Editor’s note: This is a guest post by Tarmily Wen, Principal Computer Vision Research Engineer at ADT
How to use a cookiecutter template for reproducibility, consistency, data standardization, and more

How much time have you spent trying to set up an environment for your next machine learning project? There are so many things to keep track of including installing python, python packages (and the order in which they are installed), ffmpeg, opencv, nvidia packages, cuda versions, and folder structures. That doesn’t even take into account potential conflicts and installation errors with each one of these. And this is only for the bare minimum for project setup. There are other tools that should be set up to improve quality of life.
This manual process presents points of failure: time consuming, environment conflicts, lack of reproducibility, and lack of consistency. That is why I have created a template that utilizes cookiecutter to help automate the setup process for each new ML project. This presents a few benefits: consistency, reproducibility, data standardization, and most importantly speed.
If you’re ready to get started, check out the cookiecutter template for quicker and consistent python ML project setup on GitHub. Or continue reading to learn more about it and how to use it.
What is cookiecutter?
Cookiecutter is a tool that is used to fill in templates for software projects. The values are extracted from user prompts that normally ask for the name of the project and who is contributing to it. It can also ask for what software versions are desired but that gets much trickier. Really the point of cookiecutter is to enforce a standard for project setup while also being automatic. It uses Jinja for this automation by finding and replacing variables in the project template corresponding to your custom project name..
It really is as easy as using a cookie cutter to make cookies. The template is the cookie shape and the values filled in are the icing and decorations of choice.

Why manually cut out a flying pig when there is a template to help make as many as you want?
The python ML project cookiecutter template I created adds essential features including environment reproducibility, code consistency, and data standardization, as well as some “nice to haves” like documentation generation and test automation to every ML project.
Core features of a good ML project
Reproducibility
There are so many times that the installation process for an ML repo doesn’t encompass the entire environment needed to properly run it. That is because of the aforementioned initial manual set up process for a project. It is hard to always remember to properly document the changes made. This is why the cookiecutter template uses docker. It provides a consistent environment inside of the docker container. This makes it so that anyone using the project only needs a few tools in the host operating system to properly configure, build, and run the docker image. The cookiecutter template provides the setup for the host operating system to ensure it has the correct docker setup (it is trickier when docker needs to use nvidia gpus). It also provides a Dockerfile that will automatically install all defined python packages.
But there is another layer of abstraction needed because using docker can be annoying with respect to remembering all the options for building and running arguments. There are plenty of times people use a docker command that is 3-4 lines long, which makes it easy to forget a few options when running it. Docker compose offers an easy way to have short and consistent build and run options. It also helps deal with the other big challenge when dealing with docker: docker networking. There are many times when one container depends on another and a multi-container workflow is required. It is easy to forget to put containers on the same network.
The cookiecutter template also uses poetry to ensure consistent python package dependencies and help prevent dependency hell. A requirements.txt doesn’t properly capture all of the underlying dependencies a package like pytorch needs. The packaging and dependency management made possible by poetry prevents packages from installing conflicting versions of the same dependent package.
Remember reproducibility for others is also reproducibility for yourself. There have been times when I changed my own environment, which impacted my ability to rerun old projects. And untangling the broken environment state is annoying to say the least…

Consistency
I will admit it. Sometimes I get lazy with coding and some parts of my code are sloppier than others, or some parts are written very quickly and should be revisited at some point in the future (far future). There is an “easy” way to ensure some standard coding practices, and that is done using code formatters (black, isort), linters (flake), and type checkers (pyright). These can also be incorporated automatically when you set up continuous integration (CI) to maintain code quality.
But needing to setup any CI for each project is a pain which is why the CI, using GitHub Actions, is provided in this cookiecutter to check all pushed code. It will fail the merge if all checks do not pass. This will ensure a consistent standard is present at all times in the code base. This consistency allows for easier cooperation by standardizing readability, preventing improper typing, and eliminating bad practices (such as defining a variable that is never used).

