Review of a Data-Centric AI Paper from NeurIPS 2024 — Visual Data Diagnosis and Debiasing with Concept Graphs
This post is part of a five-part series examining notable data-centric AI papers from NeurIPS 2024. For brief summaries of all five papers, checkout my overview post, where you’ll find links to each detailed analysis.
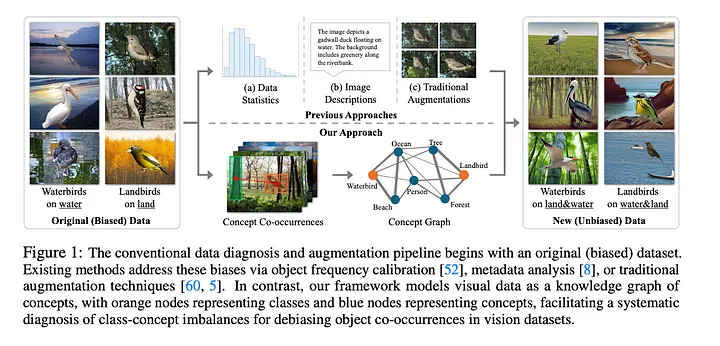
Deep learning models have achieved impressive performance across many tasks, but their reliance on extensive datasets can lead to the models learning and perpetuating inherent biases present in the data.
Object co-occurrence bias, which occurs when a label is spuriously correlated with an object that is causally unrelated to the label, is one such bias that can negatively impact model performance. For example, in the Waterbirds dataset, landbirds are overwhelmingly associated with land-based backgrounds while waterbirds are primarily depicted against water backgrounds. This bias can confound downstream tasks, as the model may learn to rely on these spurious correlations rather than the true underlying features that define the classes.
Therefore, effective methods for diagnosing and mitigating dataset biases are essential to ensure the reliability and fairness of deep learning models.
Relevant links:
Datasets like ImageNet, MS-COCO, and CelebA, which are widely used for training deep learning models, have been found to contain various biases that negatively impact the performance and reliability of deep learning models trained on such data. The authors argue that biases can arise from various factors, including:
- Texture bias: Where models prioritize texture over shape in their decision-making.
- Shape bias: Where models focus on shape characteristics rather than a holistic understanding of the object.
- Object co-occurrence bias: The spurious correlation between an object and a class label when they are not causally related. As the paper points out, an example is the tendency for “waterbirds” to be predominantly pictured against water backgrounds in datasets, even though the background doesn’t inherently define the bird type.
Among these biases, the authors specifically focus on object co-occurrence bias because it represents a fundamental challenge in how models learn to classify objects. The paper’s core hypothesis is that class labels in visual datasets exhibit co-occurring bias with specific concept sets, ultimately affecting the performance of downstream tasks.
Unlike texture or shape bias, which relates to single-object characteristics, co-occurrence bias reflects problematic relationships between objects and their contexts that can fundamentally mislead model learning. When a model learns that waterbirds must appear with water backgrounds or that medical conditions are tied to specific demographics, it’s not just making superficial errors — it’s learning false causal relationships that can severely impact its real-world reliability. This type of bias is particularly insidious because it’s both prevalent in common datasets and difficult to detect through traditional evaluation methods. Traditional bias mitigation techniques, which often focus on model-level interventions or rely on language models for debiasing, have proven inadequate for addressing these spurious correlations, making new approaches like knowledge graph-based solutions particularly valuable.
The authors argue that representing the dataset as a knowledge graph of object co-occurrences allows for a structured and controllable method to diagnose and mitigate these spurious correlations.
Concept co-occurrence Biases in visual datasets (ConBias)
To address this gap, the paper introduces ConBias, a novel framework designed to diagnose and mitigate concept co-occurrence biases in visual datasets. ConBias achieves this by representing visual datasets as knowledge graphs of concepts. This representation allows for a detailed examination of spurious concept co-occurrences and the identification of concept imbalances throughout the dataset.
The problem setting for ConBias is as follows:
- Input: A biased visual dataset with images, corresponding class labels, and a concept set describing unique objects in the data.
- Challenge: Identify and mitigate object co-occurrence biases in the dataset, manifesting as spurious correlations between class labels and concepts.
- Goal: Generate an debiased augmented dataset with respect to the concepts and their corresponding class labels, enabling improved classifier training and generalization performance.
Three Steps of ConBias
As mentioned before, object co-occurrence bias refers to the spurious correlation between a label and an object causally unrelated to that label.
By zeroing in on object co-occurrence bias, the authors aim to tackle a specific and prevalent type of bias that poses a significant challenge in visual recognition tasks. The ConBias framework specifically addresses this issue. The authors argue that generating images with a more uniform concept distribution across classes will improve the generalization capabilities of a classifier trained on the debiased dataset.
At a high level, the ConBias method involves three steps:
- Concept Graph Construction maps the co-occurrence relationships between objects (concepts) and class labels.
- Concept Diagnosis uncovers imbalanced concept combinations across classes, pinpointing potential areas of object co-occurrence bias.
