WebUOT-1M: A Dataset for Underwater Object Tracking
February 17, 2025 – Written by Harpreet Sahota
How 1.1 Million Frames Are Transforming Object Tracking

While computer vision has conquered the skies with datasets containing 20 million aerial footage, underwater tracking has languished with barely 275,000 frames — until now. WebUOT-1M shatters these limitations with a groundbreaking collection of 1.1 million annotated frames, finally bringing underwater object tracking into the modern era.
Previous datasets for underwater tracking have significant limitations in terms of scale, diversity in target categories, and the variety of scenarios covered. For example, the previous largest UOT dataset, UVOT400, contains only 275,000 frames, while open-air training data contains approximately 20 million. Moreover, datasets like UVOT400 focus on specific underwater tasks, environments, or species, limiting the ability of models trained to generalize to new situations. There’s also a lack of diversity in animal species, and the scenarios covered are limited in current datasets.
These deficiencies hinder the training and evaluation of modern underwater tracking models.
The WebUOT-1M dataset was created to address these issues and facilitate research in underwater vision understanding, marine environmental monitoring, and marine animal conservation by providing a large-scale, diverse, and well-annotated resource.
The specific purposes of the WebUOT-1M dataset include:
- Addressing the shortcomings of earlier underwater object tracking (UOT) datasets, which lack sufficient scale and diversity in target categories and scenarios.
- Providing more than just bounding box annotations in existing UOT datasets, which do not support multi-modal underwater object tracking.
- Exploring effective methods to transfer knowledge from large-scale open-air datasets to underwater tracking models, an area that has yet to be fully examined.
WebUOT-1M is the largest and most diverse underwater tracking dataset, covering various target categories and scenarios.
The dataset contains 1.1 million frames extracted from 1,500 video clips, totalling 10.5 hours of footage. The targets are organized into 12 superclasses based on WordNet. Most video clips were collected from YouTube and BiliBili and filtered. These platforms offer various real-world videos captured by different devices and from various perspectives. The long-tail distribution of videos in each class group mirrors real-world scenarios, encouraging the development of more general UOT algorithms.
Here’s a tl;dr of what this dataset comprises:
- Annotations: High-quality bounding box annotations provide ground truth data for underwater targets. Language prompts describing video sequences support applications like underwater vision-language tracking. Absent labels are also provided for each frame.
- Attributes: Each video sequence is labelled with 23 attributes to enable detailed evaluation of trackers. These attributes include low resolution, fast motion, and underwater visibility.
- Underwater scenarios: The dataset captures various underwater environments, such as sea, river, lake, and fish tank.
- Dataset split: The dataset is divided into training and test sets. The training set comprises 1,020 videos (693k frames, 6.64 hours), while the test set includes 480 videos(407k frames, 3.86 hours).
- Data collection and annotation: Videos were collected from online platforms (YouTube and BiliBili). Data cleaning involved removing unsuitable videos. A professional data labelling team performed manual annotation and correction. Enhanced videos, generated using a semi-supervised method, were provided to annotators to address challenges posed by color deviation and blurring. Unsuitable videos were removed to clean the data.
- Availability: The complete dataset, codes, and tracking results are publicly available. A datasheet details the dataset’s motivation, composition, collection, and intended uses.
The dataset is available for academic use under Creative Commons licenses.
Exploring WebUOT-1M in FiftyOne
I randomly selected 238 videos (192k+ frames) from the test set and parsed them into FiftyOne format for easy exploration.
As mentioned previously, this dataset has rich information for each video, comprising 23 attributes.
 Table 8 from the WebUOT-1M paper describing the 23 attributes for each sample in the dataset
Table 8 from the WebUOT-1M paper describing the 23 attributes for each sample in the dataset
However, interpreting the attributes in this underwater video dataset highlighted significant documentation challenges.
While the dataset includes an attributes.txt file with numerical values, no accompanying documentation or mapping guide explains what these values represent. I had to infer the meaning of values for several attributes, such as underwater scenarios (0–11), water colors (0–15), and shooting perspectives (0–2) — not to mention assuming that the attributed is 0-indexed and that the integer I chose for the human-readable value maps to what the author had intended.
Initially, when I tried to make the mappings 1-indexed instead of 0-indexed, the resulting distributions didn’t match the paper’s reported statistics. This mismatch suggests one of three possibilities:
- There are actual annotation errors in the dataset.
- My interpretation of the attribute mappings is incorrect.
- There’s an undocumented preprocessing step between the raw attributes.txt values and the distributions shown in the paper.
It’s difficult to determine which scenario is correct without clear documentation of the annotation process and value mappings. This underscores the importance of providing clear documentation and annotations for any dataset that is released with the promise of pushing the field forward. The authors could have greatly improved usability by providing a clear data dictionary or mapping guide that explicitly defines what each numerical value represents for each attribute. Such documentation would eliminate guesswork, ensure consistent user interpretation, and make the dataset more immediately useful for research and development purposes.
However, this doesn’t take away from the fact that the bounding boxes are very high quality, and the dataset is quite robust. I hope to coordinate with the author to obtain an official attribute mapping.
Let’s begin by installing some dependencies and downloading the dataset from the Voxel51 org on Hugging Face:
!pip install fiftyone umap-learn timm hiera-transformer einops
import fiftyone as fo
from fiftyone.utils.huggingface import load_from_hub
dataset = load_from_hub(
"Voxel51/WebUOT-238-Test",
name="webuot238",
overwrite=True,
)
After downloading the dataset, you can begin exploring it in the FiftyOne app. Once the dataset has been downloaded, you can do some initial exploration by launching the app.
