The Conference on Computer Vision and Pattern Recognition (CVPR) is the premier annual event for presenting and discussing the latest research on computer vision and pattern recognition.
It’s held every June in North America and brings together top academics and industry researchers to share cutting-edge work on object recognition, image segmentation, 3D reconstruction, and deep learning. Due to its high quality, low cost, and selectivity, CVPR is undoubtedly the flagship conference for computer vision.
But computer vision isn’t just limited to images. Combining vision and language has a long history at CVPR.
From pioneering work predating the deep learning revolution with the 2006 paper Using Language to Drive the Perceptual Grouping of Local Image Features and 2010’s Multimodal Semi-Supervised Learning for Image Classification. To a time before Transformers with the widely cited 2016 paper Deep Compositional Question Answering with Neural Module Networks, which, at the time, redefined the state-of-the-art for visual question answering. And, more recently, methods using Transformers like 2021’s VinVL: Revisiting Visual Representations in Vision-Language Models.
The research presented in 2024’s CVPR builds upon this rich heritage, showcasing what’s possible at the intersection of computer vision and natural language processing.
Below are, in no particular order, five papers from CVPR 2024 that I feel are set to redefine the intersection of computer vision and natural language processing. I’ll use the PACES method to summarize each paper:
- Identify the Problem
- Describe the Approach
- State the Claim made in the paper
- How is the problem Evaluated?
- Does the Substantiate the Claim?
Let’s run these papers through the paces!
Describing Differences in Image Sets with Natural Language
Links:
Authors: Lisa Dunlap, Yuhui Zhang, Xiaohan Wang, Ruiqi Zhong, Trevor Darrell†, Jacob Steinhardt†, Joseph E. Gonzalez†, Serena Yeung-Levy
Affiliations: UC Berkeley and Stanford

Problem: We’ve all faced the tedious and impractical task of sifting through thousands of images to find their differences. However, with VisDiff, this task becomes efficient and manageable, crucial for understanding model behaviours, analyzing datasets, and uncovering nuanced insights across various domains.
Approach: VisDiff uses a two-stage methodology to describe differences between two image sets in natural language automatically. First, it generates captions for images and proposes candidate descriptions using a language model (the authors use GPT-4 on BLIP-2 generated caption). Then, it re-ranks these candidates using the CLIP model, focusing on those accurately differentiating the two sets.
Claim: VisDiff effectively identifies and articulates the differences between image sets using natural language, facilitating the discovery of significant and previously unknown datasets and model differences.
Evaluation: The authors created VisDiffBench, a benchmark of 187 paired image sets with ground-truth descriptions, demonstrating the tool’s effectiveness in revealing insightful differences. The tool’s application across various domains—like dataset comparisons and generative model characterizations—highlights its ability to reveal insights.
Substantiation: The results from applying VisDiff, corroborated by the VisDiffBench dataset, confirm its capacity to generate insightful and accurate descriptions of differences between image sets, validating the tool’s significant contribution to computer vision and natural language processing.
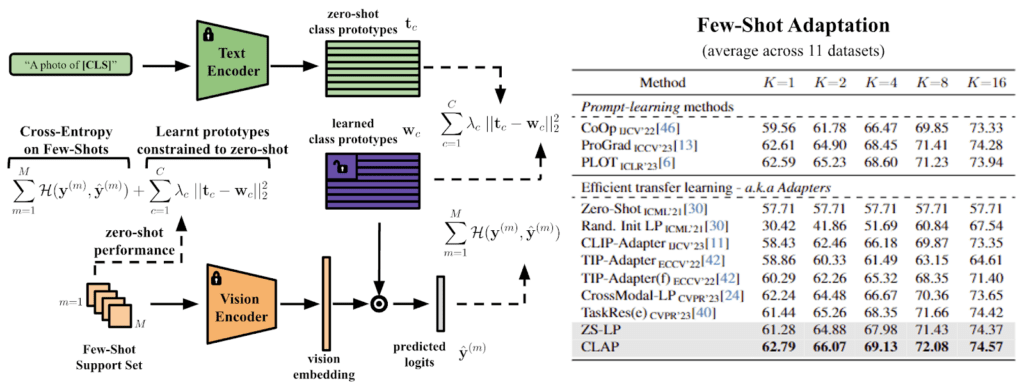
A Closer Look at the Few-Shot Adaptation of Large Vision-Language Models
Links:
Authors: Julio Silva-Rodríguez · Sina Hajimiri · Ismail Ben Ayed · Jose Dolz
Affiliation: ETS Montreal
Problem: Adapting large pre-trained language-vision models to downstream tasks using only a few labelled samples is challenging and time-consuming. Especially because of the need for extensive hyperparameter tuning and the models’ tendency to underperform in the face of distributional drifts. This issue becomes even more problematic when attempting to outperform simpler baselines or adapt to new tasks without a sufficiently labelled dataset.
