Voxel51 in conjunction with the FiftyOne community is excited to announce the general availability of FiftyOne 0.19. This release is packed with new features that make it even easier and faster to visualize your computer vision datasets and boost the performance of your machine learning models. How? Read on!
Wait, what’s FiftyOne?
FiftyOne is the open source machine learning toolset that enables data science teams to improve the performance of their computer vision models by helping them curate high quality datasets, evaluate models, find mistakes, visualize embeddings, and get to production faster.

- If you like what you see on GitHub, give the project a star.
- Get started! We’ve made it easy to get up and running in a few minutes.
- Join the FiftyOne Slack community, we’re always happy to help.
Ok, let’s dive into the release.
tl;dr: What’s new in FiftyOne 0.19?
This release includes:
- Spaces: an all-new customizable framework for organizing interactive information panels within the FiftyOne App, allowing you to visualize and query your datasets in powerful new ways through a convenient interface
- In-App embeddings visualization: you can now interactively explore embeddings visualizations natively in the App by opening an embeddings panel with one click
- Saved views: you can now save views into your datasets and switch between them natively in the App
- On-disk segmentations: you can now store your semantic segmentation masks and heatmaps on disk, rather than in the database
- New UI filtering options: the App’s sidebar now contains upgraded options for filtering datasets
- FiftyOne Teams documentation: documentation for FiftyOne Teams is now publicly available!
Check out the release notes for a full rundown of additional enhancements and bugfixes.
Live demo & AMA on Feb. 28 @ 10 AM PT

See all of the new features in action in the webinar and AMA we held on February 28, 2023. I demoed all of the new features in FiftyOne 0.19, which you can check out in the recap and the video playback.
Now, here’s a quick overview of some of the new features we packed into this release.
Spaces
FiftyOne 0.19 debuts Spaces, a customizable framework for organizing interactive information Panels in the App.
As of FiftyOne 0.19, the following Panel types are included natively:
- Samples Panel: the media grid that loads by default when you launch the App
- Histograms Panel: a dashboard of histograms for the fields of your dataset
- (New!) Embeddings Panel: a canvas for working with embeddings visualizations
- Map Panel: visualizes the geolocation data of datasets that have a GeoLocation field
- You can also configure custom Panels via plugins!
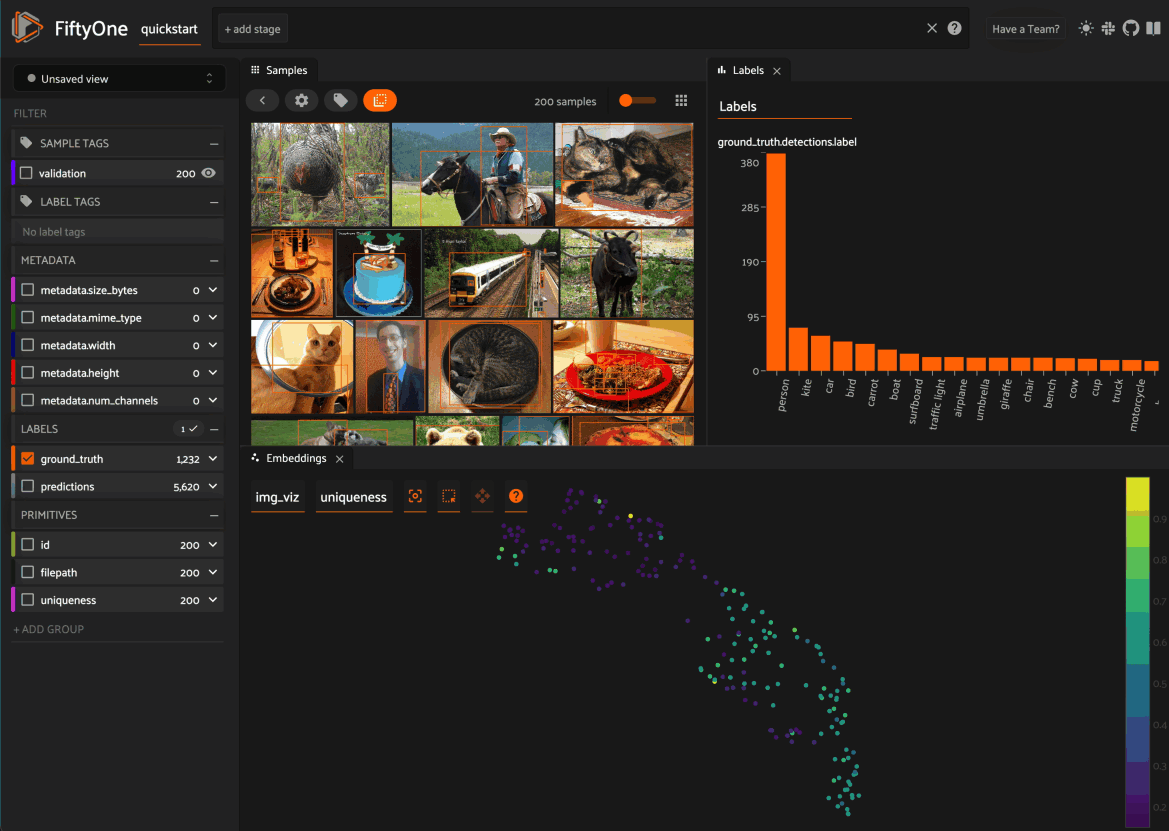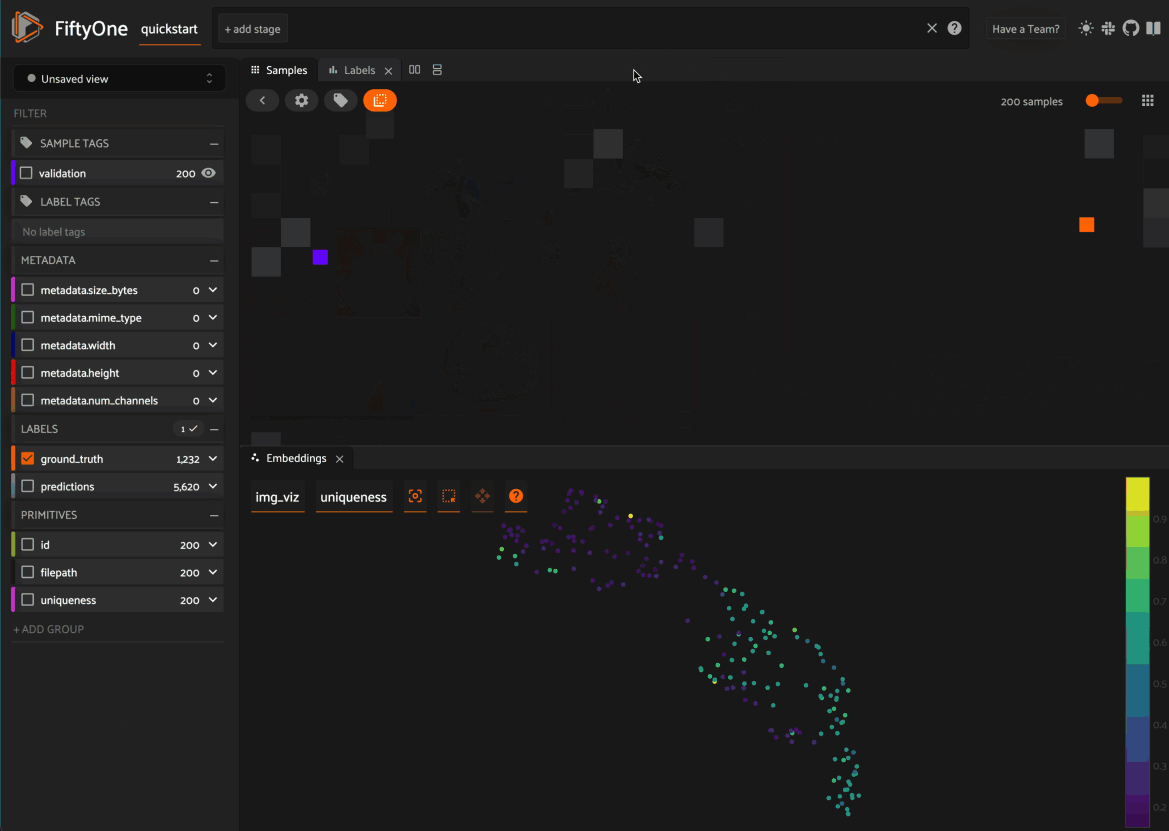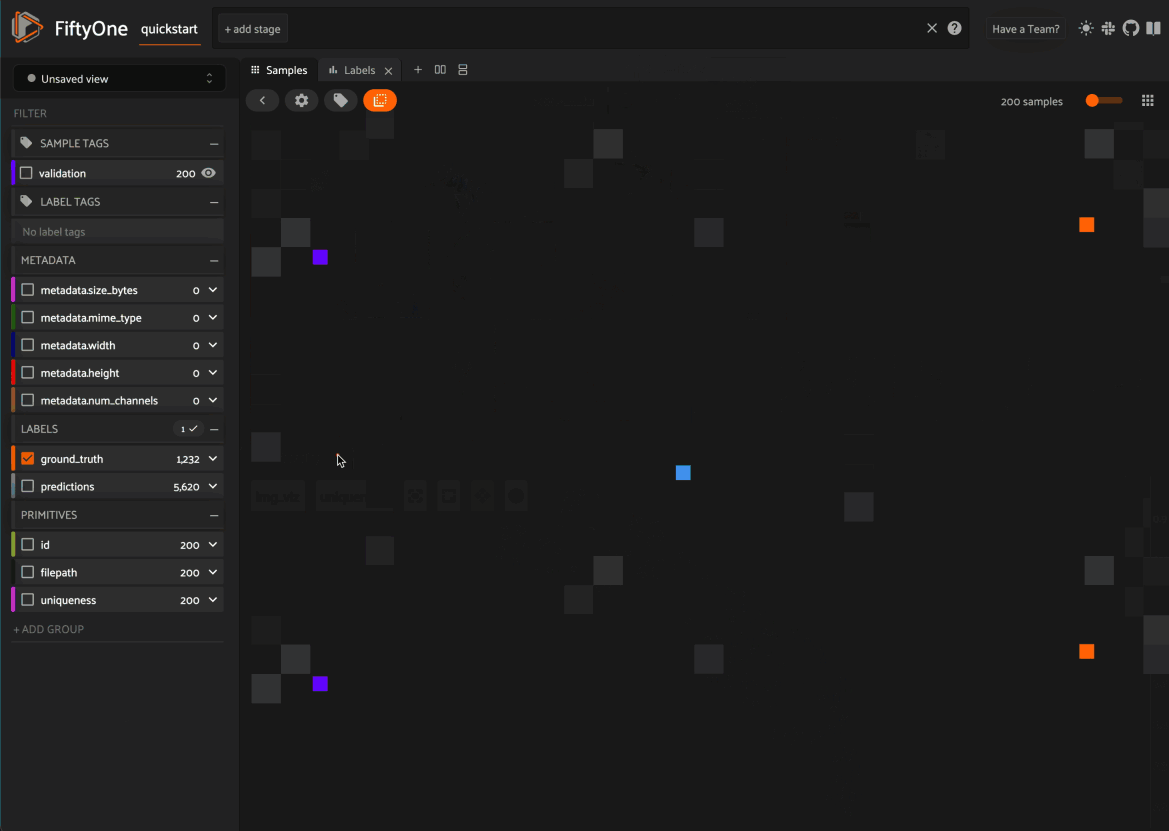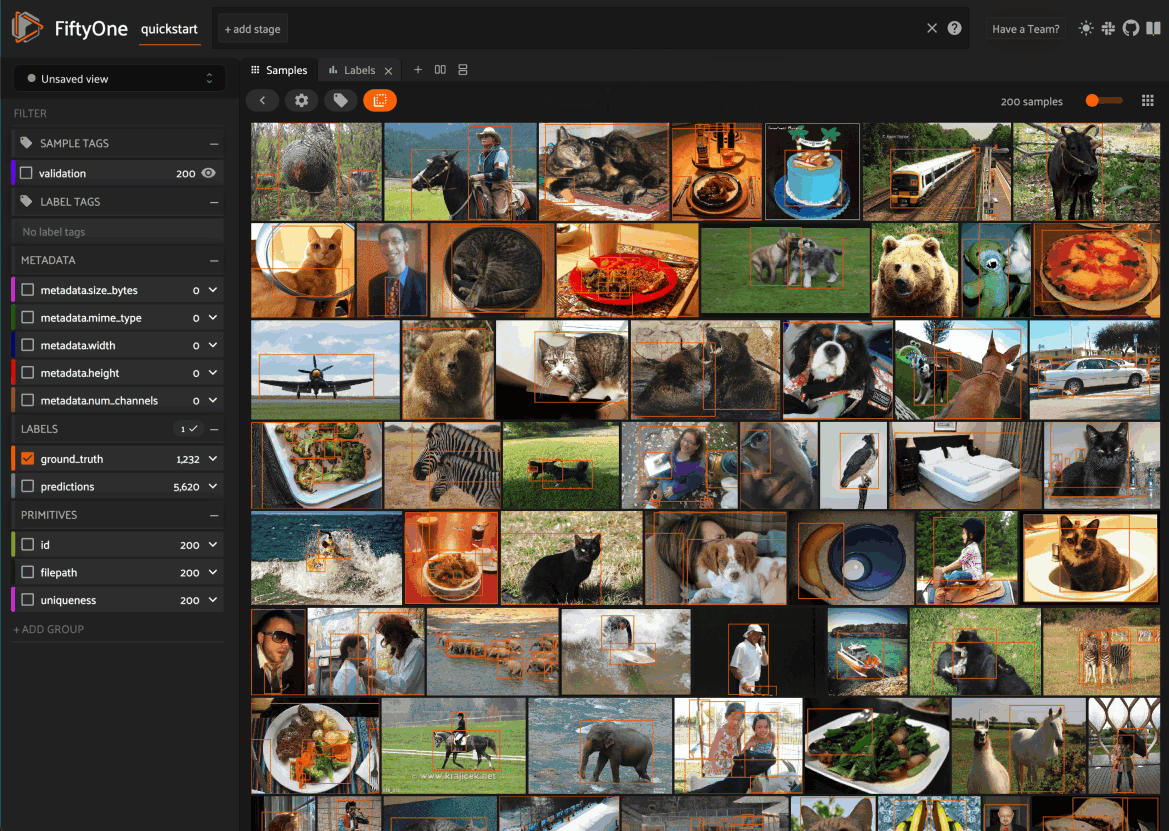
In the screenshot below, for example, we’ve added the Embeddings and Map Panels to the default Samples Panel so we can visualize all three together seamlessly in the App.