- Concept Debiasing rectifies these imbalances by generating new images with under-represented concept combinations.
Let’s go into these steps in more detail.
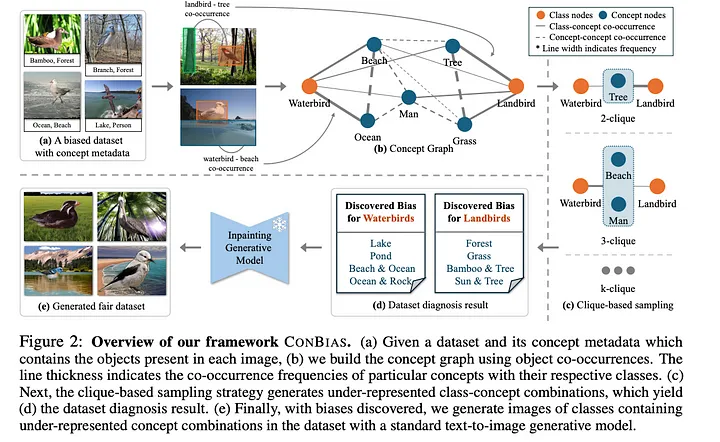
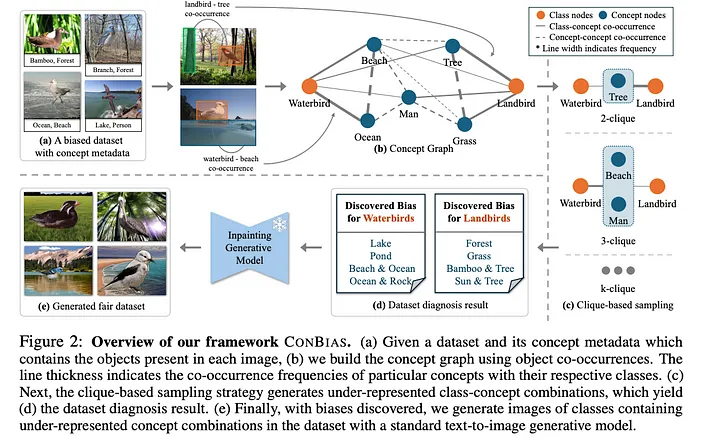
Step 1: Concept Graph Construction

The first step involves building a knowledge graph representing the visual dataset. This graph consists of nodes and edges, with weights assigned to the edges.
- The nodes in the graph represent the union of the dataset’s class labels and the concept set describing unique objects present in the data. In addition to the class label, the concept set might consist of objects like “alley,” “crosswalk,” or “gas station” present in the images.
- The edges connect nodes that co-occur in the same image. For example, if an image contains both a “landbird” (class label) and a “tree” (concept), there would be an edge between the corresponding nodes.
- The weight of each edge signifies the frequency of co-occurrence between the two connected nodes. So, a higher weight indicates a more frequent co-occurrence of those particular concepts or class labels within the dataset. This step transforms the visual data into a structured graph format that captures the dataset’s co-occurrence relationships between various concepts and class labels.
Step 2: Concept Diagnosis

Once the concept graph is constructed, ConBias analyzes it for concept imbalances, which may indicate biases in the original dataset. The framework achieves this through a series of definitions and operations:
- Class Clique Sets: For every class in the dataset, ConBias identifies groups of interconnected concepts (cliques) within the graph. Each clique represents a specific combination of concepts. These cliques are categorized based on their size, denoted by k, which refers to the number of concepts within each group. For instance, a 2-clique would represent a pair of co-occurring concepts, while a 3-clique would involve three. The framework constructs these class clique sets for every class in the dataset, considering various clique sizes ranging from 1 to the largest clique containing the specific class.
- Common Class Clique Sets: Next, ConBias focuses on the cliques shared across all classes in the dataset. These common cliques, denoted as K, are particularly important for bias analysis as they represent concept combinations appearing across different classes, enabling comparison of their co-occurrence frequencies.
- Imbalanced Common Cliques: This step identifies common cliques that exhibit uneven co-occurrence patterns across different classes, suggesting a potential bias. For each common clique, ConBias calculates the difference in co-occurrence frequencies between all class pairs. Larger discrepancies indicate a greater imbalance, suggesting a stronger potential bias. For example, in the Waterbirds dataset, the concept combination (Beach, Ocean) might be significantly more frequent in images labeled as “Waterbird” compared to “Landbird”, revealing a potential bias. This analysis highlights concept combinations that exhibit imbalanced distributions despite being common across classes, suggesting the possibility of spurious correlations between concepts and class labels.
