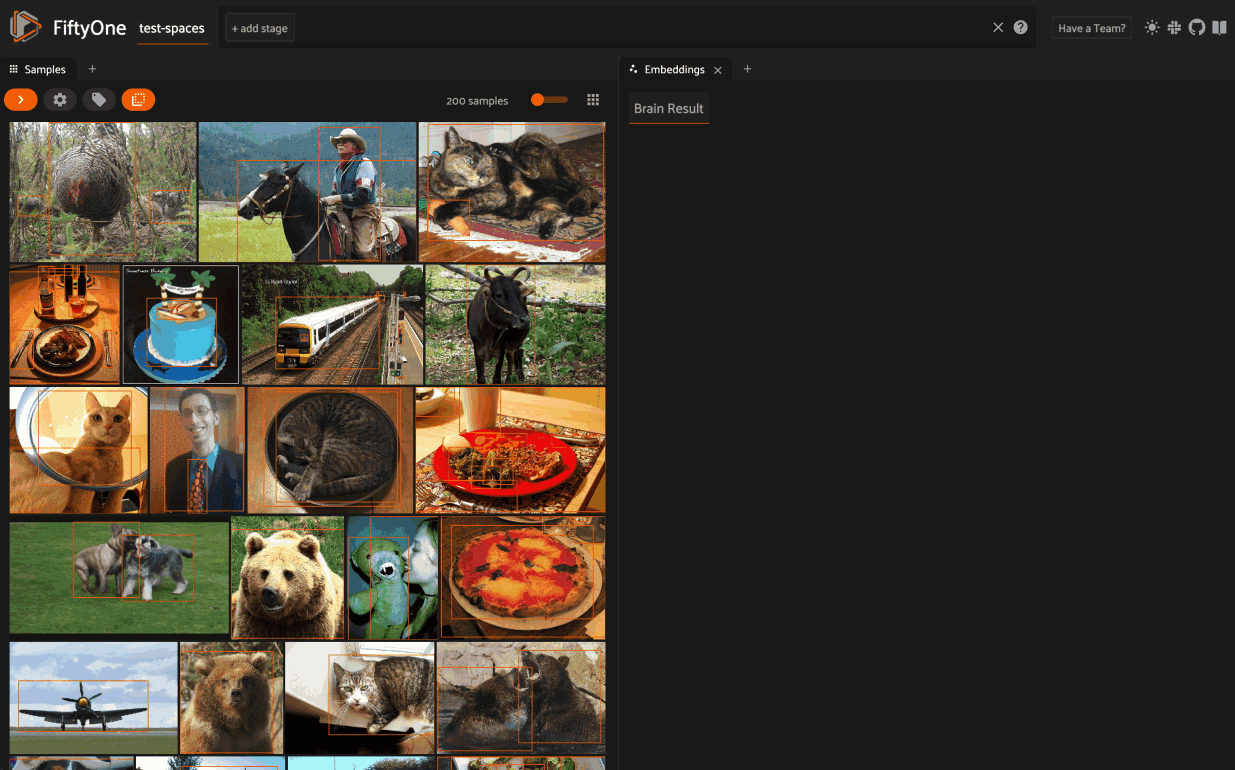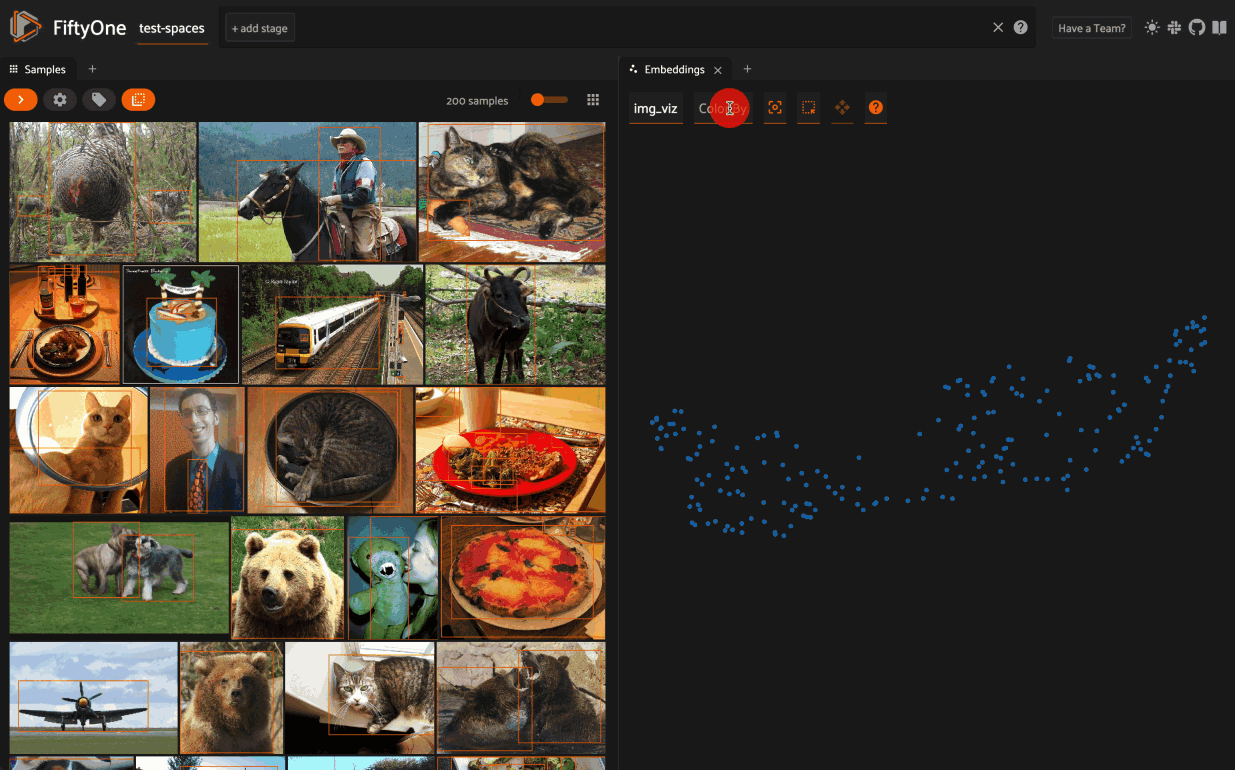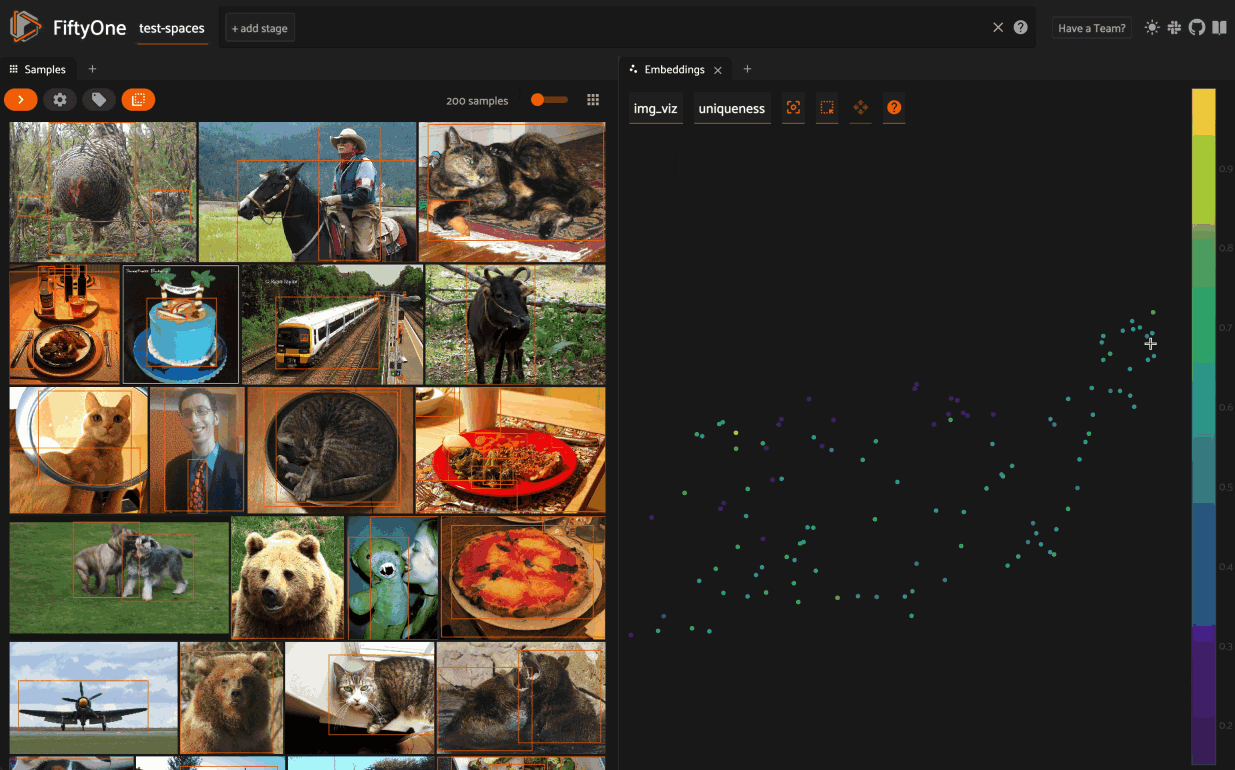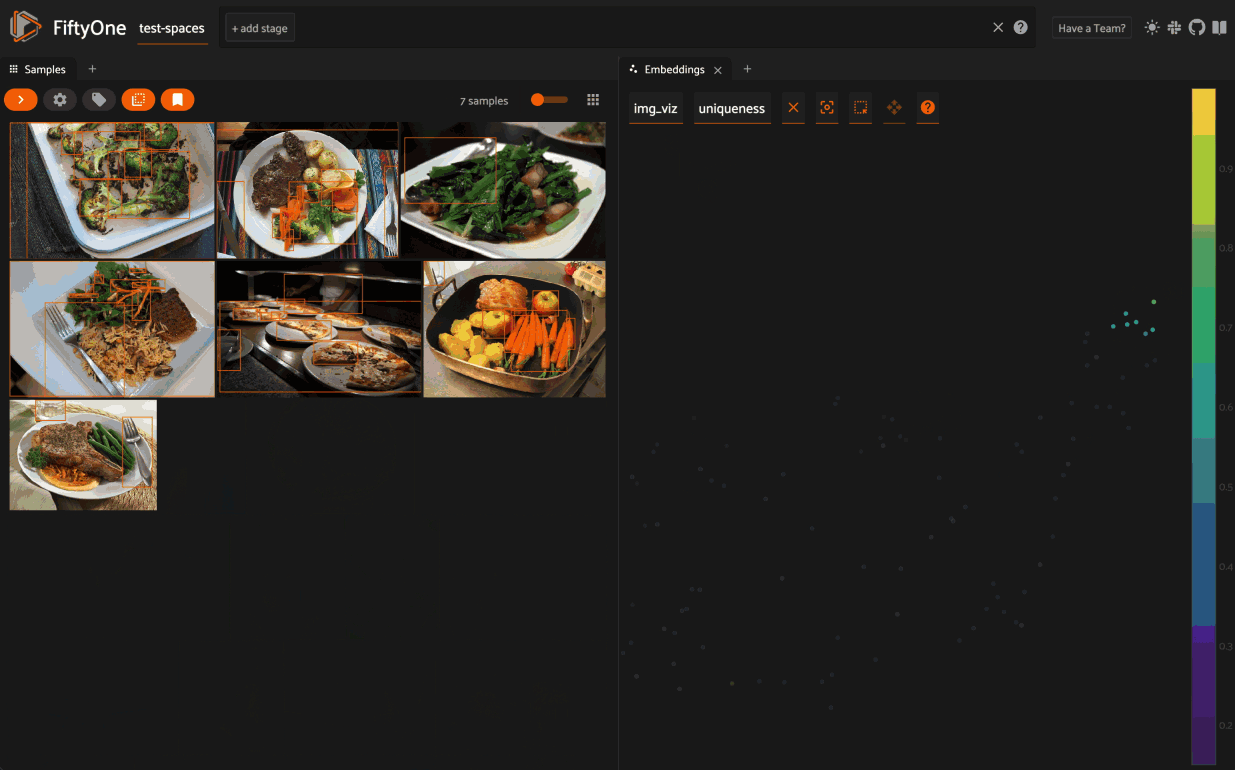
Evaluate data
Here Jacob explained: “Evaluating is a key component in many computer vision workflows. So FiftyOne has support for tons of one-number metrics: precision, recall, F1 score, intersection over union, you name it. There’s support for all of your favorite plots including PR curves and confusion matrices. You can also perform analysis on samples, labels, and entire datasets.”

