Welcome to our weekly FiftyOne tips and tricks blog where we recap interesting questions and answers that have recently popped up on Slack, GitHub, Stack Overflow, and Reddit.
Wait, what’s FiftyOne?
FiftyOne is an open source machine learning toolset that enables data science teams to improve the performance of their computer vision models by helping them curate high quality datasets, evaluate models, find mistakes, visualize embeddings, and get to production faster.

- If you like what you see on GitHub, give the project a star.
- Get started! We’ve made it easy to get up and running in a few minutes.
- Join the FiftyOne Slack community, we’re always happy to help.
Ok, let’s dive into this week’s tips and tricks!
Isolating spurious or missing objects
Community Slack member George Pearse asked,
“Is there a way to just get bounding boxes around the possibly missing and possibly spurious objects in my dataset?”
Here, George is asking about how to isolate potential mistakes in ground truth labels on a dataset. When working with a new dataset, it is always important to validate the quality of the ground truth annotations. Even highly regarded and well-cited datasets can contain a plethora of errors.
Two such common types of errors in object detection labels are:
- A ground truth label was spuriously added to the data, and does not correspond to an object in the allowed object classes
- An object is not annotated, so the ground truth detection is missing
Fortunately, the FiftyOne Brain provides a built-in method that identifies possible spurious and missing detections. These are stored at both the sample level and the detection level.
With FiftyOne’s filtering capabilities, it is easy to create a view containing only the detections that are possibly spurious, or possibly missing, or both. In these cases, you might also find it helpful to convert the filtered view to a PatchView so you can view each potential error on its own. Here is some code to get you started:
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
from fiftyone import ViewField as F
## load example dataset
dataset = foz.load_zoo_dataset("quickstart")
## find possible mistakes
fob.compute_mistakenness(dataset, "predictions")
## create a view containing only objects whose
## ground truth detections are possibly missing
pred_field = "predictions"
missing_view = dataset.filter_labels(
pred_field,
F("possible_missing") > 0,
only_matches=True
).to_patches(pred_field)
## create a view containing only objects whose
## ground truth detections are possibly spurious
gt_field = "ground_truth"
spurious_view = dataset.filter_labels(
gt_field,
F("possible_spurious") > 0,
only_matches=True
).to_patches(gt_field)
We can then view these in the FiftyOne App. Inspect the possibly spurious detection patches, for instance:
session = fo.launch_app(spurious_view)
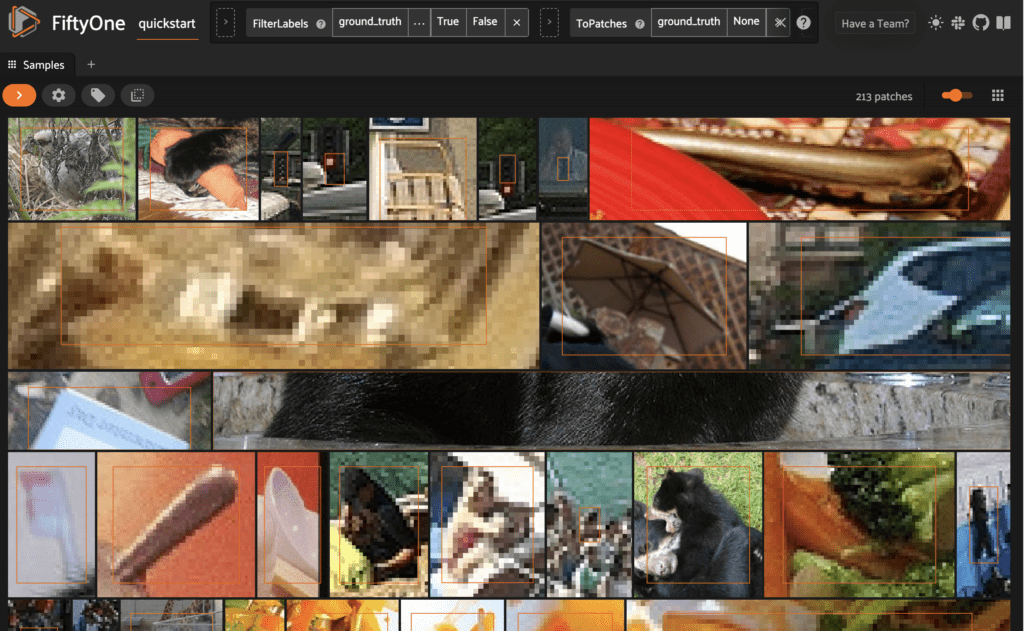
Learn more about identifying detection mistakes in the FiftyOne Docs.
Filtering by ID
Community Slack member Sylvia Schmitt asked,
“I am storing related sample IDs as StringField objects in a separate field on my data and I want to use them to match sample IDs that are stored as ObjectIdField objects. How do I do this?”
