Review of a Data-Centric AI Paper from NeurIPS 2024 — Intrinsic Self-Supervision for Data Quality Audits

This post is part of a five-part series examining notable data-centric AI papers from NeurIPS 2024. For brief summaries of all five papers, checkout my overview post, where you’ll find links to each detailed analysis.
Machine learning has made incredible progress in recent years, with deep learning models achieving impressive results on various tasks. However, this progress is often measured and compared using benchmark datasets, which are supposed to be reliable and representative collections of data.
But what happens when these very benchmarks are contaminated with errors?
It turns out, this contamination seriously threatens the reliability of benchmark results, potentially leading to overestimating model performance and hindering scientific progress.
Relevant links:
Data cleaning in deep learning is especially important in low-data regimes, where poor-quality samples can substantially affect model performance.
In this paper, the researchers aim to address the tension between the need to clean benchmark datasets and the principle of avoiding manipulating evaluation data. Several factors contribute to the authors’ research question.
- First, they recognize the limitations of traditional data-cleaning approaches in handling the massive scale of modern datasets, particularly in computer vision.
- Second, the widespread use of benchmark datasets for performance comparisons necessitates a robust and efficient method for identifying and mitigating data quality issues to ensure reliable evaluations.
- Finally, the authors acknowledge the prevalence of data quality issues, even in curated medical datasets, highlighting the importance of data-centric AI principles for improving the reliability of machine learning models.
They point out that the focus on data quantity over quality has led to varying noise levels in datasets. They also acknowledge the heavy reliance on benchmark datasets by deep learning practitioners despite them being known to contain data quality issues that can lead to over-optimistic results.
The need for comparable results has driven the reliance on benchmarks despite their limitations, creating a tension between the need for data cleaning and the avoidance of manipulating evaluation data.
Data Quality Issues in Benchmark Datasets
The paper highlights three specific types of data quality issues:
- Off-topic samples: These are images mistakenly included in the dataset, deviating from the intended data distribution. Examples include images from unrelated domains or those affected by device malfunctions. The presence of such samples adds noise to evaluation metrics and can confuse the training process.
- Near duplicates: These images depict the same object, potentially resulting in data leaks between training and evaluation sets, reducing training variability, and leading to over-optimistic performance estimations.
- Label errors: Incorrectly annotated samples can poison the training process and result in inaccurate evaluation.
As mentioned in the paper, there are several reasons why these data quality issues arise:
- Limited Manual Curation: While some datasets undergo rigorous manual verification, others rely on less intensive curation processes, potentially leading to a higher prevalence of errors.
- Data Acquisition Challenges: Collecting and assembling large datasets can introduce errors, such as accidentally including thumbnail images or failing to track metadata that links images with a common origin properly.
- Annotation Complexities: Annotating images, especially for fine-grained tasks or in specialized domains like medicine, can be challenging, leading to occasional mislabeling
To address these data quality issues, the authors propose SELFCLEAN.
SELFCLEAN: A Data Cleaning Method
SELFCLEAN addresses the problem of data quality issues within benchmark datasets by employing a two-step process:
- Representation Learning: The first step involves training a deep feature extractor using self-supervised learning (SSL) on the dataset to be cleaned. This training is performed on the entire dataset, encompassing any existing data quality issues. The authors suggest using either SimCLR or DINO as the SSL objective. Both have demonstrated success in learning meaningful representations even from noisy data. The learned representations are then compared using cosine similarity and the associated distance, scaled to a range of [0,1]. Using SSL for representation learning ensures that SELFCLEAN does not inherit any annotation biases, as it relies solely on the data’s inherent structure.
- Distance-Based Indicators: Once the feature extractor is trained, SELFCLEAN utilizes distance-based indicators to identify potential data quality issues. These indicators are used with the learned representations to identify candidate data quality issues based on distances between samples in the latent space.
Each data quality issue type is addressed with a specific indicator function that leverages the local structure of the embedding space:
- Off-topic samples: These are identified using agglomerative clustering with single linkage. Samples that merge later with larger clusters during the clustering process, indicating greater distance from the main data clusters in the latent space, are flagged as potential off-topic samples.
- Near duplicates: SELFCLEAN computes pairwise distances between all samples in the latent space to detect near duplicates. Pairs with very small distances, suggesting high similarity in their representations, are flagged as potential duplicates.
- Label errors: SELFCLEAN assesses the consistency of labels by comparing distances between a sample and its nearest neighbors from the same and different classes. If a sample exhibits a significantly smaller distance to neighbours from a different class than neighbours from its class, it raises suspicion of a potential label error.
SELFCLEAN Operating Modes
SELFCLEAN offers two modes of operation, allowing users to choose between a fully automated approach and a method incorporating human oversight: human-in-the-loop and fully automatic.
Human-in-the-Loop
In this mode, SELFCLEAN produces a ranked list of potential data quality issues.
A human curator then inspects the top-ranked samples, confirming and correcting the identified problems or determining a suitable rank threshold to achieve a desired balance between precision and recall. This mode acknowledges the limitations of fully automated cleaning, especially for complex cases requiring subjective judgment, and the possibility that some flagged samples may be valuable edge cases rather than errors.
Fully Automatic
This mode uses the score distributions generated by the distance-based indicators.
