In part one of this series, I explored some interesting datasets presented at CVPR 2024, highlighting how they’ll help advance computer vision and deep learning.
Now, it’s time to turn our attention to the other side of the coin: benchmarks.
Just as musicians need stages to showcase their talent, deep learning models need benchmarks to demonstrate their capabilities and push the boundaries of what’s possible. These standardized tasks and challenges provide a crucial yardstick for evaluating and comparing different models, driving healthy competition and accelerating progress.
CVPR 2024 has once again delivered a collection of innovative benchmarks that address existing limitations and explore new frontiers in computer vision.
In this second part of the series, I’ll highlight three benchmarks I found interesting:
- ImageNet-D: Testing the robustness of image classifiers against real-world perturbations.
- Polaris: Assessing the ability of vision-language models to follow natural language instructions in interactive environments.
- VBench: Comprehensive Benchmark Suite for Video Generative Models
Each of these benchmarks presents unique challenges and opportunities for researchers, pushing the field towards more robust models. In the following sections, I’ll focus on the following aspects of each dataset:
Task and Objective: Clearly define the specific task or problem the benchmark evaluates.
Dataset and Evaluation Metric: Provide details about the benchmark, including its size, composition, and the evaluation metrics employed to measure model performance.
Benchmark Design and Protocol: Explain the benchmark’s design and protocol, including how the dataset is split into training, validation, and test sets.
Comparison to Existing Benchmarks: Compare the new benchmark to existing ones in the same domain, highlighting its unique challenges, evaluation criteria, and/or how the benchmark complements or improves upon existing benchmarks.
State-of-the-Art Results: Showcase the leaderboard on the benchmark, if it exists, and what the top-performing models are. If available, discuss the model’s key architectural features or training strategies.
Impact and Future Directions: Discuss the benchmark’s potential impact, how it can drive research in new directions, and address important challenges in existing benchmarks.
ImageNet-D

tl;dr
- Task: Object recognition on synthetic images
- Metric: Top-1 Accuracy
- Paper
- GitHub
- Dataset on Hugging Face
Task and Domain
The ImageNet-D benchmark evaluates the robustness of neural networks in object recognition tasks using synthetic images generated by diffusion models.
- It assesses the performance of various vision models, ranging from standard visual classifiers to foundation models like CLIP and MiniGPT-4.
- The primary objective is to rigorously test the robustness of these models in correctly identifying objects under challenging conditions.
- The benchmark focuses explicitly on “hard” images designed to test the models’ perception abilities.
- Using synthetic images generated by diffusion models, ImageNet-D provides a rigorous evaluation of how well neural networks can handle variations in object representation.
Dataset Curation, Size, and Composition
The synthetic images were generated using Stable Diffusion models steered by language prompts. They tested the robustness of visual recognition systems by using diverse backgrounds, textures, and materials to challenge the models’ perception capabilities.
- It comprises 4,835 challenging images across 113 overlapping categories between ImageNet and ObjectNet.
- The images feature a diverse array of backgrounds (3,764), textures (498), and materials (573) to push the limits of object recognition models.
- The dataset is generated by pairing each object with 547 nuisance candidates from the Broden dataset, resulting in various realistic and challenging synthetic images.
- The primary evaluation metric is top-1 accuracy in object recognition, which measures the proportion of correctly classified images.
- Compared to standard datasets, ImageNet-D proves to be significantly more challenging, as evidenced by the notable drop in accuracy percentages for various state-of-the-art models.
Benchmark Design and Protocol
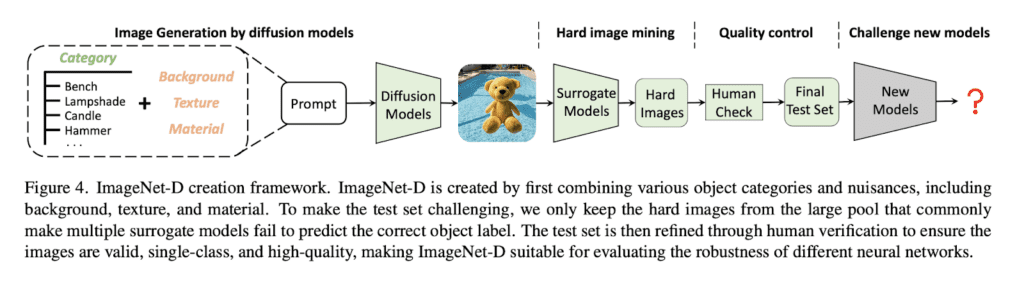
The benchmark’s construction follows a rigorous process that involves image generation, labeling, hard image mining, human verification, and quality control:
- The image generation process is formulated as Image(C, N) = Stable Diffusion(Prompt(C, N)), where C and N refer to the object category and nuisance, respectively.
