A year where Visual AI didn’t just evolve, it reshaped what’s possible
In 2024, Visual AI didn’t just advance—it redefined how machines perceive, interpret, and transform the world around us. This was the year that images turned into answers, videos evolved into real-time insights, and machines “saw” the world with a level of precision once thought impossible. Whether through groundbreaking open source contributions, the rapid leap from 2D to 3D understanding, or the explosion of vision-language models (VLMs), Visual AI took center stage.
From Meta’s SAM2 reshaping object segmentation to AI-driven 3D reconstruction mapping the human body and the Earth alike, the innovations of 2024 weren’t just technical triumphs—they were societal game-changers. Farmers grew more food with less waste. Doctors caught diseases earlier, saving lives. Cities got smarter, safer, and more efficient. Every pixel, every frame, and every datapoint became a tool to push humanity forward.
Yet, this isn’t just a retrospective of breakthroughs. It’s a celebration of what they mean for the future—how Visual AI enables machines not just to look but to understand and act. Looking back on 2024, it’s evident that vision was no longer just a component of AI—it became its most transformative power.
Bonus, read until the end to see predictions of how 2025 is going to be even better!
The Engine of Visual AI’s Advancements: Open Source
It is SHOCKING to me how much open source has changed the ML ecosystem in the past year. Never has it been easier to just pull a model off the self and fine-tune it to your use case, cutting a significant amount of development time for any project. Models are also only one way open source is paving the way for Visual AI, and arguably not the most significant. Let’s review this year’s greatest Visual AI open source contributions.