Tap into the flexibility of FiftyOne
Jacob noted: “FiftyOne’s design philosophy is all about flexibility and customizability. Everything I’ve mentioned so far has flexibility surrounding that because we know that computer vision is not a one-size-fits-all solution field.”
Jacob described FiftyOne’s flexibility with regards to:
- Datasets
- Models
- Media types
- Labels
- Plugins
- More!
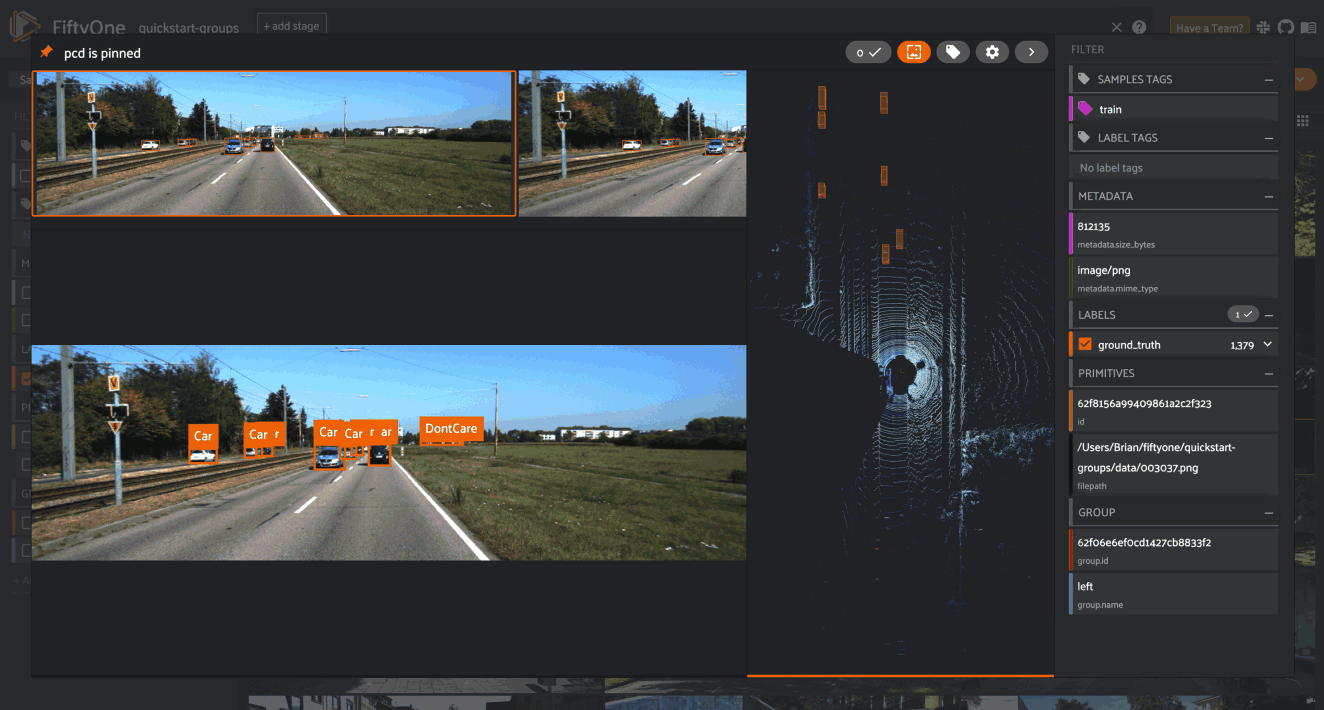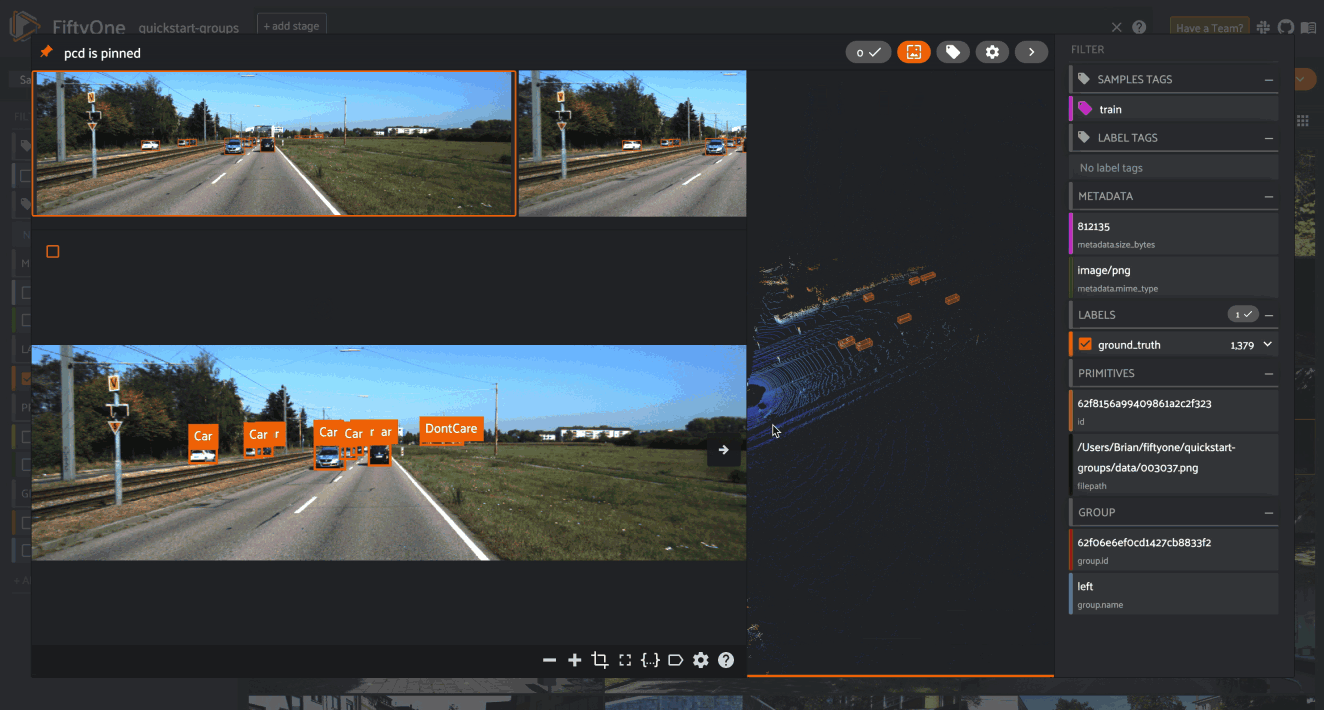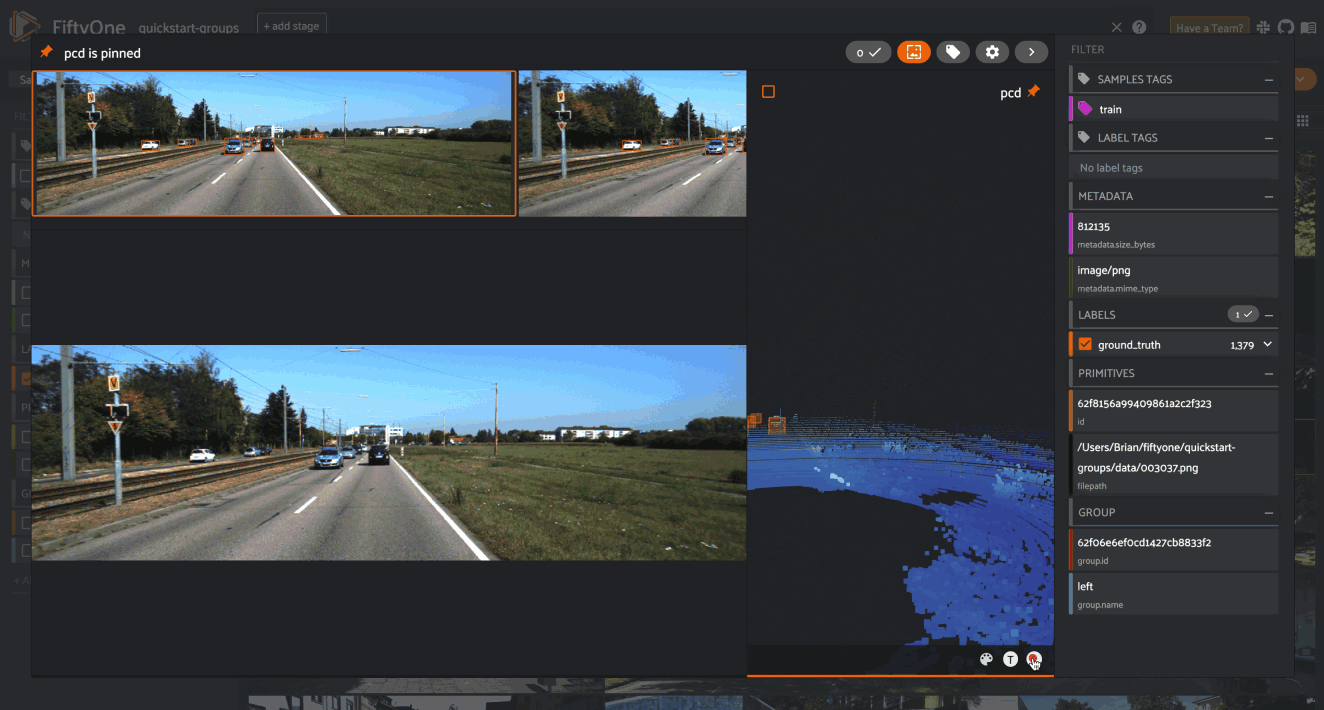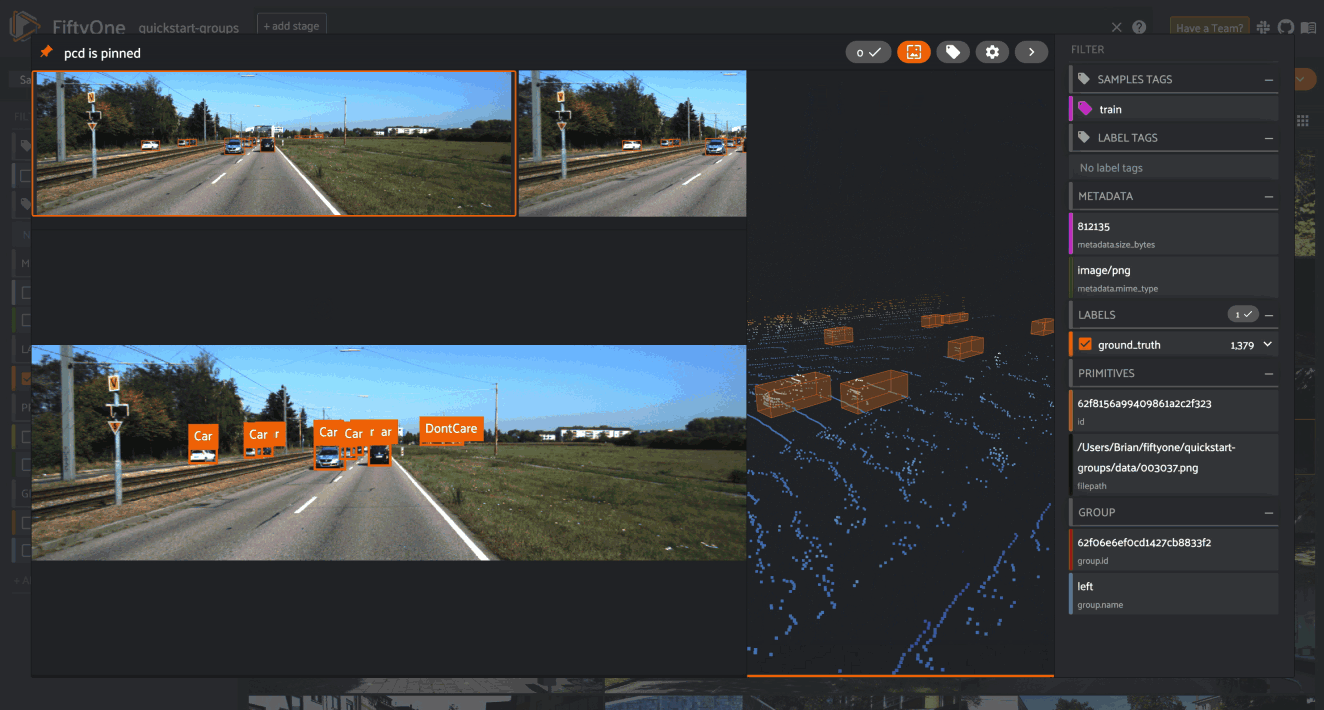
Key components of FiftyOne
Before the hands-on lab portion, Jacob gave a primer on the core components of FiftyOne that in the lab part we will see firsthand!

He also primed us on some additional basic concepts:
- A comparison of tabular data (structured data) and computer vision data (unstructured data); FiftyOne is the pandas of computer vision
- A look under the hood of a schema – including a dataset, samples, fields, metadata, filepath, labels, media type, and more
Lab: fire up FiftyOne and experience it for yourself!
The second half of the workshop was a hands-on lab, so you could put what you learned in the lecture into action. By the end of the workshop, attendees fired up FiftyOne and explored datasets and models firsthand.
The lab portion of the workshop focused on enabling you to perform all the steps needed to achieve all of this:
- Install FiftyOne
- Load datasets and models from the FiftyOne Dataset Zoo and FiftyOne Model Zoo
- Easily navigate the FiftyOne App’s features
- Programmatically inspect attributes of a dataset
- Add new samples and custom attributes to a dataset
- Evaluate model predictions
- Save insightful views into the data
- More!
Q&A recap
If we manually create a view in the GUI, can this be exported somehow, to be used later on a different machine?
With open source FiftyOne, any views that you save in the GUI can be pulled up in Python on the same machine in the future. If you want to share those views with others, you can serialize views to JSON, transfer them, then rebuild them:
stages = view._serialize() still_view = fo.DatasetView._build(dataset, stages)
If you expect to be frequently sharing views with other people, and/or working on multiple machines, then you may want to consider FiftyOne Teams, which has built-in support for sharing datasets and views.
Can FiftyOne App be rendered inside JupyterLab?
Yep! It gets rendered in an output cell that you can pop out and move into different tabs within JupyterLab. FiftyOne also supports Colab notebooks, Databricks notebooks, and more.
Does the MongoDB connection work inside a JupyterLab environment?
Yes! On the backend, FiftyOne uses a non-relational database structure with MongoDB. The database gets launched in a separate process, even when launched inside of the JupyterLab environment. You can specify your MongoDB configuration within a Jupyter notebook.
Learn how to configure MongoDB manually.
Do you have any docs to find out more about the Colab or Databricks integration?
Yes! Visit the docs on notebook environments.
Additionally, you can try FiftyOne in Colab right in your browser.
What’s the typical cadence of new releases?