There are two ways to use the app:
- As a cell in your notebook, which you can do by running:
fo.launch_app(dataset)
- In a separate browser window, run the following in your terminal:
fiftyone app launch
Once the app is launched, you can explore the dataset by:
- Scrolling through the videos for a visual vibe check of its contents
- Filter based on the labels (the various attributes associated with each video)
- Filter based on the objects (the various ground truth labels)
- Create a dashboard of plots for the various information fields of the dataset.
fo.launch_app(dataset)

Exploring deeper
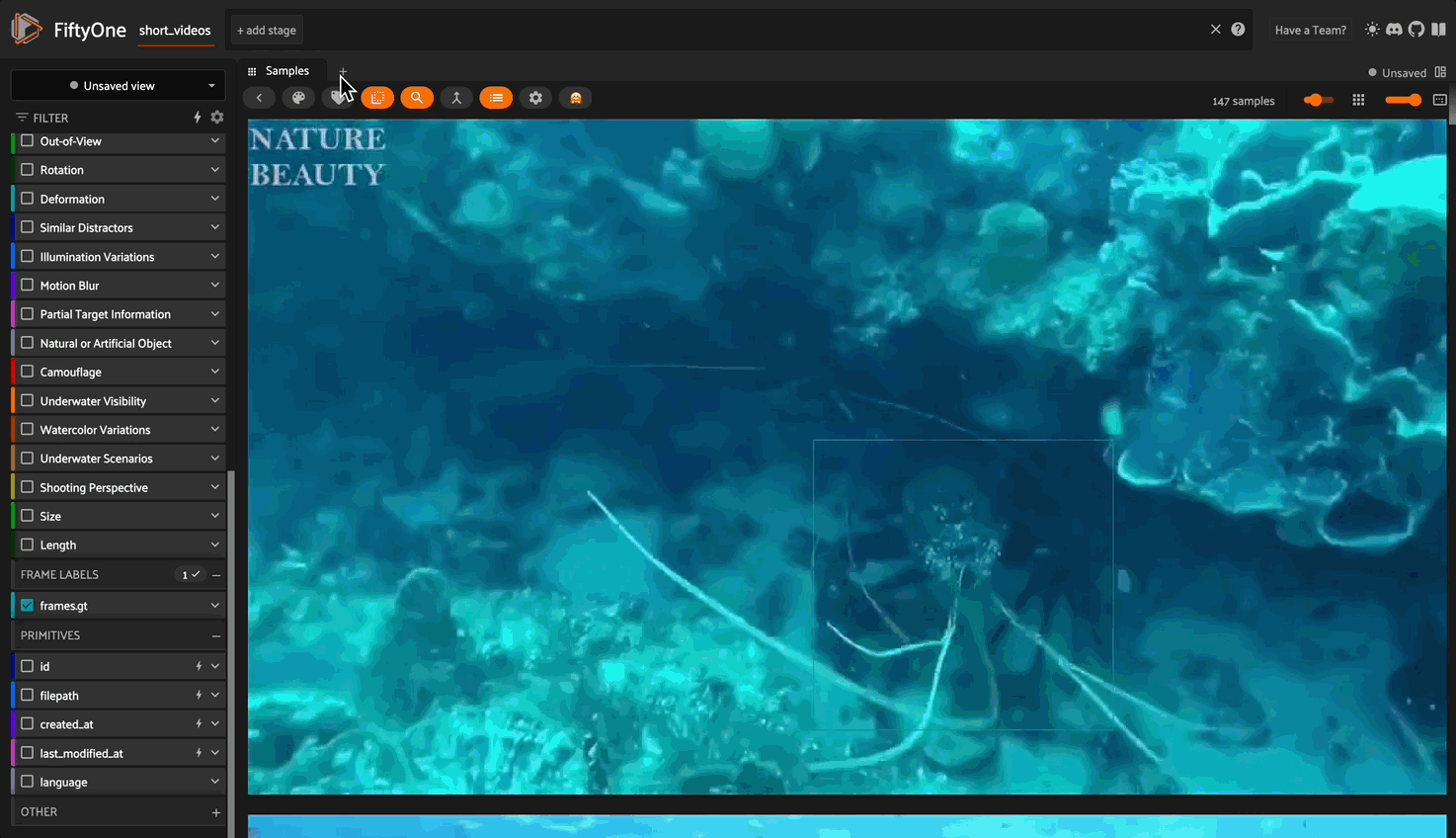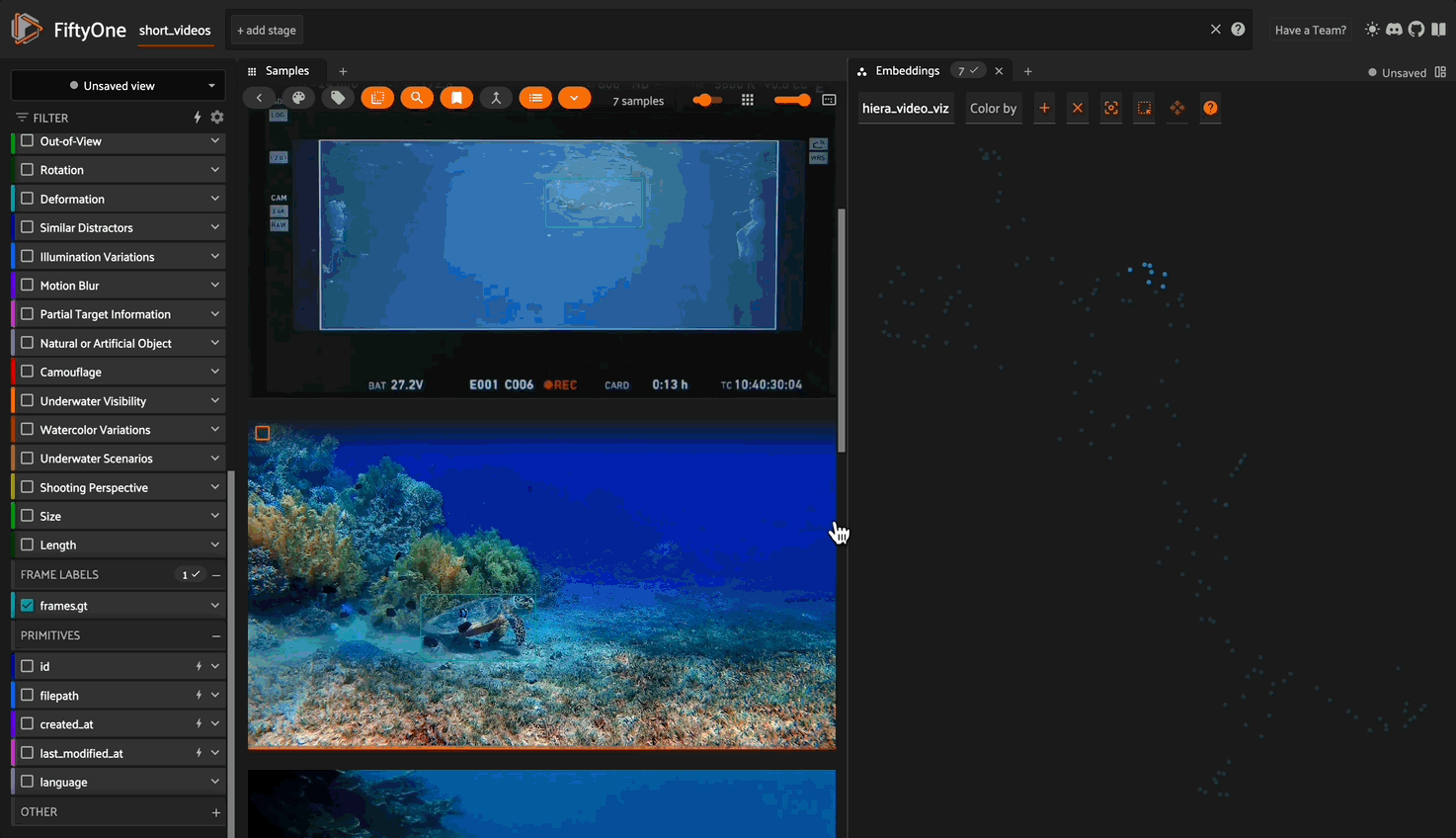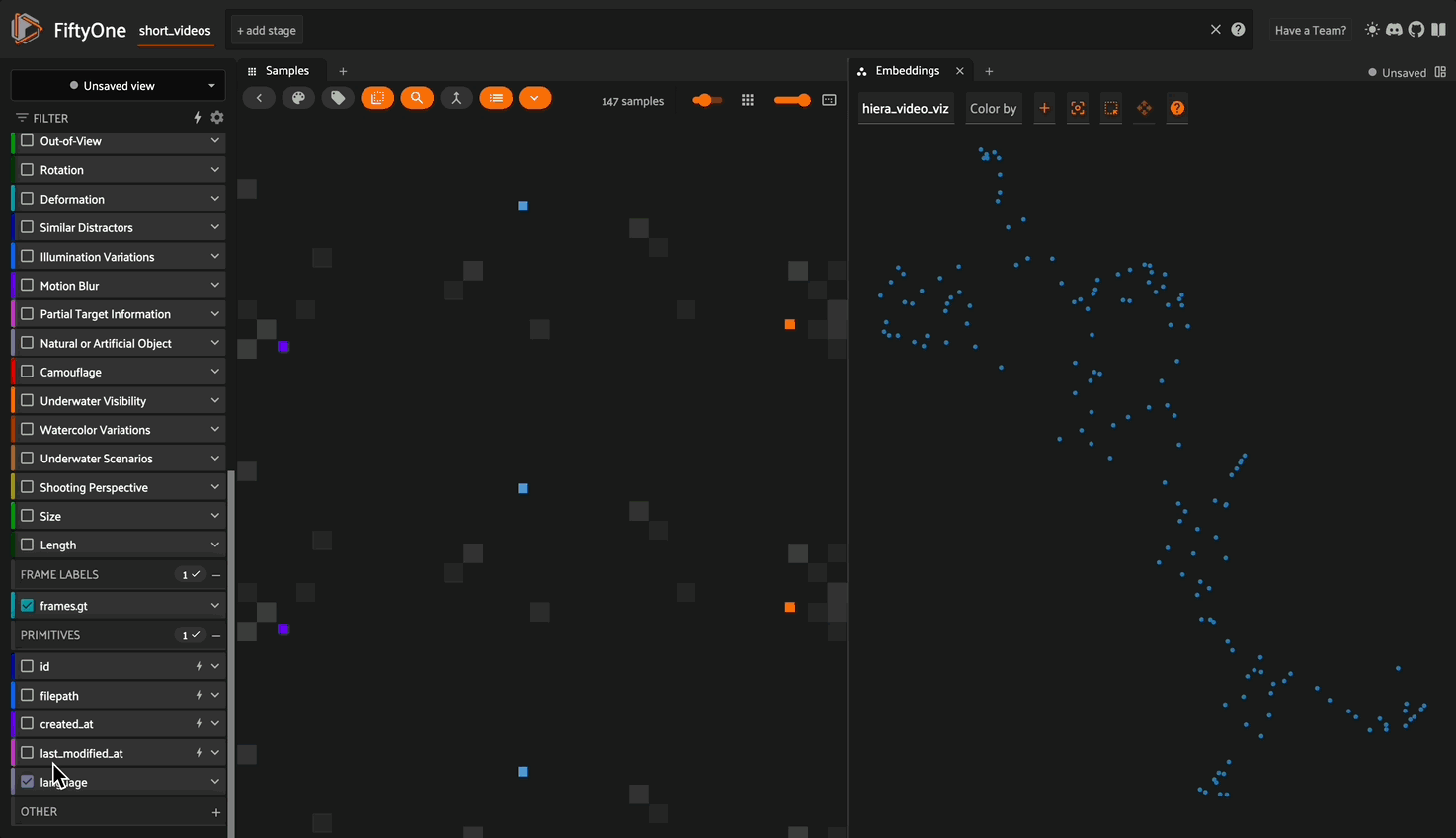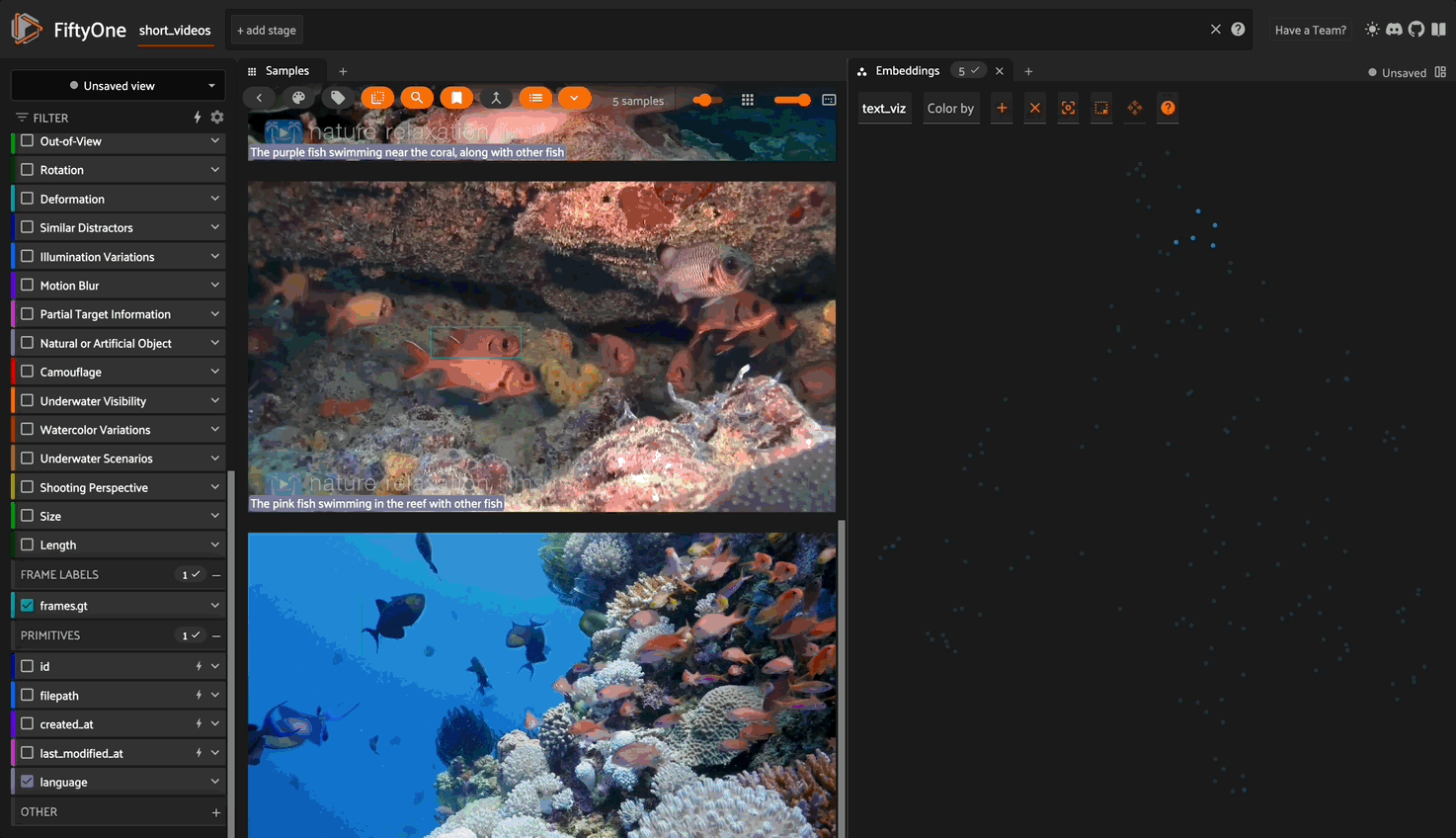
We can gain a deeper understanding of this dataset by computing and visualizing embeddings for the videos.
I’ve built a plugin which allows us to use the Hiera embedding model. FiftyOne’s plugin framework lets you extend and customize the functionality of FiftyOne to suit your needs.
If you’re interested in learning more about plugins, you might be interested in attending one of our monthly workshops. You can see the full schedule here and look for the Advanced Computer Vision Data Curation and Model Evaluation workshop.