- The nuisance N includes background, material, and texture.
- For example, images of backpacks with various backgrounds, materials, and textures are generated, offering a broader range of combinations than existing test sets.
- Each generated image is labeled with its prompt category C as the ground truth for classification.
- An image is misclassified if the model’s predicted label does not match the ground truth C.
- After creating a large image pool with all object categories and nuisance pairs, the CLIP (ViT-L/14) model is evaluated on these images.
- Hard images are selected based on shared perception failure, defined as an image that leads multiple models to predict the object’s label incorrectly. The test set is constructed using shared failures of known surrogate models.
- The test set is challenging if these failures lead to low accuracy in unknown models. This property is called transferable failure.
- Human Labeling: Since ImageNet-D includes images with diverse object and nuisance pairs that may be rare in the real world, human labeling is performed using Amazon Mechanical Turk (MTurk). Workers are asked to answer two questions for each image:
- Can you recognize the desired object ([ground truth category]) in the image?
- Can the object in the image be used as the desired object ([ground truth category])?
- To ensure workers understand the labeling criteria, they are asked to label two example images for practice, providing the correct answers. After the practice session, workers must label up to 20 images in one task, answering both questions for each image by selecting ‘yes’ or ‘no’.
- Sentinels ensure high-quality annotations. Workers’ annotations are removed if they fail to select the correct answers for positive sentinels, select ‘yes’ for negative sentinels, or provide inconsistent answers for consistent sentinels.
- Positive sentinels are images that belong to the desired category and are correctly classified by multiple models.
- Negative sentinels are images that do not belong to the desired category.
- Consistent sentinels are images that appear twice in a random order.
Comparison to Existing Benchmarks
The big difference with ImageNet-D is that it creates entirely new. synthetic images. Here’s how it’s different from existing benchmarks that try to do the same thing:
- Unlike ObjectNet, which collects real-world object images with controlled factors like background, or ImageNet-C, which introduces low-level visual corruptions, ImageNet-D generates entirely new images with diverse backgrounds, textures, and materials.
- While ImageNet-9 combines foreground and background from different images, it is limited by poor image fidelity. Similarly, Stylized-ImageNet alters the textures of ImageNet images but cannot control global factors like backgrounds. In contrast, ImageNet-D allows for specific control over the image space, which is crucial for robustness benchmarks.
- Compared to DREAM-OOD, which finds outliers by decoding sampled latent embeddings to images but lacks control over the image space, ImageNet-D focuses on hard images with a single attribute.
- By generating new images and mining the most challenging ones as the test set, ImageNet-D achieves a greater accuracy drop compared to methods that modify existing datasets. The results show that ImageNet-D causes a significant accuracy drop, up to 60%, in a range of vision models, from standard visual classifiers to the latest foundation models like CLIP and MiniGPT-4.
- The approach utilized in ImageNet-D demonstrates the potential for using generative models to evaluate model robustness, and its effectiveness is expected to grow further with advancements in generative models.
State-of-the-Art Results
ImageNet-D is a challenging benchmark for various state-of-the-art models, causing significant drops in their object recognition accuracy. Here are some key findings:
- CLIP experiences a substantial accuracy reduction of 46.05% on ImageNet-D compared to its performance on ImageNet.
- LLaVa’s accuracy drops by 29.67% when evaluated on the ImageNet-D benchmark.
- Despite being a more recent model, MiniGPT -4 still has a 16.81% decrease in accuracy on ImageNet-D.
- All tested models show an accuracy drop of more than 16% on ImageNet-D compared to their performance on the standard ImageNet dataset.
- Even the latest models, such as LLaVa-1.5 and LLaVa-NeXT, are not immune to the challenges posed by ImageNet-D, experiencing significant accuracy drops.
Impact and Future Directions
ImageNet-D demonstrates the effectiveness of using generative models to evaluate the robustness of neural networks. The authors suggest that their approach is general and has the potential for greater effectiveness as generative models improve. They aim to create more diverse and challenging test images in the future by capitalizing on advancements in generative models.