Meta’s SAM2
While on the topic of models, it’s hard to argue there is a more impactful open source model in the Visual AI space today. There are many ways to break down why Meta’s powerful segmentation model is changing the field in more ways than one. First and foremost, at the surface level, it is just an incredible model. Being able to quickly speed up the annotation process of a majority of datasets is insanely valuable. It cannot be overstated how much time, effort, and money goes into annotation today. It is a problem that affects the smallest of startups and the largest of enterprises. Using SAM2, you can cut down annotation times significantly, allowing for resources to be better spread throughout the model development cycle instead of a large chunk being poured into annotation.
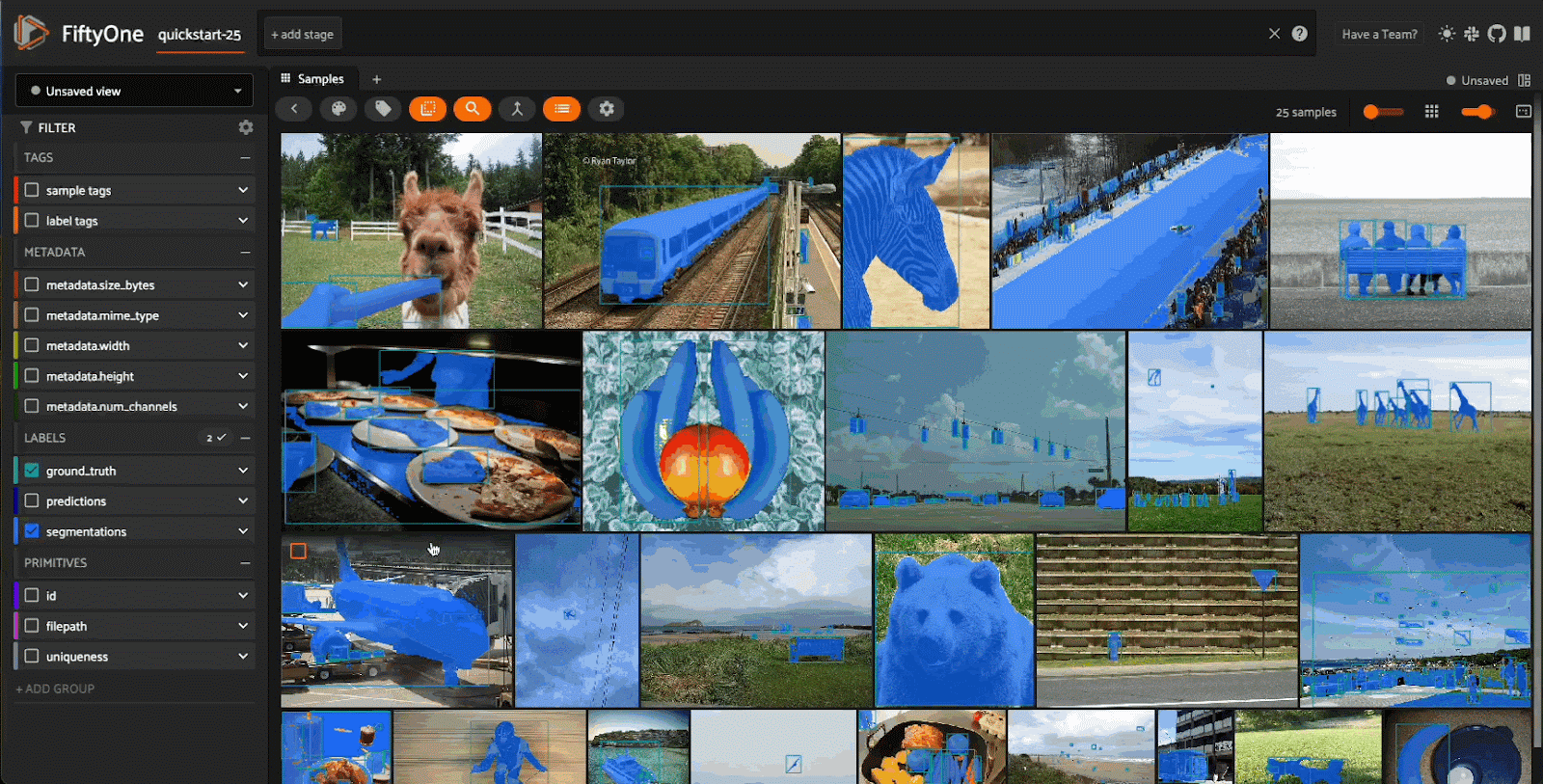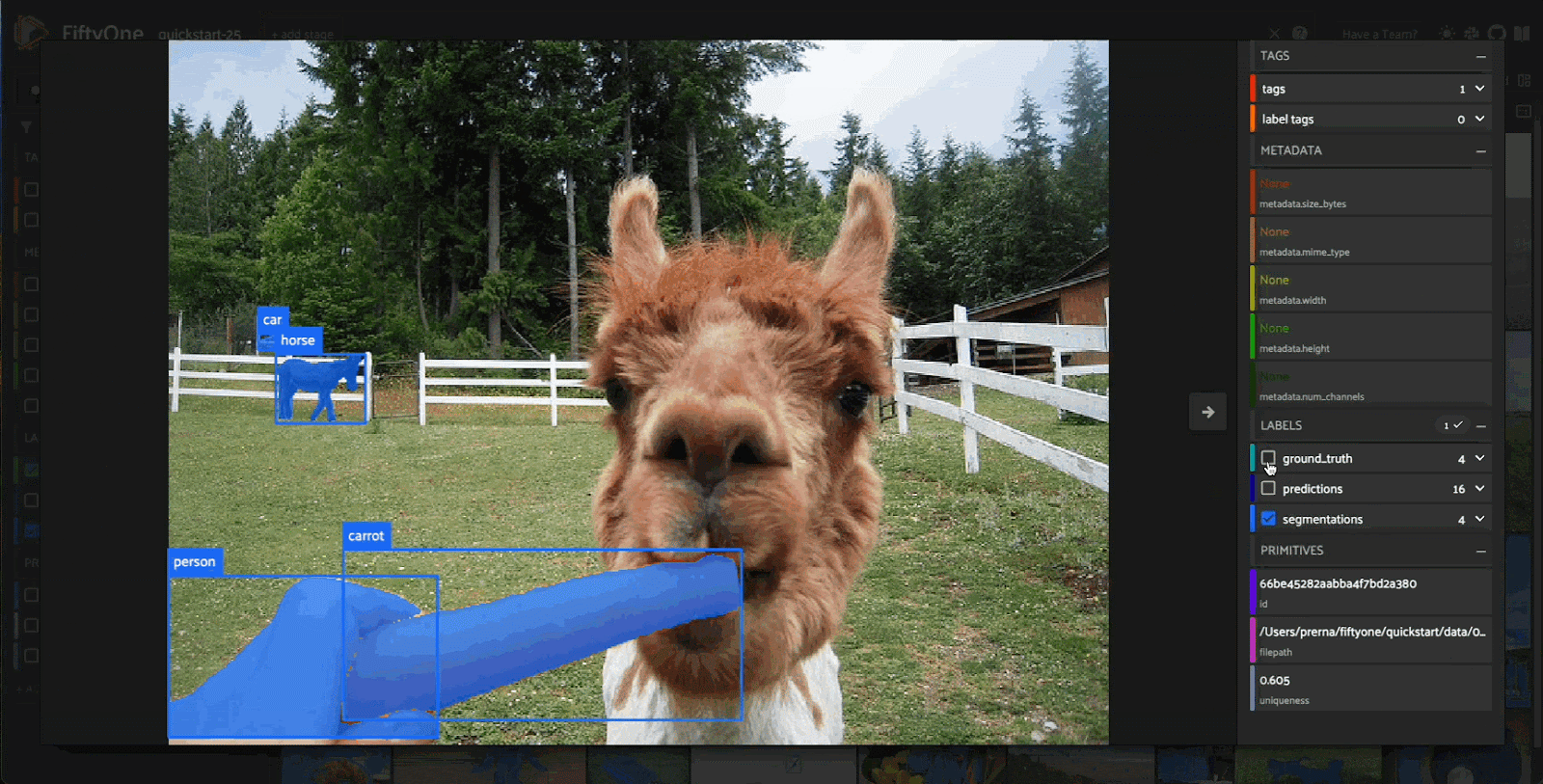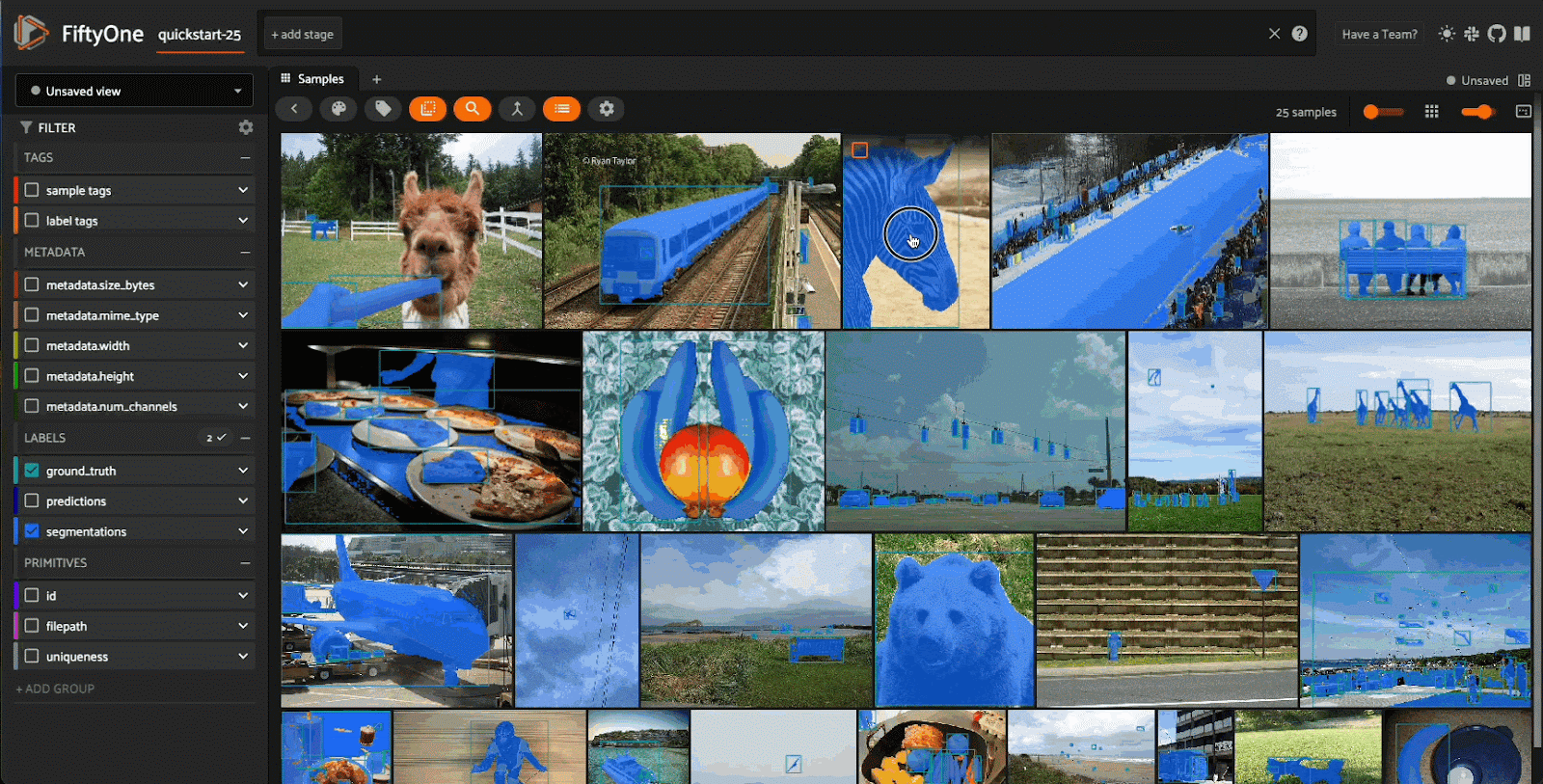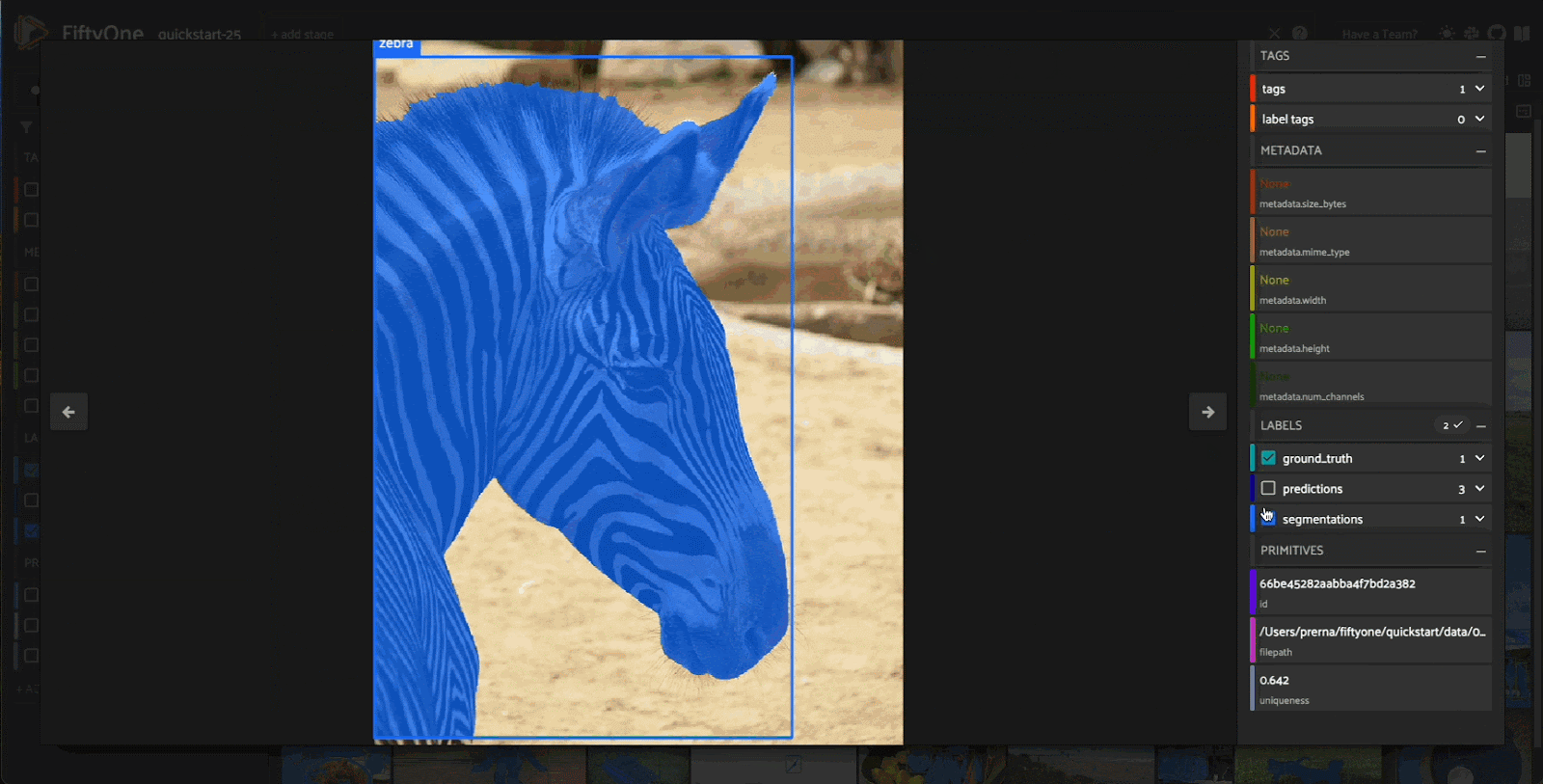
The other significant contribution that SAM2 made is we are finally moving away from frame-by-frame video analysis. The entire computer vision community has been waiting for some breakthrough research to finally move away from algorithms of the past. Industry standards going back even a few months ago were to use classical computer vision and statistical methods like the Hungarian. Finally, we can intelligently look frame-by-frame and use temporal context to guide model inference in a way that feels modern and up to date. We are a long way away from catching the same performance in context windows for video as LLMs do for text, but the gap that once felt insurmountable is finally closing.