Data standardization
Data is everything in ML. But because it is everything, it is also a hassle to get right. There are many facets of data: exploration, visualization, formating, etc. Each one can be done in many different ways. This leads to headaches and assumptions about data that can be incorrect. This is why having a central store and interface for data is important. FiftyOne is chosen exactly for this feature.
Data consistency
There are many ways to visualize data: matplotlib, plotly, opencv, bokeh, etc. These all require more custom and boilerplate code written just to see and explore the data. There is also the issue where for the same task type there are differing formats and structure: annotation formats with differing folder structures, bounding box formats represented as xyxy or xywh with normalized or unnormalized values, segmentations stored as masks or polylines, etc. FiftyOne helps avoid these headaches and inconsistencies by providing an easy-to-use Python SDK that lets you parse any formats into FiftyOne which you can then visualize and integrate into your downstream tasks like annotation, model training, and evaluation.
Data duplication
If you are working on a team, then you also need to solve the problem of having different users store duplicates of the same dataset. I have worked on teams where I’ve seen multiple copies of the same COCO dataset between different people! This is where FiftyOne Teams comes into play. FiftyOne Teams extends open-source FiftyOne by enabling you to work with your teammates directly on the same datasets. For example, your model results can be appended onto samples in a FiftyOne Teams dataset and be viewed and evaluated directly by others. Since a FiftyOne Teams deployment has one central database, all users access and pull the same datasets. When everyone is working with the same data, all updates to a dataset will be reflected to everyone.
