I’m thrilled to announce the general availability of FiftyOne Teams 1.4, an exciting addition to the FiftyOne ecosystem that brings significant upgrades to the representational power and extensibility of FiftyOne.
First, with Dataset Versioning, we’re introducing the ability to create snapshots of your datasets, enabling you to track the lineage of your data, view the exact version of a dataset on which a given model was trained, protect against accidental or fruitless data modification, and much more.
Second, we’re launching Delegated Operations, an all-new extension of FiftyOne’s plugin framework that allows you to schedule customizable tasks from within the App that are executed on a connected workflow orchestrator like Apache Airflow. Bring your data to the center of your AI workflows.
Finally, we’ve added a native Ultralytics integration, making it easy to train the latest Ultralytics models like YOLOv8 on your FiftyOne datasets with just a few lines of code.
Whether you’re prototyping a new project or leading a large effort to deploy a machine learning system into production, your AI stack needs a flexible data-centric component that enables you to organize, visualize, and iterate on your data. At Voxel51, we’re proud that tens of thousands of developers now trust open source FiftyOne as the source of truth for their ML data and use FiftyOne Teams to collaborate with their team to build better models through better data.
Wait, what’s FiftyOne?
FiftyOne is the open source machine learning toolset that enables data science teams to improve the performance of their computer vision models by helping them curate high quality datasets, evaluate models, find mistakes, visualize embeddings, and get to production faster.

Okay, but what’s FiftyOne Teams?
FiftyOne Teams extends FiftyOne with a GSuite-like experience for teams that want to collaborate on data stored in a centralized location with additional features like user permissions, dataset versioning, cloud-backed media, and enterprise security.

If this sounds interesting, read on! Then schedule a workshop to learn more about FiftyOne Teams.
tl;dr: What’s new in FiftyOne Teams 1.4?
This release includes three headline features:
- Dataset Versioning: you can now create snapshots of your datasets and view/rollback to previous snapshots, enabling you to track the lineage of your data, view the exact version of a dataset on which a given model was trained, protect against accidental data modification, and much more.
- Delegated Operations: this all-new feature allows you to schedule tasks from within the FiftyOne App that are executed on a connected workflow orchestration tool like Apache Airflow. You can choose from dozens of prebuilt operations or write, permission, and upload your own custom workflows to your Teams deployment.
- Ultralytics Integration: this integration makes it easy to train the latest Ultralytics models like YOLOv8 on your FiftyOne datasets with just a few lines of code.
Check out the release notes for a full rundown of additional enhancements and bugfixes in FiftyOne Teams 1.4.
Dataset Versioning
One of the most popular feature requests from FiftyOne Teams users has been the ability to create and track versions of their datasets natively within FiftyOne. Now with FiftyOne Teams 1.4, you can!
Dataset Versioning allows you to track the lineage of your data, view the exact version of a dataset on which a given model was trained, protect against accidental data modification, and much more. With dataset versioning, you can trust FiftyOne Teams as the single source of truth for your organization’s data.
Check out the 60 second video below for a walkthrough of the feature:
Dataset Versioning in FiftyOne Teams is implemented as a linear sequence of read-only snapshots. In other words, creating a new snapshot creates a permanent record of the dataset’s contents that can be loaded and viewed at any time in the future, but not directly edited. Conversely, the current version of a dataset is called its HEAD (think git). If you have not explicitly loaded a snapshot, you are viewing its HEAD, and you can make additions, updates, and deletions to the dataset’s contents as you normally would (provided you have sufficient permissions).
Any user with Can View access to a dataset can view its snapshots. However, only users with Can Manage permissions to a dataset can create, edit, and delete its snapshots.
Dataset snapshots record all aspects of your data stored within FiftyOne, including dataset-level information, schema, samples, frames, brain runs, and evaluations. However, snapshots exclude any information stored in external services, such as media stored in cloud buckets or embeddings stored in an external vector database, which are assumed to be immutable. If you need to update the image for a sample in a dataset, for example, update the sample’s filepath—which is tracked by snapshots—rather than updating the media in cloud storage in-place—which would not be tracked by snapshots. This design allows dataset snapshots to be as lightweight and versatile as possible.
