Editor’s note: This is a guest post by Chien Vu, PhD, Machine Learning Researcher at Detomo, Japan



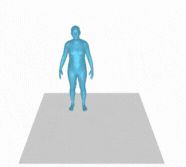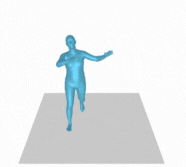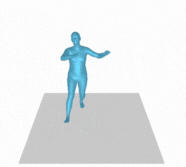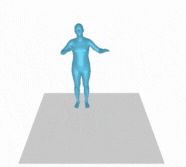
Creating movement based on written descriptions has various applications in industries such as gaming, filmmaking, robotics animation, and the future of the metaverse. Conventionally, motion capture, also known as mocap, is a technique used to capture the movements of an object or individual in real time and convert them into digital data. It involves placing reflective markers on the object or individual’s body, which are then tracked by cameras or other sensors. The captured data can then be used to animate digital characters, create visual effects, or analyze movement for scientific or medical research. Motion capture is widely used in the entertainment industry for films, video games, and virtual reality experiences, as well as in sports science, biomechanics, and robotics.
However, motion capture is a relatively expensive process due to the equipment required (high-quality cameras, specialized software, and reflective markers), people to operate the equipment and ensure high quality results, and other factors.
Generating movement from written descriptions could drastically reduce the time and money required to produce games and movies, opening up new avenues for creators. In this blog post, we present a novel framework called T2M-GPT that utilizes a Vector Quantised Variational AutoEncoder (VQ-VAE) and a Generative Pretrained Transformer (GPT) to generate human motion capture from textual descriptions. The T2M-GPT framework achieves superior performance compared to other state-of-the-art approaches, including recent diffusion-based methods. Notably, T2M-GPT produces high-quality motion and demonstrates comparable consistency between text and generated motion. Continue reading for further details about T2M-GPT, including why we created it, how it works, and how to try it out.
Human motion synthesis
Human motion synthesis, also known as motion generation, is a computer graphics technique used to generate realistic and natural-looking human movements in a virtual environment. It involves developing algorithms and models that can simulate human motion, typically by utilizing motion capture data, physical laws, and artificial intelligence techniques. The goal of human motion synthesis is to create virtual characters that can move and interact with their environment in a manner that appears natural and believable to human observers. There are three different methods for generating it: future motion prediction, monocular motion estimation, and conditioned motion synthesis.
Future motion prediction
Future motion prediction is the process of using available information to predict the future trajectory or movement of an object or entity. This can be accomplished through various means, such as mathematical models, machine learning algorithms, or physical simulations. Predicting future frames from past motion or an initial pose has a history dating back to the 1980s, with statistical models commonly used in earlier studies. Recent research has shown promising results using generative models with neural networks such as DLow [1] (Diversifying Latent Flows) and SoMoFormer [2] (Social Motion Transformer).
DLow uses a single random variable and a set of learnable mapping functions to generate correlated latent codes, which are then decoded into a diverse set of correlated samples. During training, DLow optimizes the latent mappings to promote sample diversity using a flexible diversity-promoting prior. The prior can be customized to generate diverse motions with common features. Meanwhile, SoMoFormer is proposed for multi-person 3D pose forecasting. The unique transformer architecture models human motion input as a joint sequence, allowing attention over joints while predicting the entire future motion sequence for each joint in parallel. SoMoFormer extends to multi-person scenes by using the joints of all individuals in a scene as input queries, and by learning relationships between joints and between people.
Monocular motion estimation
Monocular motion estimation refers to the process of estimating the motion of an object or scene using a single camera. This is done by analyzing the changes in the image captured by the camera over time, and using this information to determine the direction and speed of motion. There are several techniques used for monocular motion estimation, including optical flow (Figure 1), structure from motion (Figure 2), and visual odometry.
Optical flow is a technique that estimates the motion of image pixels over time, while structure from motion uses the relative motion of different points in the scene to estimate the camera’s motion like VIBE [3] (Video Inference for Body Pose and Shape Estimation).
VIBE uses an existing large-scale motion capture dataset (AMASS) along with unpaired, in-the-wild, 2D keypoint annotations. The main innovation of VIBE is an adversarial learning framework that uses AMASS to distinguish between real human motions and those produced by the temporal pose and shape regression networks. By using a temporal network architecture and performing adversarial training at the sequence level, VIBE can generate kinematically plausible motion sequences without the need for in-the-wild ground-truth 3D labels.