For open-source users of FiftyOne, you still get the advantage of having a single source of truth for all of your datasets in your local environment. So you won’t find yourself with multiple copies of the COCO dataset on your machine (I may have been guilty of this before…).

Nice to haves for a good ML project
These aren’t really necessary compared to the other tools, but I do believe these additional components of the cookiecutter template improve code quality and experiment tracking.
Pytorch-lightning is a wonderful library built around pytorch that reduces boilerplate code. It lets you get to writing research code much faster in a standard manner. It also has built many integrations to allow for easy, efficient, and fast training.
Weights & Biases is easily the best experimentation tracker I have seen to date. The powerful experiment tracking and visualization provides better insight in model training. It also allows for better collaboration since everyone in the group can view the results or reports can be generated and sent to others.
Sphinx is an auto documentation framework that scans through your code and checks the doc strings under classes and functions along with the type signature to create either .rst or .html files that allows for better viewing and sharing of the API documentation.
Nox is an automated test runner for python that allows for tests to be run in isolated session environments. This tool can be used to check CI, unit tests, safety tests, doc generation tests, etc.
How to use the python ML project cookiecutter
I will now walk through how to quickly create a new ML project using the python ML project cookiecutter template.
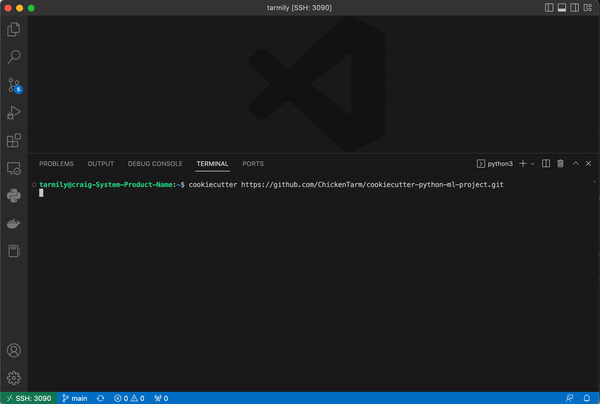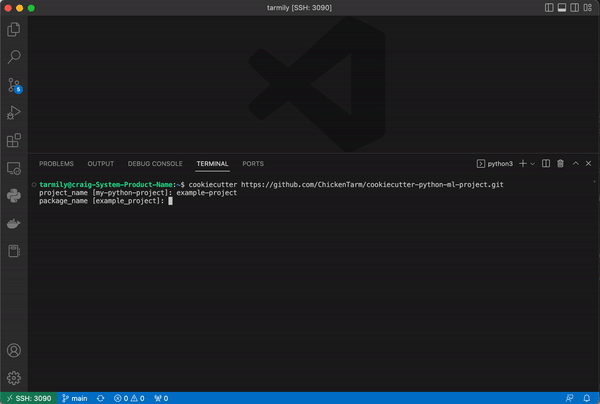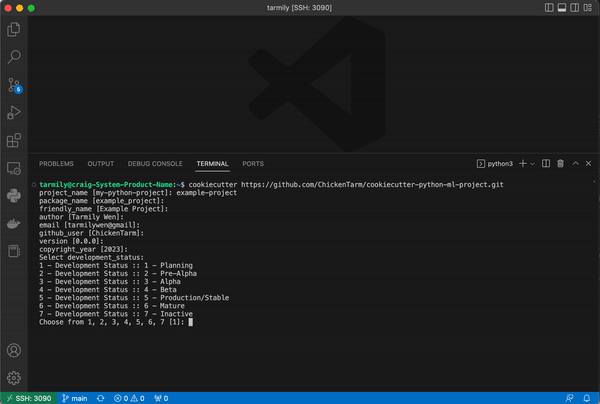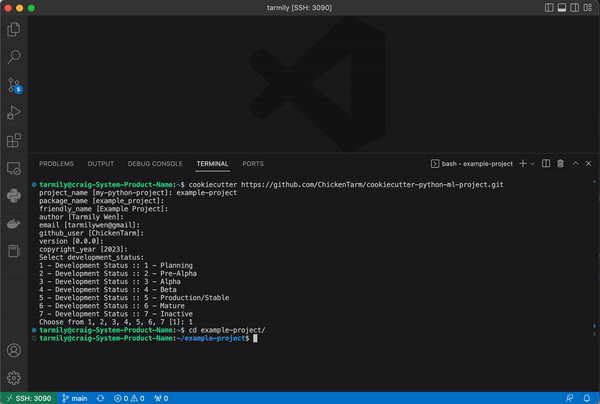
You just need to point cookiecutter to the GitHub repository for this template and fill in the required values: project name, email, and github username. The rest of the values can just use the default values.