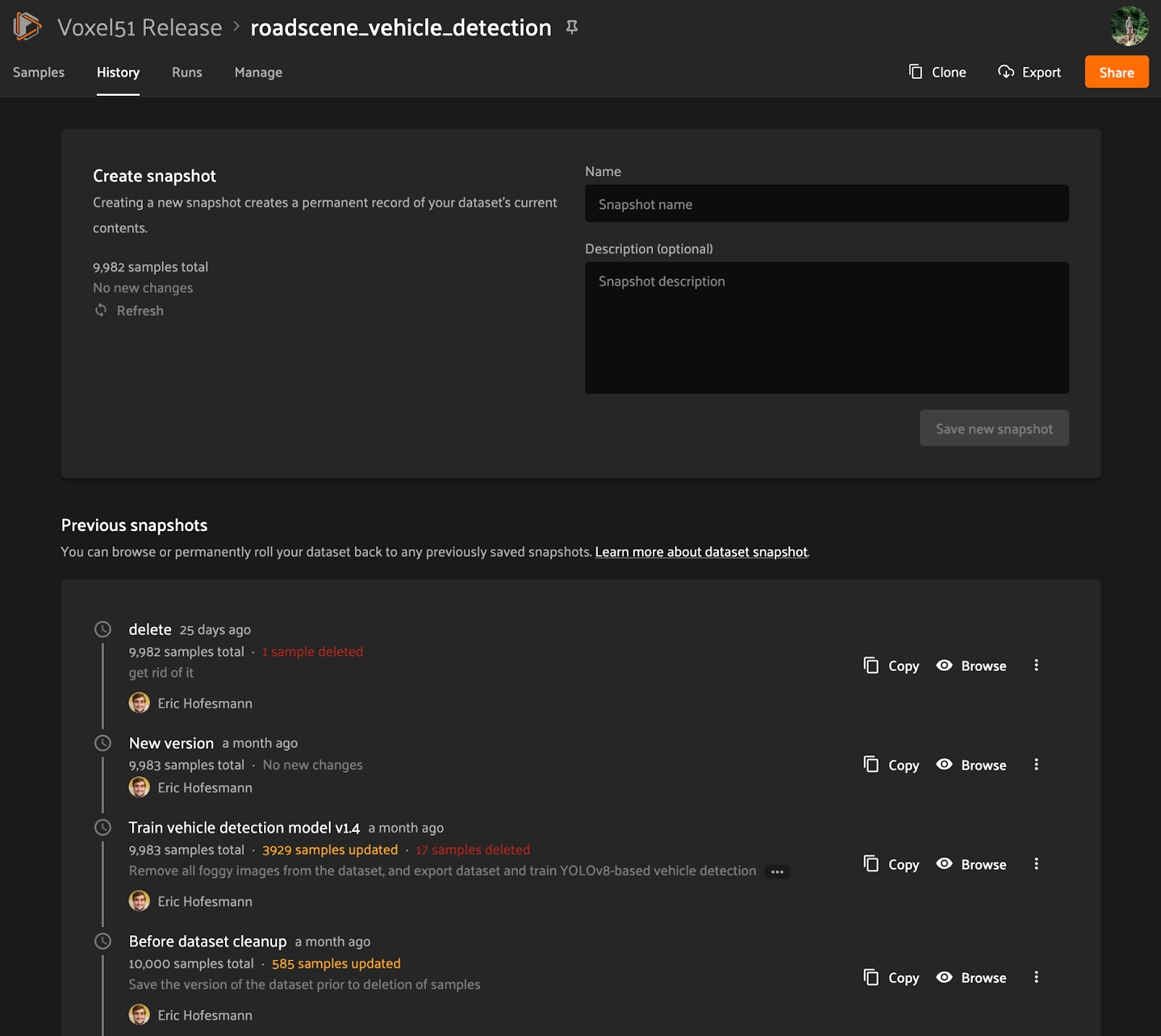
After upgrading to FiftyOne Teams 1.4, all datasets will have a History tab in the App that provides access to the dataset’s versioning history. From this tab, you can easily:
- View changes between the dataset’s HEAD and its most recent snapshot (if any)
- Create a new snapshot
- View the dataset’s snapshots and their associated metadata
- Open a snapshot in the App to visualize it
- Clone a snapshot into a new dataset
- Rollback a dataset to a previous snapshot
- Delete a snapshot
You can programmatically load a specific snapshot of a dataset via the FiftyOne Teams SDK by passing the optional snapshot argument to load_dataset():
import fiftyone as fo
# Load a snapshot
dataset = fo.load_dataset("dataset name", snapshot="snapshot name")
Snapshots behave exactly like regular FiftyOne datasets, except that they are always read-only.