Polaris
tl;dr
- Task: Image Captioning
- Metric: Polos, based on the novel Multimodal Metric Learning from Human Feedback (M²LHF) framework
- Project Page
- Paper
- GitHub
- Dataset on Hugging Face
This paper was interesting because it introduces Polaris, a new large-scale benchmark dataset for evaluating image captioning models, and Polos, a state-of-the-art (SOTA) metric trained on this dataset.
Let’s quickly discuss the concepts of benchmarks and metrics.
A benchmark is a standardized dataset or suite of datasets used to evaluate and compare the performance of different models or algorithms on a specific task. In image captioning, a benchmark typically consists of images, associated human-written captions, and human judgments of caption quality for a subset of the data. The benchmark provides a common ground for comparing different captioning models or evaluation metrics.
A metric, on the other hand, is a method or function used to measure a model’s performance on a specific task. In image captioning, a metric takes an image, a candidate caption, and possibly one or more reference captions as input. It outputs a score indicating the quality of the candidate caption. The metric’s performance is evaluated by measuring how well its scores correlate with human judgments on a benchmark dataset.
Task and Objective
Automatic evaluation of image captioning models is essential for accelerating progress in image captioning, as it enables researchers to quickly and objectively compare different models and architectures without the need for time-consuming and expensive human evaluations.
This research aims to create an effective evaluation metric, Polos, designed explicitly for image captioning models, that closely mirrors human judgment of image caption quality. The main goal is the development of a metric that closely aligns with human judgments of caption quality, fluency, relevance, and descriptiveness.
This paper closely intertwines the development of the Polos metric and the Polaris benchmark dataset. The authors introduce the Multimodal Metric Learning from Human Feedback (M²LHF) framework, which is used to develop the Polos metric.
Dataset and Evaluation Metric
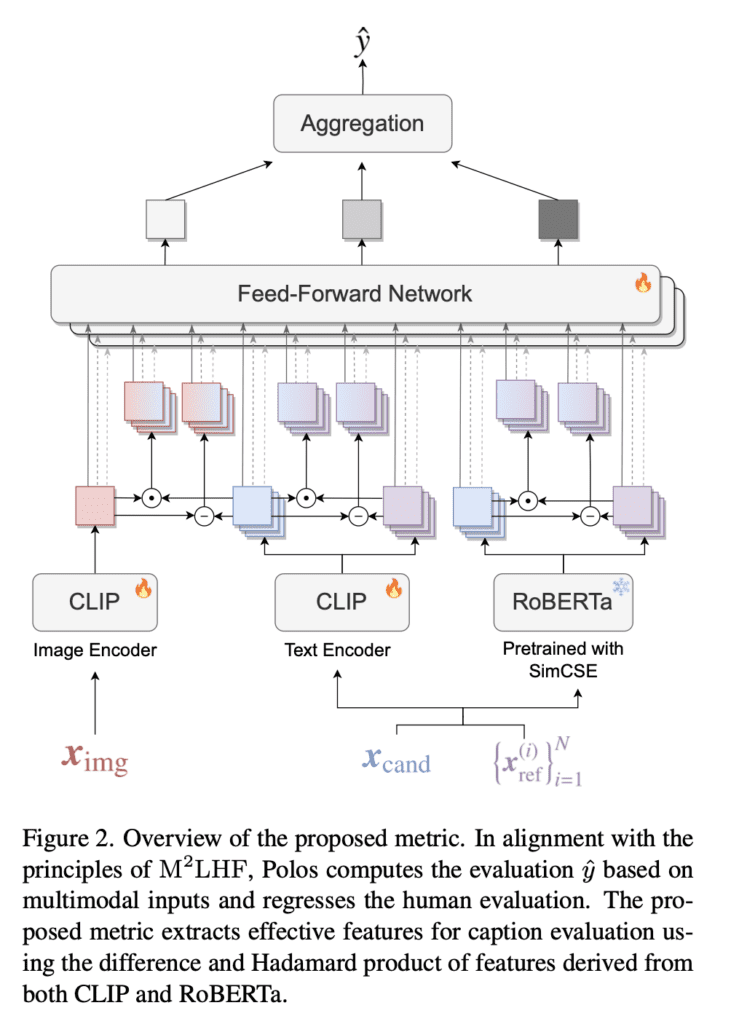
Evaluating image captioning models accurately requires metrics that align with human judgment.
