10 papers you won’t want to miss

The annual IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) is just around the corner. Every year, thousands of computer vision researchers and engineers from across the globe come together to take part in this monumental event. The prestigious conference, which can trace its origin back to 1983, represents the pinnacle of progress in computer vision. With CVPR playing host to some of the field’s most pioneering projects and painstakingly crafted papers, it’s no wonder that the conference has the fourth highest h5-index of any conference or publication, trailing only Nature, Science, and The New England Journal of Medicine.
This year, the conference will take place in Vancouver, Canada, from June 18th – June 22nd. With 2359 accepted papers, 100 workshops, 33 tutorials, and Flash Sessions happening in the Expo (including two by Voxel51), CVPR will have something for everyone.
To help you make the most of a jam-packed June week, we’ve compiled a list of the top 10 papers you just can’t miss, with links and summaries. We selected these papers based on GitHub project star counts, perceived impact to the field, and personal interest.
Here are our top picks in alphabetical order:
- Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks
- DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
- F2-NeRF: Fast Neural Radiance Field Training with Free Camera Trajectories
- GLIGEN: Open-Set Grounded Text-to-Image Generation
- ImageBind: One Embedding Space To Bind Them All
- Mask DINO: Towards A Unified Transformer-based Framework for Object Detection and Segmentation
- MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures
- Planning-oriented Autonomous Driving
- SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
- VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation
Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks
- Links: (Arxiv | Code)
- Authors: Weihua Chen, Xianzhe Xu, Jian Jia, Hao luo, Yaohua Wang, Fan Wang, Rong Jin, Xiuyu Sun
Beyond Appearance introduces a new approach to human-centric visual tasks like pose estimation and pedestrian tracking which aims to learn a generalized human representation from a plethora of unlabeled human images. Unlike traditional self-supervised learning methods, this method, dubbed SOLIDER (Semantic cOntrollable seLf-supervIseD lEaRning framework), incorporates prior knowledge from human images to create pseudo-semantic labels as a way to integrate more semantic information into the learned representation.
The real game-changer, however, is SOLIDER’s conditional network with a semantic controller. Different downstream tasks demand varying ratios of semantic and appearance information. For instance, human parsing requires high semantic information, while person re-identification instead benefits more from appearance information. SOLIDER’s semantic controller allows users to tailor these ratios to meet specific task requirements.
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation

- Links: (Arxiv | Project Page | Dataset)
- Authors: Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, Kfir Aberman
DreamBooth’s fine-tuned text-to-image diffusion models bridge the gap between human imagination and AI interpretation. The innovation lies in the authors’ approach to subject-driven generation: the user guides the AI’s creative process. Gone are the days of AI merely replicating what it has learned. With DreamBooth, it’s about molding AI’s understanding in real time.
DreamBooth empowers users to have more control over the AI’s image generation process, effectively making the AI a collaborator rather than just a tool. This fine-tuning of diffusion models enables a more nuanced and responsive generation of images from text input. With DreamBooth, your words guide the brushstrokes of the model’s metaphorical paint brush.
F2-NeRF: Fast Neural Radiance Field Training with Free Camera Trajectories
- Links: (Arxiv | Code | Project Page)
- Authors: Peng Wang, Yuan Liu, Zhaoxi Chen, Lingjie Liu, Ziwei Liu, Taku Komura, Christian Theobalt, Wenping Wang
In F2-NeRF, the paper’s authors present a novel approach to training Neural Radiance Fields (NeRFs). The approach is based on a new type of NeRF called a Fast-Free-NeRFs (F2-NeRF), which make use of fast Fourier feature-based volume rendering to significantly reduce the computational complexity of novel view synthesis – hence the ‘Fast’.
The second F, ‘Free’, derives from a new method which the authors dub perspective warping, that can be applied to create 3D scenes from arbitrary free camera trajectories, including images captured along non-linear and non-uniform paths. This method brings an unprecedented level of flexibility to NeRFs. F2-NeRF isn’t just a paper to read; it’s a glimpse into the future of 3D scene understanding and creation.