If you have Can Manage permissions to a dataset, you can also use the Management SDK to programmatically create and manipulate snapshots:
import fiftyone.management as fom # List available snapshots fom.list_snapshots(dataset_name) # Create a new snapshot fom.create_snapshot(dataset_name, snapshot_name, **kwargs) # Delete a snapshot fom.delete_snapshot(dataset_name) # Revert a dataset to a snapshot fom.revert_dataset_to_snapshot(dataset_name, snapshot_name)
For more information about Dataset Versioning in FiftyOne, check out the docs.
Delegated Operations
FiftyOne Teams 1.4 adds a powerful new Delegated Operations feature to FiftyOne’s Plugin framework that allows you to schedule builtin and/or custom tasks from within the App that are executed on a connected workflow orchestrator like Apache Airflow.
Why is this awesome? Your AI stack needs a flexible data-centric component that enables you to organize and compute on your data. With Delegated Operations, FiftyOne becomes both a dataset management/visualization tool and a workflow automation tool that defines how your data-centric workflows like ingestion, curation, and evaluation are performed. In short, think of FiftyOne Teams as the single source of truth on which you co-develop your data and models together.
What can Delegated Operations do for you? Get started by installing any of these plugins available in the FiftyOne Plugins repository:
- @voxel51/annotation – ✏️ Utilities for integrating FiftyOne with annotation tools
- @voxel51/brain – 🧠 Utilities for working with the FiftyOne Brain
- @voxel51/evaluation – ✅ Utilities for evaluating models with FiftyOne
- @voxel51/io – 📁 A collection of import/export utilities
- @voxel51/indexes – 📈 Utilities working with FiftyOne database indexes
- @voxel51/utils – ⚒️ Call your favorite SDK utilities from the App
- @voxel51/zoo – 🌎 Download datasets and run inference with models from the FiftyOne Zoo, all without leaving the App
- @voxel51/voxelgpt – 🤖An AI assistant that can query visual datasets, search the FiftyOne docs, and answer general computer vision questions
For example, wish you could import data from within the App? With the @voxel51/io plugin, you can!

Want to send data for annotation from within the App? Sure thing, just install the @voxel51/annotation plugin:

Have model predictions on your dataset that you want to evaluate? The @voxel51/evaluation plugin makes it easy:

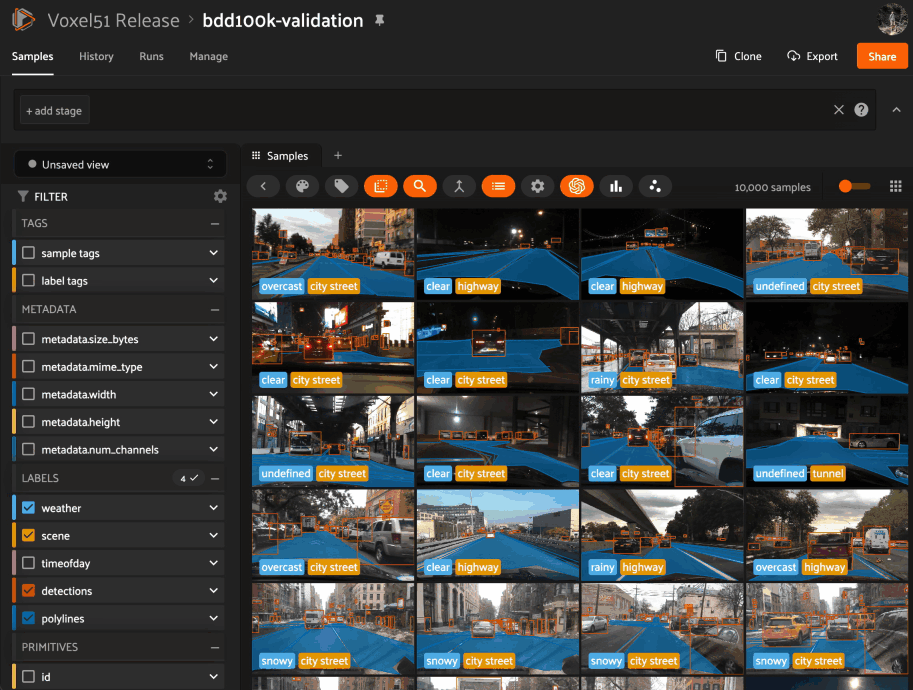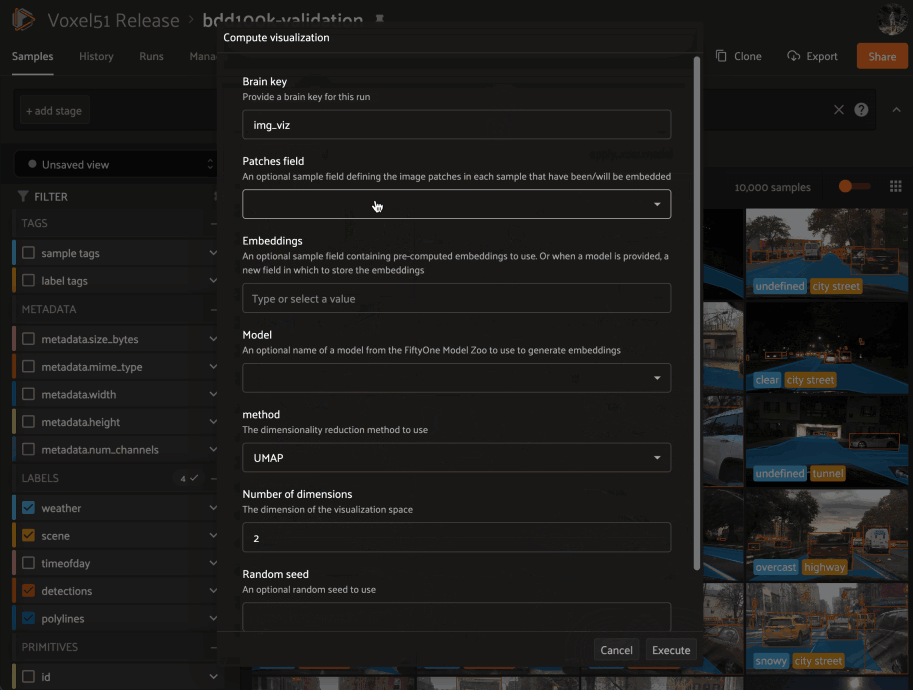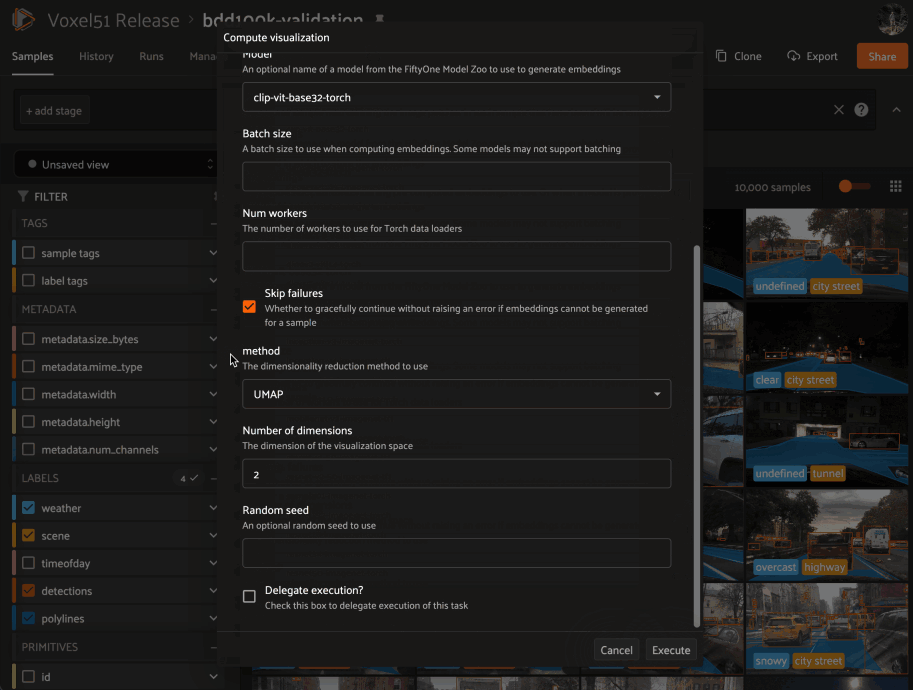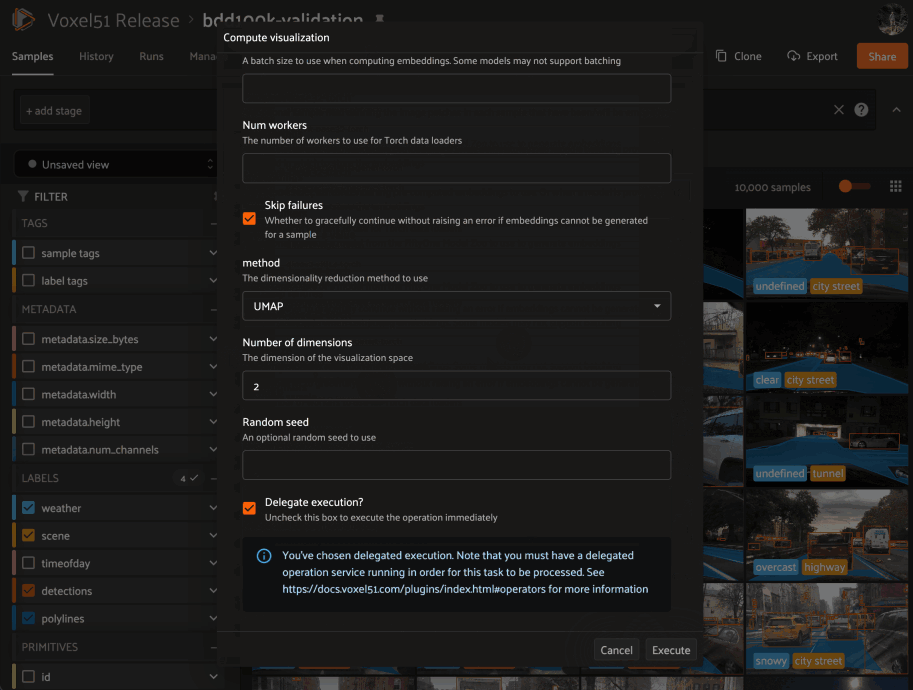
Need to compute embedding for your dataset so you can visualize them in the Embeddings panel? Kick off the task with the @voxel51/brain plugin and proceed with other work while the execution happens in the background:
When you choose delegated execution in the App, the task is automatically scheduled for execution on your connected orchestrator and you can continue with other work. Meanwhile, all datasets have a Runs tab in the App where you can browse a history of all Delegated Operations that have been run on the dataset and their status:

You can also click on an individual run to see information about its inputs, outputs, and any errors that occurred during execution:

When writing your own plugins, you can declare that an operation should be delegated by implementing the optional resolve_delegation() method and returning True.