The Hiera Embedding model from Facebook is a hierarchical vision transformer for efficient image and video understanding tasks. It combines speed with high accuracy by simplifying traditional transformer architectures while maintaining performance through masked autoencoder (MAE) pretraining. This video embedding model was pretrained on the Kinetics-400 (K400) dataset. The masked autoencoder objective forces the model to learn robust spatiotemporal patterns by reconstructing randomly masked video patches. This video-specific pre-training enables temporal understanding capabilities while maintaining the core hierarchical architecture developed through image training.
While not guaranteed, Hiera’s embeddings frequently retain semantic value even for OOD data (like what we’re working with) due to its sparse token hierarchy and MAE’s reconstruction-driven learning.
The main point is that we can compute video embeddings relatively easily with the plugin. Let’s start by downloading the plugin and installing its necessary dependencies.
!fiftyone plugins download https://github.com/harpreetsahota204/hiera-video-embeddings-plugin !fiftyone plugins requirements @harpreetsahota/hiera_video_embeddings --install
We’ll need to set an environment variable:
import os os.environ['FIFTYONE_ALLOW_LEGACY_ORCHESTRATORS'] = 'true'
Now, you can instantiate the operator for the plugin
import fiftyone.operators as foo
hiera_embeddings = foo.get_operator("@harpreetsahota/hiera_video_embeddings/compute_hiera_video_embeddings")
Alternatively, you can use the app and fill out the operator form. I’ll refer you to the GitHub repo for the plugin for more details.
This plugin supports all currently released versions and checkpoints of the Hiera Video Models collection:
- hiera_base_16x224
- hiera_base_plus_16x224
- hiera_large_16x224
- hiera_huge_16x224
It also supports two types of embeddings:
- Terminal Embedding (terminal): A 768-dimensional embedding vector derived from the final layer of the model. This represents the global semantic context of the video sequence. It can optionally be normalized.
- Hierarchical Embedding (hierarchical): A 1440-dimensional embedding vector that concatenates features across all intermediate outputs (96+192+384+768 = 1440 dimensions). This captures multi-scale representations of the video content. These embeddings cannot be normalized.
Sadly, the Hiera video embedding model struggles with long-duration videos.
We’ll work only with short-duration videos. I’m not too familiar with many video embedding models, but if you know of one that I should create a plugin that works well for longer-duration videos, please let me know. Note: the V-JEPA model for video embeddings is currently on the roadmap.
Luckily, you can easily filter your dataset as follows:
from fiftyone import ViewField as F
short_videos = dataset.filter_labels(
"Length", F("label").is_in(["short"])
).clone(name="short_videos")
This leaves us with 147 samples that we will work with going forward, which you can verify by running the following:
len(short_videos)
Before running the following cell, you must kick off a delegated operation. You can do this by opening your terminal and running:
fiftyone delegated launch.