The last point is more of an affirmation of previous thoughts that held true through 2024, which is that large players in the space are still pushing for the democratization of Visual AI. Meta could very easily as much not release models like SAM2 and keep them internal to build up a lead on the competition yet continue to stay committed to open source. Yet, Meta continues to be a champion of open source in a very public way. As time goes on, annotation will only become easier and more accessible to researchers and small teams who no longer have to pay a small fortune to get datasets annotated. Heading into 2025, you have to wonder: how long until annotation as we know it is dead?
YOLOv9-11 and Ultralytics’ Continued Rise
If you aren’t familiar with YOLO models of the past, it deserves a quick history lesson. The first YOLO model was released in 2015 led by Joseph Redmon. He went on with others to create YOLOv2 and YOLOv3 before stopping further development. However, the community was confused when YOLOv4 was released in 2020, this time with different authors. The Visual AI community was still nascent and argued over naming conventions and whether or not you could just claim a model architecture name for adding improvements.

Then Ultralytics arrived and decided to pave their own way, releasing YOLOv5, and without a paper. Instead, the new GitHub repo allowed for easy training and deployment and was an instant success. It quickly became one of the most popular models available and, more importantly, one of the easiest to use. Since then, the pattern has continued, with researchers publishing papers with improvements to the YOLO architecture in models YOLOv6, YOLOv7, YOLOv9, and YOLOv10, while Ultralytics created YOLOv8 and YOLOv11 to be easier to use and more flexible for different applications.
Despite some years of controversies claiming they are piggybacking off others’ success, what is undeniable is Ultralytics’ push to make Visual AI easy and accessible to anyone without sacrificing performance. I can only imagine how many new members of the community’s first experience with object detection started with Ultralytics. The company’s development of their open source library has made model training a breeze, being able to train one of the best-performing models in only a few lines of code. On top of that, by including multiple flavors of each model, from their nano-size models to their extra-large models, it is easy for developers to find the right model. Recent updates have even expanded the tasks they support beyond object detection to things like segmentations, pose estimation, and oriented bounding boxes!
Builders are always going to want to build. By catering to the large enterprise and hobbyist alike, the Ultralytics library marches onward into 2025 with huge momentum.
The Libraries That Make Visual AI Work
Almost everyone has heard of libraries like OpenCV, Pytorch, and Torchvision. But there have been incredible leaps and bounds in other libraries to help support new tasks that have helped push research even further. It would be impossible to thank each and every project and the thousands of contributors who have helped make the entire community better. MedSAM2 has been helping bring the awesomeness of SAM2 to the medical field, segmenting organs in a variety of medical imaging methods. Rerun has made it easier than ever to stream multimodal data for spatial and embodied AI.

However, there is a small group of libraries that has empowered an exploding sector of Visual AI that could change not just computer vision but also AI as we know it.
The 2D → 3D Revolution
The Visual AI community became obsessed with 3D works in 2024, piggybacking on the growth of libraries like Pytorch3D and others, and took 3D heights we previously could never imagine. Seeing insane progress in both academia and industry, here are some of the main highlights in 2024 that made 3D special.
NerFs vs Gaussian Splatting
We received our first NerF paper back in 2020 when NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis was released, shaking up the 3D field. NerFs are a way to represent a 3D scene with five dimensions: x,y,z and viewing direction, θ,ϕ. This was quickly adopted by the Visual AI community as an exciting way to perform 3D reconstruction, a task aimed at reconstructing a scene based on a series of images. Through clever photogrammetry and machine learning, the results were incredible. There was only one issue: they were extremely slow. Not only did NerFs require a beefy GPU to train, but they also required one to view as well. The accuracy of the reconstruction was high, but usability was low in applied use cases, so the community looked elsewhere.