Major releases are primarily made available around the completion of new features. However, between major releases, there are more frequent minor releases to handle bugs. You can check out the release notes for all versions here: https://docs.voxel51.com/release-notes.html
I want to use the FiftyOne App to quickly look at my YOLOv5 dataset and annotations. I’d like to quickly analyze my data and do some very basic tasks like remove duplicates, show distributions, etc. Can you explain what can be done natively in the App vs what requires the Python SDK?
Today, you need to first load your dataset into FiftyOne either through the Python SDK or the command-line interface. But no need to be afraid, loading a YOLOv5 dataset takes only a few lines of code.
Once your dataset is in FiftyOne, you can then visualize it in the App, view distributions, filter on your labels, etc.
Noting that finding duplicate samples will require a couple more lines of code to compute similarity.
Is there a tutorial for integration on FiftyOne and Label Studio?
Yes! Check out the Label Studio integration and examples in the docs.
And if you’re curious about integrations with other annotation tools, FiftyOne also integrates with CVAT, Labelbox, and Scale.
To get uniqueness measures and those cool scatterplots, do we compute the embeddings once? Or do we have to compute embeddings each time for uniqueness, similarity, visualizations, etc.?
Great question! You can compute the embeddings once and then reuse them for uniqueness, similarity, visualizations, etc.
All of these FiftyOne Brain methods allow you to specify embeddings in multiple ways. You could provide a FiftyOne Zoo Model, in which case the embeddings would be generated, but you can also provide a NumPy array of precomputed embeddings, or a field of your dataset which contains the embeddings for each sample.
For example, for similarity:
# Compute embeddings each time results = fob.compute_similarity(dataset, model=foz.load_zoo_model(...), ...) # Compute embeddings once and reuse them results = fob.compute_similarity(dataset, embeddings=np.array(...), ...)
Learn more about this similarity example in the docs.
Can the underlying data in those histograms be extracted using Python?
Yes! The underlying data in these histograms can absolutely be extracted using Python. Visit the docs on using aggregations to learn how.
Is it possible to convert an image dataset to a video dataset?
Yes, you can convert an image dataset to a video dataset. There are many different formats for videos, so you would need to be thoughtful about the way that you did that, but it is absolutely possible. Additionally, a video dataset in FiftyOne does require a video media file (ex: an .mp4 file) today. So if you have a dataset that is a collection of images, you could convert those to videos with something like FFmpeg, then load those videos into FiftyOne. Stay tuned for updates on this in the near future.
How many images can I browse with FiftyOne? Is there an upper limit?
There’s no limit to the number of images you can browse in FiftyOne. We frequently see users with 10+ million samples. Though there are two axes to consider in terms of performance: number of samples and number of fields. When you have a billion detections on a dataset, a filter query that touches each of them will take some time.
The sweet spot for snappy FiftyOne usage is on the order of hundreds of thousands of samples and dozens of fields. A common use case when datasets are larger than this is to have a data lake dataset with all samples in it, and then smaller working dataset clones that you actively work with.
See dataset cloning docs here.
If I run an evaluation over a complete dataset, is it possible to obtain metrics for a filtered DatasetView without having to rerun the complete evaluation? (For example, running evaluations for a dataset containing data from all countries, and later obtaining/extracting per-country metrics (precision, recall, mAP).)
Currently, if you want to evaluate a subset into a dataset, then you need to perform that evaluation separately. The evaluation of detections can change depending on the ground truth/predicted labels that exist. So two bounding boxes that were matched in one view may be matched differently in another. We plan to add more flexibility around this in the future.
Is there an easy way to import YOLO predictions into FiftyOne?
Yes! There is a one-line way to do it here.
And you can learn even more about working with YOLOv8 (and therefore also v5 because they share the same format) in the YOLO tutorial.
For other YOLO versions, reach out in Slack and we can assist.
Additional resources
If you missed the workshop or would like to revisit it, here are some additional resources for you:
- The Colab notebook with the exercises from the hands-on lab
- Join us for a future workshop
Stay tuned for the video recap of the Getting Started with FiftyOne Workshop coming soon.