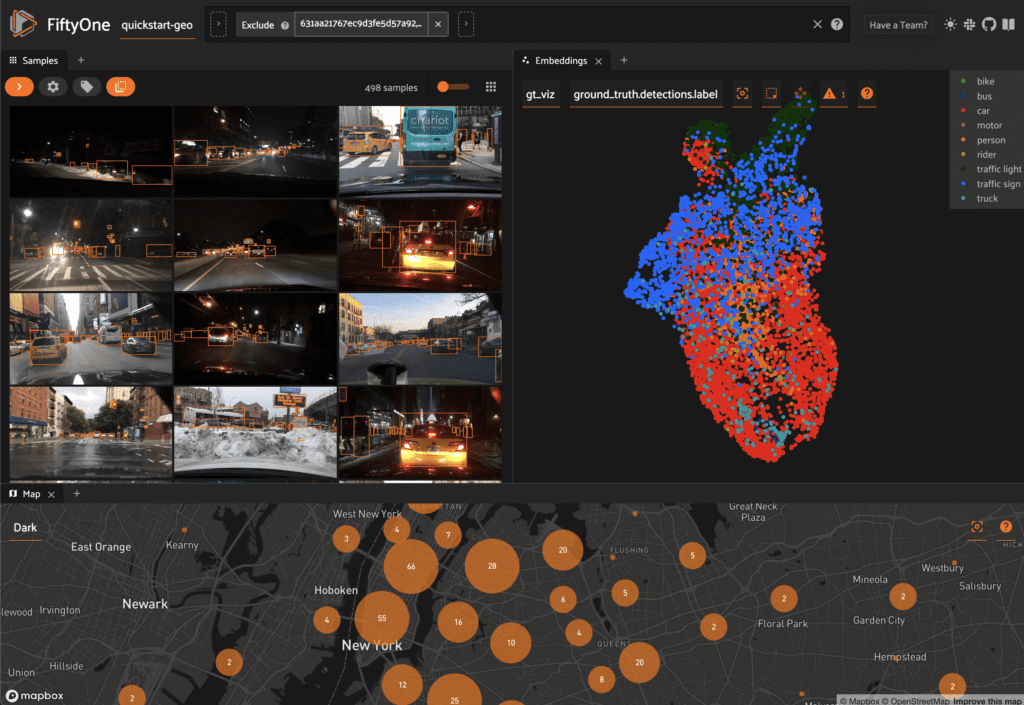
You can configure Spaces visually in the App in a variety of ways described below.
1. Click the + icon in any Space to add a new Panel:
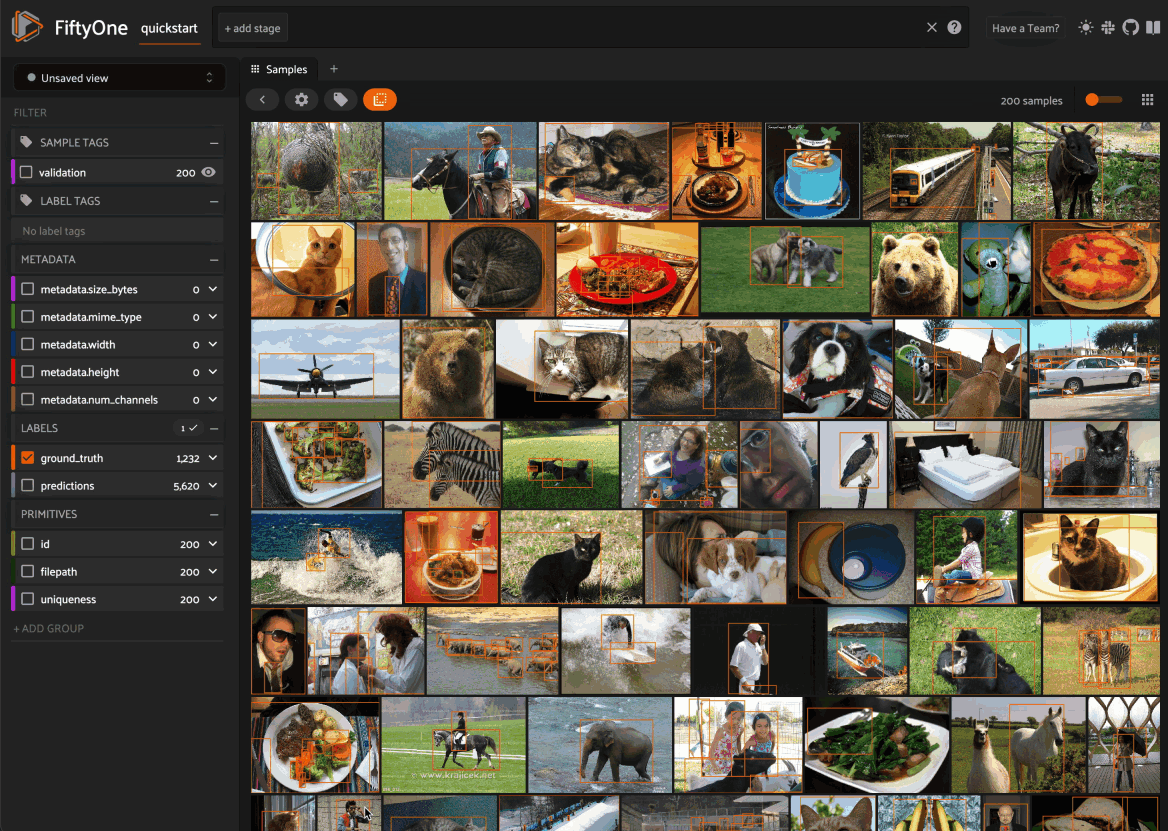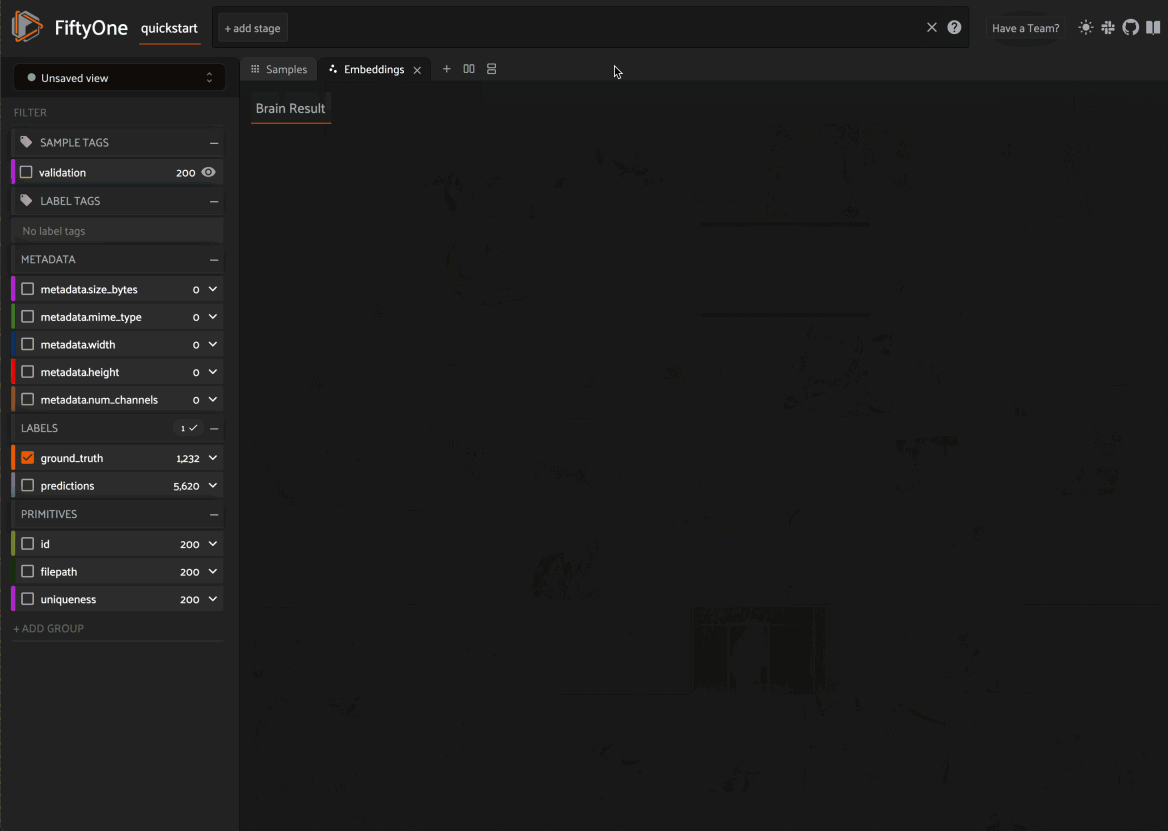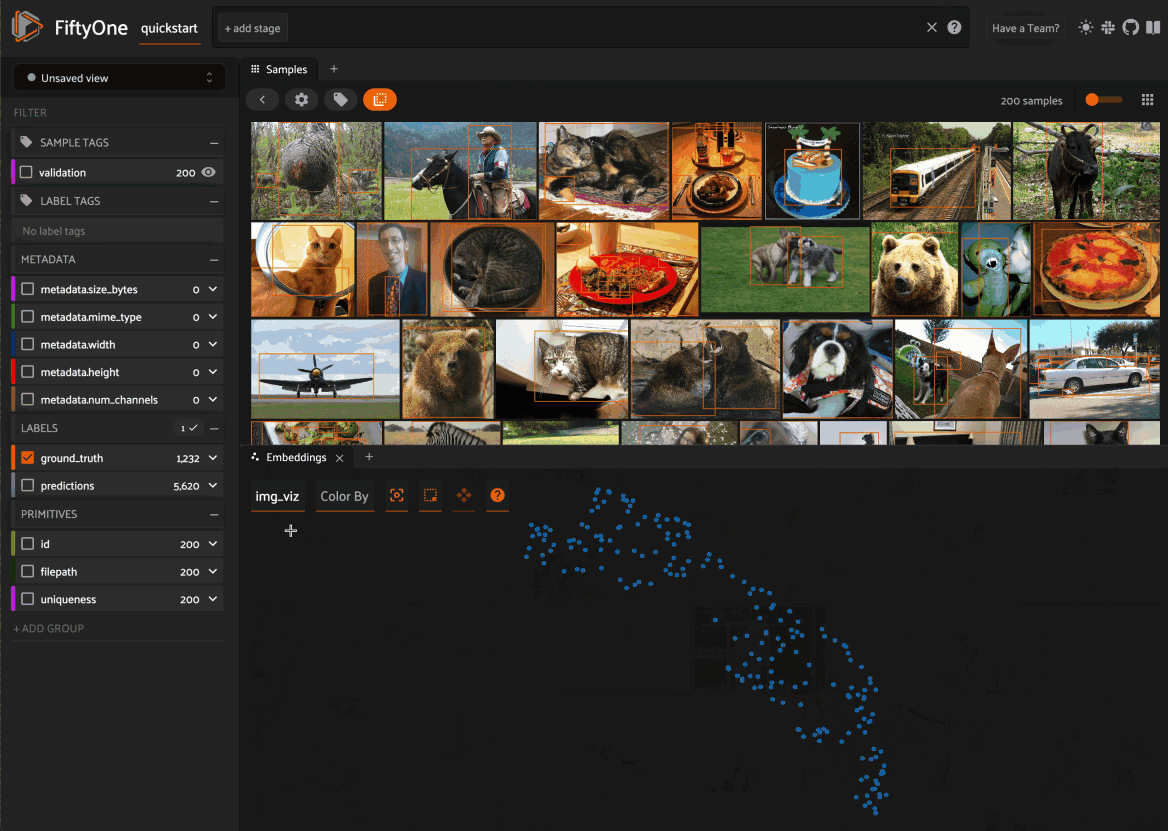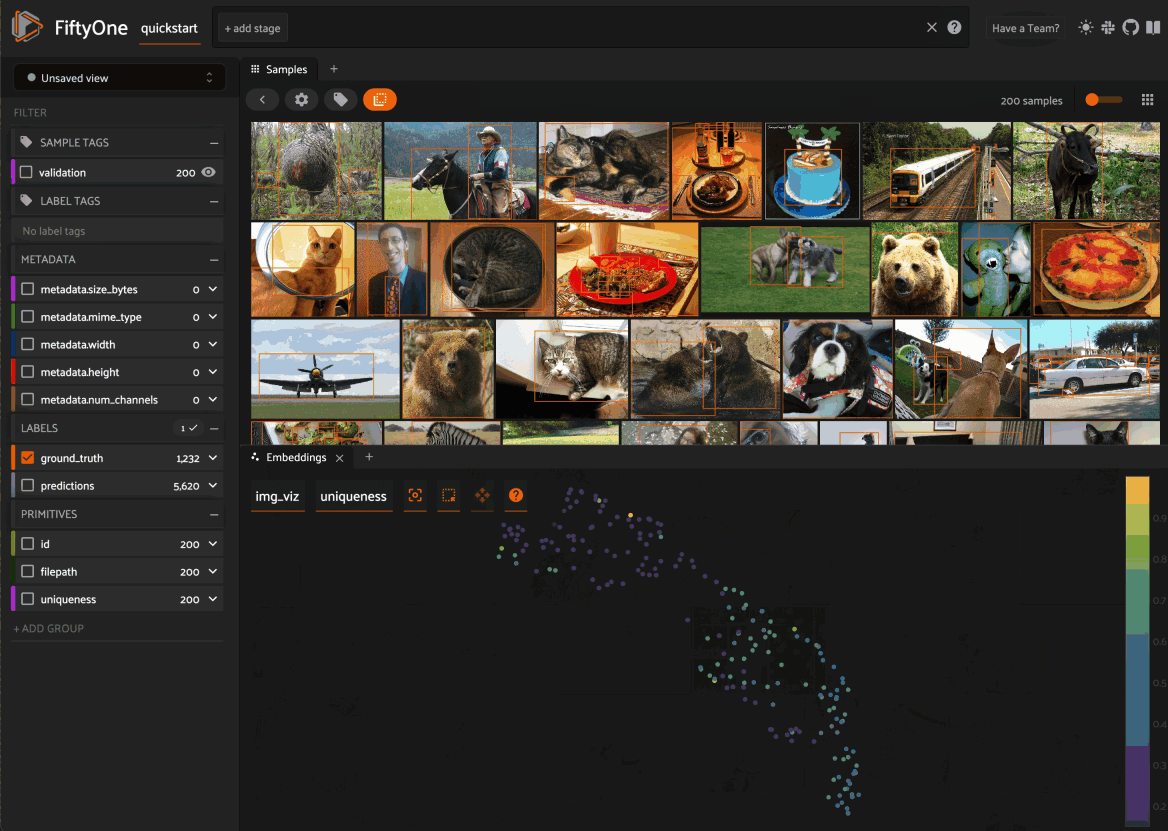
2. When you have multiple Panels open in a Space, you can use the divider buttons to split the Space either horizontally or vertically:
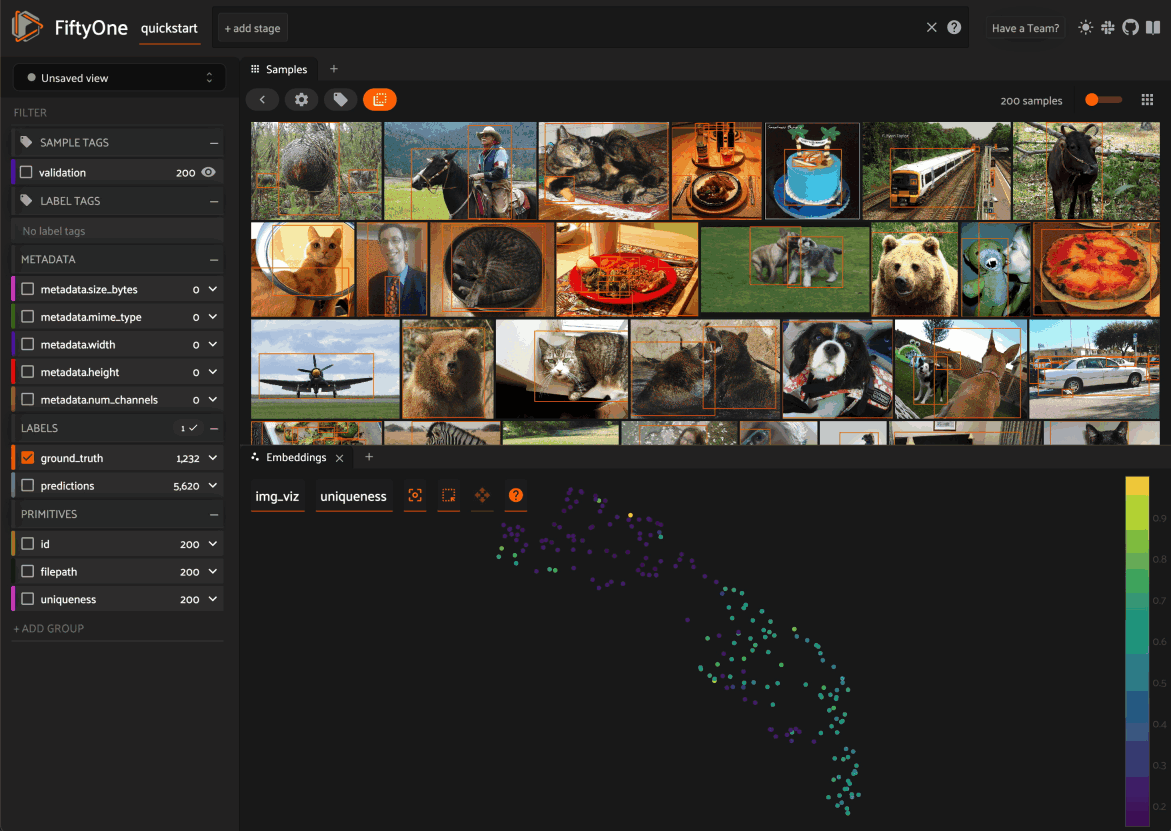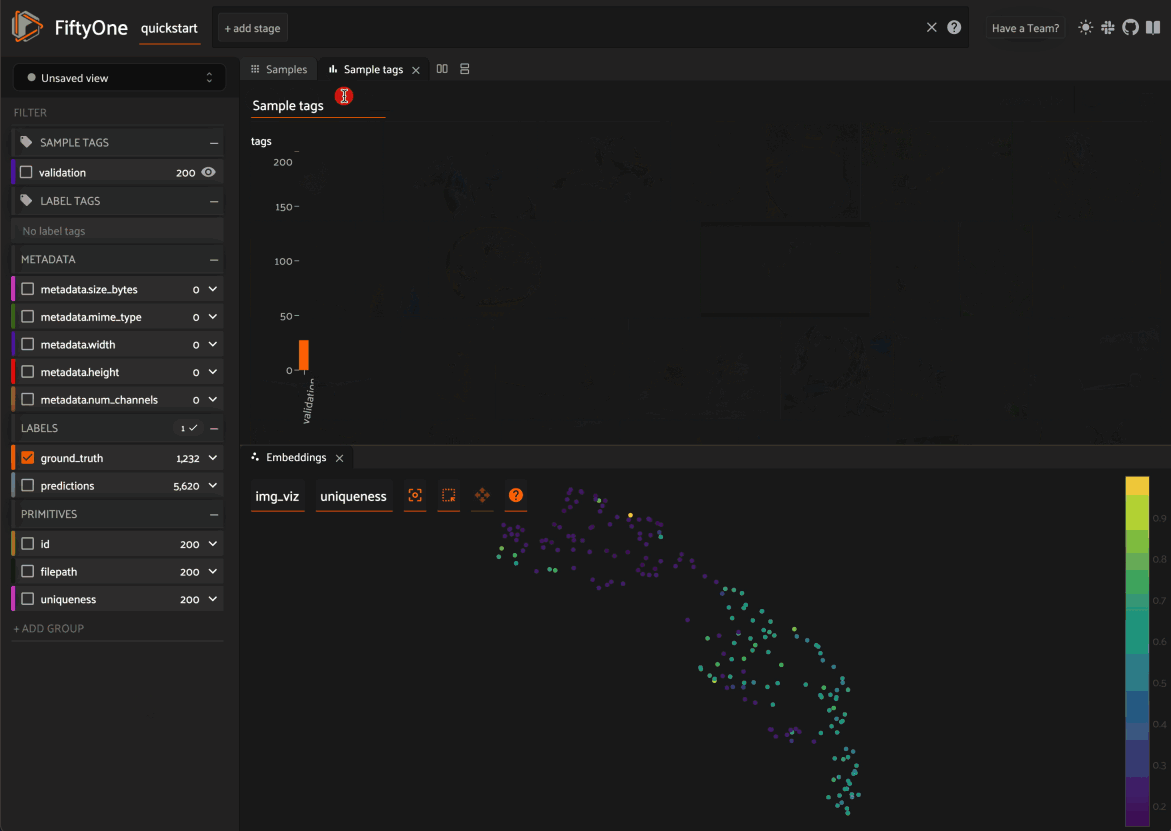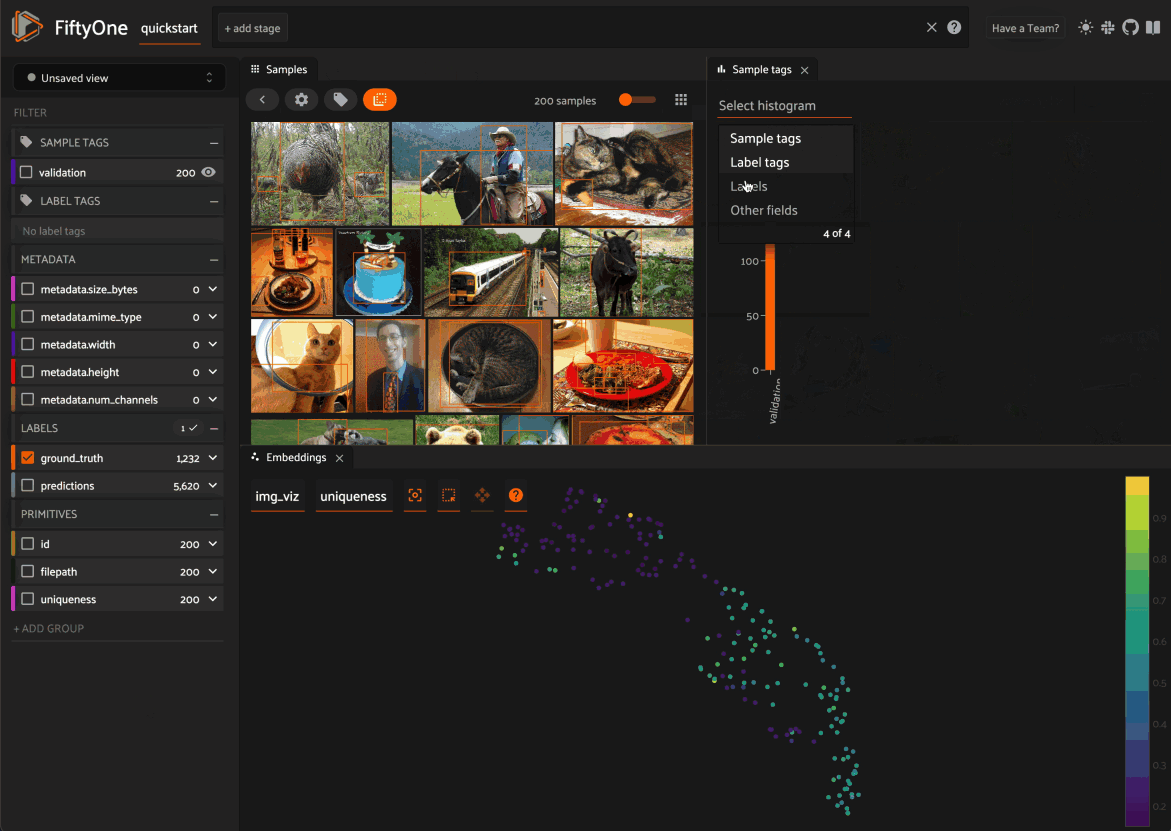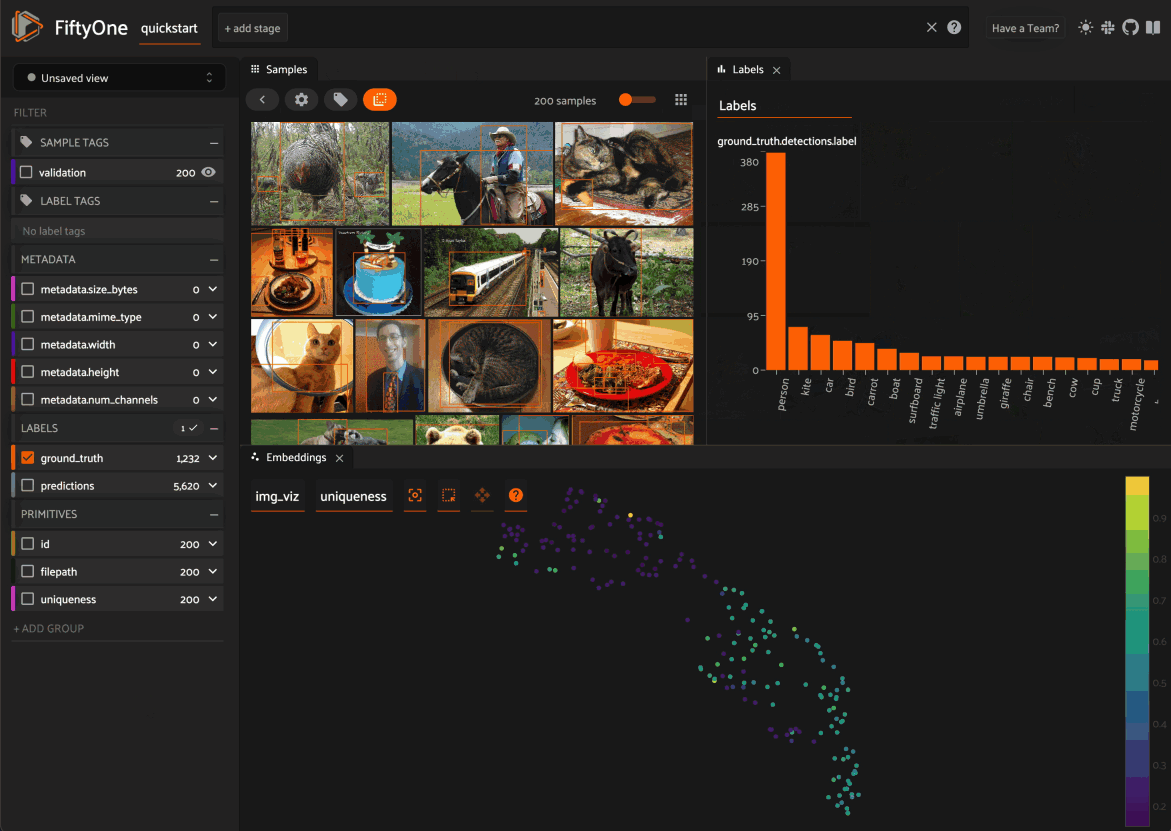
3. You can rearrange Panels at any time by dragging their tabs between Spaces, or close a Panel by clicking on its x icon:
You can also programmatically configure your Spaces layout from Python!