However, existing datasets often lack the scale and diversity needed to train such metrics effectively. This paper addresses this challenge by introducing the Polaris dataset and the Polos evaluation metric.
Dataset
- The Polaris dataset includes 13,691 images and 131,020 generated captions from 10 diverse image captioning models, providing a wide range of caption quality and style. The images used in Polaris are drawn from the MS-COCO and nocaps datasets, chosen for their widespread use in image captioning tasks and their diverse range of image content Additionally, it contains 262,040 human-written reference captions, which serve as a gold standard for comparison.
- The Polaris dataset is split into training (78,631 samples), validation (26,269 samples), and test sets (26,123 samples).
- The generated captions in the Polaris dataset encompass 3,154 unique words, totalling 1,177,512 words. On average, each generated caption is composed of 8.99 words.
- The reference captions have a vocabulary of 22,275 unique words and a word count of 8,309,300. On average, each reference caption consists of 10.7 words.
- The authors collected 131,020 human judgments from 550 evaluators on the image-caption pairs in the Polaris dataset to obtain a comprehensive assessment of caption quality.
- Human evaluators rated each caption on a 5-point scale, considering factors such as fluency, image relevance, and detail level. These ratings were then normalized to a range of [0, 1] to facilitate comparison and evaluation.
Metric
- Polos uses a parallel feature extraction mechanism that combines features from the CLIP model, which captures image-text similarity, and a RoBERTa model pretrained with SimCSE, which provides high-quality textual representations.
- The extracted features are then passed through a multilayer perceptron (MLP) to predict the human evaluation score.
- The primary objective of the Polos metric is to achieve a high correlation with human judgments, demonstrating its ability to assess caption quality accurately.
- The effectiveness of Polos is quantified using Kendall’s Tau correlation coefficients, specifically Tau-b for the Flickr8K-CF dataset and Tau-c for other datasets. These coefficients measure the alignment between the rankings produced by the Polos metric and those derived from human judgments, with a higher correlation indicating better performance.
- The authors also introduce the Multimodal Metric Learning from Human Feedback (M²LHF) framework, a general approach for developing metrics that learn from human judgments on multimodal inputs.
Benchmark Design and Protocol
- Each caption in Polaris received an average of eight judgments from different evaluators. This novel approach aims to closely mimic human judgment by considering various aspects of caption quality, providing a more comprehensive and reliable assessment of caption quality compared to datasets with fewer judgments per caption.
- Evaluators rated captions on a 5-point scale based on fluency, image relevance, and detail level. These ratings were then normalized to a [0, 1] range for training the Polos metric.
- The proposed Polos metric integrates similarity-based and learning-based methods to evaluate the quality of captions. By leveraging the large-scale Polaris dataset for training and evaluation, the authors ensure the Polos metric is robust and generalizable across different image captioning models and datasets.
Comparison to Existing Benchmarks
Unlike traditional datasets, Polaris includes a much larger volume of human judgments and evaluations from a diverse set of evaluators. This benchmark addresses the gap in existing metrics – poor correlation with human judgment.
- Standard datasets commonly used to evaluate image captioning include Flickr8K-Expert, Flickr8K-CF, Composite, and PASCAL-50S.
- Flickr8K-Expert and Flickr8K-CF datasets:
- Comprise a significant amount of human judgments on captions provided by humans.
- Do not contain any captions generated by models, which presents an issue from the perspective of the domain gap when using them for training metrics.
- Composite dataset:
- Contains 12K human judgments across images collected from MSCOCO, Flickr8k, and Flickr30k.
- Although each image initially contains five references, only one was selected for human judgments within the dataset.
- CapEval1k dataset:
- Introduced for training automatic evaluation metrics.
- Has several limitations: it is a closed dataset, uses outdated models, and includes only 1K human judgments.
- Flickr8K-Expert and Flickr8K-CF datasets:
State-of-the-Art Results
The Polos metric performs state-of-the-art on the Polaris benchmark and the Composite, Flickr8K (Expert and CF), PASCAL-50S and FOIL benchmarks.
It outperforms the previous best metric RefPAC-S by decent margins ranging from 0.2 to 1.8 Kendall’s Tau points on the different sets.