In addition to optical flow and structure from motion, another technique used for monocular motion estimation is visual odometry, which estimates the 3D structure of the scene based on the camera’s motion. Recently, an end-to-end learning approach called PoseConvGRU [4] has been developed to directly map input image pairs to ego-motion estimates using a two-module Long-term Recurrent Convolutional Neural Network. The feature-encoding module of this network captures short-term motion features in an image pair, while the memory-propagating module captures long-term motion features in consecutive image pairs. The visual memory is implemented with convolutional gated recurrent units (ConvGRU), which propagate information over time. This method stacks two consecutive RGB images to extract motion information and estimate poses, which are then passed through a stacked ConvGRU module to generate the relative transformation pose for each image pair.
Conditioned motion synthesis
While there is a lot of research on future motion prediction, synthesis from scratch has received less attention. Early work used statistical models like PCA [5] and GPLVMs [6] to learn cyclic motions; and the next generation of synthesis involved guiding conditioning with short text or language representations like Text2Action [7] and Language2Pose [8].
Text2Action is a generative adversarial network (GAN) built on a sequence-to-sequence (SEQ2SEQ) architecture that can generate a sequence of human actions based on a sentence describing human behavior. The Text2Action model includes a text encoder recurrent neural network (RNN) and an action decoder RNN, enabling the synthesis of various actions for a robot or virtual agent.
Language2Pose tries to map linguistic concepts to motion animations by learning a joint embedding of language and pose. This joint embedding space is learned end-to-end using a curriculum learning approach that emphasizes shorter and easier sequences before longer and harder ones.
To generate human motion from a joint embedding for language and motion, these generative deep learning models should be able to learn precise mapping from the language space to the motion space. Recently MotionCLIP [9] aligns its latent space with that of the Contrastive Language-Image Pre-training (CLIP) [10] model to imbue rich semantic knowledge into the human motion manifold; and ACTOR [11] and TEMOS [12] proposed transformer-based VAEs for action-to-motion and text-to-motion.
While these models represent important steps on the path to generating motion from text, they are limited in their ability to produce high-quality motion for longer and more complex textual descriptions. Additionally, some of these models utilize a complex three-stage process for text-to-motion generation but sometimes they still fail to generate high-quality motion consistent with the text. To improve the performance of motion generation, it is recommended that we explore methods to elevate the traditional approach for acquiring discrete representations with the advanced capabilities of high-quality large language models such as Generative Pre-trained Transformer (GPT). That’s why Text to Image-Generative Pre-trained Transformer (T2M-GPT) was proposed.
Transformers in motion
The T2M-GPT [13] method is a straightforward yet efficient technique that utilizes a two-stage process to produce high-quality motion sequences consistent with complex textual descriptions. T2M-GPT uses a simple and classic framework based on Vector Quantized Variational Autoencoders (VQ-VAE) to learn the discrete representation for motion generation. Comparing to complex diffusion-based techniques such as Human Motion Diffusion Model (MDM) [14] or MotionDiffuse [15], T2M-GPT yields comparable performance. Moreover, the T2M-GPT utilizes models similar to GPT, which include distinct representations, enabling the model to produce motion from text with increased precision and competitive outcomes. The two-stage process is outlined below.
Stage 1
VQ-VAE is employed to convert motion sequences into discrete code indices. Motion VQ-VAE consists of a standard CNN-based architecture with 1D convolution (Conv1D) with stride 2, residual block (ResBlock), and ReLU activation as shown in Figure 3 below.
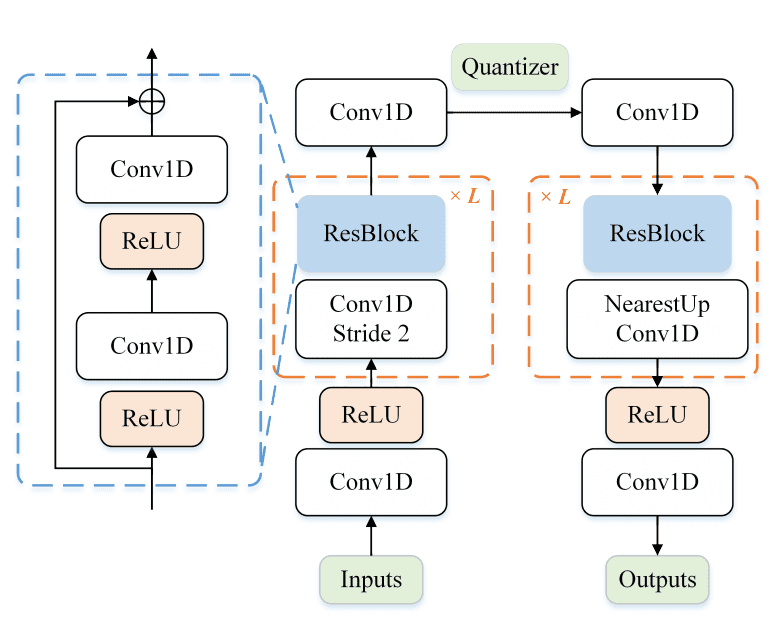
VQ-VAE has exhibited notable efficacy in generative tasks pertaining to various modalities, including but not limited to image synthesis, text-to-image generation, speech gesture generation, and music generation. The success of VQ-VAE stems from its aptitude to dissociate the process of learning discrete representation and the prior. Nevertheless, a rudimentary training of VQ-VAE can encounter codebook collapse, wherein only a meager number of codes are stimulated, leading to suboptimal performance in reconstruction and generation.
