Featured Resource

Featured Case Study

Classification in Computer Vision
Classification in computer vision is the task of assigning category labels to images. In an image classification problem, a model analyzes an entire image and predicts which class (or classes) the image belongs to. For example, a classifier might determine that a given photo is of a cat, a dog, or a bird. This is one of the fundamental problems in computer vision, and modern deep learning approaches (like convolutional neural networks) have achieved remarkable success on classification tasks – a famous example being the ResNet architecture that won the 2015 ImageNet competition.
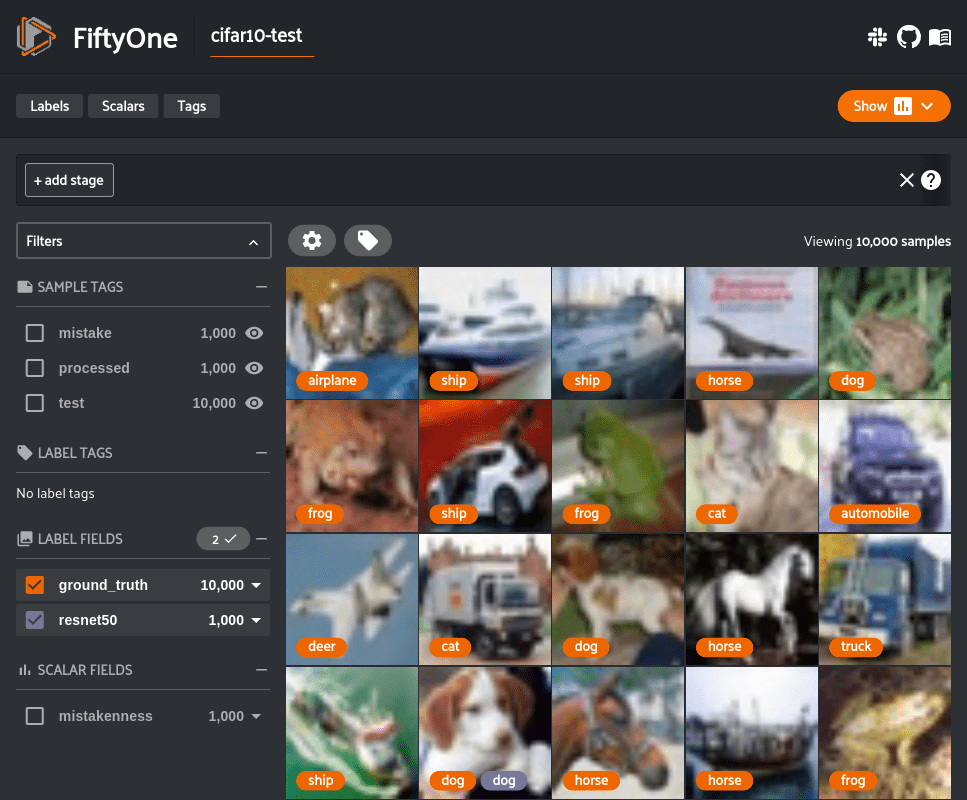
Single-Label vs Multi-Label Classification
There are two main flavors of image classification: single-label and multi-label. In single-label (or multi-class) classification, each image is assigned one label from a set of mutually exclusive classes. For instance, an animal photo might be classified either as “cat” or “dog” but not both. In multi-label classification, an image can have multiple labels simultaneously. This is useful when images can contain multiple objects or attributes at once. For example, a single photograph could be labeled with both “cat” and “dog” if it contains one of each, or with tags like “indoor”, “sofa”, and “person” to describe everything present. Multi-label classifiers output a set of relevant labels for each image rather than just one.
Datasets and Real-World Examples
Large labeled datasets have driven the progress of image classification. The ImageNet dataset is a prime example. It contains over 14 million annotated images across tens of thousands of categories and has been the basis of the influential ImageNet Large Scale Visual Recognition Challenge (ILSVRC). Models trained on the 1,000-category subset of ImageNet have become benchmarks for classification performance. Other common datasets include CIFAR-10 (60,000 tiny images in 10 classes) and MNIST (handwritten digits), among many others.
In the real world, image classification is used in a huge variety of applications. Some notable examples include:
- Photo organization: automatically tagging and grouping images (e.g., labeling vacation photos as “beach”, “birthday”, “pets”).
- Content moderation: identifying and filtering inappropriate or sensitive images on social media platforms.
- Medical imaging: classifying X-rays or MRI scans to detect diseases (for example, predicting “tumor” vs “no tumor” in an image).
- E-commerce: Categorizing product images into categories (for instance, classifying clothing images into “t-shirts”, “shoes”, “hats”).