Approach: The authors have proposed a new method called CLAP, which stands for CLass-Adaptive linear Probe. This method introduces an optimized balancing term by adapting the general Augmented Lagrangian method (which, honestly, I have no clue what that means). The main thing CLAP does is efficiently adapt large vision-language models to new tasks using only a few labelled samples. Now, you don’t need endless hyperparameter tuning, huge validation sets, and expensive GPU bills to achieve state-of-the-art!
Claim: CLAP consistently outperforms state-of-the-art efficient transfer learning approaches across many datasets and scenarios, offering a more efficient and realistic solution for few-shot adaptation of large vision-language models.
Evaluation: CLAP’s evaluation covers a wide range of datasets and scenarios, demonstrating its superior performance compared to current state-of-the-art methods. This comprehensive evaluation highlights CLAP’s efficiency and effectiveness in real-world settings, where access to large, labelled datasets and the ability for extensive hyperparameter tuning is limited.
Substantiation: The empirical results confirm that CLAP outperforms simpler baselines and state-of-the-art methods while effectively addressing the challenges of adapting to new tasks in the presence of distributional drifts. The evidence demonstrates CLAP’s utility in providing a practical and efficient solution for the few-shot adaptation of large vision-language models.
Let’s Think Outside the Box: Exploring Leap-of-Thought in Large Language Models with Creative Humor Generation

Links:
Authors: Shanshan Zhong, Zhongzhan Huang, Shanghua Gao, Wushao Wen, Liang Lin, Marinka Zitnik, Pan Zhou
Affiliation: Sea AI Lab, Sun Yat-sen University, Harvard University
Problem: Current large language models (LLMs) can execute step-by-step logical reasoning, yet they often need more creative problem-solving, which is essential for innovative advancements and requires out-of-the-box thought processes.
Approach: The paper introduces the Creative Leap-of-Thought (CLoT) paradigm to enhance LLMs’ Leap-of-Thought (LoT) abilities. CLoT involves instruction tuning with the multimodal and multilingual Oogiri-GO dataset to foster LoT humour generation and discrimination. It further employs self-refinement, prompting the LLM to explore parallels between unrelated concepts, thus generating and training high-quality creative data.
Claim: CLoT improves an LLM’s ability to generate creative and humorous responses in the Oogiri game, a form of comedy that focuses on improvisation by providing a funny answer on the spot for a question or thematic topic. The claim is that this is an ideal platform for exploring an LLM’s LoT ability to think outside the box and provide unexpected and humorous responses to multimodal information, demonstrating out-of-the-box thinking across various creative tasks.
Evaluation: The Oogiri-GO dataset, with over 130,000 samples, is used to evaluate and demonstrate the insufficiencies of existing LLMs and the improvements achieved with CLoT. CLoT’s performance is showcased in tasks such as the Oogiri game, cloud guessing game, and divergent association task, highlighting its capacity to generate high-quality humour.
Substantiation: The advancements shown by the CLoT-integrated LLMs in producing high-quality humour and creative responses substantiate the claim that CLoT significantly boosts an LLM’s creative abilities, providing a new avenue to enhance innovative applications in diverse domains.
Alpha-CLIP: A CLIP Model Focusing on Wherever You Want

Links:
Authors: Zeyi Sun, Ye Fang, Tong Wu, Pan Zhang, Yuhang Zang, Shu Kong, Yuanjun Xiong, Dahua Lin, Jiaqi Wang
Affiliation: Shanghai Jiao Tong University, Fudan University, The Chinese University of Hong Kong, Shanghai AI Laboratory, University of Macau, MThreads, Inc.
Problem: When we need to understand or edit just a part of an image, it’s tough for current image recognition systems to focus on that area—they tend to look at everything, important or not. While CLIP captures the content of the entire image, sometimes you want to focus on a region\ of interest for a finer understanding and controllable content generation.
Approach: Alpha-CLIP is a more advanced version of the CLIP model that improves its visual recognition ability while providing better control over the focus on image contents. It adds an alpha channel layer to the existing image and text matching system, which guides the system to focus on specific spots without losing sight of the whole picture. This method extends CLIP to focus on specific regions via an alpha mask, leading to higher performance. By learning from numerous examples, Alpha-CLIP is highly effective in identifying and highlighting important features of an image.
Claim: Alpha-CLIP maintains the original CLIP model’s visual recognition ability while providing precise control over the focus on image contents, resulting in superior performance across various tasks.
Evaluation: Alpha-CLIP was assessed across diverse tasks, including open-world recognition and multimodal large language model applications. The model was also evaluated on text-and-image tasks like captioning and question-answering, where it reduced mistakes and biases. For image generation, it gave more control to create variations and extract main subjects from complex backgrounds.
Substantiation: The reported evaluation results affirm that Alpha-CLIP successfully directs attention to specific regions without losing the general context, validating the claim that integrating an alpha channel can enhance region-focused visual understanding in machine vision models. Alpha-CLIP showed better accuracy in identifying parts of images, beating the original CLIP by 4.1% on the ImageNet test. Across different tasks, it proved to be a more focused and flexible tool than its predecessor. Alpha-CLIP demonstrated it can pinpoint and emphasize important image areas without losing the big picture.