Then, run the following command:
await hiera_embeddings(
short_videos,
model_name="hiera_base_plus_16x224",
checkpoint="mae_k400", #one of mae_k400 OR mae_k400_ft_k400
embedding_types="terminal", #or hierarchical
emb_field="hiera_video_embeddings",
normalize=True, #defaults to False, only works with `terminal` embeddings
delegate=True
)
Once this process is complete, let’s reload and persist the dataset:
short_videos.persistent = True short_videos.reload()
While we’re at it, let’s go ahead and compute embeddings for the video captions as well. For this, we’ll make use of Jina Embeddings V3:
import torch
from transformers import AutoModel
jina_embeddings_model = AutoModel.from_pretrained(
"jinaai/jina-embeddings-v3",
trust_remote_code=True,
device_map = "cuda" if torch.cuda.is_available() else "cpu"
)
We can run the model on our dataset and use the separation task as it’s suitable for visualizing clusters.
for sample in short_videos.iter_samples(autosave=True):
text_embeddings = jina_embeddings_model.encode(
sentences = [sample["language"]], # model expects a list of strings
task="separation"
)
sample["text_embeddings"] = text_embeddings.squeeze()
Now, we can compute a 2D representation of our high-dimensional embeddings using UMAP.
import fiftyone.brain as fob
embedding_fields = [ "hiera_video_embeddings", "text_embeddings"]
for fields in embedding_fields:
_fname = fields.split("_embeddings")[0]
results = fob.compute_visualization(
short_videos,
embeddings=fields,
method="umap",
brain_key=f"{_fname}_viz",
num_dims=2,
)
And from here we can visualize our embeddings in the app:
I think an interesting next step is applying SAM2 to this subset of data and seeing how it performs. To do that, start by installing the required dependencies for SAM2:
!pip install "git+https://github.com/facebookresearch/sam2.git#egg=sam-2"
FiftyOne has an integration with SAM2, and we can make use of that through the FiftyOne Model Zoo. The model zoo gives provides you native access to hundreds of pre-trained models.
import torch
import fiftyone.zoo as foz
sam_model = foz.load_zoo_model(
"segment-anything-2-hiera-tiny-video-torch",
device="cuda" if torch.cuda.is_available() else "cpu"
)
SAM2 (Segment Anything Model 2) offers powerful video segmentation capabilities.
Its key features include:
- Precise object segmentation and tracking across video frames
- Simple prompting methods:
- Bounding boxes
- Point selections
- Efficient workflow:
- Only requires prompts on the first frame.
- Automatically propagates segmentation masks to subsequent frames.
This means we can identify an object in the first frame of a video, and SAM2 will automatically track and segment that object throughout the entire sequence.
Once you’ve instantiated the model, the next step is to apply it to your dataset. Note that depending on the type of GPU you’re running this on, it can take quite a bit of time. For reference, I ran this on an NVIDIA RTX 6000 Ada, which took a little over an hour.
short_videos.apply_model(
sam_model,
label_field="sam_segmentations",
prompt_field="frames.gt", # Can be a detections or a keypoint field
)
Once the model has been applied to the dataset, we can look at the results in the app for a heuristics-driven visual vibe check of model performance.
From an initial visual inspection, it seems like SAM2 does a fairly good job of segmenting the objects of interest. There are some cases where the masks aren’t as tight, but given that this is an underwater dataset, it’s still quite impressive.
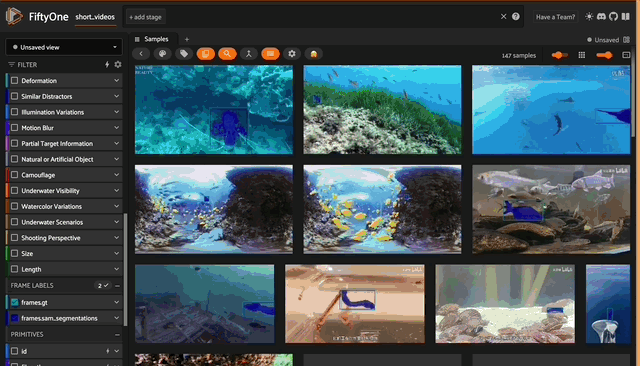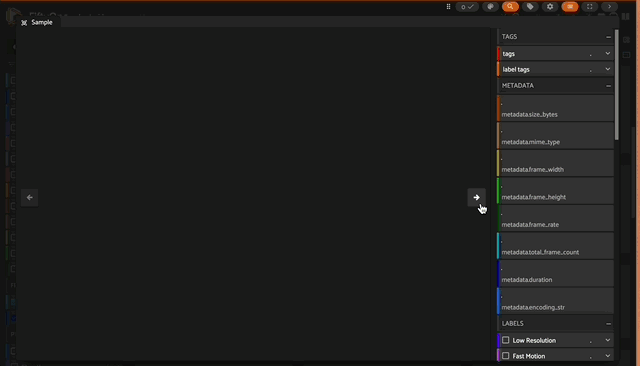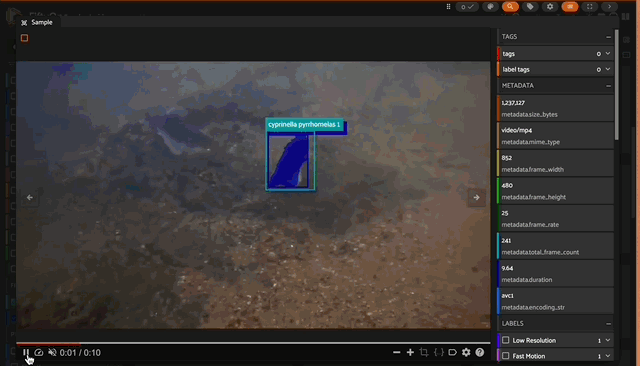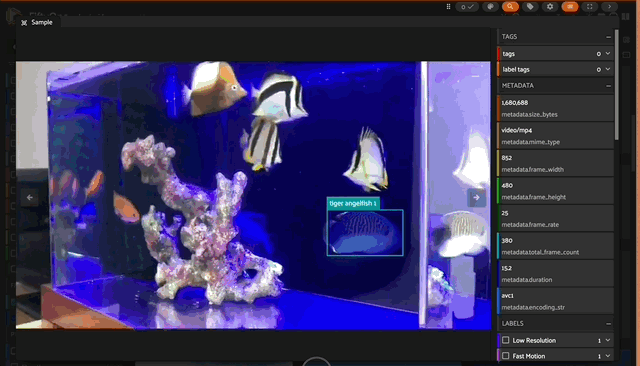 Exploring SAM2 predictions in the FiftyOne app
Exploring SAM2 predictions in the FiftyOne appHowever, what’s more impressive, at least from my initial visual vibe check, is the quality of the bounding boxes generated by SAM2. It seems the boxes are on point with, and at times tighter than, the ground truth boxes!
