
Welcome to Voxel51’s weekly digest of the latest trending AI, machine learning and computer vision news, events and resources! Subscribe to the email version.
📰 The Industry Pulse
NVIDIA & Mistral AI Unleash Powerful, Efficient Language Model

NVIDIA recently announced the release of Mistral-NeMo-Minitron-8B, a new foundation model developed in collaboration with Mistral AI. This 8 billion parameter model demonstrates exceptional performance across various natural language processing tasks.
- Origins: This 8B parameter model is derived from the larger Mistral NeMo 12B model using a combination of width pruning and knowledge distillation.
- Performance: Mistral-NeMo-Minitron 8B demonstrates state-of-the-art accuracy for its size, outperforming other 8B models, such as Llama-3.1 8B and Gemma 7B, on various benchmarks.
- Efficiency: The model’s development highlights the efficiency of iterative pruning and distillation, reducing training costs compared to training from scratch.
- Techniques: The development process involved:
- Teacher fine-tuning: The original Mistral NeMo 12B model was fine-tuned on a specific dataset to correct for distribution shifts.
- Width-only pruning: The model size was reduced by pruning the embedding and MLP intermediate dimensions while preserving the number of attention heads and layers.
- Distillation: The pruned model was then trained using knowledge distillation from the fine-tuned teacher model.
Read the technical blog for more details.
Phi-3.5: Microsoft’s Open Challenge to OpenAI and Google
Moving beyond its OpenAI partnership, Microsoft releases three new Phi-3.5 models, demonstrating its independent AI development capabilities. All three models are open-source and licensed under MIT, allowing for commercial use and modification.
Model Breakdown:
- Size: 3.82 billion parameters
- Strengths: Lightweight, designed for resource-constrained environments, excels in reasoning tasks like code generation, math, and logic.
- Notable Performance: Strong in multilingual and multi-turn conversations, outperforms similarly sized models on the RepoQA benchmark for code understanding.
2. Phi-3.5 MoE (Mixture of Experts):
- Size: 41.9 billion parameters (6.6 billion active)
- Strengths: Combines multiple specialized models for enhanced performance across diverse reasoning tasks, including code, math, and multilingual language understanding.
- Notable Performance: It exceeds larger models on certain benchmarks, like RepoQA, and outperforms GPT-4o mini on the 5-shot MMLU across various subjects.
- Size: 4.15 billion parameters
- Strengths: The multimodal model integrates text and image processing and is suitable for image understanding, OCR, chart/table comprehension, and video summarization.
- Training Data: Utilizes a blend of synthetic and filtered public datasets emphasizing high-quality, reasoning-focused data.
Training Details:
- Phi-3.5 Mini Instruct: 3.4 trillion tokens, 512 H100-80G GPUs, 10 days.
- Phi-3.5 MoE: 4.9 trillion tokens, 512 H100-80G GPUs, 23 days.
- Phi-3.5 Vision Instruct: 500 billion tokens, 256 A100-80G GPUs, 6 days.
Microsoft has also released one of the most comprehensive cookbooks I’ve ever seen. It’s full of notebook tutorials and examples of using the Phi models. Check it out here.
UniBench Brings Order to Benchmark Chaos

UniBench is a comprehensive evaluation framework for vision-language models (VLMs) that addresses the fragmented landscape of VLM benchmarks. Some interesting bits about the framework are:
- UniBench implements 53 benchmarks covering various capabilities, from object recognition to spatial awareness and reasoning.
- The framework evaluates nearly 60 publicly available VLMs trained on up to 12.8B samples.
- Key findings from UniBench evaluations:
- Scaling training data or model size improves performance on many tasks but offers little benefit for reasoning and relations.
- Even leading VLMs struggle with simple tasks like digit recognition and counting.
- Data quality matters more than quantity for improving model performance.
- Tailored learning objectives can help where scaling does not.
- UniBench provides a distilled set of representative benchmarks that can run in 5 minutes on a single GPU, offering a fast yet comprehensive evaluation pipeline.
- The framework is designed to be easily extendable, allowing researchers to add new models and benchmarks.