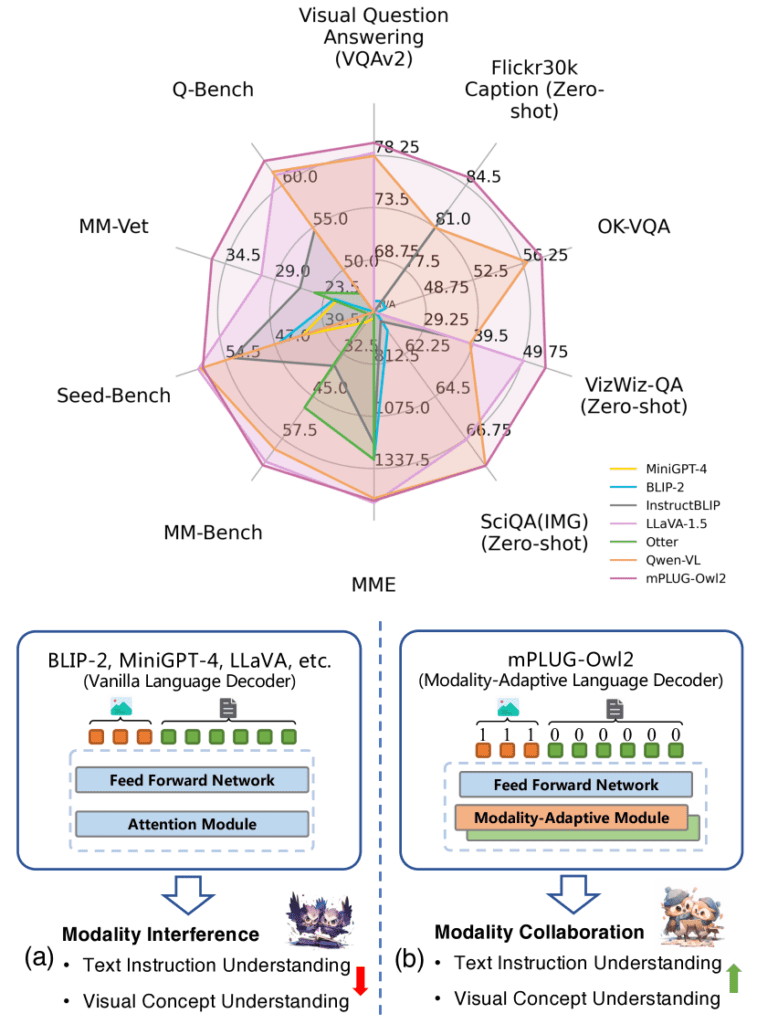
mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration
Links:
Authors: Qinghao Ye, Haiyang Xu, Jiabo Ye, Ming Yan, Anwen Hu, Haowei Liu, Qi Qian, Ji Zhang, Fei Huang, Jingren Zhou
Affiliation: Alibaba Group
Problem: The paper addresses integrating different modalities—like visual and textual content—within a single multimodal large Language Model (MLLM). The goal is to enhance performance in text and multimodal tasks without task-specific fine-tuning.
Approach: mPLUG-Owl2 has a modularized network design with shared functional modules to promote modality collaboration. It also presents a modality-adaptive module to preserve modality-specific features, allowing the model to capture low-level and high-level semantic visual information effectively.
Claim: mPLUG-Owl2 is the first MLLM model that showcases modality collaboration in pure-text and multimodal scenarios, improving performance across various tasks using a single generic model.
Evaluation: mPLUG-Owl2 is evaluated across eight classic vision-language benchmarks and five recent zero-shot multimodal benchmarks, demonstrating its adaptability and proficiency in multimodal instruction comprehension and generation. The model is shown to achieve state-of-the-art results on multiple pure-text benchmarks as well.
Substantiation: The evaluation results substantiate the claim that mPLUG-Owl2 can enhance multimodal and language-only performance through modality collaboration, as evidenced by its state-of-the-art performances on various benchmarks with a single unified model.
The deep learning community’s commitment to open science is truly remarkable.
The openness in deep learning strikes a perfect balance between serious science and accessible fun. It’s pretty awesome that all these models we’ve been discussing come with everything you need to dive in – from the actual model weights to the datasets they were trained on. It’s like being invited to read about the magic and try your hand at it, too, whether to double-check the results, satisfy your curiosity, or just to see how it all works.
We’re living through an exciting chapter in tech, with breakthroughs and innovations appearing faster than ever before. It can be a lot to keep up with, but that’s where summaries like mine come in – they’re here to give you a quick taste of the latest and greatest.
I’m pumped to get my hands dirty with these models, and I’ll share what I discover along the way.
Visit Voxel51 at CVPR 2024!
Visit us at booth #1519 at CVPR 2024! We’d love to meet you, discuss computer vision and NLP, and send you home with some of the most coveted swag at the event.