These results demonstrate the benefit of large-scale supervised training and improved text representations compared to unsupervised methods relying on CLIP alone. However, substantial room for improvement is still needed to close the gap with human-level consistency.
Impact and Future Directions
The Polaris dataset and Polos metric aim to spur the development of more accurate automatic evaluation methods for image captioning. A reliable automatic metric that correlates well with human judgment is crucial for accelerating progress in this area, as it enables faster iteration and comparison of captioning models.
The authors note some limitations and future directions. Polos tends to overemphasize identifying the most noticeable objects while missing fine-grained details and contextual information. Techniques like RegionCLIP could potentially help improve its fine-grained alignment capabilities.
Another direction is to extend the dataset with a harsher or multi-step scoring system. Overall, this work takes important steps toward a more discriminative and human-like evaluation of image captioning models.
VBench
tl;dr
- Task: Text-to-Vide (T2V) Generation
- Metric: Instead of reducing the qality of video generation to one number, this benchmark looks at 16 dimensions in video generation, with fine-grained levels that reveal a models strengths and weaknessed
- Project Page
- Paper
- GitHub
- Leaderboard on Hugging Face
Task and Objective
This benchmark evaluates the performance of text-to-video (T2V) models. It assesses the quality and consistency of generated videos across multiple dimensions and content categories.
- Provides a standardized and reliable framework for comparing different T2V models
- Evaluates video quality, consistency, and fulfillment of conditions
Dataset and Evaluation Metric
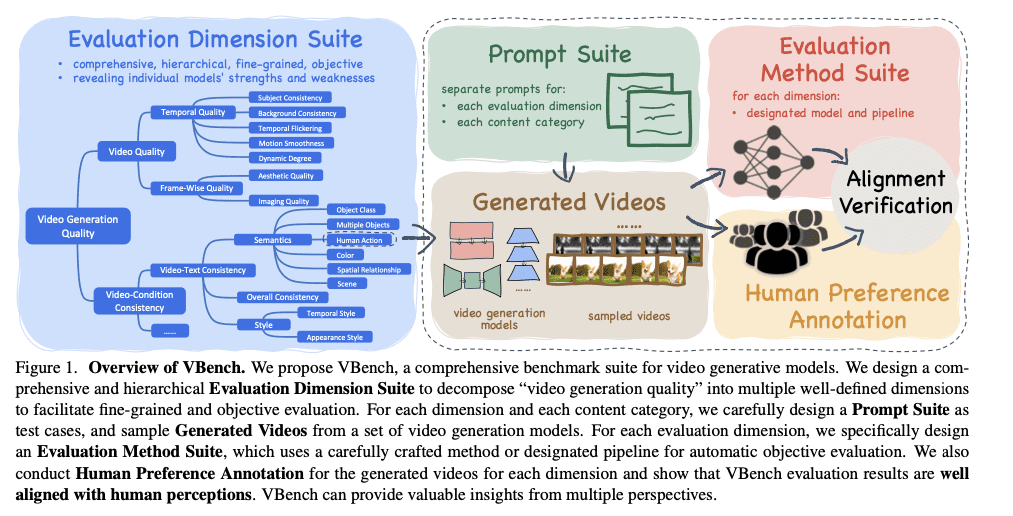
VBench introduces a diverse and carefully curated prompt suite to evaluate T2V models. The benchmark employs a multi-dimensional evaluation framework with human preference annotations.
- Prompt suite per dimension:
- Contains around 100 prompts for each of the 16 evaluation dimensions
- Evaluation dimensions: Subject Consistency, Background Consistency, Temporal Flickering, Motion Smoothness, Dynamic Degree, Object Class, Human Action, Color, Spatial Relationship, Scene, Appearance Style, and Temporal Style
- Prompt suite per category:
- Covers various content domains, such as animals, objects, humans, and scenes
- Evaluation perspectives: Video Quality, Video-Condition Consistency, and Fulfillment of Conditions
- Human preference annotations: collected through a data preparation procedure involving video generation, video pair sampling, annotation interface design, and data quality control measures
Benchmark Design and Protocol
The authors laid out an extensive procedure for data preparation for human preference annotations, as they hope to capture a models alignment with human perception.
Data preparation procedure:
- Video Generation: T2V models generate videos based on the prompts in the VBench prompt suite.
- Video Pair Sampling: Pairs of generated videos sharing the same input prompt are sampled for each evaluation dimension.