The VQ-VAE frequently becomes trapped in a suboptimal state due to two underlying reasons. Firstly, the encoder is incentivized by the commitment loss (a measure to encourage the encoder output to stay close to the embedding space and to prevent it from fluctuating too frequently from one code vector to another) to solely adhere to the codebook vectors that it has been designated to, which hinders it from learning to prioritize other codebook vectors that are yet to be assigned. Secondly, solely those codebook vectors that have been allocated encoder output vectors will undergo updating. Therefore, any codebook vector that lacks an assigned encoder output vector will retain its position in the embedding space unchanged. Consequently, a considerable portion of the codebook remains unutilized.
To mitigate this issue, VQ-VAE is trained using exponential moving average (EMA) [16] and Code Reset techniques [16]. EMA facilitates the convergence of VQ-VAE by expediting the learning process, without being reliant on a specific optimizer selection. On the other hand, the Code Reset techniques serve to randomly reset one of the encoder outputs from the current batch when the mean usage of a codebook vector falls below a specified threshold, ensuring that all codebook vectors are utilized and are able to provide a gradient for learning purposes (Figure 4).
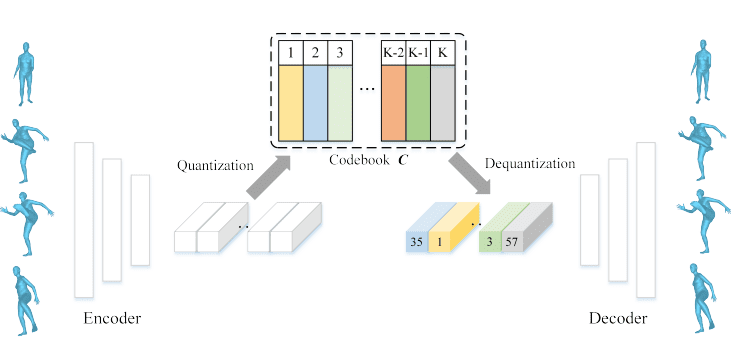
Stage 2
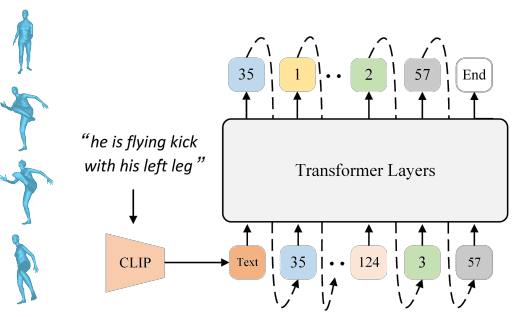
In the second stage, a standard GPT-like model is trained to generate sequences of code indices from pre-trained text embeddings. To improve the model’s ability to predict motion length, a specific End token is introduced to signify the end of a motion. The implementation of the End token addresses concerns that other methods face, such as requiring manual input of the motion length in MDM and MotionDiffuse [14, 15] which is not a feasible approach for real-world applications, because we don’t know the actual motion length given the input text description. Therefore, the End token is the simple solution that helps the model knows when the motion should end
GPT, as a Large Language Model (LLM), has the capacity to randomly generate the next token, however training GPT for motion description is difficult. In the training phase, i − 1 correct index predicts the next index. However, in the inference phase, there is no guarantee that indices serving as conditions are correct. To address this issue, sequence corruption is employed by replacing τ × 100% (τ ∈ U[0, 1]) ground-truth code indices with random ones during the training process to mitigate this discrepancy (Figure 5).