Of course, we can perform a more rigorous evaluation using the evaluate_detections method of the dataset and get some concrete number for model performance. Since the dataset doesn’t have ground truth annotations for segmentation masks, we can evaluate the predicted bounding boxes against the ground truth.
short_videos.evaluate_detections(
pred_field="frames.sam_segmentations",
gt_field="frames.gt",
eval_key="sam_eval",
iou=0.7
)
You can analyze the results of the evaluation right in the app via the Model Evaluation panel:
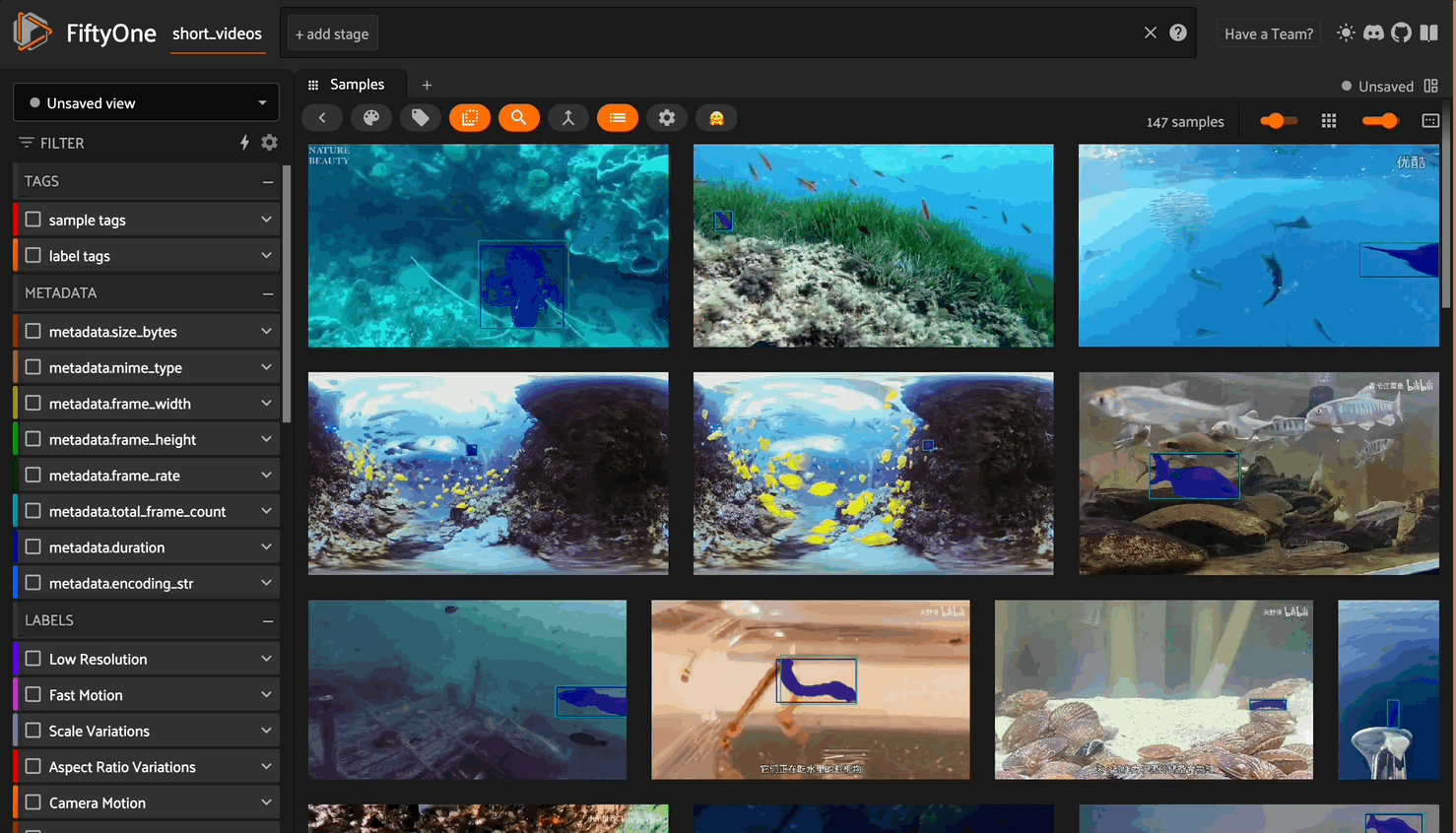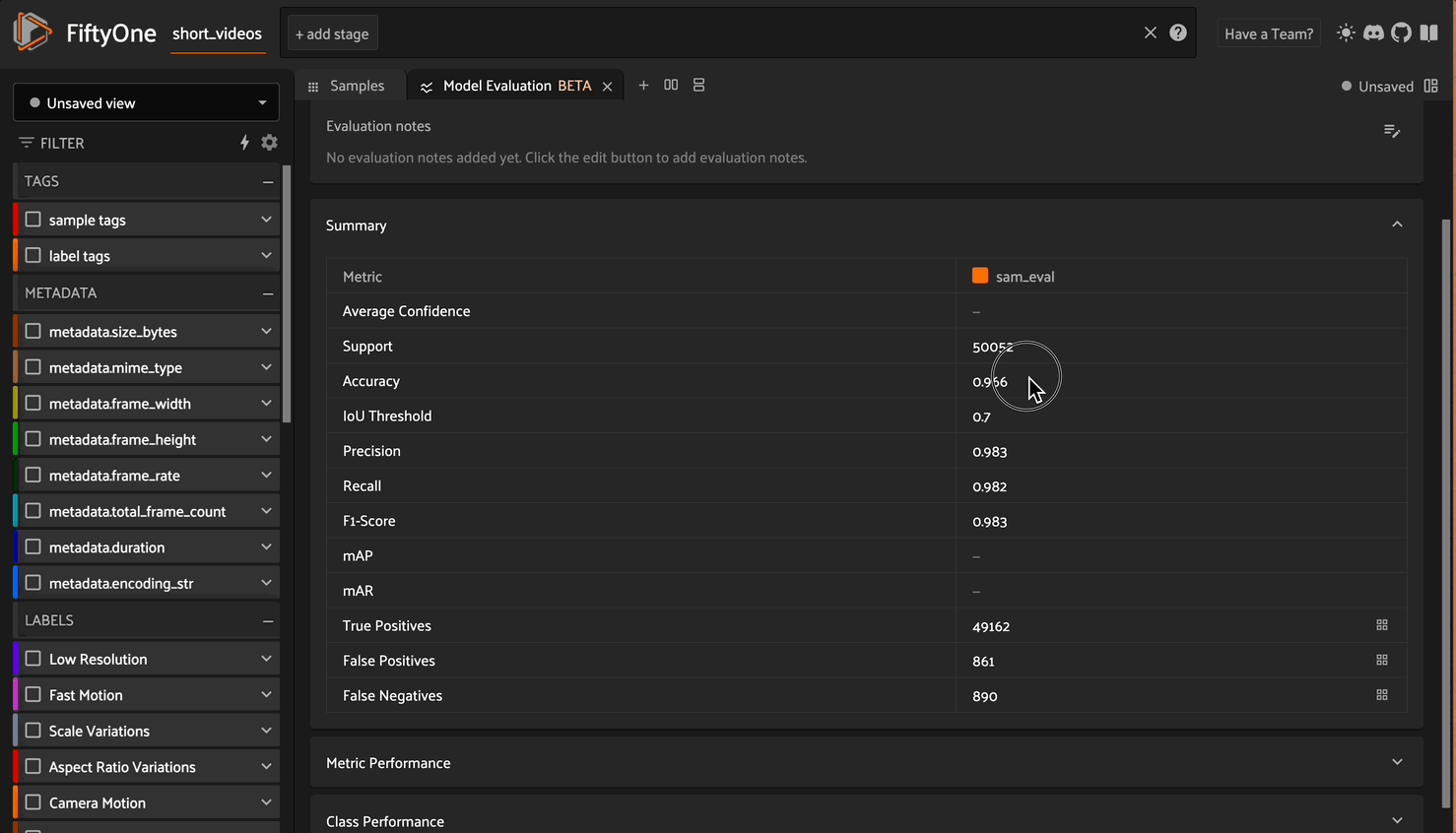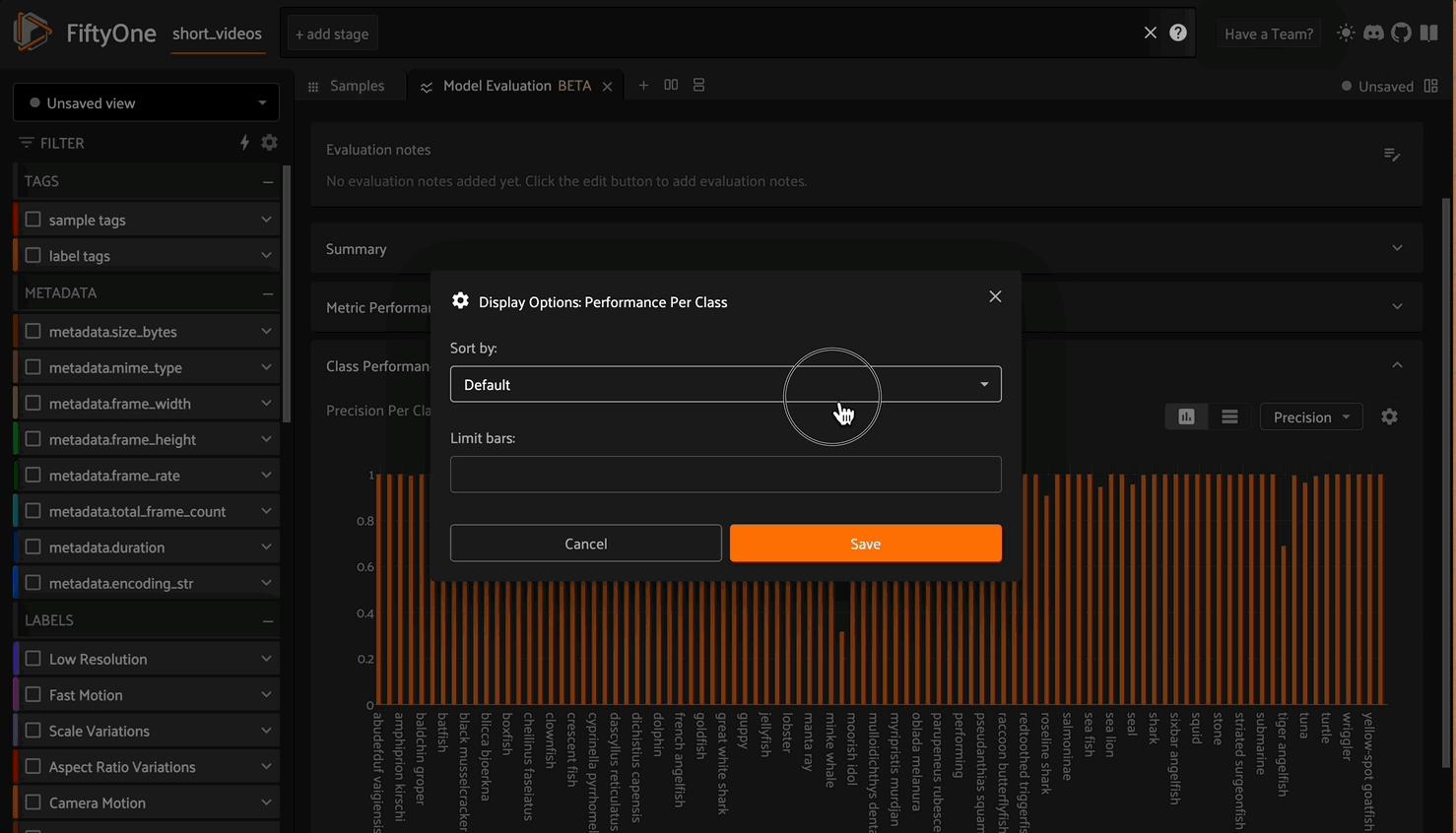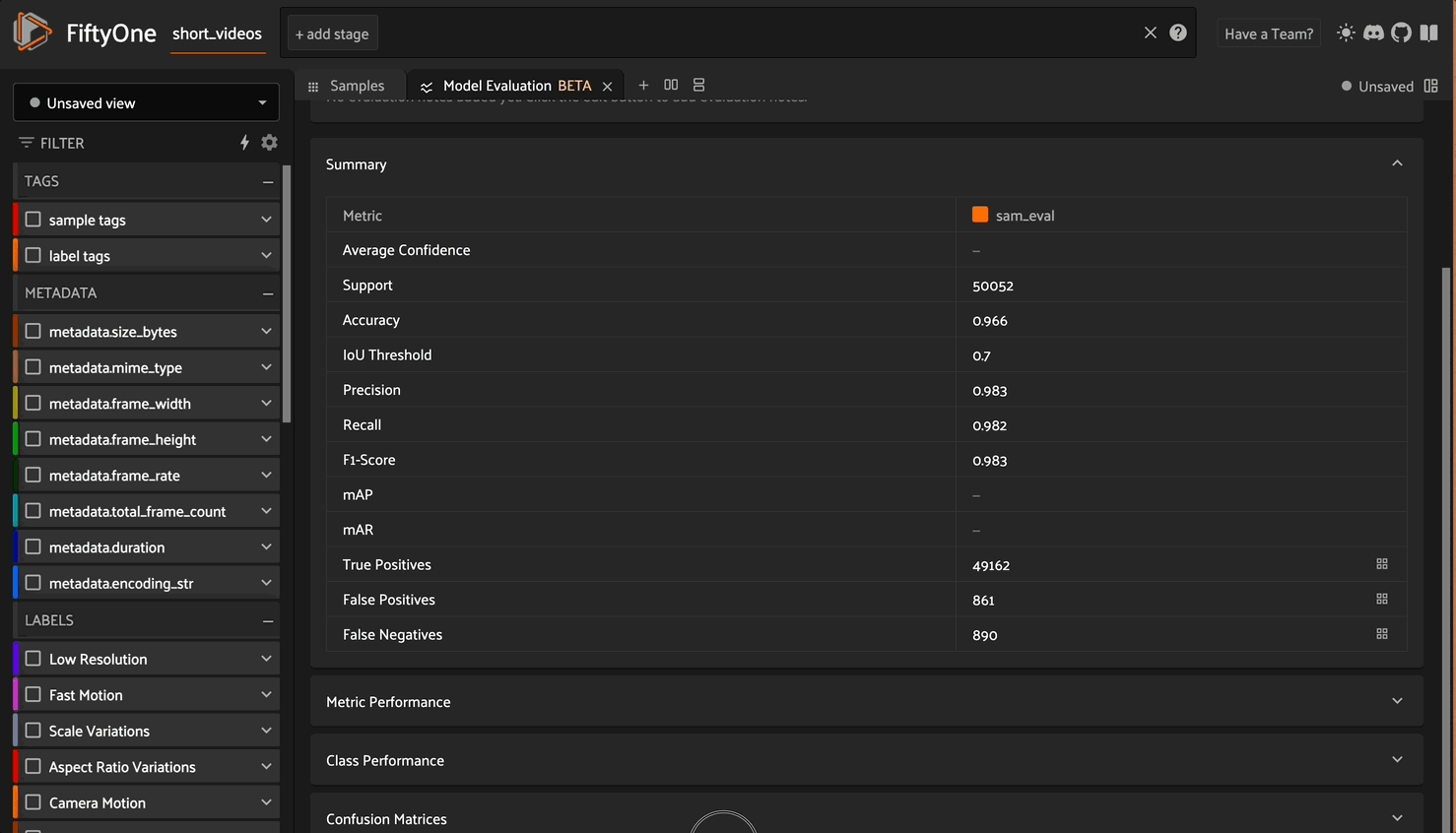
An important consideration
In this demonstration, we’re using SAM2 to showcase basic segmentation capabilities on underwater footage, focusing primarily on the spatial accuracy of masks and bounding boxes. For this simplified use case, we’ll evaluate the model using IoU (Intersection over Union) metrics to assess how well SAM2 can identify objects frame by frame.
However, it’s important to note that real-world underwater object tracking presents significantly more complex challenges.
