Welcome to our weekly FiftyOne tips and tricks blog where we recap interesting questions and answers that have recently popped up on Slack, GitHub, Stack Overflow, and Reddit.
As an open source community, the FiftyOne community is open to all. This means everyone is welcome to ask questions, and everyone is welcome to answer them. Continue reading to see the latest questions asked and answers provided!
Wait, what’s FiftyOne?
FiftyOne is an open source machine learning toolset that enables data science teams to improve the performance of their computer vision models by helping them curate high quality datasets, evaluate models, find mistakes, visualize embeddings, and get to production faster.
- If you like what you see on GitHub, give the project a star.
- Get started! We’ve made it easy to get up and running in a few minutes.
- Join the FiftyOne Slack community, we’re always happy to help.
Ok, let’s dive into this week’s tips and tricks!
Filtering images by type of class
Community Slack member Walter asked:
I want to download images from Open Images V7 and exclude certain images that contain specific types of classes. Is there a way to do this?
Yes! Here’s a programmatic example that only includes samples whose ground truth label is “slug” or “conch.”
import fiftyone as fo
import fiftyone.zoo as foz
from fiftyone import ViewField as F
dataset = foz.load_zoo_dataset("imagenet-sample")
# Only include samples whose ground truth `label` is "slug" or "conch"
slug_conch_view = dataset.filter_labels(
"ground_truth", (F("label") == "slug") | (F("label") == "conch")
)
session = fo.launch_app(view=slug_conch_view)
You can find examples of common filters in the Filtering section of the Docs. Note that you can also filter samples in the FiftyOne App using the sidebar.
Finally, to make the Open Images download and import more manageable, it doesn’t hurt to mention that FiftyOne provides parameters that can be used to download specific subsets of the dataset to suit your needs. Check out the Open Images V7 section in the Docs for more details.
Computing and finding mistakes
Community Slack member Victoria asked:
Can I apply the
compute mistakesmethod to primitives? For example, if I have an image with ground truth labels for weather conditions (like SUNNY, CLOUDY, etc.) and predictions from a model, along with confidence scores, can I use the ‘mistakenness’ method to spot potential errors in my setup?
Yes! compute_mistakenness() supports Classification labels so this should work for you. Here’s how it works:
compute_mistakenness() computes the likelihood that the ground truth labels in label_field are incorrect based on the predicted labels in pred_field.
Mistakenness is measured by either the confidence or logits of the predictions in pred_field. This measure can be used to detect things like annotation errors and unusually hard samples.
For classifications, a mistakenness_field is populated on each sample that quantifies the likelihood that the label in the label_field of that sample is incorrect.
For objects (detections, polylines, keypoints, etc), the mistakenness of each object in label_field is computed, using fiftyone.core.collections.SampleCollection.evaluate_detections() to locate corresponding objects in pred_field. The three types of mistakes are identified as mistakes, missing, and spurious. Check out the “Finding detection mistakes” tutorial for more details.
Grouping samples into a video
Community Slack member Nadu asked:
I have 800 samples loaded into my FiftyOne session. Is it possible to create a video of these 800 samples?