Training
For training motion VQ-VAE and T2M-GPT, two standard datasets exist for text-driven motion generations:
- KIT Motion-Language (KIT-ML) [17] contains 3,911 human motion sequences scaled to 12.5 frames per second and 6,278 textual annotations. The total vocabulary size is 1,623 words, and each motion sequence is described in 1 to 4 sentences. The average length of descriptions is approximately 8 words.
- HumanML3D [18] is currently the largest 3D human motion dataset with textual descriptions. The dataset contains 14,616 human motions scaled to 20 FPS and 44,970 text descriptions. The total vocabulary size is 5,371 words. The average length of descriptions is approximately 12 words.
Evaluating synthetic motion
To evaluate the global representations of motion and text descriptions, five metrics were used:
- R-Precision metric is utilized to evaluate the ranking of Euclidean distances between a motion sequence and 32 text embeddings, consisting of one ground-truth and 31 randomly chosen mismatched descriptions. This metric serves as an effective measure to assess the degree of compatibility between the motion sequence and the textual description.
- Frechet Inception Distance (FID) also known as Wasserstein-2 distance is used to calculate the distribution distance between the generated and real motion on the extracted motion features. Lower scores indicate the two groups of motion are more similar, or have more similar statistics, with a perfect score being 0.0 indicating that the two groups of motion are identical. FID is an important metric widely used to evaluate the overall quality of generated motions.
- Multimodal Distance (MM-Dist) calculates the mean Euclidean distance between the text feature and the corresponding generated motion feature. A lower score indicates that the model can comprehend the text well, while a higher score might indicate a possibility of generating a mismatched motion.
- Diversity measures the variance of the generated motions across all action categories. To determine this, a random sampling process is performed on a set of motions generated from various action types, resulting in two subsets of equal size. The average Euclidean distances between the two subsets are then calculated.
- Multimodality (MModality) is different from diversity; multimodality measures the average diversity within each action type. A low value of multimodality indicates that the generated motions might be similar, even with varying text prompts. Conversely, a high multimodality value indicates a variety of motions, despite using the same textual input. Thus, it is advisable to maintain a sufficiently high value.
After being assessed using these metrics, VQ-VAE demonstrates a level of performance that is close to real motion, indicating the utilization of high-quality discrete representations. For the generation, T2M-GPT achieves comparable performance on text-motion consistency (R-Precision and MM-Dist) compared to the state-of-the-art method MotionDiffuse [15]. Manually corrupting sequences during the training of GPT brings consistent improvement, meanwhile, motion length can be predicted straightforwardly and effectively through an additional End token. Here is the same output from T2M-GPT (Figure 6 and Figure 7):

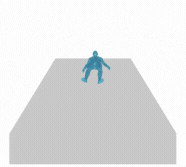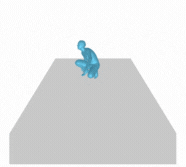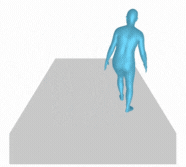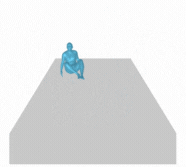
Figure 6 (above). A person jogs in place, slowly at first, then increases speed; they then back up and squat down


Figure 7 (above). Someone appears to be stretching; they turn their upper body in a counter-clockwise direction and then lean their upper body from side to side
However, there are still some failure cases like the following example (Figure 8). This could be attributed to either insufficient information in the text prompt or inaccurate description of motion in the training dataset. One of the ways to improve this is preparing more training dataset or using different descriptions with the same motion to enhance the diversity of motion generation.
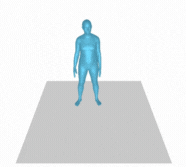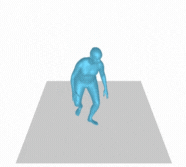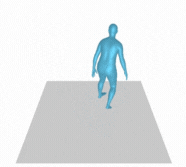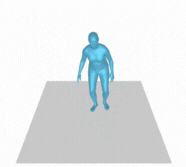

Figure 8. A person slightly crouches down and walks forward then back, then around slowly
Check out the Generate Human Motion Hugging Face Space, where you can quickly test the performance of T2M-GPT. The Space supports both the skeleton and Skinned Multi-Person Linear 3D Model (SMPL) of the human body.
The training and inference code are also provided in the T2M-GPT GitHub repository.