GLIGEN: Open-Set Grounded Text-to-Image Generation

- Links: (Arxiv | Code | Project Page)
- Authors: Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, Yong Jae Lee
GLIGEN sets a new standard for text-to-image generation with Grounded Language-Image GENeration. The method excels at handling open-set conditions – a context where the model is required to generate images of objects or scenes it hasn’t been explicitly trained on. This represents a dramatic improvement over traditional models that struggle when faced with concepts outside of their training set.
The model achieves this versatility by grounding the text-to-image generation process in the semantics of the input text, as opposed to relying solely on learnt correlations. This enables GLIGEN to better handle novel scenarios and generate images with a level of detail and accuracy previously unseen. The paper’s exploration of open-set grounded text-to-image generation paves the way for applications in visual storytelling, content creation, and AI-powered design tools.
For a thorough presentation of GLIGEN by the project’s lead author, Yuheng Li, see the blog post Towards Controllable Diffusion Models with GLIGEN.
ImageBind: One Embedding Space To Bind Them All
- Links: (Paper | Code)
- Authors: Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, Ishan Misra
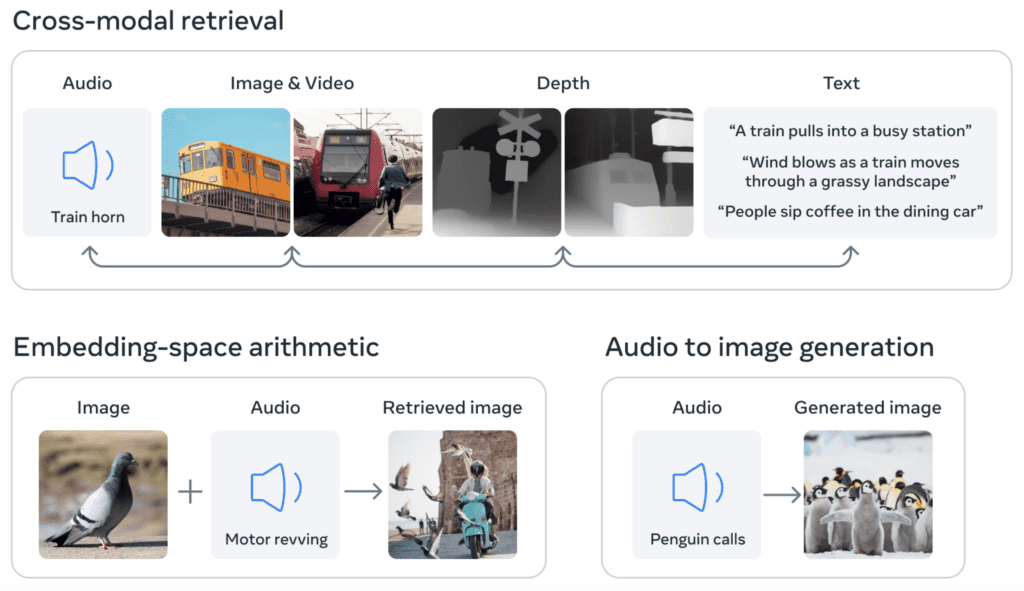
With ImageBind, FAIR and Meta AI researchers present a framework that learns a common embedding space for six modalities: images, text, audio, depth, thermal, and inertial measurement unit (IMU). This approach signifies a major departure from previous models, which typically required individual mappings for each domain pair, such as text-to-image and audio-to-image.
ImageBind streamlines image-to-image translation, and gives rise to a variety of emergent applications, including cross-modal retrieval, and state-of-the-art zero shot recognition tasks. It’s no surprise that the project’s GitHub repo accumulated more than 5,000 stars within its first week.