Step 3: Concept Debiasing
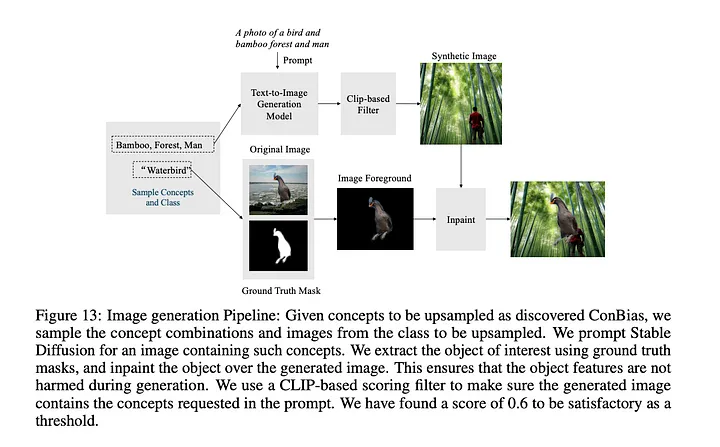
The final step of ConBias addresses the imbalances identified in the previous stage by generating new images that contain under-represented concept combinations.
- Based on the Concept Diagnosis step analysis, ConBias pinpoints the concept combinations and corresponding classes that require rebalancing. For each under-represented combination, the framework calculates the number of new images needed to achieve a balanced representation.
- ConBias creates these new images using a text-to-image generative model, such as Stable Diffusion. The prompts given to the model are descriptive phrases constructed from the underrepresented concept combinations. For example, if the combination “Waterbird, Tree” was underrepresented, ConBias would prompt the model with phrases like, “An image of a waterbird and a tree.”
- To maintain the integrity of the original images and avoid unwanted modifications to the objects themselves, ConBias uses an inpainting technique. This technique involves generating the background with the desired concepts and then seamlessly inserting the original object into the scene, using ground-truth masks if available.
- These newly generated images containing balanced representations of the previously imbalanced concepts are then added to the original dataset to create an augmented dataset. This augmented dataset can then retrain the classifier, ideally reducing the impact of the identified biases on its performance.
Key Findings
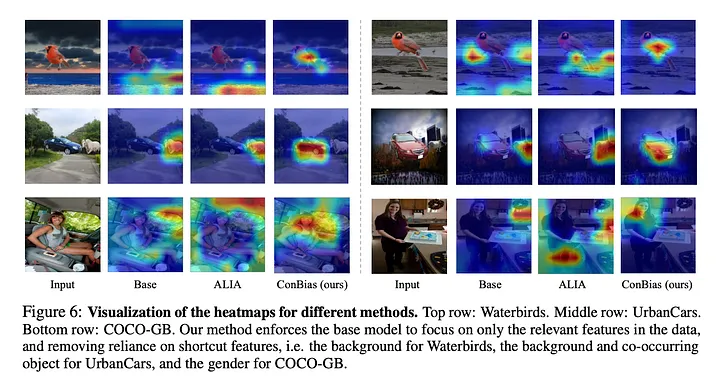
Across multiple datasets (Waterbirds, UrbanCars, and COCO-GB), ConBias consistently demonstrated a substantial improvement in the generalization performance of classifiers. Specifically, it achieved notable gains in accuracy on both class-balanced and out-of-distribution (OOD) test sets. This improvement indicates that models trained on the debiased dataset generated by
ConBias are better equipped to handle data that doesn’t conform to the biases present in the original training data.
- Superiority over Traditional Augmentation Techniques: Compared to standard data augmentation methods like CutMix and RandAug, ConBias exhibited a marked advantage in mitigating object co-occurrence bias. This suggests that ConBias’s targeted approach, which focuses on identifying and rectifying specific concept imbalances, is more effective than generic augmentation techniques that don’t explicitly address bias.
- Outperformance of State-of-the-art Methods: ConBias outperformed ALIA. This recently proposed state-of-the-art method uses large language models for data debiasing. The authors attribute this superior performance to ConBias directly diagnosing and addressing biases within the dataset instead of relying on external language models that may introduce new biases.
- Effectiveness of Clique-Based Concept Balancing: The study found that leveraging the graph structure and employing clique-based concept balancing is crucial for effective bias mitigation. This approach, which analyzes concept co-occurrences within cliques of varying sizes, allows ConBias to identify and rectify more complex and subtle biases compared to simply examining single-concept frequencies.
- Importance of Concept Imbalance Discovery: ConBias’s ability to identify concept imbalances significantly impacted its success. By pinpointing specific concept combinations over- or under-represented for certain classes, ConBias can guide the generation of synthetic data that effectively addresses these imbalances. The researchers note that this targeted approach is more effective than relying on diverse prompts from large language models, as done in ALIA.
- Benefits of Inpainting-Based Image Generation: Using an inpainting-based image generation method, which preserves the original object while modifying the background, proved beneficial for debiasing. This approach ensures that the synthetic data remains relevant to the classification task and avoids introducing artifacts that could hinder model training.
These findings highlight the effectiveness of the ConBias framework in diagnosing and mitigating object co-occurrence bias in visual datasets, leading to improved model generalization and more reliable deep learning applications. They also underscore the importance of addressing bias directly within datasets and utilizing targeted approaches for data debiasing.