When Gaussian Splatting was introduced in 2023, it offered a promising alternative. By leveraging 3D Gaussians, one could render a scene without nearly as many computations. Accuracy still was dependent on a robust neural network, but once rendered, it was significantly more efficient and optimized. At launch, researchers were hesitant and skeptical if the new method would usurp NerFs. However, in 2024, researchers have made Gaussian Splatting the talk of every conference, transforming industries entirely with their fast speed and flexibility. We can now create 3D worlds for our self-driving cars to simulate using OmniRe, generate accurate 3D avatars of heads with GAGAvatar, or create scenes with just text using DreamScene360. For more resources on Gaussian Splats, check out this awesome repo.

The Race for Autonomy Continues
No industry dominates the 3D Visual AI space quite like Autonomous Vehicles. What makes it so exciting is that leaders in the field, Waymo, Tesla, Wayve, and others, all have significantly different approaches to solving autonomous driving. And we have no clue who will be right! What we do know is that the work they have done in the past year has been incredible so here is a quick synopsis of work.
Waymo has shown incredible progress, both in the safety and understanding of their vehicles. Publishing 14 papers this year on safety alone, Waymo is committed to listening to their harshest critics and aiming to be better. After concerns about how Waymo cars handle construction sites, they dedicated resources to solving it right away. Another concern was how they handle small vehicles like bikes and scooters. Check this video out:

This example might be one of the most impressive videos of self-driving cars to date. I expect as Waymo begins to expand, we will only see even more incredible examples.
Tesla has been keeping their lips sealed on their side, staying committed to their camera-only sensor system. There are many skeptics on the ADAS/AV side if this is even possible without LIDAR/RADAR sensors or even safe. Only time will tell. Tesla did announce in its We, Robot event the plan for the Robotaxi and Robovan to be released in the future, signaling their vision for autonomous vehicles.

Wayve stays committed to publishing a majority of their research, releasing their LINGO models, models that use images, driving data, and language to explain causal factors in the driving scene, accelerate training, and adapt driving behaviors to new environments. Language can also be used for model introspection, where we can ask a driving model about its driving decisions. This can open up new possibilities for interacting with autonomous driving systems through dialogue, where passengers can ask the technology what it’s doing and why. Vision Language Models show much promise for what the future holds, but what are they?
Scaling AI with Vision Language Models
As we highlight achievements in 2024, one of the most exciting prospects for 2025 is the further adoption of VLMs in Visual AI. There were significant strides made with models like Florence 2, GPT4o, and the recently released Gemini 2. These models are getting more and more intelligent, spanning different types of knowledge, languages, and modalities. Here’s an example of Gemini from the latest release:

We are right on the edge of our ChatGPT moment with VLMs. We aren’t quite yet at the point where people are pointing their phones in public and asking questions today, but 2025 holds lots of promise for what VLMs could mean for Visual AI. Hopefully, in combination with tools like SAM2, VLMs can remove 90% of human annotation by the end of 2025. More than that, we can use these models as we saw with Wayve to get better insights into why models make the decisions they do, increasing safety and transparency and closing the gap between human and AI interactions. A VLM explosion isn’t the only prediction for 2025, so check out what I predict is coming next!
2024’s Legacy and What Lies Ahead
The past year was as pivotal as ever for Visual AI. The field’s continued commitment to open source has allowed it to rocket forward to new heights, expanding to limits once thought impossible. With the way 3D and VLMs are on such an upward trajectory, 2025 serves to be an exciting year. Here are my predictions for the next year:
- Departure from 2D to 3D. Many tasks or applications that previously existed in 2D were only doing so because latency or accuracy to do so wasn’t possible in 3D. That will change with many object detection, segmentation, and visual understanding tasks moving from pixels to voxels.
- VLMs get their ChatGPT moment. Whether it’s asking a model what the mole on your arm is or how to get a stain out of your shirt, people will be using vision language models to help them every day.
- Open Source drives innovation. The best and brightest in Visual AI innovation stay open source off the back of what is an already talented and growing community.
- Annotation as we know it dies. Long gone will be the days of going frame-by-frame drawing bounding boxes. New video processing models + new VLMs will eliminate the need to outsource annotation ever again.
I’m feeling very confident about these! Visual AI is one of the most exciting fields to watch and I can’t wait to see what the new year holds. 2024 was the best year for Visual AI so far, but who knows what 2025 might hold!
Want to be part of the open source movement in Visual AI? Want to debate my predictions? Hop on over to the FiftyOne Community Discord to discuss anything Visual AI, or contact me on LinkedIn!