The code sample below shows an end-to-end example of loading a dataset, generating an embeddings visualization via the FiftyOne Brain, and launching the App with a customized Spaces layout that includes the Samples Panel, Histograms Panel, and Embeddings Panel with the Brain result already loaded:
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
fob.compute_visualization(dataset, brain_key="img_viz")
samples_panel = fo.Panel(
type="Samples",
pinned=True, # don’t allow closing
)
histograms_panel = fo.Panel(
type="Histograms",
state=dict(plot="Labels"), # open label fields by default
)
# Open the visualization we generated above by default
embeddings_panel = fo.Panel(
type="Embeddings",
state=dict(brainResult="img_viz", colorByField="metadata.size_bytes"),
)
spaces = fo.Space(
children=[
fo.Space(
children=[
fo.Space(children=[samples_panel]),
fo.Space(children=[histograms_panel]),
],
orientation="horizontal",
),
fo.Space(children=[embeddings_panel]),
],
orientation="vertical",
)
session = fo.launch_app(dataset, spaces=spaces)
Check out the docs for more information about using and configuring Spaces layouts.
In-App embeddings visualization
New in FiftyOne 0.19 (and enabled by the Spaces feature above), when you load a dataset in the App that contains an embeddings visualization, you can open the Embeddings Panel to visualize and interactively explore a scatterplot of the embeddings in the App.
For example, try running the code below to download a dataset, generate two embeddings visualizations on it, and launch the App:
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
# Image embeddings
fob.compute_visualization(dataset, brain_key="img_viz")
# Object patch embeddings
fob.compute_visualization(
dataset, patches_field="ground_truth", brain_key="gt_viz"
)
session = fo.launch_app(dataset)
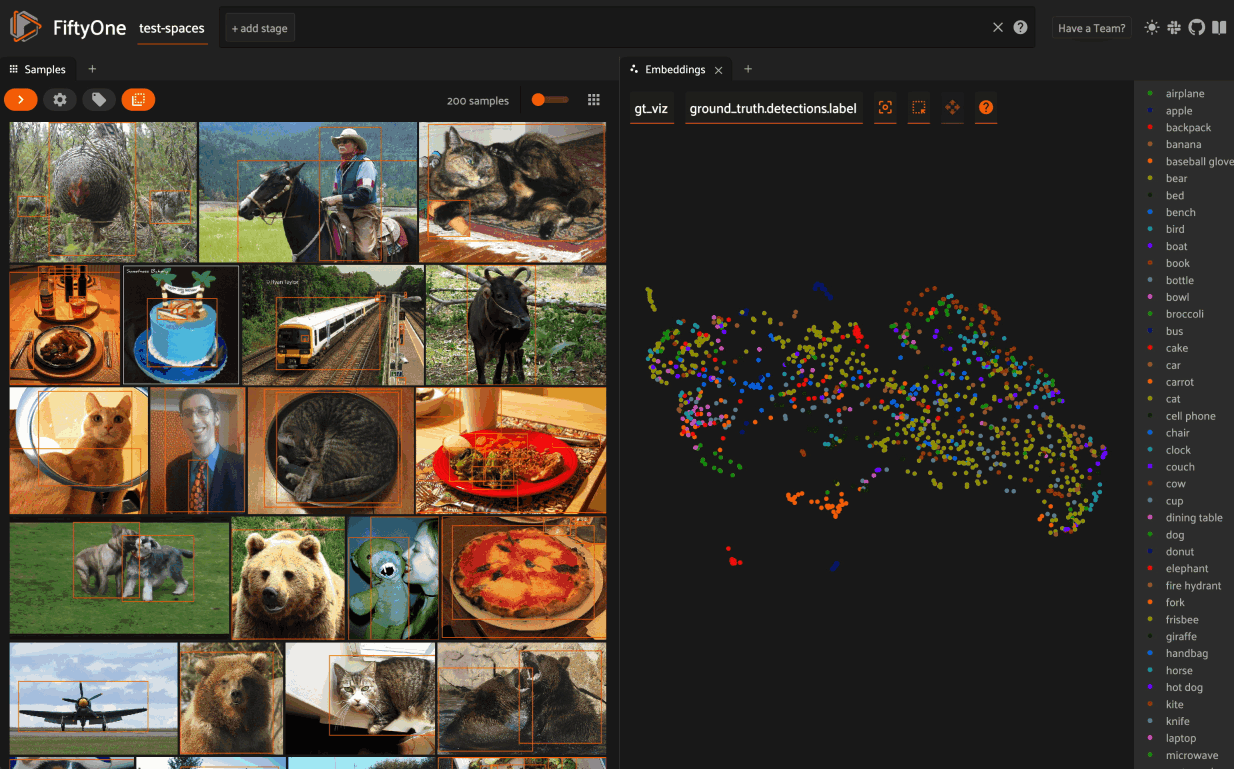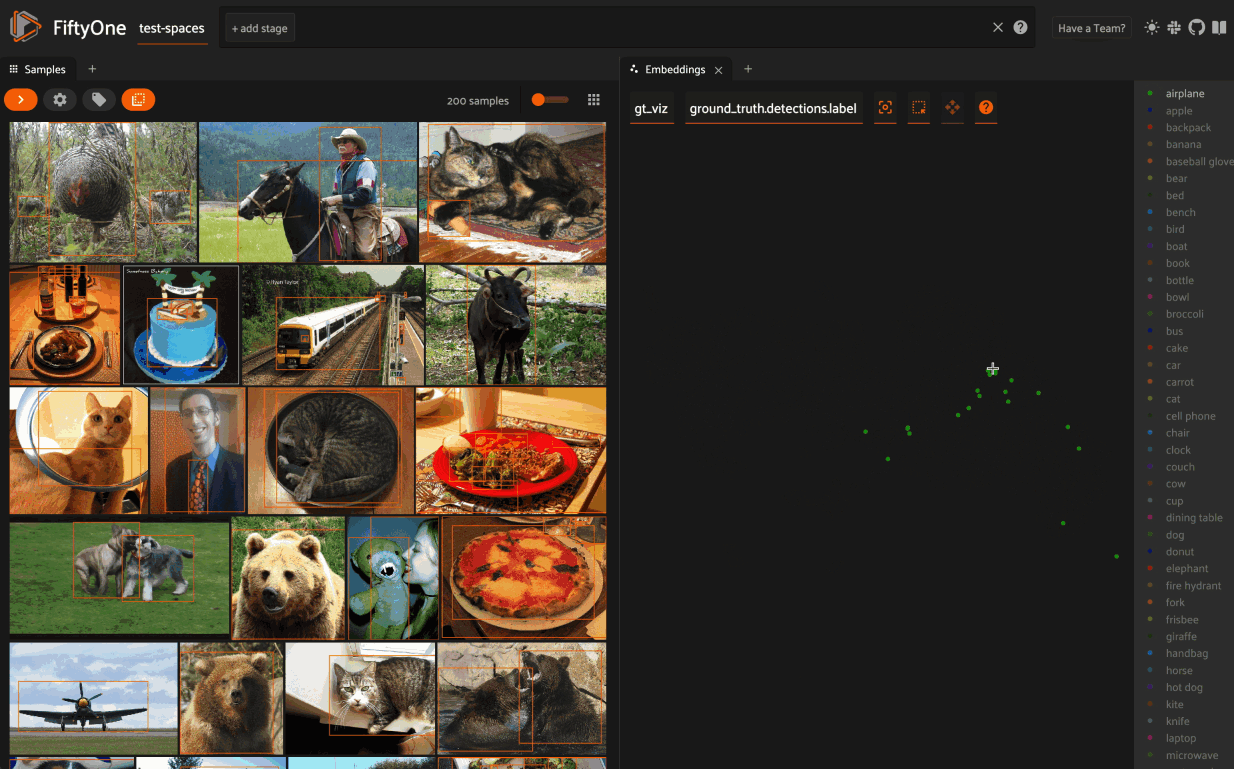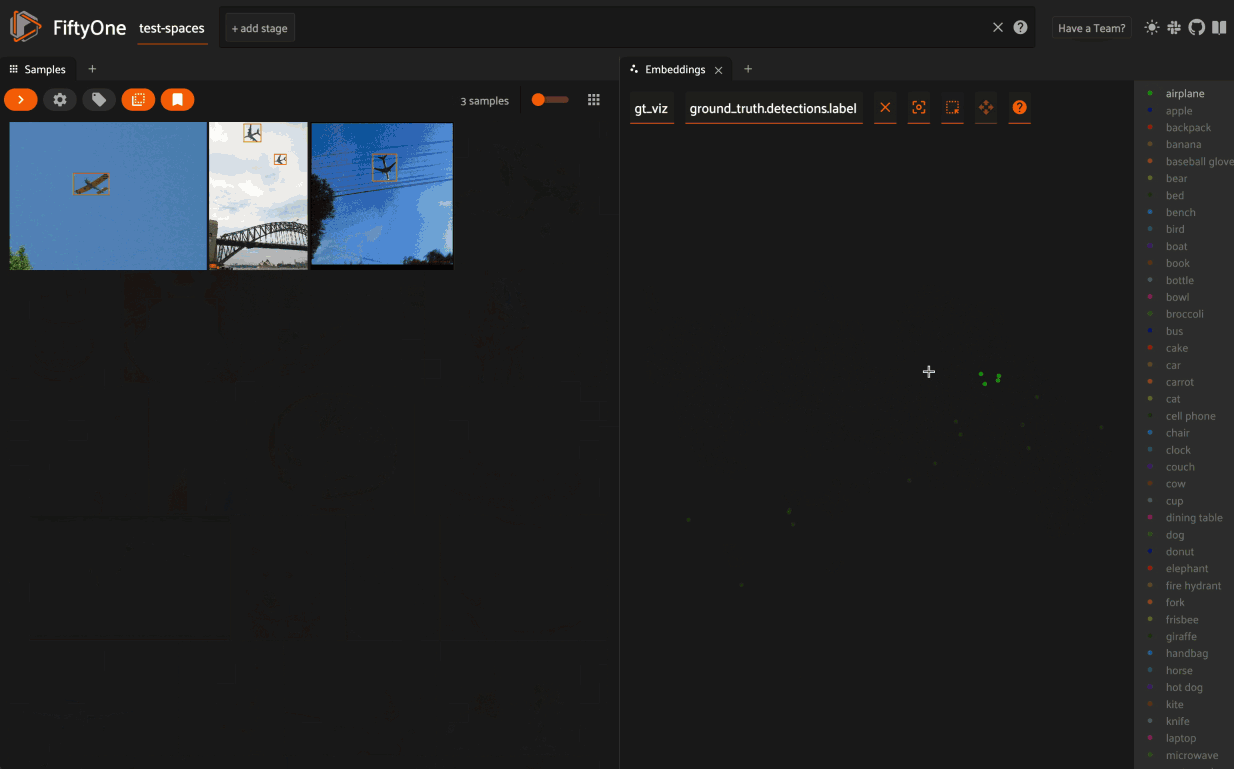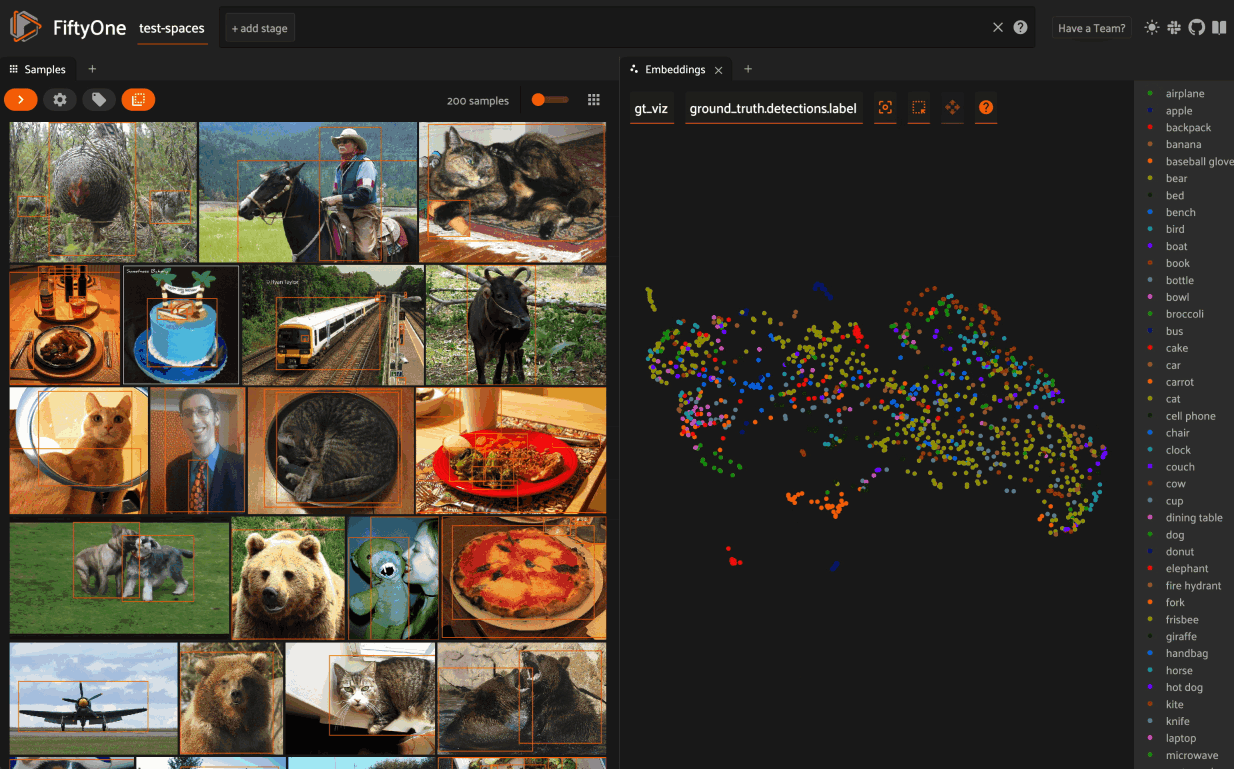
Then click on the + icon next to the Samples tab to open the Embeddings Panel and use the two menus in the upper-left corner of the Panel to configure your plot:
- Brain key: the Brain key associated with the compute_visualization() run to display
- Color by: an optional sample field (or label attribute, for patches embeddings) to color the points by
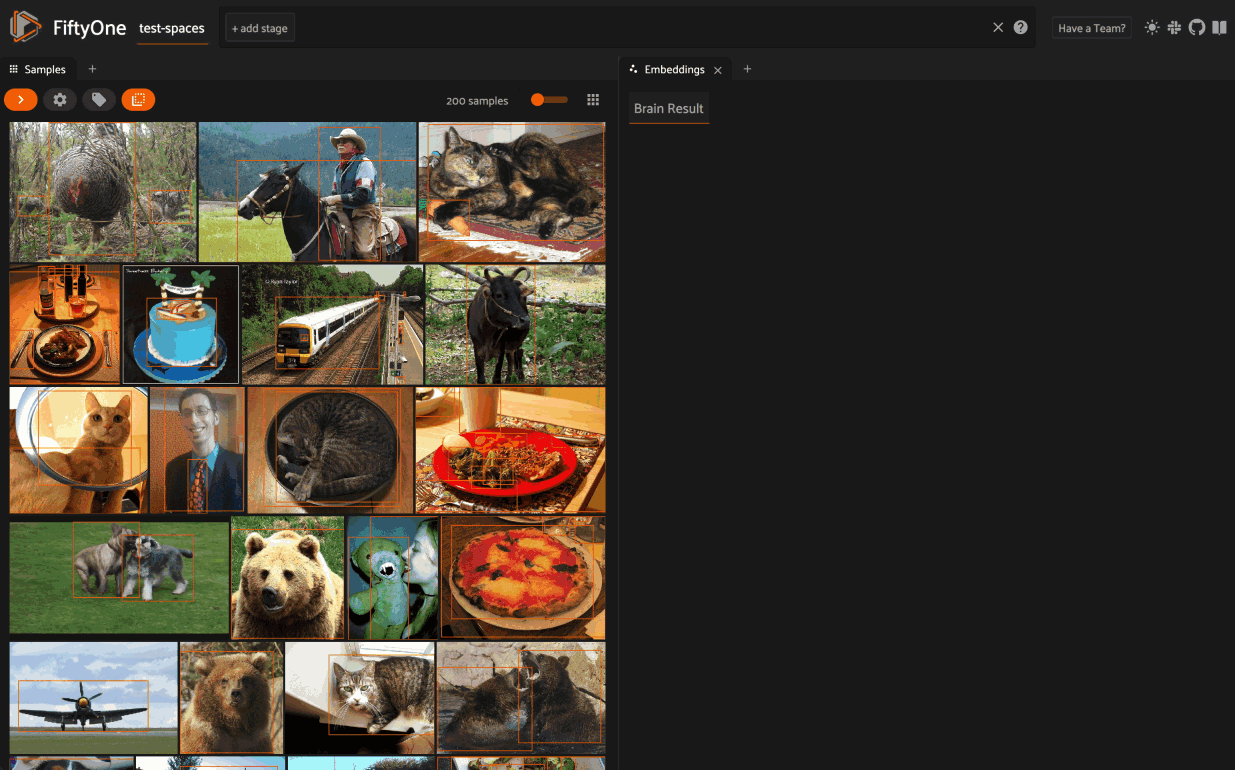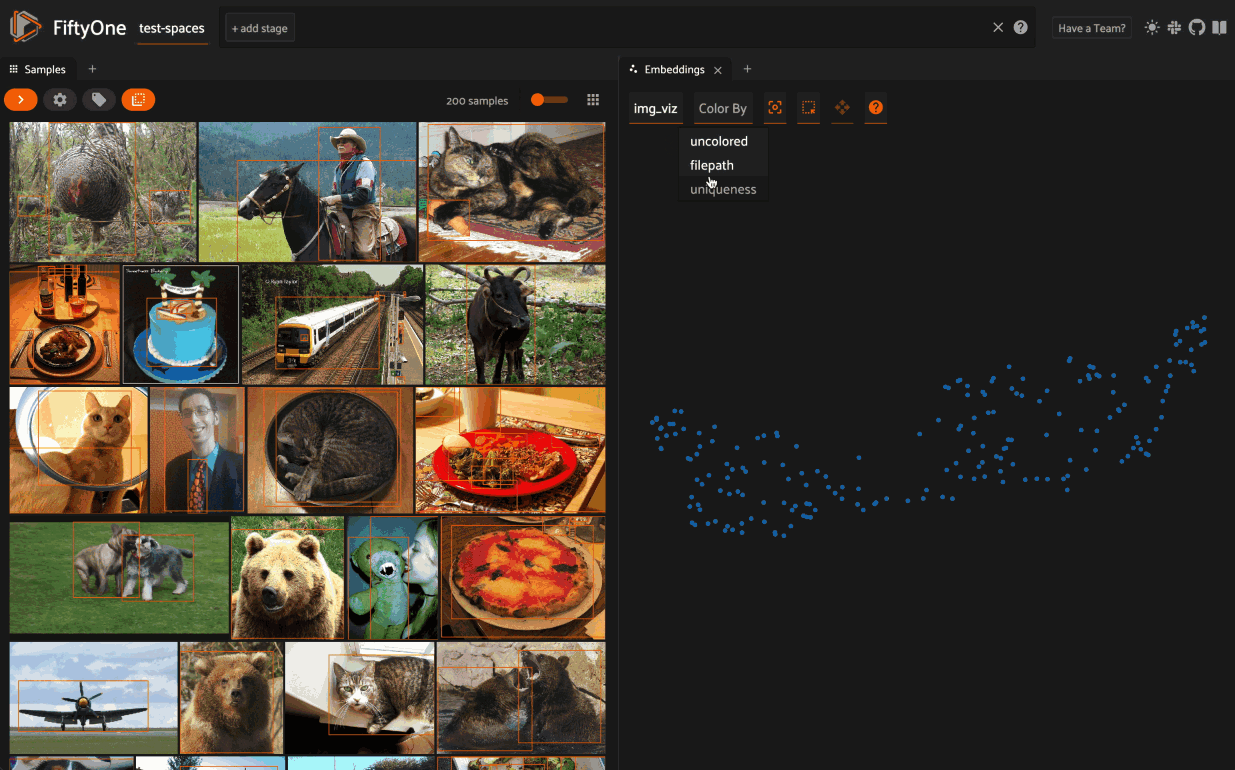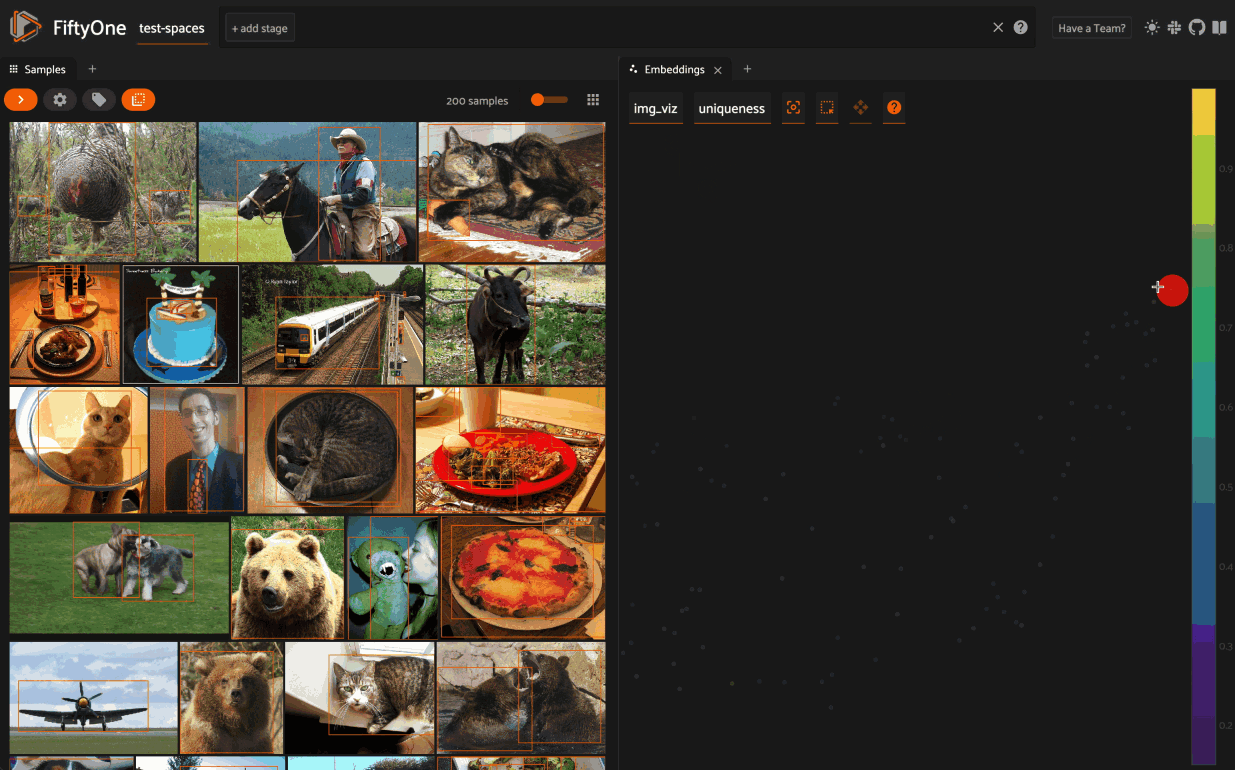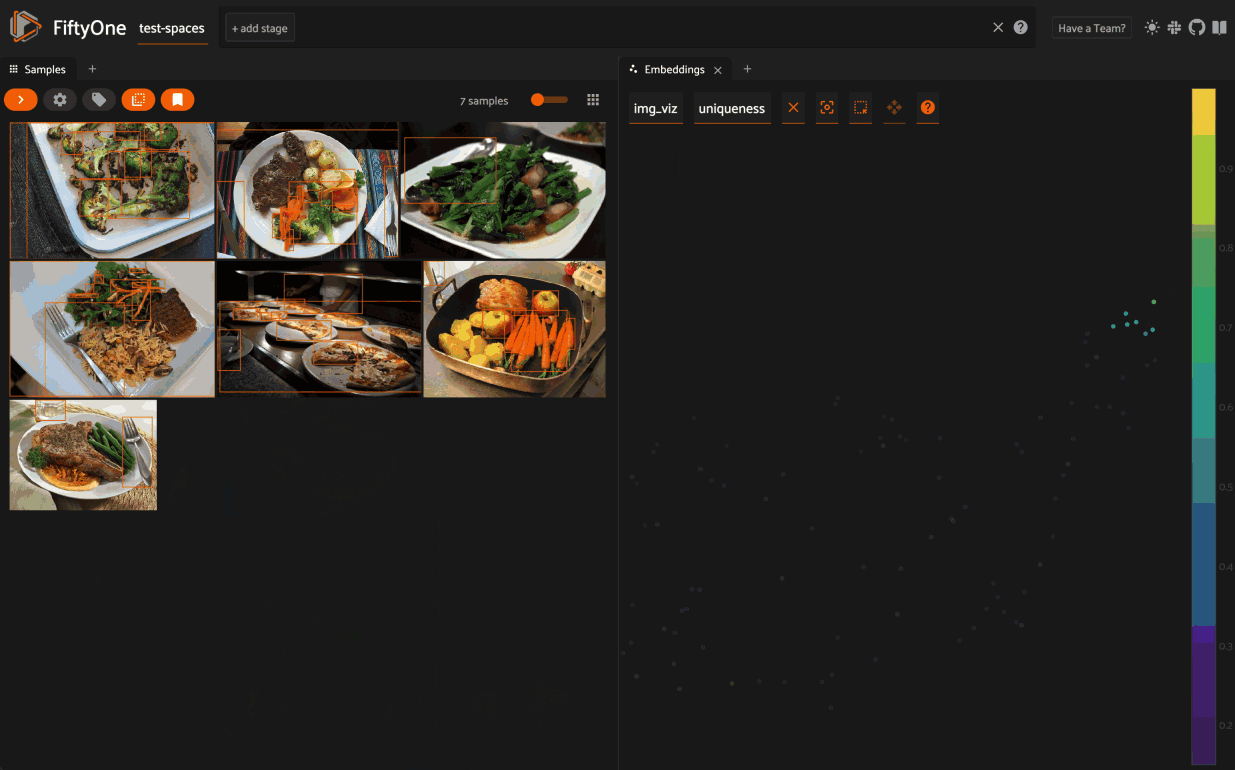
From there you can lasso points in the plot to show only the corresponding samples/patches in the Samples Panel:
The Embeddings Panel also provides a number of additional controls:
- Press the pan icon in the menu (or type g) to switch to pan mode, in which you can click and drag to change your current field of view
- Press the lasso icon (or type s) to switch back to lasso mode
- Press the locate icon to reset the plot’s viewport to a tight crop of the current view’s embeddings
- Press the x icon (or double click anywhere in the plot) to clear the current selection