While this SAM2 demonstration shows promising results for basic segmentation and bounding box tracking, a complete tracking solution would need more sophisticated components to handle these advanced tracking requirements. To illustrate concretely, suppose we’re concerned with tracking fish, then we need to consider (though the same considerations apply to any object tracking task):
- Identity Preservation: Maintaining track of a specific fish among similar-looking ones. For example, when tracking a particular clownfish in a group, the system must maintain its unique identity even when other clownfish cross its path.
- Distractor Handling: Not getting confused by other fish of the same species. The system must distinguish the target from visually similar fish that may enter the frame, even when they exhibit similar patterns or behaviors.
- Temporal Consistency: Maintaining the same ID across frames. This involves predicting motion patterns and understanding typical fish behaviors to maintain tracking even during quick movements or direction changes.
- Re-identification: Recognizing the same fish after temporary occlusion. When the target fish temporarily disappears behind coral or other fish, the system must be able to recognize and re-establish tracking when it reappears.
- Group Behavior Handling: Managing scenarios where fish (or other marine life) move in schools or groups, need more sophistication to maintain individual tracking within collective movement patterns.
So, while SAM2 is great for demonstrating segmentation capabilities, a production underwater tracking system would need additional components to handle the complex identity tracking challenges.
Check out this blog for more details.
Conclusion
In this exploration of the WebUOT dataset, we’ve demonstrated several key capabilities:
- Dataset visualization and exploration using FiftyOne
- Computing and visualizing video embeddings using the Hiera model
- Generating text embeddings using Jina Embeddings V3
- Applying SAM2 for object segmentation and detection
Our evaluation of SAM2’s performance on underwater footage shows promising results for basic segmentation tasks. However, this demonstration only scratches the surface of what’s needed for comprehensive underwater object tracking. Real-world applications require sophisticated systems that can handle identity preservation, temporal consistency, occlusion recovery, and group dynamics.
These challenges are particularly acute in underwater environments where factors like variable visibility, light refraction, and complex marine life behaviors come into play.