- Annotation Interface Design: A user-friendly interface allows human annotators to compare and express preferences between video pairs.
- Annotation Collection: Human annotators review video pairs and select their preferred video based on the specified evaluation dimension.
- Data Quality Control: Quality control measures, such as attention checks and consistency checks, are implemented to ensure the reliability of the collected preference data.
- Dimension-Specific Focus: Annotators focus solely on the specific evaluation dimension being assessed when expressing their preference.
- Comparative Judgment: Annotators judge between video pairs rather than providing absolute ratings.
- Attention to Detail: Annotators pay close attention to relevant details and nuances in the generated videos.
- Neutral and Unbiased Assessment: Annotators maintain a neutral and unbiased perspective when comparing and selecting preferred videos.
- Consistency and Reproducibility: Annotators consistently apply the same criteria and standards across different video pairs and evaluation dimensions.
- Handling Ambiguous or Challenging Cases: Annotators make their best judgment based on available information and specific criteria, with the option to indicate a “tie” or “unsure” response if necessary.
Comparison to Existing Benchmarks

The paper does not explicitly compare it to existing benchmarks, they do discuss existing metrics that are commonly used for evaluating video generation models and their limitations:
- Inception Score (IS)
- Fréchet Inception Distance (FID)
- Fréchet Video Distance (FVD)
- CLIPSIM
The main issues with these metrics are:
- Inconsistency with human judgment: The paper states that these existing metrics “are inconsistent with human judgement” when evaluating the quality of generated videos.
- Lack of diversity and specificity in prompts: The prompts used for these metrics, such as class labels from UCF-101 dataset for IS, FID, and FVD, and human-labeled video captions from MSR-VTT for CLIPSIM, “lack diversity and specificity, limiting accurate and fine-grained evaluation of video generation.”
- Not tailored to the unique challenges of video generation: The paper also mentions that generic Video Quality Assessment (VQA) methods “are primarily designed for real videos, thereby neglecting the unique challenges posed by generative models, such as artifacts in synthesized videos.”
- Oversimplification of evaluation: Existing metrics often reduce video generation model performance to a single number, which “oversimplifies the evaluation” and fails to provide insights into individual models’ specific strengths and weaknesses
- VBench aims to address these limitations by providing a comprehensive and standardized evaluation framework that aligns with human perception and captures the nuanced aspects of video quality and consistency.
State-of-the-Art Results
The leaderboard is on Hugging Face.

Impact and Future Directions
In my opinion, VBench has the potential to significantly impact the field of text-to-video generation and shape its future directions.
By providing a comprehensive and standardized evaluation framework, VBench addresses the limitations of existing metrics and offers a more reliable and insightful way to assess the performance of T2V models.
One of the key strengths of VBench is its alignment with human perception.
By incorporating human preference annotations and considering multiple evaluation dimensions, VBench captures the nuanced aspects of video quality and consistency important to human viewers. This human-centric approach ensures the benchmark reflects real-world expectations and requirements for generated videos.
By assessing performance across various dimensions and content categories, researchers can identify areas where models excel and where improvements are needed. This granular analysis facilitates targeted research efforts and drives the development of more advanced and specialized T2V models.
The insights provided by VBench, such as the trade-offs between temporal consistency and dynamic degree, highlight the challenges and opportunities in the field. These findings can guide researchers in developing techniques to mitigate trade-offs and optimize model performance across different dimensions. The identification of hidden potential in specific content categories encourages the exploration of specialized models tailored to particular domains, such as humans or animals.
Conclusion
CVPR 2024 has once again demonstrated the incredible pace of innovation in computer vision and deep learning.
From robust image classifiers tested against real-world perturbations to vision-language models navigating interactive environments, the benchmarks presented this year are pushing the boundaries of what’s possible.
ImageNet-D, Polaris, and VBench each offer unique challenges and opportunities for researchers, driving the development of more robust, versatile, and human-aligned models. As these benchmarks continue to evolve and inspire new research directions, we can expect even more groundbreaking advancements in the field of computer vision.
The future is bright, and I, for one, am excited to see what incredible innovations emerge next!
Visit Voxel51 at CVPR 2024!
And if you’re attending CVPR 2024, don’t forget to stop by the Voxel51 booth #1519 to connect with the team, discuss the latest in computer vision and NLP, and grab some of the most sought-after swag at the event. See you there!