If you were comparing the values in two `StringFields`, you could use the ViewField as follows:
import fiftyone as fo
from fiftyone import ViewField as F
dataset = fo.Dataset(..)
dataset.match(F('field_a') == F('field_b'))
However, sample IDs are represented as ObjectIdField objects. They are stored under an _id key in the underlying database, and need to be referenced with this same syntax, prepending an underscore. Additionally, the object needs to be converted to a string for the comparison.
Here is what such a matching operation might look like:
import fiftyone as fo
import fiftyone.zoo as foz
from fiftyone import ViewField as F
dataset = foz.load_zoo_dataset("quickstart")
# Add a `str_id` field that matches `id` on 10 samples
view = dataset.take(10)
view.set_values("str_id", view.values("id"))
matching_view = dataset.match(
F("str_id") == F("_id").to_string()
)
Learn more about fields and filtering in the FiftyOne Docs.
Merging datasets with shared media files
Community Slack member Joy Timmermans asked,
“I have three datasets, and some of my samples are in multiple datasets. I’d like to combine all of these datasets into one dataset for export, retaining each copy of each of the samples. How do I do this?”
If your datasets were created independently, even if there are samples that have the same media files (located at the same file paths), these samples will have different sample IDs. In this case, you can create a combined dataset with the add_collection() method without passing in any optional arguments.
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
ds1 = dataset[:100].clone()
ds2 = dataset[100:].clone()
## create temporary dataset for combining
tmp = ds1.clone()
## add ds2 samples
tmp.add_collection(ds2)
## export
tmp.export(..)
## delete temporary dataset
tmp.delete()
If, on the other hand, your datasets have samples with the same sample IDs, then applying the add_collection() method without options will only lead to the “combined” dataset having a single copy of each media file.
Fortunately, you can bypass this by passing in new_ids = True to add_collection(). In your case, combining three datasets would look like:
import fiftyone as fo import fiftyone.zoo as foz ## start with dataset1, dataset2, dataset3 tmp = dataset1.clone() tmp.add_collection(dataset2, new_ids = True) tmp.add_collection(dataset3, new_ids = True) tmp.export(..) tmp.delete()
Learn more about merging datasets in the FiftyOne Docs.
Exporting GeoJSON annotations
Community Slack member Kais Bedioui asked,
“I am logging some of my production data in GeoJSON format, and I want to save it in the database in that same format. Is there a way to include the ground_truth label in the labels.json file so that when I reload the GeoJSON dataset, it comes with its annotations?”
To do this, you can use the optional property_makers argument of the GeoJSON exporter to include additional properties directly in GeoJSON format. For example:
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart-geo")
dataset.export(
labels_path="/tmp/labels.json",
dataset_type=fo.types.GeoJSONDataset,
property_makers={"ground_truth": lambda d: len(d.detections)},
)
Alternatively, if you want to save the annotations but do not need to save everything in GeoJSON format, you can export it as a FiftyOne Dataset:
import fiftyone as fo
dataset.export(
export_dir="/tmp/all",
dataset_type=fo.types.FiftyOneDataset,
export_media=False,
)
When you take this approach, all you have to do to load the dataset back in is use FiftyOne’s from_dir() method:
import fiftyone as fo
dataset = fo.Dataset.from_dir(
dataset_dir="/tmp/all",
dataset_type=fo.types.FiftyOneDataset,
)
Learn more about from_dir(), and importing and exporting data in the FiftyOne Docs.
Picking random frames from videos
Community Slack member Joy Timmermans asked,
“Is there an equivalent of take() for frames in a video dataset so that I can randomly select a subset of frames for each sample?”
One way to accomplish this would be to use a Python library for random sampling in conjunction with the select_frames() method. First, you can use random sampling without replacement to pick a set of frame numbers for each video. Then, you can get the frame id for each of these frames. Finally, you can pass this list of ids into select_frames().
Here’s one implementation using numpy’s random choice method:
from numpy.random import choice as nrc
import fiftyone as fo
import fiftyone.zoo as foz
from fiftyone import ViewField as F
dataset = foz.load_zoo_dataset("quickstart-video")
## get nested list of frame ids for each sample
frame_ids = dataset.values("frames.id")
## number of frames for each sample
nframes = dataset.values(F("frames").length())
## number of samples in dataset
nsample = len(dataset)
sample_frames = [nrc(nframe, 10, replace=False) for nframe in nframes]
keep_frame_ids = []
for i in range(nsample):
curr_frame_ids = frame_ids[i]
for s in sample_frames[i]:
keep_frame_ids.append(curr_frame_ids[s])
kept_view = dataset.select_frames(keep_frame_ids)
If you’d like, at this point you can also convert the videos to frames:
kept_frames_view = kept_view.to_frames()
Learn more about video views and frame views in the FiftyOne Docs.
Join the FiftyOne community!
Join the thousands of engineers and data scientists already using FiftyOne to solve some of the most challenging problems in computer vision today!
- 1,300+ FiftyOne Slack members
- 2,500+ stars on GitHub
- 3,000+ Meetup members
- Used by 241+ repositories
- 55+ contributors