When coloring points by categorical fields (strings and integers) with fewer than 100 unique classes, you can also use the legend to toggle the visibility of each class of points:
- Single click on a legend trace to show/hide that class in the plot
- Double click on a legend trace to show/hide all other classes in the plot
As demonstrated in the previous section, the Embeddings Panel can also be programmatically configured via Python.
Check out the docs for more information about working with embeddings visualizations in the App.
Saved views
In FiftyOne 0.19 you can use a new menu in the upper-left of the App to record the current state of the App’s view bar and filters sidebar as a saved view into your dataset:
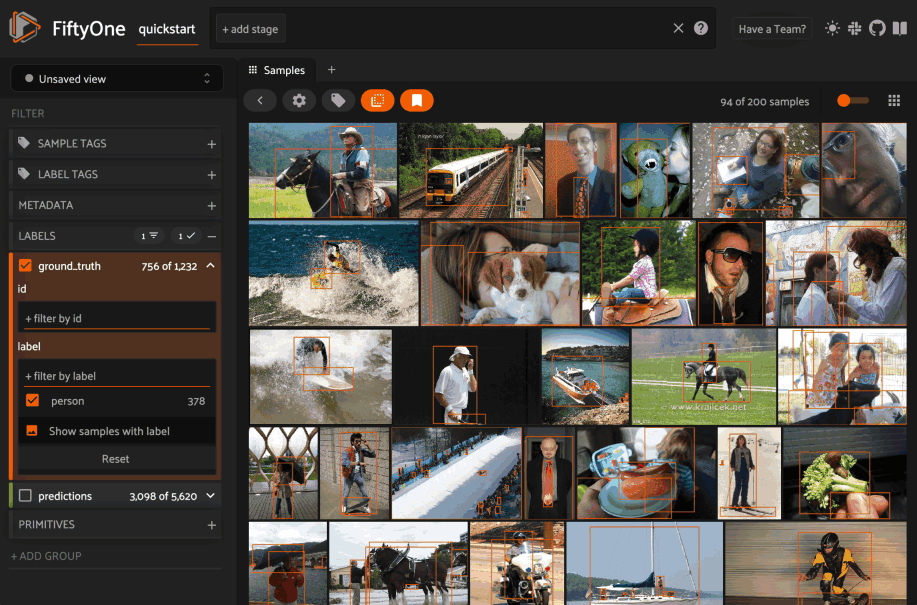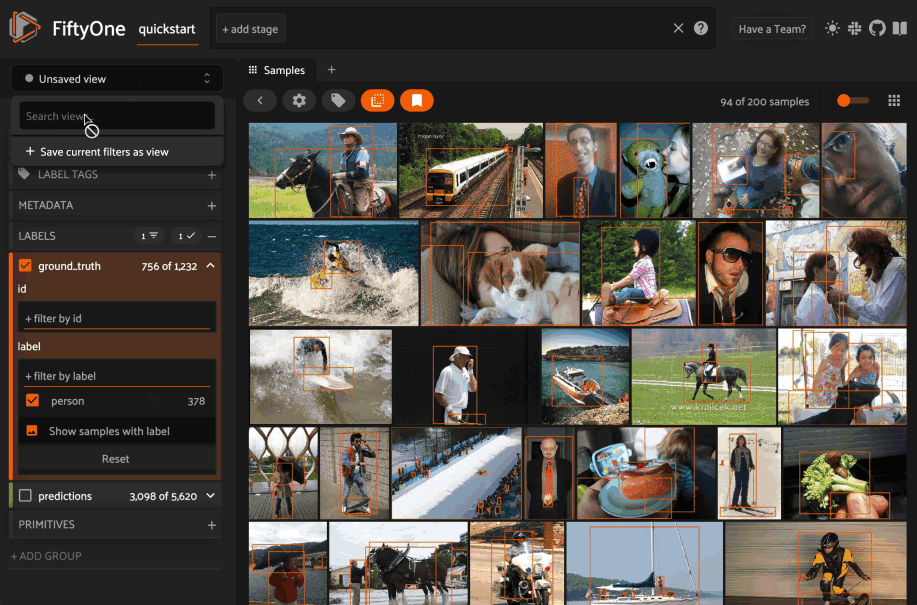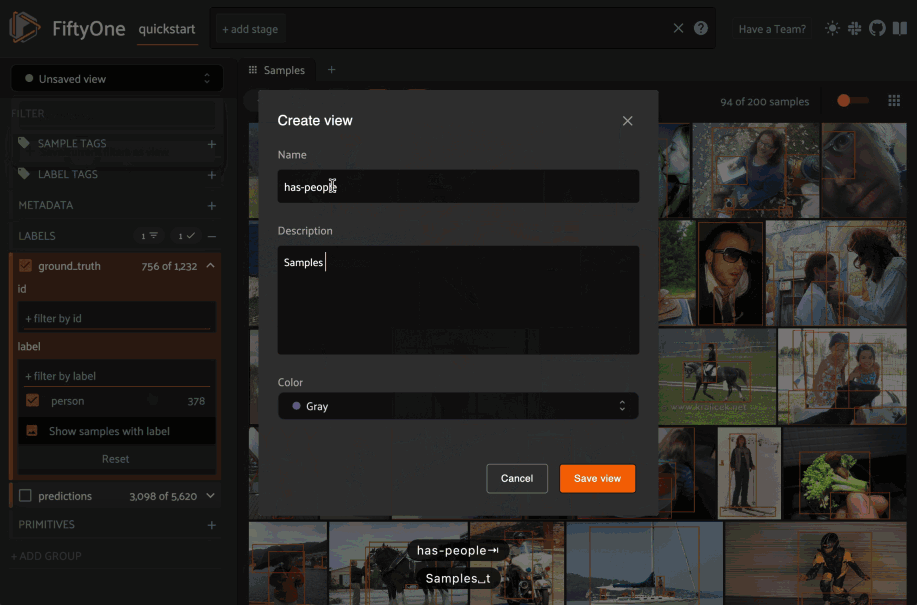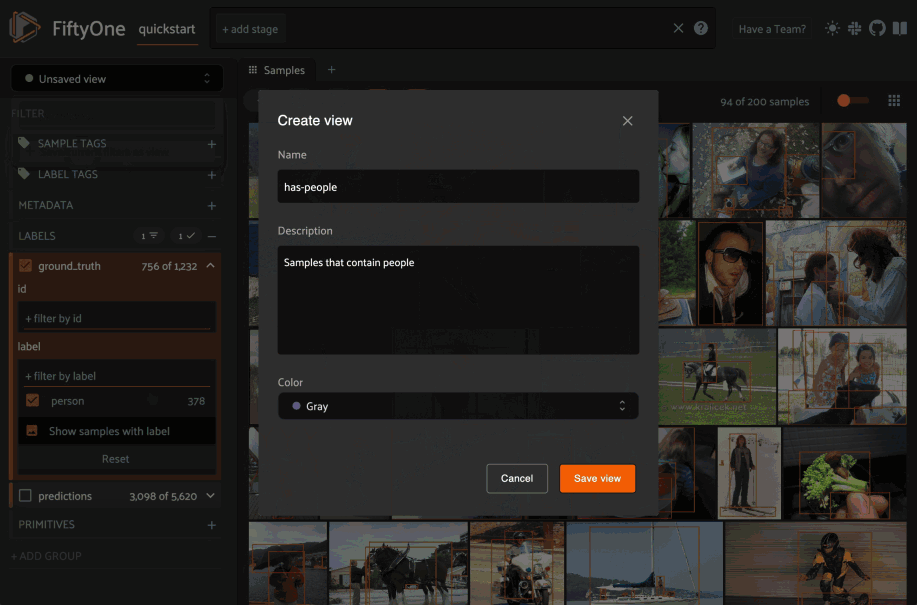
Saved views are persisted on your dataset under a name of your choice so that you can quickly load them in a future session via the UI or Python.
Saved views are a convenient way to record semantically relevant subsets of a dataset, such as:
- Samples in a particular state, e.g. with certain tag(s)
- A subset of a dataset that was used for a task, e.g. training a model
- Samples that contain content of interest, e.g. object types or image characteristics
Remember that saved views only store the rules used to extract content from the underlying dataset, not the actual content itself. You can save hundreds of views into a dataset if desired without worrying about storage space.