If the samples are ordered, you can group by a specified field and order them by another field, creating a video out of frames. You can use the group action in the App’s menu to dynamically group your samples by a field of your choice:
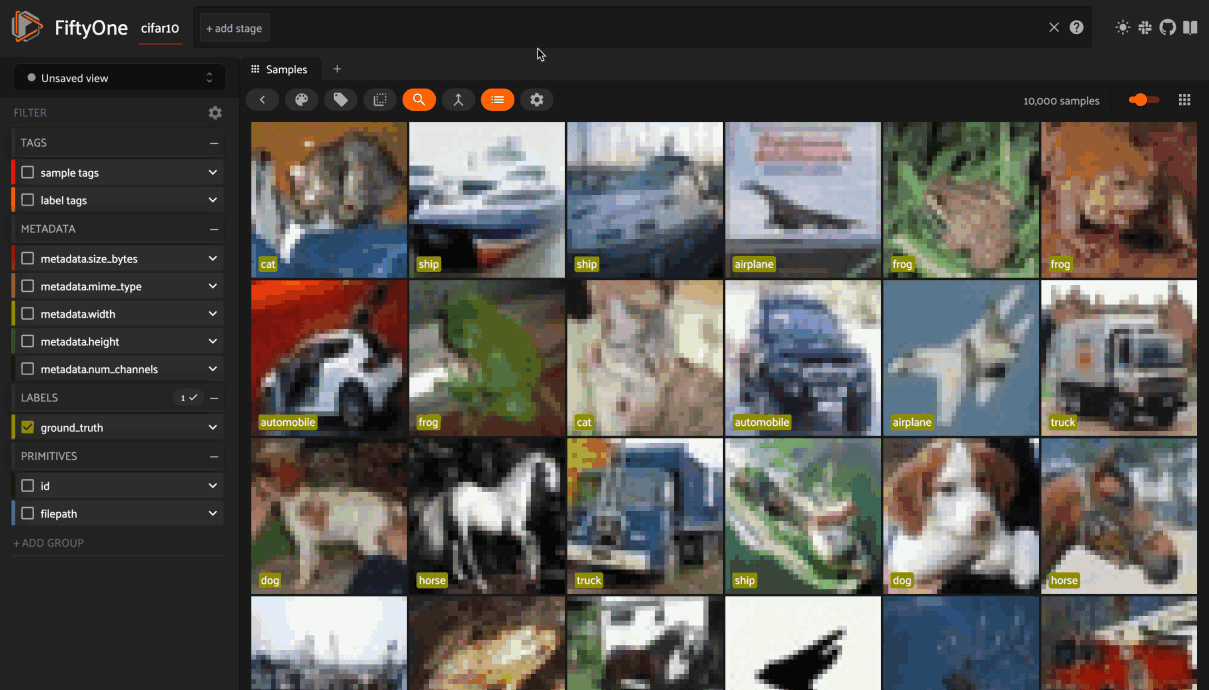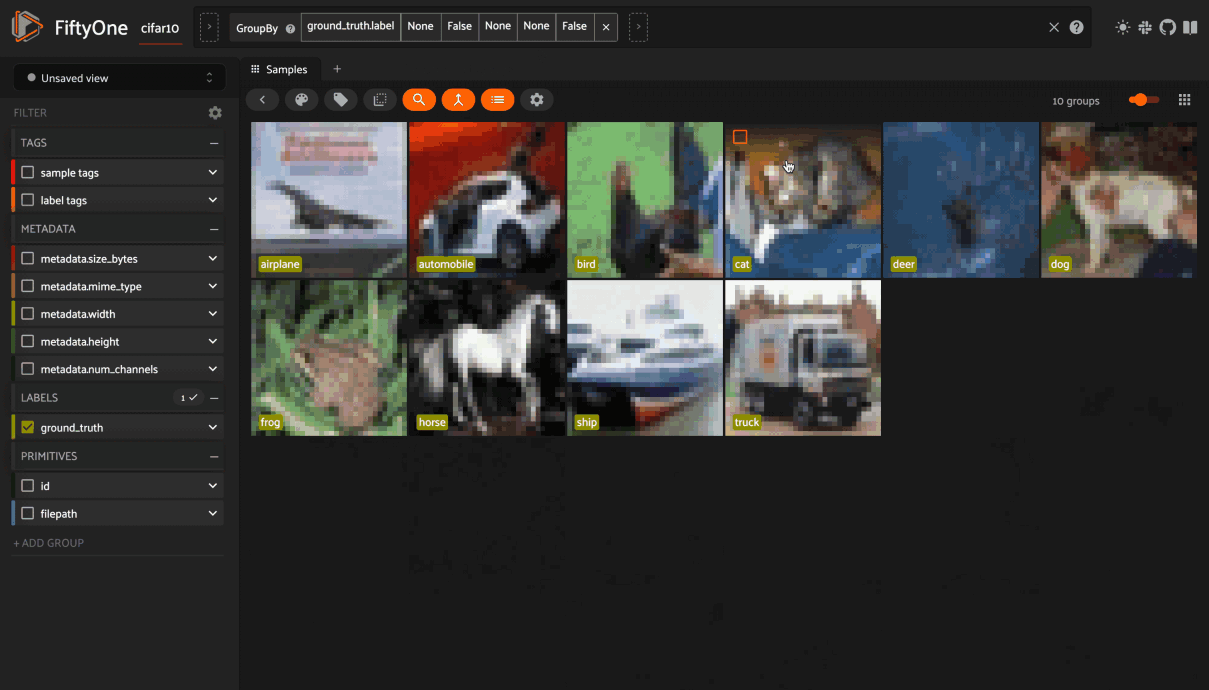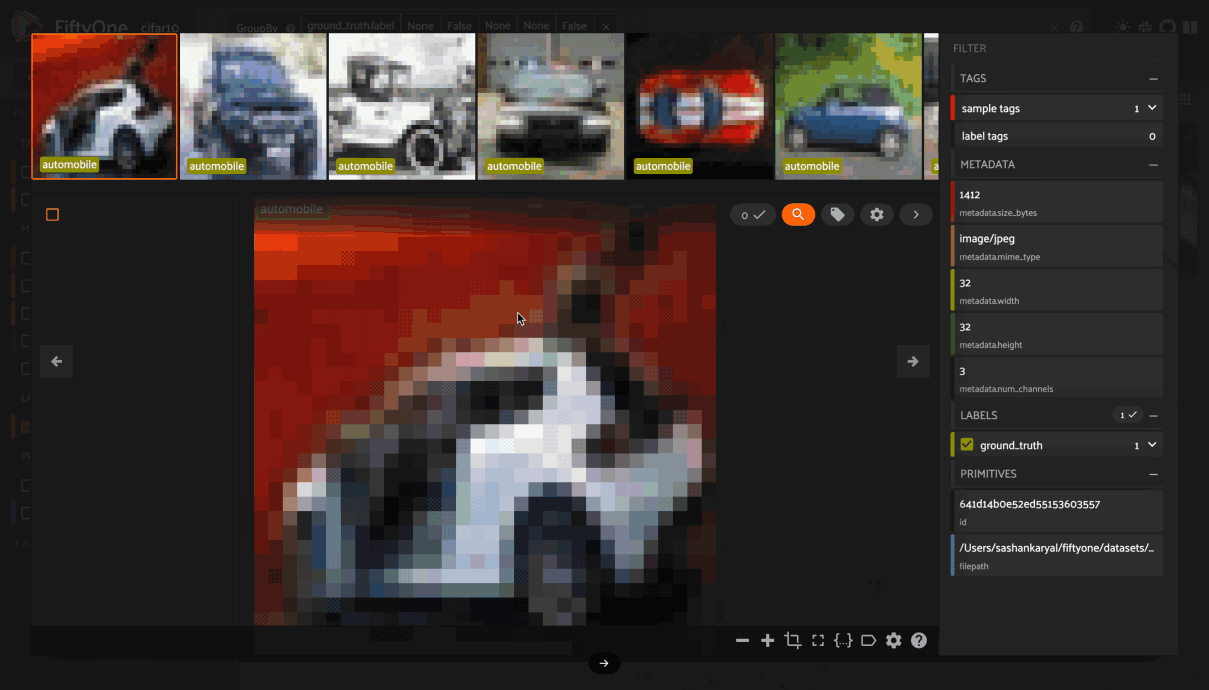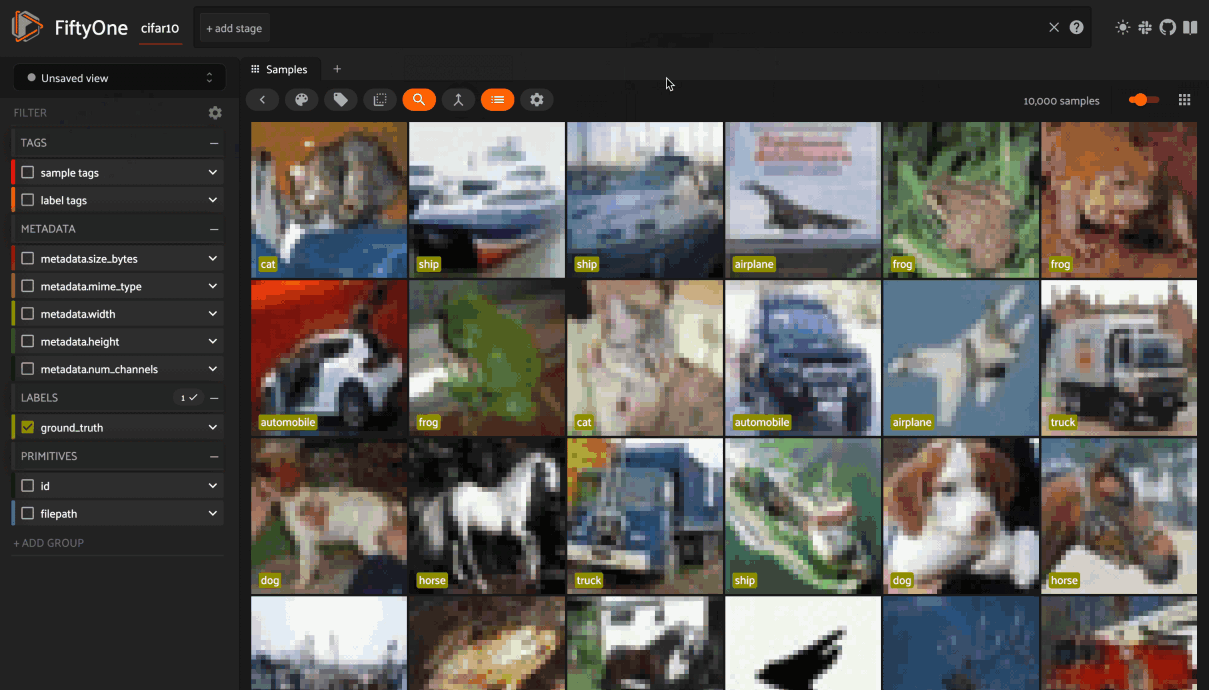
In this mode, the App’s grid shows the first sample from each group, and you can click on a sample