- UniBench aims to guide researchers in navigating the complex landscape of VLM benchmarks, enabling more systematic and efficient evaluations of progress in the field.
Check out the GitHub repo here. If this interests you and you want me to do a tutorial, just reply to the email and let me know!
💎 GitHub Gems: FiftyOne v0.25.0 is here!
Upgrade now: pip install –upgrade fiftyone
Headline Features:
- Python Panels: Build custom App panels with a simple Python interface. Includes built-in components for information display, tutorials, interactive graphs, triggering operations, and more.
- Custom Dashboards: Create no-code dashboards to visualize dataset statistics and model performance.
- SAM 2 Integration: Leverage Segment Anything 2 directly within FiftyOne for automatic object segmentation in images and videos.
- Elasticsearch Integration: Connect to your Elasticsearch cluster for scalable text and image searches across your datasets.
- Image Representativeness Analysis: Identify your datasets’ most common and uncommon image types.
Model Zoo Upgrades:
- New Models: YOLOv10, RT-DETR, and YOLOv8 classification models added.
- Enhanced Functionality: Store object track IDs from Ultralytics models and utilize GPU inference with Hugging Face Transformers models.
Additional Goodies:
- Direct Linking: Copy and paste URLs to directly access specific samples or groups within the FiftyOne App.
- Streamlined Annotations: Annotate directly from frame and clip views.
- JPG Heatmap Support: Visualize heatmaps stored in JPG format.
Read the full release notes here, and the blog here.
📖 Good Read: Evaluating the Effectiveness of LLM-Evaluators (aka LLM-as-Judge)
Eugene Yan released another great blog post. It’s a huge piece (an estimated 50 minute reading time) and I’ve got my key takeaways for you here 👇🏼
LLM-evaluators, also known as “LLM-as-a-Judge”, are gaining traction due to the limitations of traditional evaluation methods in handling complex LLM tasks.
LLM-evaluators are large language models used to evaluate the quality of responses generated by other LLMs. They offer a potentially scalable and cost-effective alternative to human evaluation. LLM-evaluators can be used for various tasks, including:
- Assessing the harmfulness and toxicity of outputs
- Evaluating summarization quality
- Checking factual consistency and detecting hallucinations
- Judging question-answering performance
- Critiquing code generation
Evaluation Approaches
There are three main approaches to using LLM-evaluators:
- Direct scoring: Evaluating a single response without comparison
- Pairwise comparison: Choosing the better of two responses
- Reference-based evaluation: Comparing the response to a gold reference
Performance and Limitations
- LLM-evaluators can achieve a high correlation with human judgments on some tasks
- They often outperform traditional metrics like ROUGE or BERTScore
- However, they may struggle with more subjective or nuanced evaluations
- Biases such as position bias, verbosity bias, and self-enhancement bias have been observed
Best Practices
- Use specific, well-defined criteria for evaluation
- Consider using Chain-of-Thought (CoT) reasoning to improve performance
- Be aware of potential biases and limitations
- Combine LLM-evaluators with other evaluation methods for a more robust assessment
Future Directions
- Developing more specialized and fine tuned LLM-evaluators
- Improving alignment with human preferences and expert judgments
- Addressing biases and enhancing generalizability across different tasks
While LLM-evaluators show promise in automating and scaling evaluation tasks, they should be used judiciously and with other evaluation methods to ensure a reliable and comprehensive assessment of LLM outputs.
🎙️ Good Listens : hu-po Discusses the AI Scientist Paper
Whenever an exciting paper comes out, the first thing I do is see if hu-po has done a paper review or has one scheduled. He’s been my go-to for paper reviews over the last several months; he’s hands-down the best in the game.
I count this as a good listen even though it’s a YouTube video since you can do as I did and listen to the video while doing chores around the house and still understand what it’s all about.