You can load a saved view at any time by selecting it from the saved view menu:
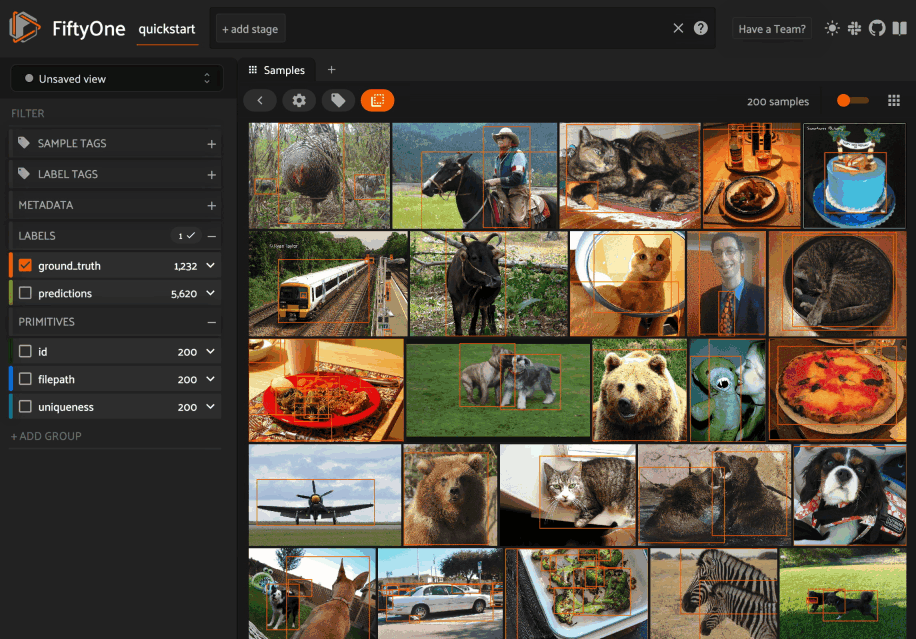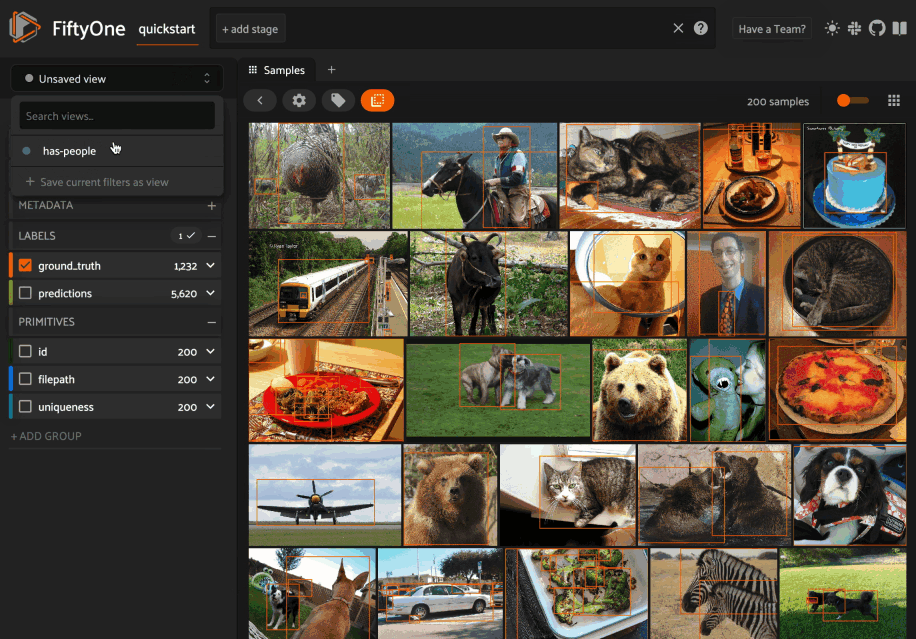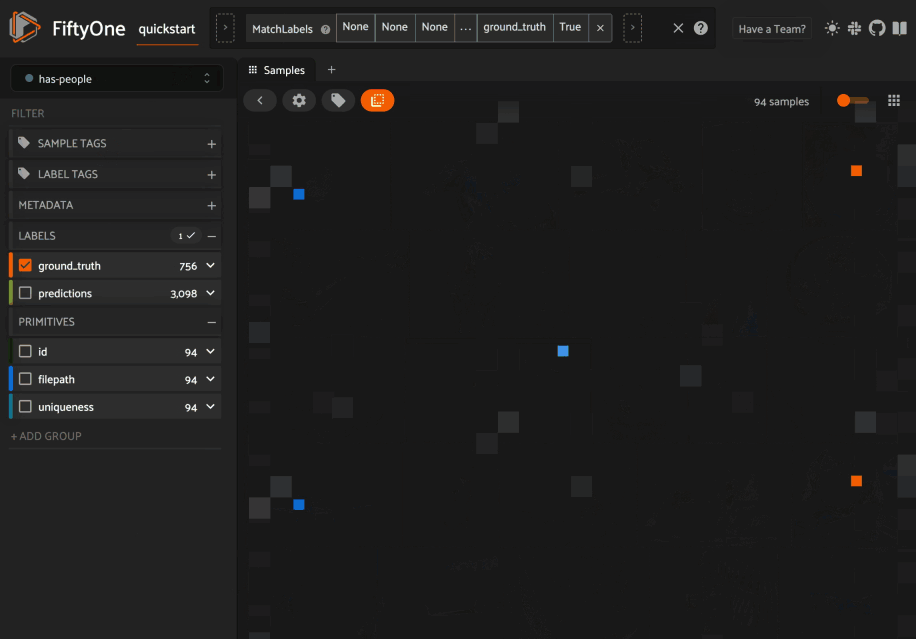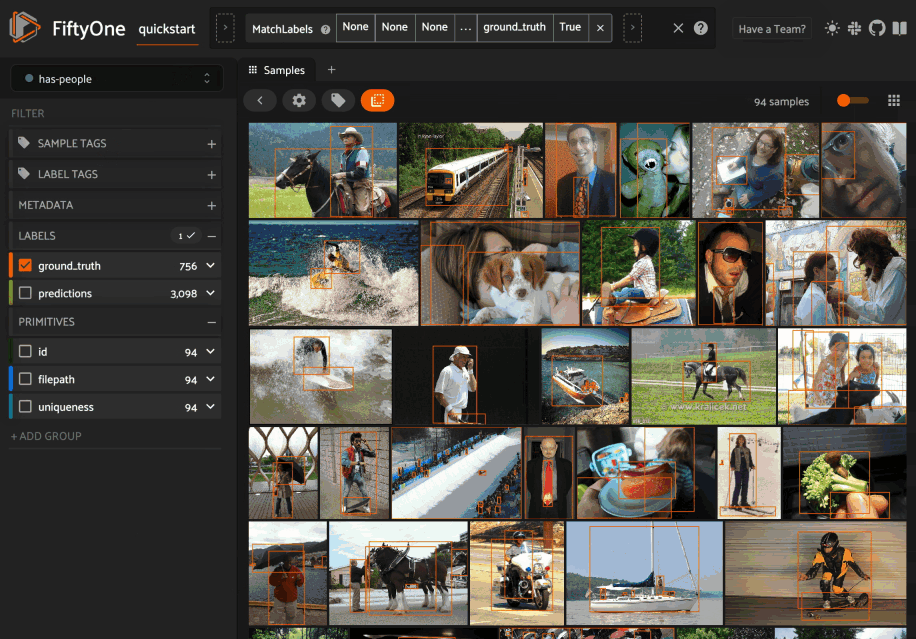
You can also edit or delete saved views by clicking on their pencil icon:
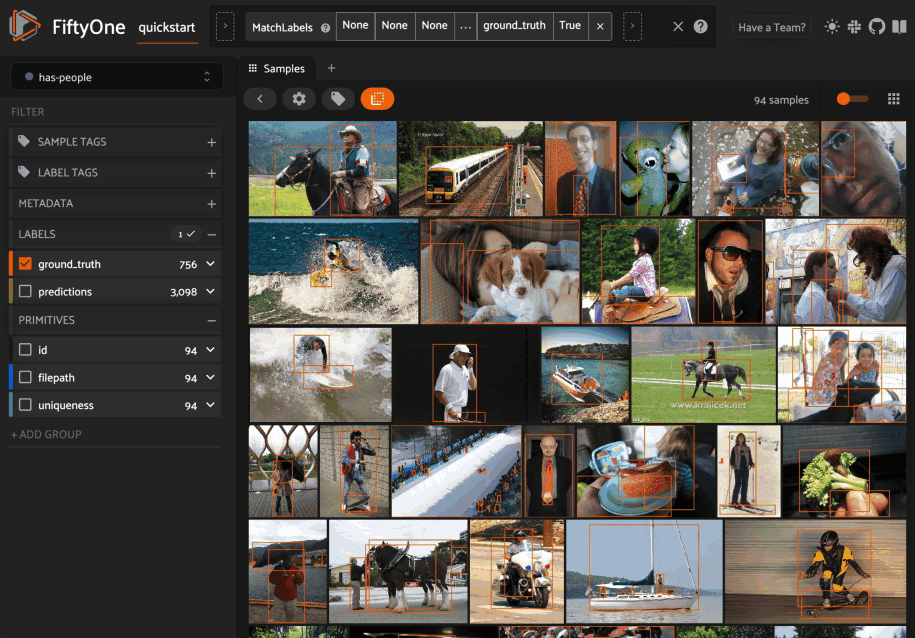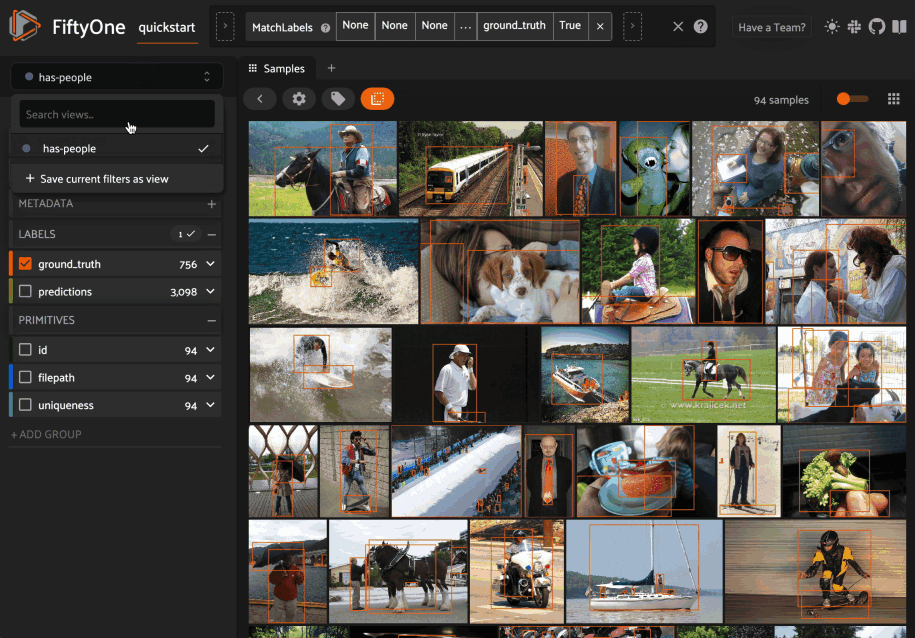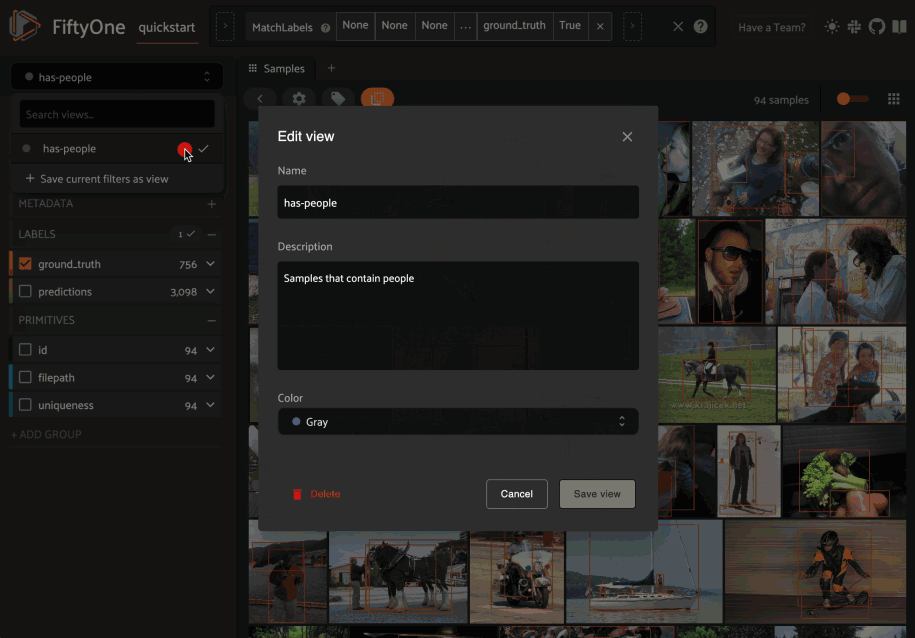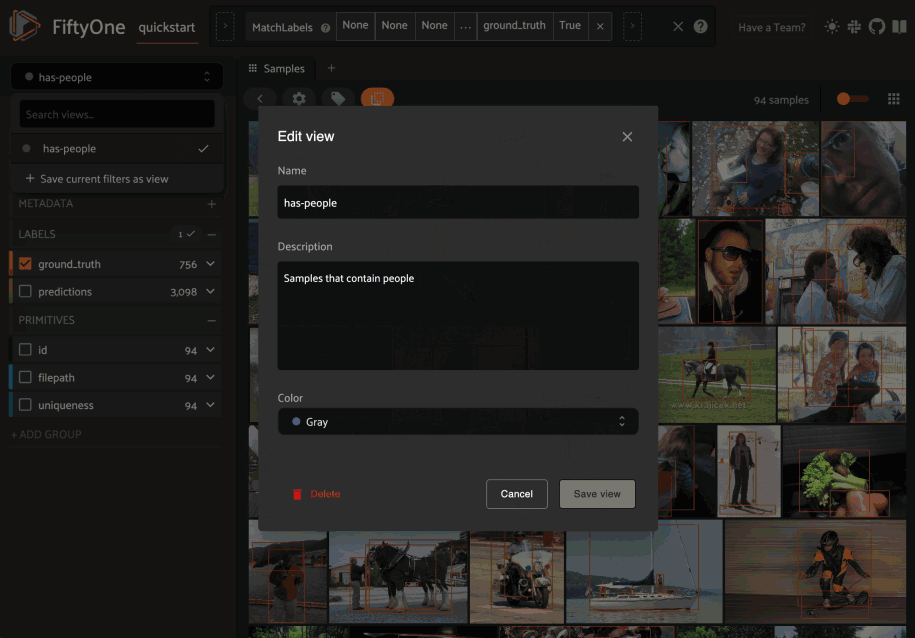
You can also programmatically create saved views via Python:
import fiftyone as fo
import fiftyone.zoo as foz
from fiftyone import ViewField as F
dataset = foz.load_zoo_dataset("quickstart")
dataset.persistent = True
# Create a view
cats_view = (
dataset
.select_fields("ground_truth")
.filter_labels("ground_truth", F("label") == "cat")
.sort_by(F("ground_truth.detections").length(), reverse=True)
)
# Save the view
dataset.save_view("cats-view", cats_view)
And load them in future sessions (including saved views created via the App):
import fiftyone as fo
dataset = fo.load_dataset("quickstart")
# Retrieve a saved view
cats_view = dataset.load_saved_view("cats-view")
print(cats_view)
Check out the docs for more information about using saved views in the App and Python.