to view all elements of the group in the modal. You can then navigate through the elements of the group either sequentially using the carousel, or randomly using the pagination UI at the bottom of the modal.
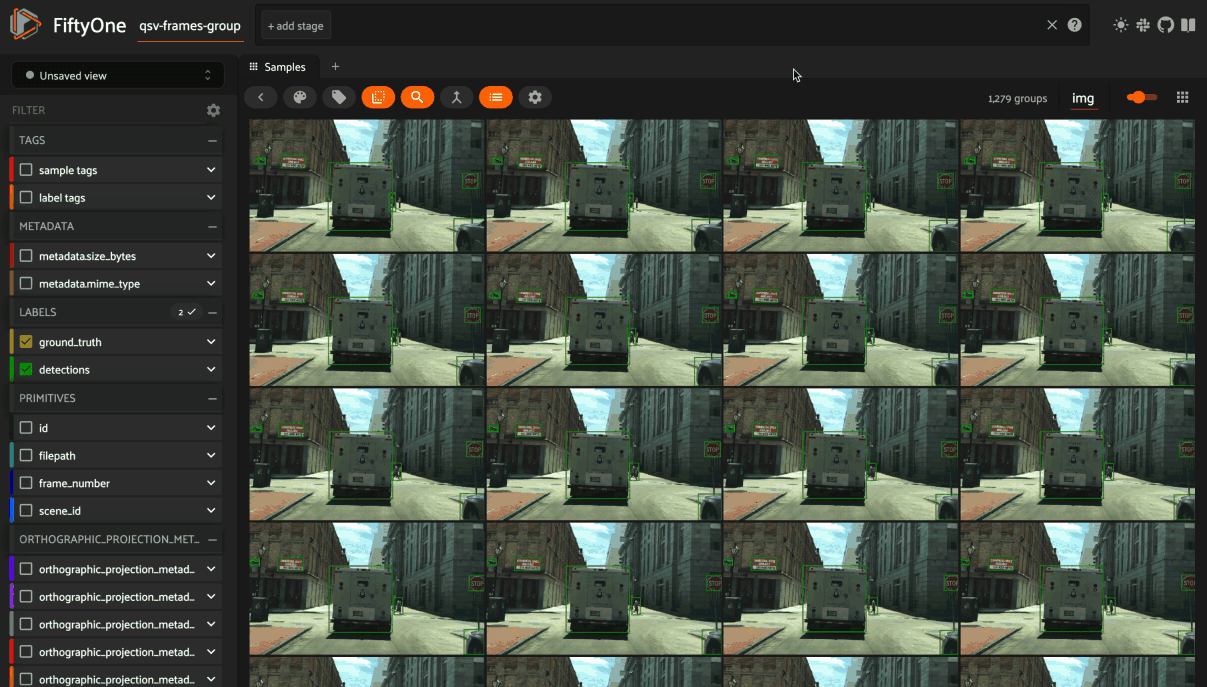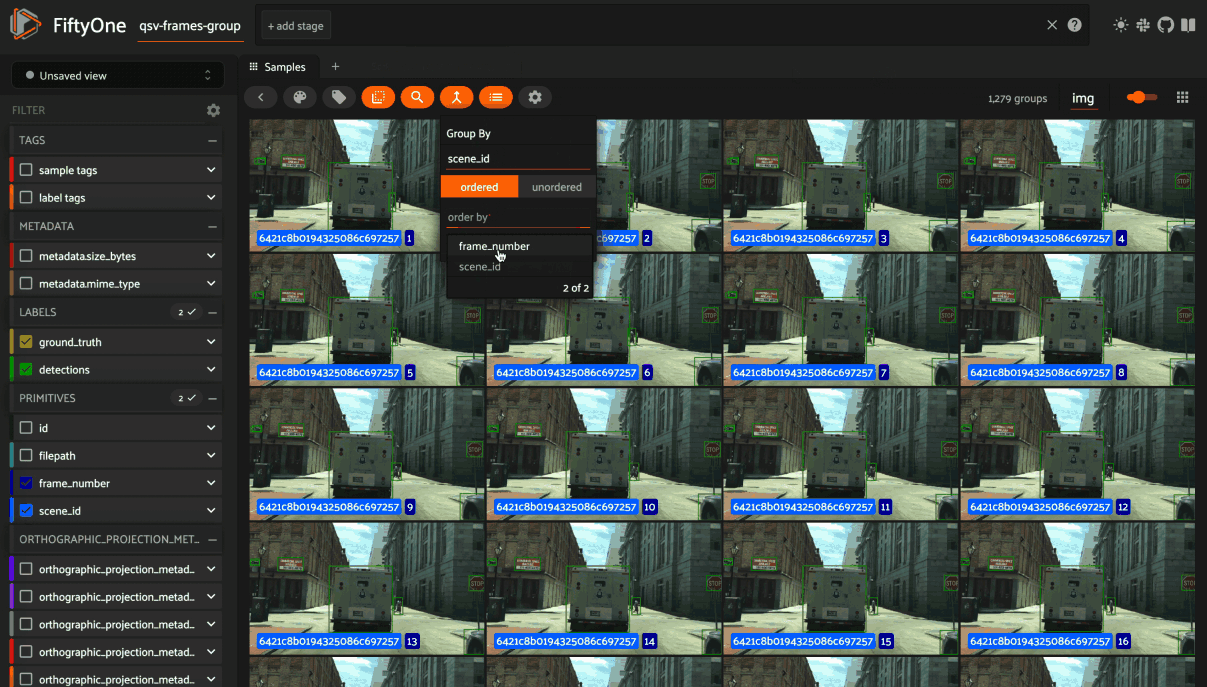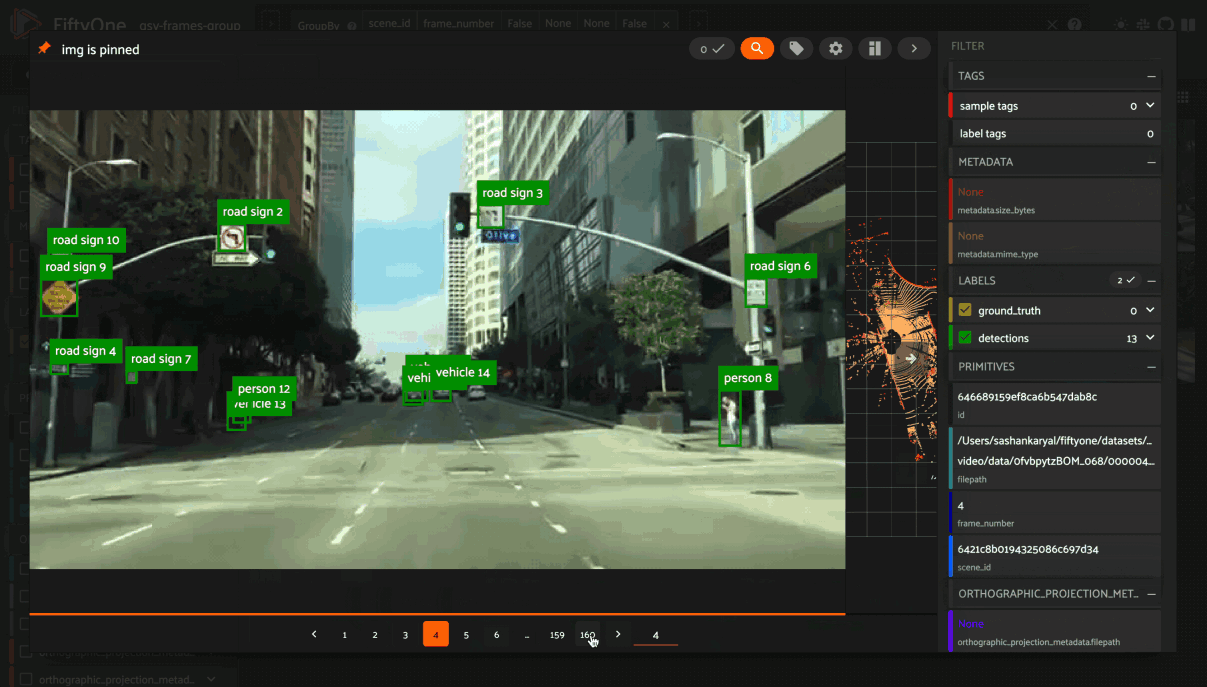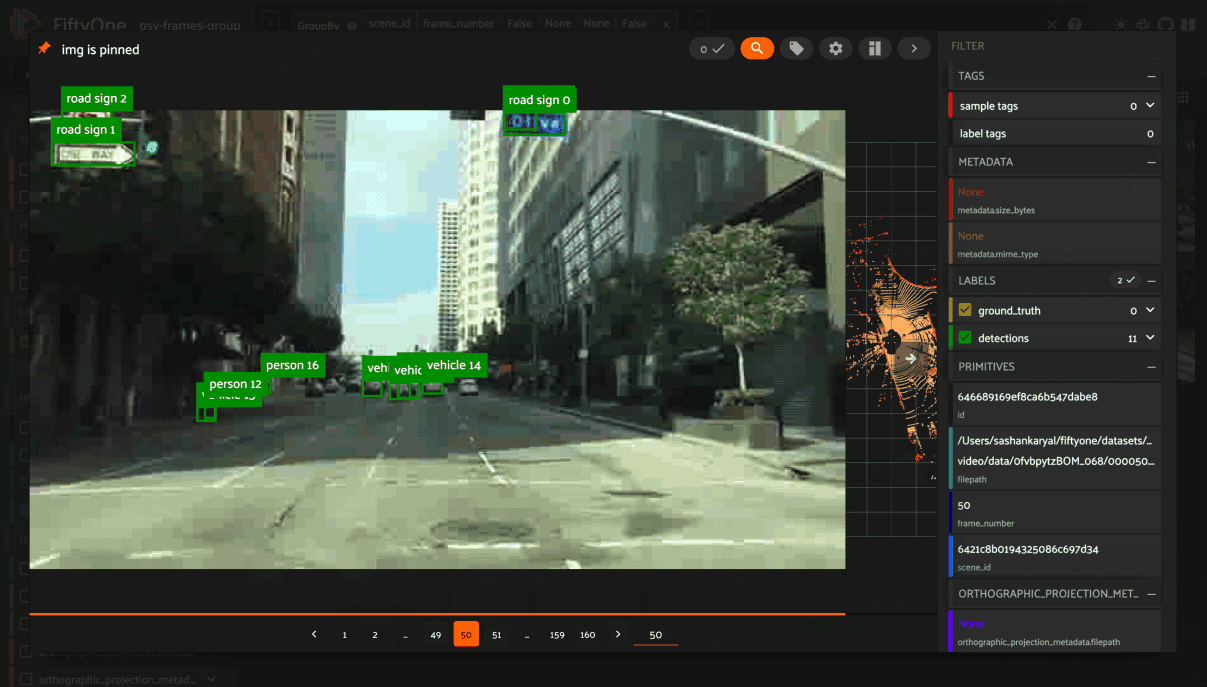
When viewing ordered groups, you have an additional option to render the elements of the group as a video.