Typically, these scores exhibit a smooth distribution for clean samples, with contaminated samples receiving significantly lower scores, separating them from the bulk of the data. This allows for the automated identification of problematic samples based on statistically determined outlier thresholds.
The method utilizes two hyperparameters: a “contamination rate guess” representing an estimated upper bound on the fraction of issues in the dataset, and a “significance level” defining the desired statistical confidence in the outlier detection process.
Experiments to Evaluate SELFCLEAN
The authors conduct a series of experiments to evaluate the effectiveness of SELFCLEAN in detecting off-topic samples, near duplicates, and label errors. These experiments involve synthetic and natural contamination in various benchmark datasets.
- Datasets: The authors utilize twelve datasets encompassing general vision and medical imaging. The general vision benchmarks include ImageNet, STL-10, CelebA, and Food-101N. The medical datasets consist of CheXpert, VinDr-BodyPartXR, PatchCamelyon, HAM10000, ISIC-2019, Fitzpatrick17k, DDI, and PAD-UFES-20, covering modalities such as X-ray, histopathology, and dermatoscopy images.
- Evaluation metrics: Performance evaluation relies on ranking metrics, specifically AUROC (Area Under the Receiver Operating Characteristic curve) and AP (Average Precision). AUROC measures the likelihood of a relevant sample being ranked higher than an irrelevant one. At the same time, AP assesses precision across all recall values, accounting for the proportion of positive and negative samples.
Synthetic Contamination Experiments
To compare SELFCLEAN with competing methods, the authors create synthetic datasets by introducing specific types of contamination into benchmark datasets (STL-10, VinDr-BodyPartXR, and DDI). In this experiment, they used the following contamination strategies:
- Off-topic samples: Adding images from a different category or applying Gaussian blurring.
- Near duplicates: Augmenting existing images with transformations like rotation, flipping, and blurring or creating collages with artifacts.
- Label errors: Randomly changing labels uniformly or proportionally to class prevalence.
Natural Contamination Experiments
The authors evaluate cleaning on naturally occurring data quality issues in benchmark datasets (ImageNet, Food-101N, CelebA, HAM10000, ISIC-2019, PAD-UFES-20, and CheXpert). They design two experiments:
- Metadata comparison: Measuring how well SELFCLEAN’s ranking aligns with available metadata. For example, they use labels in CelebA that indicate images featuring the same celebrity and metadata in HAM10000 and ISIC-2019 that link images depicting the same skin lesion.
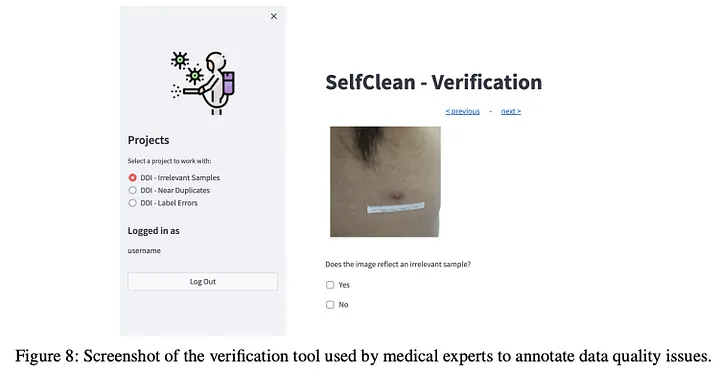
- Human annotator comparison: Comparing SELFCLEAN rankings against human verification for the top-ranked images.
Key Findings
- SELFCLEAN with DINO pre-training consistently outperforms competing approaches across all three types of data quality issues (off-topic samples, near duplicates, and label errors) in terms of both AUROC and AP.
- Dataset-specific representations learned through SSL tend to outperform general-purpose representations, emphasizing the significance of capturing the dataset’s context for effective data cleaning.
- Human annotators confirm significantly more data quality issues in the top-ranked images identified by SELFCLEAN compared to random samples, demonstrating that the method’s rankings align well with human assessment.
- The effectiveness of SELFCLEAN heavily relies on pre-training the deep feature extractor using SSL. The choice of SSL objective and dataset used for pre-training significantly influences the results. DINO generally yields the best performance.
- Removing problematic samples identified by SELFCLEAN leads to significant changes in downstream classification performance, highlighting the practical importance of data cleaning for accurate model evaluation.
- Applying SELFCLEAN to benchmark datasets reveals the presence of various data quality issues, emphasizing the need for data cleaning and raising concerns about the reliability of reported results.
The findings from the SELFCLEAN methodology expose the widespread presence of data quality issues like off-topic samples, near duplicates, and label errors, even in well-regarded benchmark datasets.
Importantly, the paper underscores that identifying these issues isn’t simply about discarding “bad” data but gaining a deeper understanding of the dataset’s composition and potential biases, ultimately leading to more informed model development and interpretation. Instead, they advocate for a more comprehensive approach to data quality:
- Understanding Dataset Composition: Identifying relationships between samples, such as near duplicates even within the same data split, can provide valuable insights into the dataset’s structure and potential biases.
- Enhancing Model Robustness: Cleaning the training data can lead to more robust models that are less susceptible to the negative effects of noisy data.
- Building Trust in Benchmarks: By addressing data quality issues, we can restore confidence in benchmark results and ensure that they accurately reflect the progress of machine learning.