On-disk segmentations
In prior FiftyOne versions, semantic segmentations and heatmaps could only be stored as compressed bytes directly in the database.
Now in FiftyOne 0.19, you can store segmentations and heatmaps as images on disk and store (only) their paths on your FiftyOne datasets, just like you do for the primary media of each sample:
import cv2 import numpy as np import fiftyone as fo # Example segmentation mask mask_path = "/tmp/segmentation.png" mask = np.random.randint(10, size=(128, 128), dtype=np.uint8) cv2.imwrite(mask_path, mask) sample = fo.Sample(filepath="/path/to/image.png") sample["segmentation"] = fo.Segmentation(mask_path=mask_path) print(sample)
Segmentation masks can be stored in either of these formats on disk:
- 2D 8-bit or 16-bit images
- 3D 8-bit RGB images
When you load datasets with segmentation fields containing 2D masks in the App, each pixel value is rendered as a different color from the App’s color pool so that you can visually distinguish the classes. When you view RGB segmentation masks in the App, the mask colors are always used.
You can also store semantic labels for your segmentation fields on your dataset. Then, when you view the dataset in the App, label strings will appear in the App’s tooltip when you hover over pixels.
If you are working with 2D segmentation masks, specify target keys as integers:
import fiftyone as fo
dataset = fo.Dataset()
dataset.default_mask_targets = {1: "cat", 2: "dog"}
And if you are working with RGB segmentation masks, specify target keys as RGB hex strings:
import fiftyone as fo
dataset = fo.Dataset()
dataset.default_mask_targets = {"#499CEF": "cat", "#6D04FF": "dog"}
The entire FiftyOne API was upgraded to support on-disk and/or RGB segmentations:
- Evaluation via evaluate_segmentations() natively supports on-disk and/or RGB segmentations
- The apply_model() method now has an optional output_dir argument specifying where to store semantic segmentation inferences as images on disk
- There’s a new export_segmentations() utility for conveniently exporting in-database segmentations to on-disk images
- Other new utilities like transform_segmentations() are now available for manipulating segmentations
Check out the docs for more information about adding on-disk segmentations to your FiftyOne datasets.
New UI filtering options
We’re constantly improving and extending the filtering options available natively in the App to provide more powerful and intuitive ways to query datasets. In FiftyOne 0.19, we added a new selector that allows you to fine-tune your filters in the sidebar.
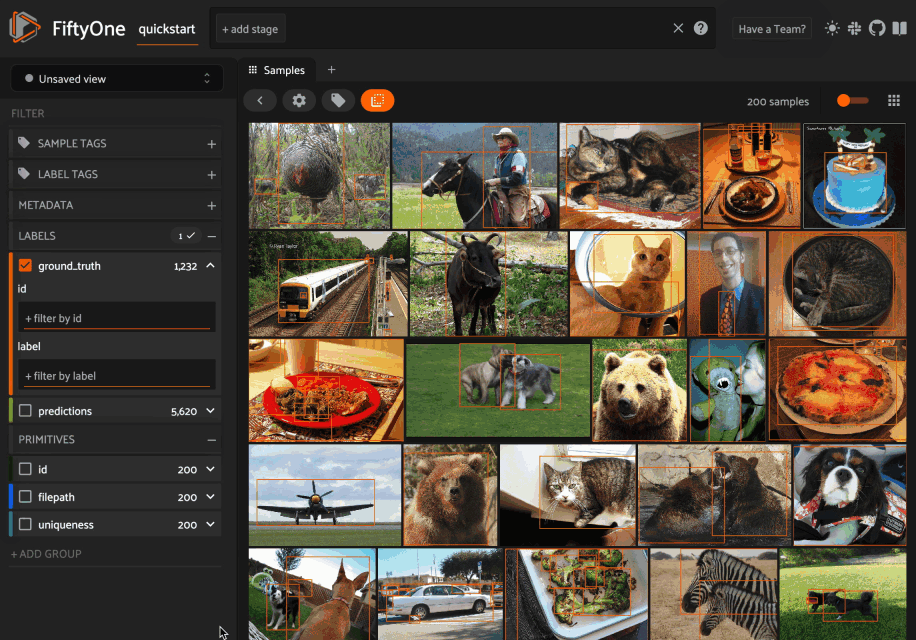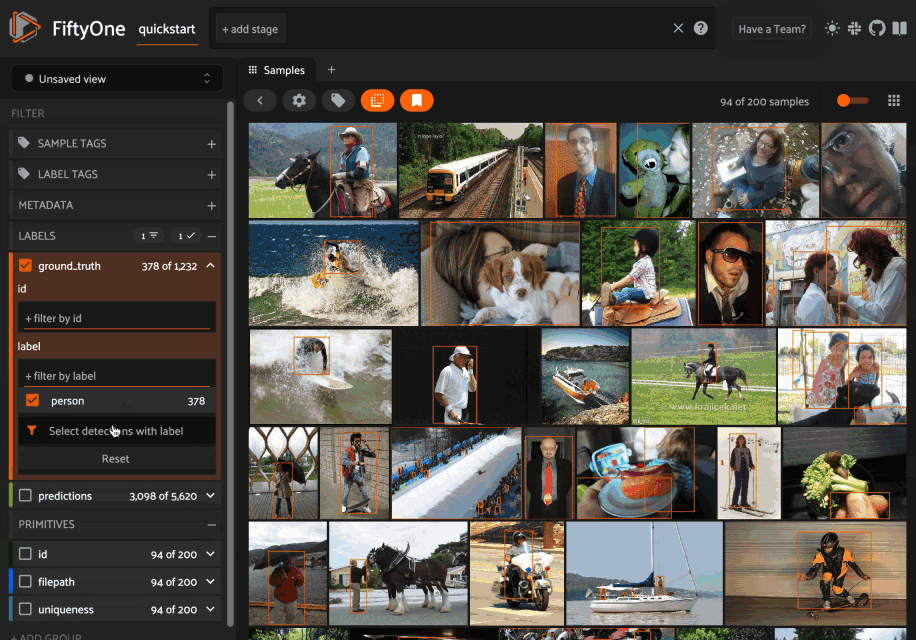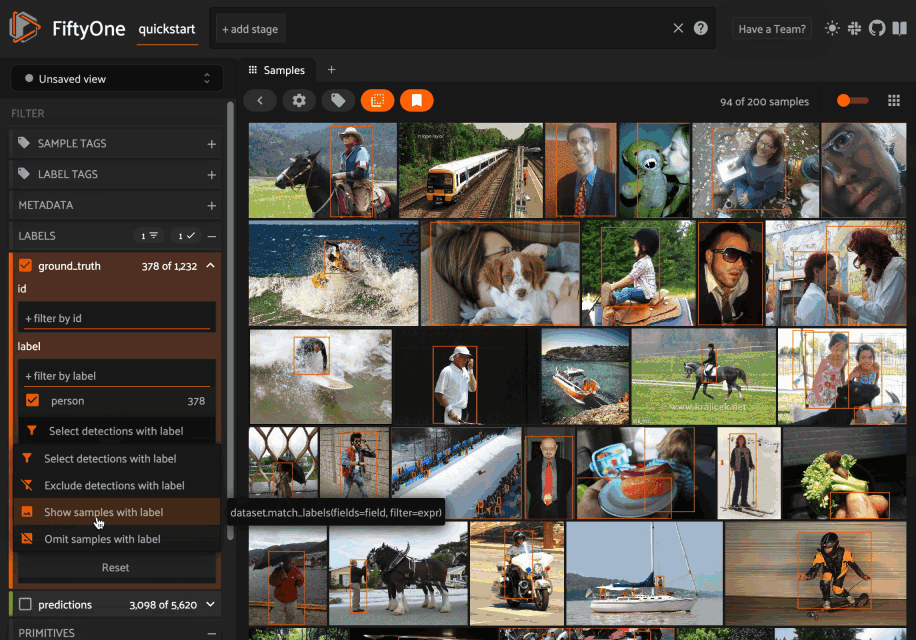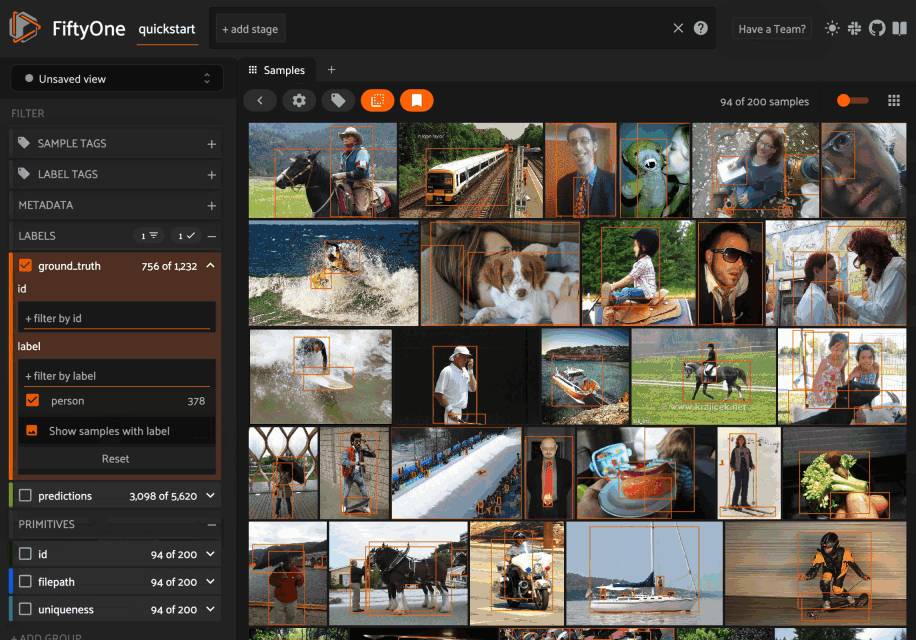
For example, when filtering by the label attribute of a Detections field, you can choose between the following options:
- (default): Filter to only show objects with the specified labels (omitting samples with no matching objects)
- Exclude objects with the specified labels
- Show samples that contain the specified labels (without filtering)
- Omit samples that contain the specific labels
All applicable filtering options are available from both the grid view and the sample modal, and for all field types, including top-level fields and dynamic label attributes!
FiftyOne Teams documentation
Exciting news! Documentation for FiftyOne Teams is now publicly available at https://docs.voxel51.com/teams.
FiftyOne Teams enables multiple users to securely collaborate on the same datasets and models, either on-premises or in the cloud, all built on top of the open source FiftyOne workflows that you’re already relying on. Look interesting? Schedule a demo to get started with FiftyOne Teams yourself.
Community contributions
Shoutout to the following community members who contributed to this release!
- kalpit-S contributed #2354 – added help link for Mapbox configuration in App
- flakeice contributed #2359 – fix bug when loading datasets in VOC format
- Rustem Galiullin contributed #2353 – add support for custom CVAT task names
- Rustem Galiullin contributed #2373 – exact frame count support
- Oguz-hanoglu contributed #2297 – improved explanation of sidebar modes in the App
- Jamie Werther contributed #2427 – show only supported eval keys
- Nikita Manovich contributed #2478 – Fix several CVAT links
- Chris Hall contributed #2561 – updated CVAT links
FiftyOne community updates
The FiftyOne community continues to grow!
- 1,300+ FiftyOne Slack members
- 2,500+ stars on GitHub
- 3,000+ Meetup members
- Used by 245+ repositories
- 56+ contributors