Conclusion
Utilizing a traditional structure, VQ-VAE and GPT can be combined to generate high quality human motion from textual depictions. With a fairly small training dataset (around 50% of the HumanML3D dataset), T2M-GPT has already outperformed other models such as Language2Pose, TM2T,… on several metrics (FID, MM-Dist, Diversity,…). If the size of the dataset is expanded, it could enhance the model’s performance further.
The model can be extended to other objects by retraining the model on a new dataset with relevant textual descriptions and motion sequences. For instance, if you want to generate motion sequences for a new object like a bicycle, you will need to gather a dataset that includes textual descriptions of different bicycle movements along with the corresponding motion sequences. You can then use this dataset to retrain the T2M-GPT model to generate motion sequences for bicycles.
Models like T2M-GPT may enable people to create motion synthesis for arbitrarily complex action sequences, from text descriptions alone. As research in this field continues to progress, we may even be able to generate more complex and interactive videos that respond to user input or adapt to different environments and industries.
References:
[1] Ye Yuan and Kris Kitani. DLow: Diversifying Latent Flows for Diverse Human Motion Prediction. https://arxiv.org/abs/2003.08386
[2] Edward Vendrow, Satyajit Kumar, Ehsan Adeli, and Hamid Rezatofighi. SoMoFormer: Multi-Person Pose Forecasting with Transformers. https://arxiv.org/abs/2208.14023v1
[3] Muhammed Kocabas, Nikos Athanasiou and Michael J. Black. VIBE: Video Inference for Human Body Pose and Shape Estimation. https://arxiv.org/pdf/1912.05656.pdf
[4] Guangyao Zhai, Liang Liu, Linjian Zhang, Yong Liu. PoseConvGRU: A Monocular Approach for Visual Ego-motion Estimation by Learning https://arxiv.org/abs/1906.08095
[5] Dirk Ormoneit, Michael J. Black, Trevor Hastie, and Hedvig Kjellstrom. Representing cyclic human motion using functional analysis. https://www.sciencedirect.com/science/article/abs/pii/S0262885605001526
[6] Raquel Urtasun, David J. Fleet, and Neil D. Lawrence. Modeling Human Locomotion with Topologically Constrained Latent Variable Models. https://link.springer.com/chapter/10.1007/978-3-540-75703-0_8
[7] Hyemin Ahn, Timothy Ha, Yunho Choi, Hwiyeon Yoo, and Songhwai Oh. Text2Action: Generative Adversarial Synthesis from Language to Action. https://arxiv.org/pdf/1710.05298.pdf
[8] Chaitanya Ahuja and Louis-Philippe Morency. Language2Pose: Natural Language Grounded Pose Forecasting. https://arxiv.org/abs/1907.01108
[9] Guy Tevet, Brian Gordon, Amir Hertz, Amit H Bermano, and Daniel Cohen-Or. MotionCLIP: Exposing Human Motion Generation to CLIP Space. https://arxiv.org/abs/2203.08063
[10] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning Transferable Visual Models from Natural Language Supervision. https://arxiv.org/pdf/2103.00020.pdf
[11] Mathis Petrovich, Michael J. Black, and Gul Varol. Action-Conditioned 3D Human Motion Synthesis with Transformer VAE. https://arxiv.org/pdf/2104.05670.pdf
[12] Mathis Petrovich, Michael J. Black, and Gul Varol. TEMOS: Generating diverse human motions from textual descriptions. https://arxiv.org/abs/2204.14109
[13] Jianrong Zhang, Yangsong Zhang, Xiaodong Cun, Shaoli Huang, Yong Zhang, Hongwei Zhao, Hongtao Lu , Xi Shen. T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations. https://arxiv.org/pdf/2301.06052.pdf
[14] Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Amit H Bermano, and Daniel Cohen-Or. Human motion diffusion model. https://arxiv.org/abs/2209.14916
[15] Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xinying Guo, Lei Yang, and Ziwei Liu. MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model. https://arxiv.org/abs/2208.15001
[16] Will Williams, Sam Ringer, Tom Ash, David MacLeod, Jamie Dougherty, and John Hughes. Hierarchical Quantized Autoencoders. https://arxiv.org/pdf/2002.08111.pdf
[17] Matthias Plappert, Christian Mandery, and Tamim Asfour. The KIT Motion-Language Dataset. https://arxiv.org/abs/1607.03827 [18] Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating Diverse and Natural 3D Human Motions from Text. https://openaccess.thecvf.com/content/CVPR2022/papers/Guo_Generating_Diverse_and_Natural_3D_Human_Motions_From_Text_CVPR_2022_paper.pdf