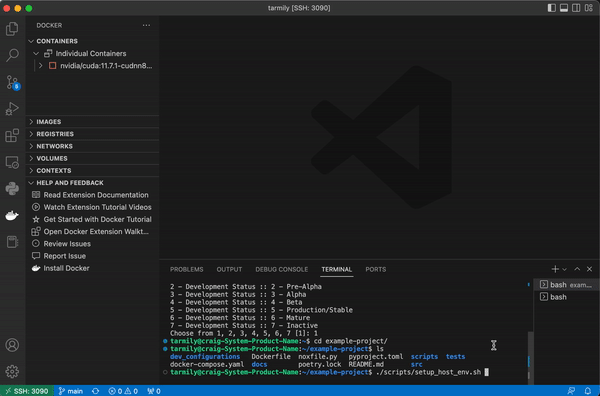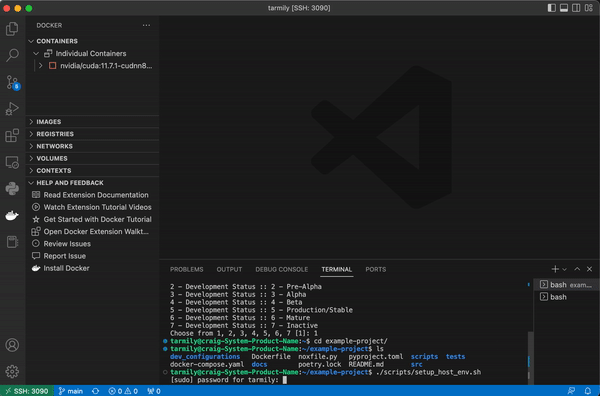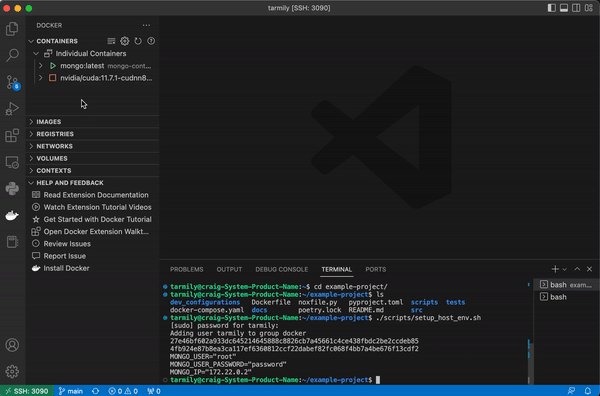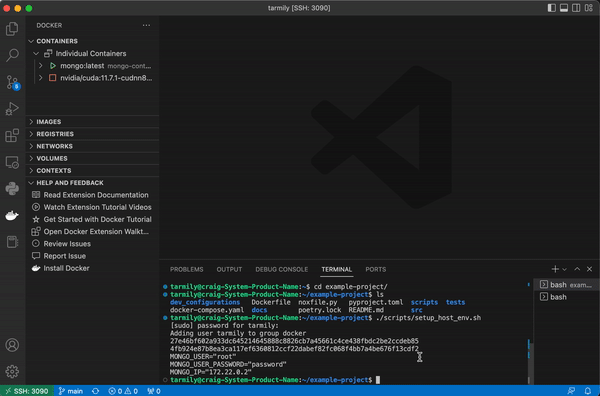
This script will install docker, compose, and nvidia-container-runtime. It will also configure docker settings, namely the container runtime.
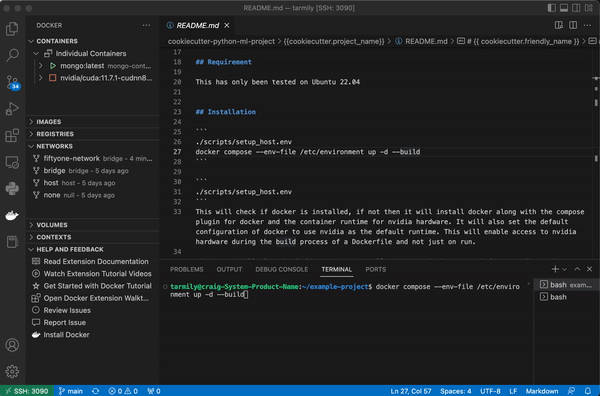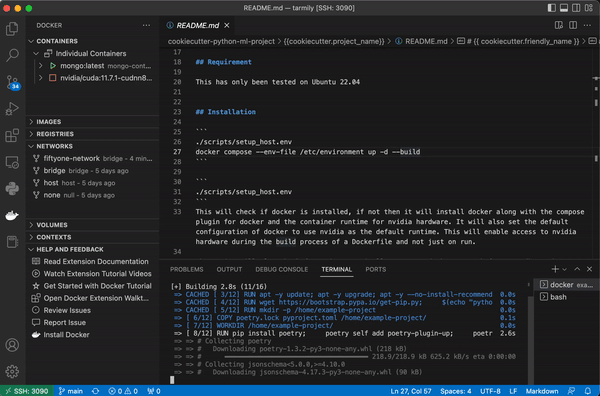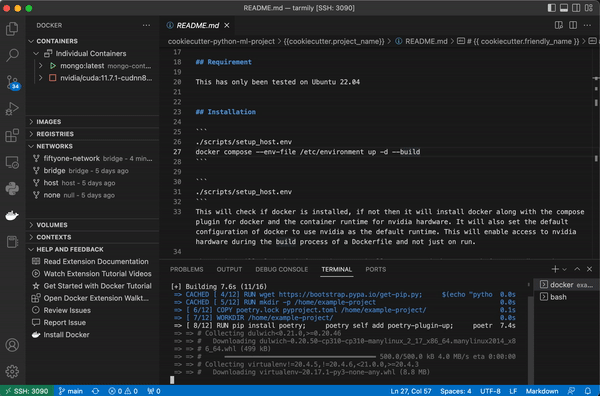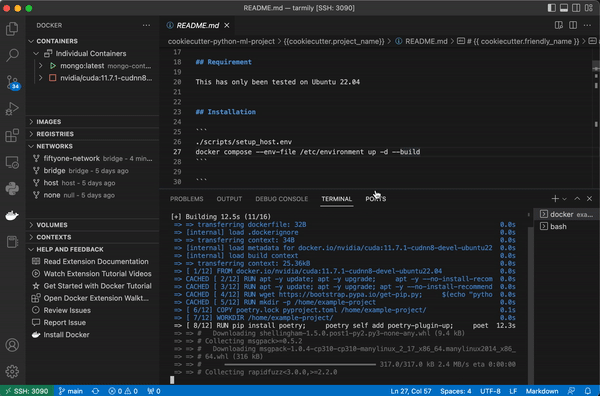
Your docker container will automatically set up python along with python packages for ML, CI, testing, and docs. The compose file also attaches the container to the correct docker network so the container has access to FiftyOne’s mongdb and qdrant if you use that integration.
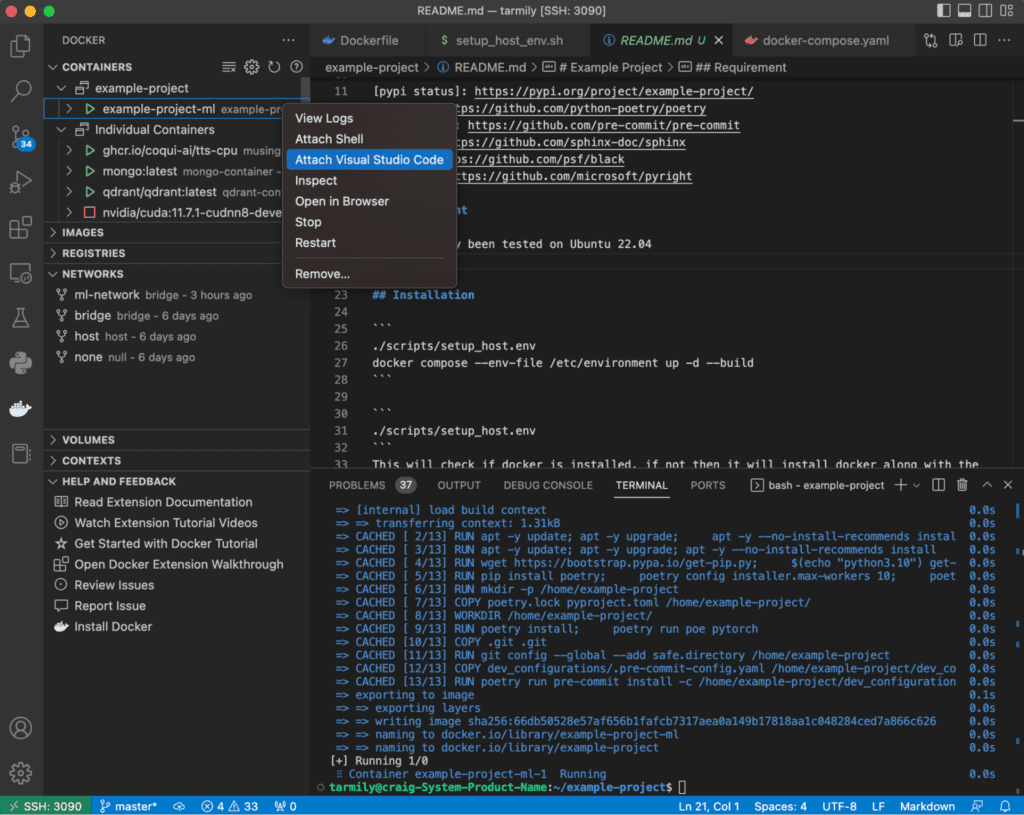
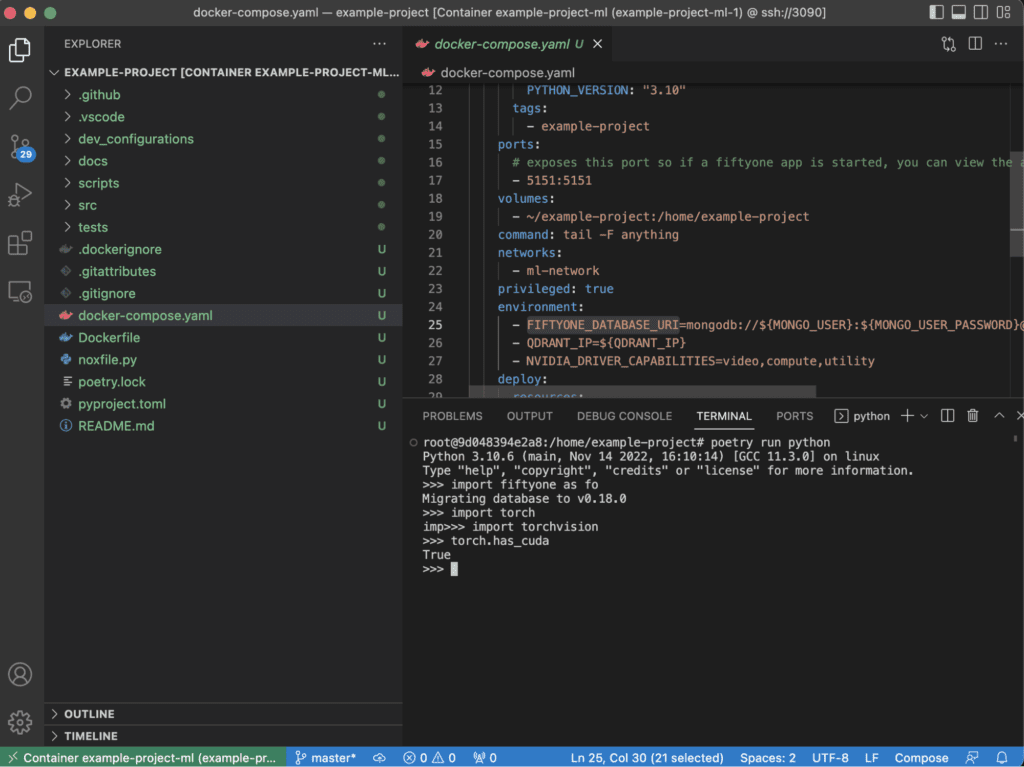
It is very easy to connect to a running container and check that the environment is properly set up.