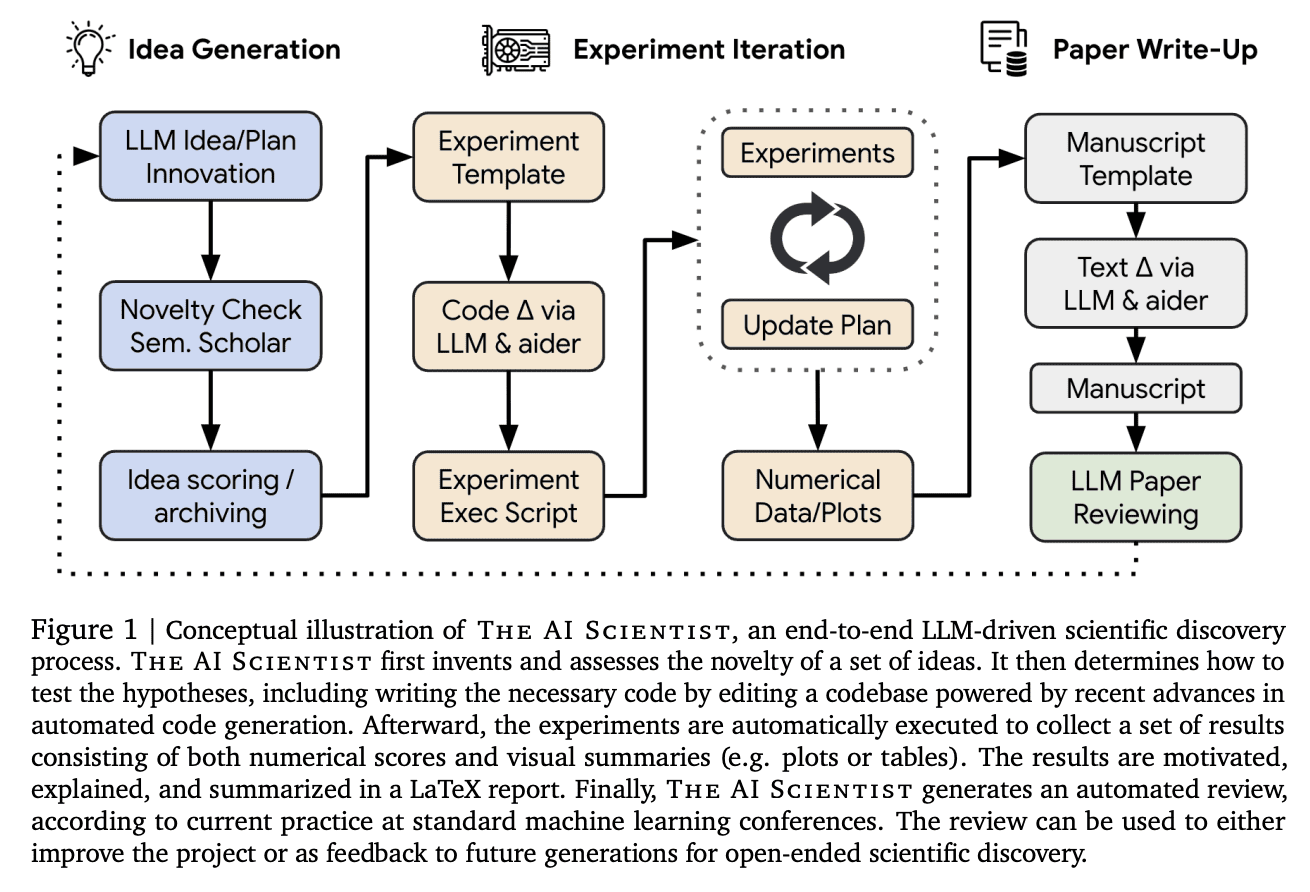
So, what is the “The AI Scientist”?
It’s a system for fully automated scientific discovery using foundation models like large language models (LLMs). This system automates the entire research process, from generating ideas to writing papers and conducting peer reviews. The system has successfully produced papers in various machine learning subfields, including diffusion modeling, language modeling, and grasping. While the current version has limitations, such as occasional errors in result interpretation and visual issues, it shows promise in democratizing research and accelerating scientific progress.
Interesting things The AI Scientist can do:
- Idea generation and novelty evaluation
- Code implementation and experiment execution
- Result analysis and visualization
- Scientific report writing
- Automated peer review process
Check out more resources about the AI Scientist here:
🗓️. Upcoming Events
Check out these upcoming AI, machine learning and computer vision events! View the full calendar and register for an event.