Learn more about Grouping functionality in the Docs.
Integrating FiftyOne with CVAT and Label Studio
Community Slack member Dom asked:
Is there a way to pass existing labels in my dataset view to Label Studio or CVAT? In some cases I have missed annotations on images, so it would save my team time if they can see what has already been labeled.
Yes! If you are using dataset.annotate() just pass a parameter with the label field name that contains your label’s dataset.annotate(..., label_field=<my_existing_labels_field>))
Learn more about FiftyOne’s native integration with Label Studio and CVAT in the Docs.
Sorting detection patches by confidence
Community Slack member Danish asked:
I need some help with ‘sort_by’. I’d like to get my patches sorted by confidence, vs a random ordering which I am getting when I use the code below:
# model_a_name: yolo # model_a_eval_name: eval_yolo # A_TP view valid_patch = vfo_dataset.to_evaluation_patches(f"{model_a_eval_name}") valid_view = ( valid_patch.filter_labels( f"{model_a_name}", F("confidence") > 0.05, only_matches=True ) .filter_labels( f"{model_a_name}", F(f"{model_a_eval_name}") == "tp", only_matches=True ) .sort_by( F(f"{model_a_name}.confidence"), reverse=True ) # reverse means descending ) vfo_dataset.save_view("test_A_TP", valid_view)
Try using predictions.detections.confidence and you should get the results in the order you are looking for.
from fiftyone import ViewField as F
valid_patch = quick.to_evaluation_patches("eval")
valid_view = (
valid_patch.filter_labels(
"predictions", F("confidence") > 0.05, only_matches=True
)
.filter_labels(
"predictions", F("eval") == "tp", only_matches=True
)
.sort_by(
F(f"predictions.detections.confidence"), reverse=True
) # reverse means descending
)
Don’t forget you can always print out your dataset or sample to see its schema and understand how you can slice, filter or sort your datasets!
print(dataset) # print dataset schema sample = dataset.first() print(sample) # print sample schema

