Understanding Dataset Difficulty with Class-Wise Autoencoders
February 4, 2025 – Written by Jason Corso
Classifying images—assigning a label to an image from a closed set of possible labels—is one of the original problems that drove the link between computer vision and machine learning. Despite the incredible strides in this area, the quality of datasets remains a critical factor in model performance. Contemporary visual AI systems rely on large, diverse, and high-quality datasets. Errors in labeling and variations in class complexity can significantly impact performance. Traditional approaches to evaluating dataset quality often rely on computationally expensive classifiers or heuristic methods with limited generalizability.
Our machine learning group at Voxel51 introduced a new, computationally efficient, and empirically validated method for measuring the difficulty of a dataset—a key element to dataset quality. Our approach uses class-wise autoencoders, which we call reconstructors, to measure classification difficulty. We introduce a simple but valuable metric called Reconstruction Error Ratios (RERs) to provide a fast, interpretable, and scalable way to assess dataset difficulty and detect mislabeled samples. In this post, we explore the intuition behind this method and summarize a key finding: RERs strongly correlate with classifier error rates, making them a powerful tool for dataset analysis.
The full technical paper is available on arXiv and example code is available on GitHub.
The Key Idea: Class-Wise Autoencoders
At its core, an autoencoder is a deep network trained to reconstruct its input. If an autoencoder is trained on a specific class of data, it becomes specialized in capturing the structure of that class. Naturally, a well-trained autoencoder should reconstruct samples from its own class with lower error than samples from other classes, assuming well-behaved data.
Building on this idea, we use class-wise autoencoders and train a separate autoencoder (a “reconstructor”) for each class in a dataset. When a new sample is passed through these reconstructors, we measure how well each one reconstructs the sample.
Importantly, the reconstruction error alone is not too useful in helping us understand much about generalizable properties of dataset quality or difficulty. So, we introduce Reconstruction Error Ratios (RERs) as a mechanism to serve this purpose. We propose a specific RER in the paper that is the ratio between the reconstruction error for a sample’s labeled-class reconstructor to the reconstruction error of the sample from the alternative class with the lowest error.
If a sample is easily reconstructed by the correct class’s autoencoder, this RER is low. If an alternative class’s autoencoder performs comparably or better, the RER is high, suggesting ambiguity in classification.
Why This Matters
This RER is a sample-level probe that provides a quantitative measure of classification difficulty without needing to train a full-scale classifier. The reconstructors themselves are trained on just a tiny subset of each class’s labeled data (e.g., 100). Unlike conventional methods, which require a deep classifier to be trained on the dataset, RERs can be computed quickly using shallow autoencoders trained on feature representations from a foundation model like CLIP or DINOv2. The figure below shows this RER value for a subset of the samples in CIFAR-10 dataset across all ten classes.

Additionally, these sample-level probes can be averaged over classes and over the full dataset to provide insights at multiple levels:
- Sample-level: How difficult is it to classify a specific image?
- Class-level: Which classes are inherently more difficult to separate?
- Dataset-level: How challenging is the dataset as a whole?
Yes, this means we can do minimal computation over a dataset to get a sense of its “average difficulty.” But, does this work?
A Key Finding: RERs Predict Classification Performance
One of the most striking results from our work is that these dataset-level RERs correlate strongly with the performance of state-of-the-art classifiers. By evaluating RERs across 19 popular visual datasets, researchers found a high correlation between dataset difficulty (as measured by RERs) and the error rates of top classifiers reported in PapersWithCode.