Mask DINO: Towards A Unified Transformer-based Framework for Object Detection and Segmentation
- Links: (Arxiv | Code)
- Authors: Feng Li, Hao Zhang, Huaizhe xu, Shilong Liu, Lei Zhang, Lionel M. Ni, Heung-Yeung Shum
In analogy with unified CNN-based models like Mask-R-CNN, Mask DINO presents a unified, transformer-based framework for object detection and segmentation, bringing together the performance of transformers with the simplicity and efficiency of single-stage pipelines.
The model does so by extending DINO (DETR with Improved Denoising Anchor Boxes) with a mask prediction branch, which generates binary prediction masks from dot products between embeddings of the query and the pixel maps. This makes the model capable of instance, semantic, and panoptic segmentation. At the time of the paper’s Arxiv submission, Mask DINO achieved state-of-the-art performance on the COCO datasets for all three of these segmentation tasks.
MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures
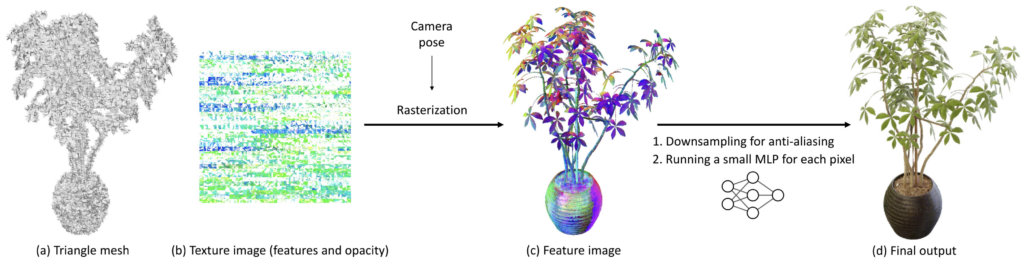
Traditional volumetric rendering of neural radiance fields (NeRFs), is compute-intensive. With MobileNeRF, researchers have brought novel view synthesis to mobile devices. This breakthrough is achieved through the introduction of a new NeRF representation based on textured polygons, which shifts some of the computational load from over-utilized shader cores to the rasterizer, which is typically underutilized in NeRF computations.
By optimizing NeRFs for mobile architectures, MobileNeRF opens up a wide array of potential applications, from on-the-go 3D model visualization to real-time augmented reality experiences, even on devices with limited computational capabilities. This paper is an absolute must-read for anyone interested in 3D rendering or the future of mobile computing.
Planning-oriented Autonomous Driving
- Links: (Arxiv | Code | Project Page)
- Authors: Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, Lewei Lu, Xiaosong Jia, Qiang Liu, Jifeng Dai, Yu Qiao, Hongyang Li
In Planning-oriented Autonomous Driving, present a compelling argument for the value of strategic planning in autonomous driving systems. Whereas autonomous driving has traditionally been treated as a sequence of modular tasks, each performed by a different model, this can lead to the accumulation of errors from subtasks, as well as from poor coordination. Instead, the authors of the paper propose a “unified” paradigm, where a single model is trained to optimize the planning of the driving itself.
This ‘planning-oriented’ approach offers autonomous vehicles the ability to make decisions akin to human drivers, accounting for variables such as traffic, pedestrian behavior, and road conditions. To justify the new paradigm, the paper’s authors introduce a full-stack framework for unified autonomous driving (UniAD) which achieves state-of-the-art performance across the board on the notoriously challenging nuScenes dataset.
SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
- Links: (Arxiv | Code | Project Page)
- Authors: Wenxuan Zhang, Xiaodong Cun, Xuan Wang, Yong Zhang, Xi Shen, Yu Guo, Ying Shan, Fei Wang
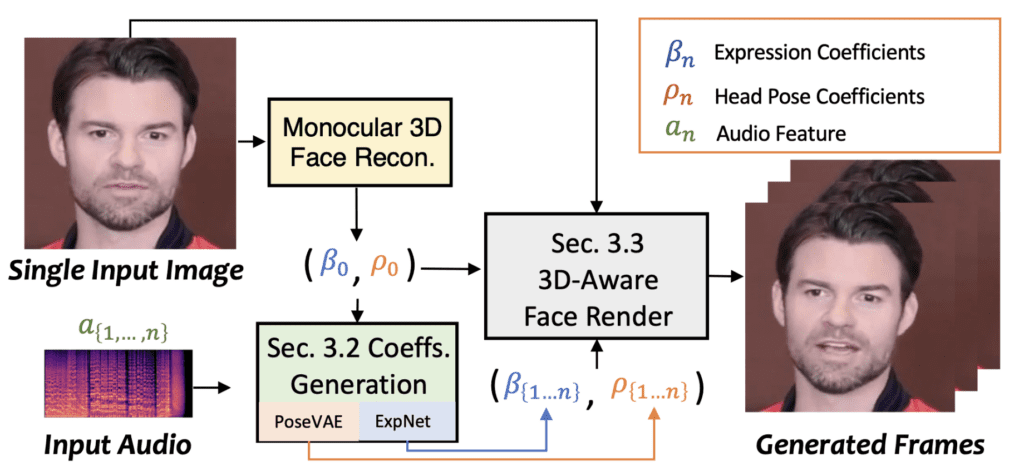
You’ll likely feel more excitement, fear, and amazement than sadness when you see how SadTalker can bring a portrait to life. SadTalker marries audio and images to generate often-uncanny talking head videos with intricate facial expressions and head poses. The model works with photographs or cartoons, and English or Chinese audio – it even works for singing!
The key to SadTalker’s success is its use of 3D Morphable Model (3DMM). While models based on 2D motion can result in unnatural head movement, distorted expressions, and identity modification, and models based on full 3D information can result in stiff or incoherent videos, SadTalker threads the needle by restricting its 3D modeling to motion. The model generates coefficients for head, pose, and expression, and uses these to render the final video. In so doing, SadTalker bypasses the problems of both fully-2D and fully-3D approaches, and surpasses prior methods in video and motion quality.
VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation

- Links: (Arxiv | Code)
- Authors: Zhengxiong Luo, Dayou Chen, Yingya Zhang, Yan Huang, Liang Wang, Yujun Shen, Deli Zhao, Jingren Zhou, Tieniu Tan
VideoFusion tackles the challenging problem of extending diffusion-based models from image generation to video generation. The paper’s novel involves decomposing the complex, high-dimensional diffusion process into two types of noise: a uniform noise that is shared across all frames, and a time-varying residual noise. Breaking the problem down in this way – essentially content and motion – accounts for the content redundancy and temporal correlation inherent in video data.
One major benefit that VideoFusion’s decomposition brings is enhanced efficiency. Because the base noise is shared by all frames, prediction of this noise can be reduced to an image-generation diffusion task. This simplifies the learning of time-dependent features of video data, and reduces latency by 57.5% compared to video-based diffusion methods.
Visit Voxel51 at CVPR!
Want to discuss the state of computer vision, talk about data-centric AI, or learn how the open source computer vision toolkit FiftyOne can help you overcome data quality issues and build higher quality models? Come by our booth #1618 at CVPR. Not only will we be available to discuss all things computer vision with you, we’d also simply love to meet fellow members of the CV community, and swag you up with some of our latest and greatest threads.
Want to make your dataset easily accessible to the fastest growing community in machine learning and computer vision? Add your dataset to the FiftyOne Dataset Zoo so anyone can load it with a single line of code.
Reach out to me on Linkedin! I’d love to discuss how we can work together to help bring your research to a wider audience 🙂
Join the FiftyOne community!
Join the thousands of engineers and data scientists already using FiftyOne to solve some of the most challenging problems in computer vision today!
- 1,600+ FiftyOne Slack members
- 3,000+ stars on GitHub
- 4,000+ Meetup members
- Used by 266+ repositories
- 58+ contributors