That’s it? Yep! When a user executes a delegated operation, the execute() method is called by the connected orchestrator rather than being immediately executed by the App server when the user creates the task.
import fiftyone.operators as foo
import fiftyone.operators.types as types
class YourOperator(foo.Operator):
@property
def config(self):
return foo.OperatorConfig(
name="your_operator",
label="Your operator",
dynamic=True,
)
def resolve_input(self, ctx):
# Collect your input parameters here
pass
def resolve_delegation(self, ctx):
#
# Return True to schedule this operation for delegated execution
# or False to execute it immediately
#
# You can optionally use `ctx` to dynamically determine whether
# to delegate based on the user-provided inputs
#
pass
def execute(self, ctx):
# Perform the operation using `ctx.dataset`, `ctx.params` etc
pass
def resolve_ouput(self, ctx):
# Render any output information here
pass
def register(p):
p.register(YourOperator)
If an Operator requires secret information like API keys, usernames, or passwords that need to be stored encrypted, an Admin of your FiftyOne Teams deployment can upload the necessary key-value pairs using the Secrets UI shown below:

Then, as a plugin developer, simply declare the secrets that your Operator requires by adding them to the plugin’s fiftyone.yml file:
- OPENAI_API_KEY
Your Operator can then access these secrets at runtime via the ctx.secrets dict:
def execute(self, ctx):
api_key = ctx.secrets["OPENAI_API_KEY"] # your Open AI API key
Note that the ctx.secrets dict will also be automatically populated with the values of any environment variables whose name matches a secret key declared by an Operator, so a plugin written using the above pattern can run in all of the following environments with no code changes:
- Open source FiftyOne
- Logged into FiftyOne Teams via the web
- A locally launched App via the FiftyOne Teams SDK
Check out the docs for more information about writing your own operators and plugins and distributing them via GitHub.
Ultralytics integration
FiftyOne Teams 1.4 also includes a native Ultralytics integration, making it easy to train the latest Ultralytics models like YOLOv8 on your FiftyOne datasets with just a few simple lines of code.
Running inference on a FiftyOne dataset with an Ultralytics model is made simple with the utility methods in the new fiftyone.utils.ultralytics module:
import fiftyone as fo
import fiftyone.utils.ultralytics as fou
from ultralytics import YOLO
dataset = fo.load_dataset("your-dataset")
model = YOLO("yolov8s.pt")
for sample in dataset.iter_samples(progress=True):
result = model(sample.filepath)[0]
sample["boxes"] = fou.to_detections(result)
sample.save()
session = fo.launch_app(dataset)
You can also use FiftyOne’s builtin YOLO exporter to prepare datasets for training:
import fiftyone as fo
import fiftyone.utils.ultralytics as fou
import fiftyone.zoo as foz
# The path to export the dataset
EXPORT_DIR = "/tmp/oiv7-yolo"
# Prepare train split
train = foz.load_zoo_dataset(
"open-images-v7",
split="train",
label_types=["detections"],
max_samples=100,
)
# YOLO format requires a common classes list
classes = train.default_classes
train.export(
export_dir=EXPORT_DIR,
dataset_type=fo.types.YOLOv5Dataset,
label_field="ground_truth",
split="train",
classes=classes,
)
# Prepare validation split
validation = foz.load_zoo_dataset(
"open-images-v7",
split="validation",
label_types=["detections"],
max_samples=10,
)
validation.export(
export_dir=EXPORT_DIR,
dataset_type=fo.types.YOLOv5Dataset,
label_field="ground_truth",
split="val", # Ultralytics uses 'val'
classes=classes,
)
From here, training an Ultralytics model is as simple as passing the path to the dataset YAML file:
from ultralytics import YOLO
# The path to the `dataset.yaml` file we created above
YAML_FILE = "/tmp/oiv7-yolo/dataset.yaml"
# Load a model
model = YOLO("yolov8s.pt") # load a pretrained model
# model = YOLO("yolov8s.yaml") # build a model from scratch
# Train the model
model.train(data=YAML_FILE, epochs=3)
# Evaluate model on the validation set
metrics = model.val()
# Export the model
path = model.export(format="onnx")
Check out the FiftyOne Integrations page for a growing list of third-party libraries and products that FiftyOne natively integrates with.