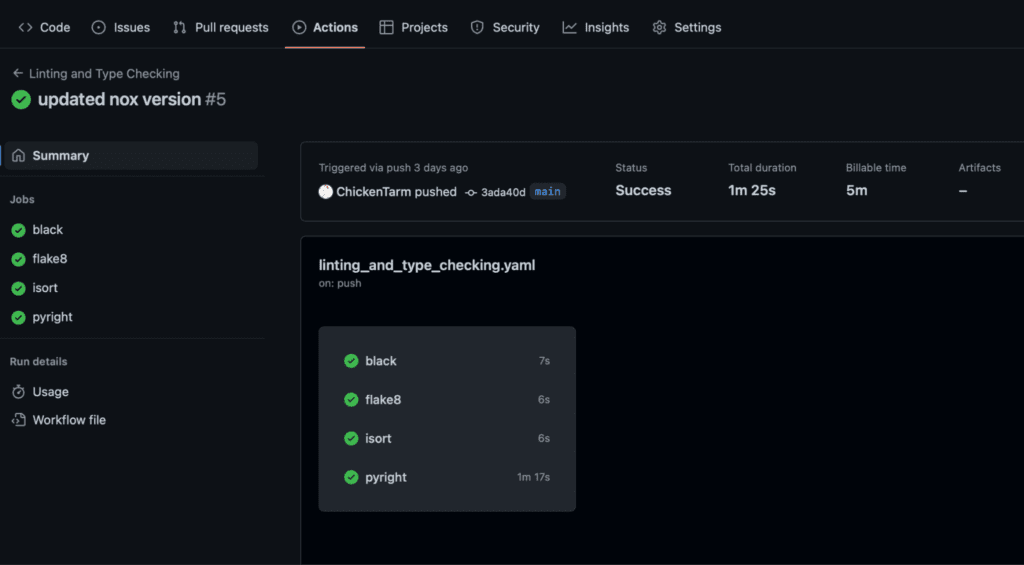
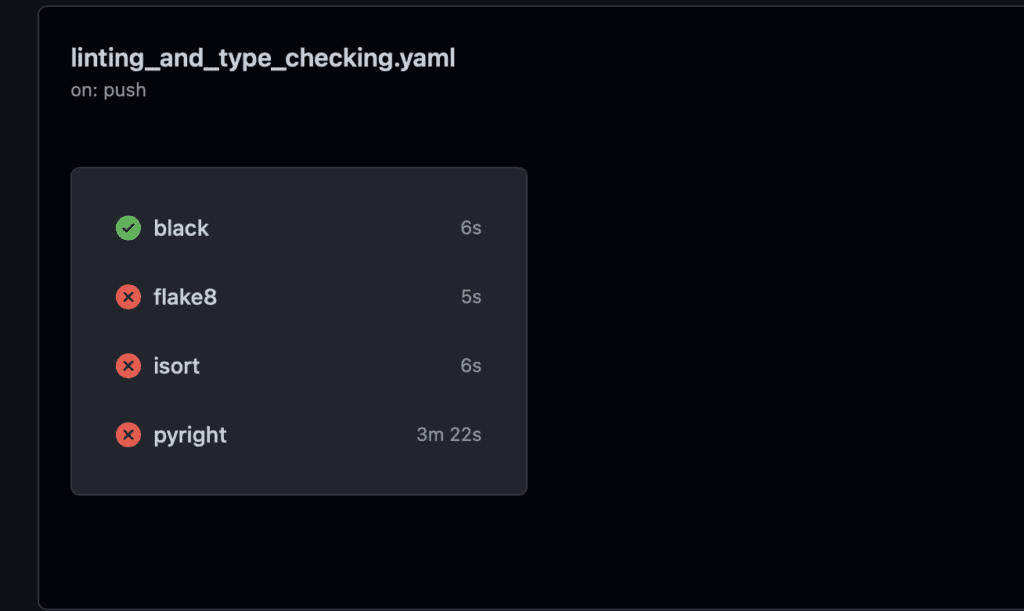
The actions page will let you know what CI tests have passed or failed.
It is as easy as that to get a python ML environment up and running. In addition, pairing this cookiecutter template with a modern IDE with the ability to hook into running containers makes it feel like you are working in a local development environment even though you are actually working within a container. My IDE of choice is VSCode since it has the best docker plugin I have seen, but it is not the only one with this capability.
Final thoughts
My cookiecutter is based on hypermodern python cookiecutter which means there are probably a few features that may not be needed for your project: nox, unit testing, and auto doc generation. Those are nice to have but really not all projects need that level of rigor, but that is offered in the template if that is desired.
It can be a lot of effort setting up a project with all of these attributes, which is why I created this cookiecutter template to enable projects to have these attributes without the overhead of learning to set them up manually. At the end of the day we all want the same thing – to produce quality code, but not have that get in the way of research. I hope my cookiecutter proves useful for you. Try it out and if there are any issues or improvements that can be made let me know!