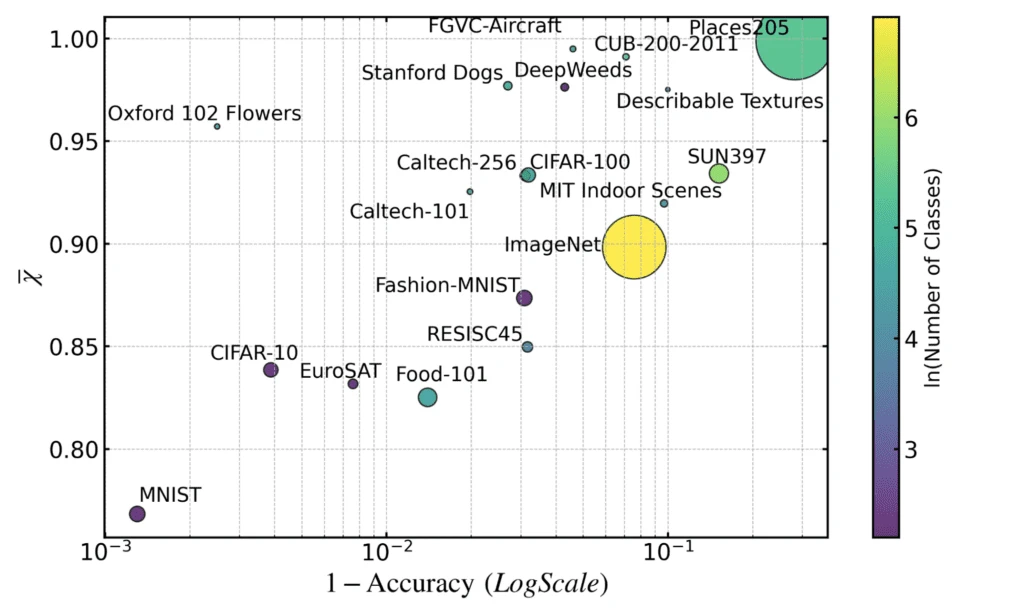
This finding suggests that RERs can serve as a proxy for classifier performance without the need for training large-scale models. Specifically:
- Harder datasets (higher average RERs) tend to have lower classification accuracy.
- Easier datasets (lower average RERs) correlate with higher classification accuracy.
- Some datasets contain noisy or mislabeled samples that have abnormally high RERs.
This is just one of the empirical findings about dataset difficulty in the main report. Others include a concrete estimate of dataset difficulty independent of sample size, analysis of error rates of a dataset, and the ability to detect label mistakes. Perhaps we’ll cover some of these in future blogs.
Conclusion: Why RERs Matter in Real-World AI
Class-wise autoencoders and RERs offer a simple, scalable, and interpretable way to assess dataset difficulty and detect label errors. By leveraging shallow autoencoders trained on feature representations, this method bypasses the need for expensive model training while providing rich insights into dataset quality.
Summarily, by systematically analyzing dataset difficulty using RERs, AI practitioners and researchers can estimate the potential improvement from collecting more data versus the inherent limits imposed by class structure. And, they can do so without the labor and cost of training many large-scale, expensive models.
This research opens exciting possibilities for data-centric AI, including:
- Benchmarking datasets before model training.
- Efficiently curating high-quality datasets.
- Identifying and correcting mislabeled samples.
With the increasing importance of high-quality datasets in AI, techniques like RERs could become essential tools for dataset evaluation and improvement. And, at Voxel51, we are working hard to build them into our leading AI developer tooling, FiftyOne Teams.
To explore the code and try RERs on your own datasets, check out the original paper and the open-source implementation at Voxel51’s GitHub.
Acknowledgments
This blog gently introduces technical work done by Jacob Marks, Brent Griffin and myself. Thank you to my colleagues Kirti Joshi, and Michelle Brinich for reviewing this blog and providing great feedback.
Biography
Jason Corso is Professor of Robotics, Electrical Engineering and Computer Science at the University of Michigan and Co-Founder / Chief Science Officer of the AI startup Voxel51. He received his PhD and MSE degrees at Johns Hopkins University in 2005 and 2002, respectively, and a BS Degree with honors from Loyola University Maryland in 2000, all in Computer Science. He is the recipient of the University of Michigan EECS Outstanding Achievement Award 2018, Google Faculty Research Award 2015, Army Research Office Young Investigator Award 2010, National Science Foundation CAREER award 2009, SUNY Buffalo Young Investigator Award 2011, a member of the 2009 DARPA Computer Science Study Group, and a recipient of the Link Foundation Fellowship in Advanced Simulation and Training 2003. Corso has authored more than 150 peer-reviewed papers and hundreds of thousands of lines of open-source code on topics of his interest, including computer vision, robotics, data science, and general computing. He is a member of the AAAI, ACM, MAA and a senior member of the IEEE.
Disclaimer
This article is provided for informational purposes only. It is not to be taken as legal or other advice in any way. The views expressed are those of the author only and not his employer or any other institution. The author does not assume and hereby disclaims any liability to any party for any loss, damage, or disruption caused by the content, errors, or omissions, whether such errors or omissions result from accident, negligence, or any other cause.
Copyright 2025 by Jason J. Corso. All Rights Reserved.
No part of this publication may be reproduced, distributed, or transmitted in any form or by any means, including photocopying, recording, or other electronic or mechanical methods, without the prior written permission of the publisher, except in the case of brief quotations embodied in critical reviews and certain other noncommercial uses permitted by copyright law. For permission requests, write to the publisher via direct message on LinkedIn at https://www.linkedin.com/in/jason-corso/