Evaluation Metrics
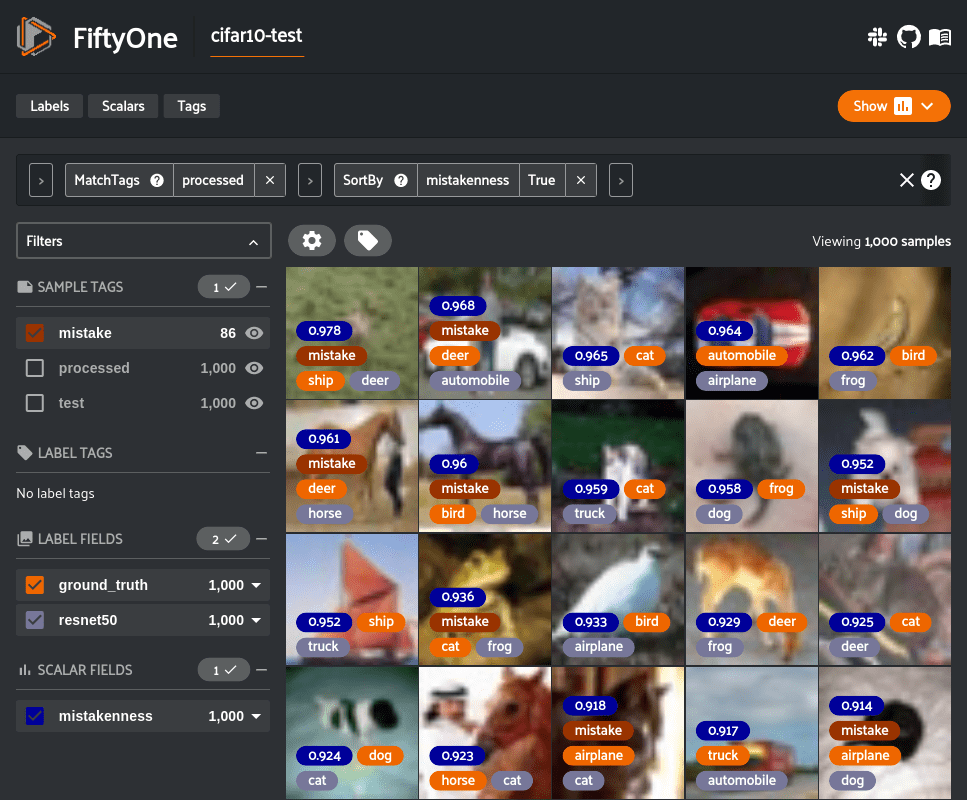
Evaluating an image classifier involves checking how well its predicted labels match the true ground truth labels. The simplest metric is accuracy, which is the percentage of images correctly classified overall. While accuracy is easy to understand, it can be misleading if the dataset is imbalanced (e.g. if some classes are much more common than others). To get a more complete picture, we often look at precision and recall for each class. Precision measures how many of the items that the model labeled as a given class were actually that class, and recall measures how many of the actual items of that class the model successfully found. We can also compute the F1-score which is the harmonic mean of precision and recall, providing a single number that balances both. These metrics can be calculated for each class and summarized in a classification report.
Modern computer vision libraries and tools help generate these metrics. For example, the open-source tool FiftyOne provides built-in methods to evaluate classification models, outputting standard metrics like classification reports, confusion matrices, and precision-recall curves, and even recording per-sample statistics that you can explore interactively.
Classification vs. Detection vs. Segmentation
It’s important to distinguish image classification from other vision tasks like object detection and image segmentation. In image classification, the output is just labels for the whole image (no localization). Object detection goes a step further – it not only classifies objects but also locates them in the image by drawing bounding boxes around each identified object. Segmentation is even more granular: it assigns a class label to each pixel in the image, effectively outlining the exact shape of objects or regions.
Further Tools and Resources
Because of its central role, image classification has a rich ecosystem of models and tools. As mentioned, deep learning models like ResNet and its variants are go-to architectures for image classification. There are also many pre-trained models available that can be fine-tuned for new classification tasks. FiftyOne’s Model Zoo offers a convenient way to download and apply pre-trained classification models to your own datasets with just a few commands. For more on evaluating classifiers, you can refer to FiftyOne’s documentation on model evaluation, which explains how to generate metrics and inspect misclassifications.
Want to build and deploy visual AI at scale?
Talk to an expert about FiftyOne for your enterprise.
Open Source
Like what you see on GitHub? Give the Open Source FiftyOne project a star
Community
Get answers and ask questions in a variety of use case-specific channels on Discord