Welcome to our weekly FiftyOne tips and tricks blog where we recap interesting questions and answers that have recently popped up on Slack, GitHub, Stack Overflow, and Reddit.
Wait, what’s FiftyOne?
FiftyOne is an open source machine learning toolset that enables data science teams to improve the performance of their computer vision models by helping them curate high quality datasets, evaluate models, find mistakes, visualize embeddings, and get to production faster.
- If you like what you see on GitHub, give the project a star.
- Get started! We’ve made it easy to get up and running in a few minutes.
- Join the FiftyOne Slack community, we’re always happy to help.
Ok, let’s dive into this week’s tips and tricks!
Making fields from duplicates_view available in exported annotations
Community Slack member Vinicius asked (and then figured out the solution on his own!):
“Is it possible to make fields such as dup_type from the duplicates_view() method available in exported annotations?”
Yes! There are a few ways to accomplish this. Here’s the solution that Vinicius came up with. First, move the information to detection level:
for sample in dataset.match(F('dup_type').is_in(['duplicate','nearest'])):
sample.detections.detections[0]['dup_type'] = sample.dup_type
sample.save()
Then export the dataset with include_attributes = True:
dataset.export(..., dataset_type=fo.types.FiftyOneImageDetectionDataset, include_attributes = True)
After importing back the dataset, move the attributes to the sample level:
for dup_type in ['duplicate','nearest']:
dataset.filter_labels('detections',F('dup_type')==dup_type).tag_samples(dup_type)
Learn more about duplicate detection and the FiftyOne Brain in the Docs.
Deleting label fields
Community Slack member Joy asked,
“How can I remove the label field named ‘test?’ in the screenshot below? I’ve tried delete_labels and remove_dynamic_sample_field, but neither does the trick.”
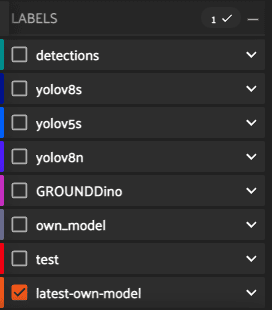
You can delete the “test” field from all samples in the dataset using delete_sample_field(field_name, error_level=0)
The parameters breakdown as such:
- field_name – the field name or
embedded.field.name - error_level (0) – the error level to use. Valid values are:
- 0 (-) – raise error if a top-level field cannot be deleted
- 1 (-) – log warning if a top-level field cannot be deleted
- 2 (-) – ignore top-level fields that cannot be deleted
For more information on delete_sample_field check out the FiftyOne Docs.
UPDATE: This issue was resolved in the FiftyOne 0.21.0 release via the new built-in operators.
Loading datasets on a headless server
Community Slack member Wes asked,
“I’m having some trouble figuring out how to load annotations on a headless server running FiftyOne. Any tips?”
If your dataset is in a common format, you can use these instructions to load your data. If it is not in one of the natively supported formats, use the custom formats instructions.
To visualize your dataset in FiftyOne using a headless machine, aka remote server, check out the remote sessions documentation.
Learn more about using the FityOne App and about how to load datasets into FiftyOne in the Docs.
Efficiently modifying and deleting fields in views
Community Slack member Tobias asked,
“According to the documentation when you use view = dataset.filter_labels(...) to create a view and then save it, it should not override labels currently not in the view. On the other hand if I am selecting certain fields from a sample like this:
sample["my_custom_field1"] = "custom_value1"
sample["my_custom_field2"] = "custom_value2"
sample.save()
view = dataset.select_fields("my_custom_field1")
for sample in view:
sample["my_custom_field1"] = "new_value"
view.save()
My custom field named my_custom_field2 has been deleted from all samples in the dataset! I am not sure whether this is working as intended, as I can’t use select_fields then in this case if I want to update the samples from the view.”
This is intended behavior, as specified in the Docs. This method does not delete samples or frames from the underlying dataset that this view excludes. If a view has excluded fields or filtered list values, this method will permanently delete this data from the dataset, unless fields is used to omit such fields from the save.
You can use the view.save(fields="my_custom_field1") to save only the field you modified and leave the others untouched. However, there is a more efficient way to do this using set_values(). This will let you avoid having to iterate over your samples in memory, and just set the new values that you want to your field directly:
dataset.set_values("my_custom_field1", ["new_value"]*len(dataset))
Learn more about working with dataset views in the Docs.
Accessing samples from Amazon S3
Community Slack member ht asked,
“Using FiftyOne, can I load images directly from S3?”
The open source version of FiftyOne does not support the direct access of images stored on S3. You’ll want to upgrade to FiftyOne Teams which supports cloud-backed media, multiple users, and role-based security. Learn more about FiftyOne Teams on the website and Docs.
Join the FiftyOne community!
Join the thousands of engineers and data scientists already using FiftyOne to solve some of the most challenging problems in computer vision today!
- 1,700+ FiftyOne Slack members
- 3,000+ stars on GitHub
- 4,000+ Meetup members
- Used by 300+ repositories
- 60+ contributors

