Featured Resource

Featured Case Study

How Automated Data Labeling Enhances Computer Vision Efficiency and Accuracy
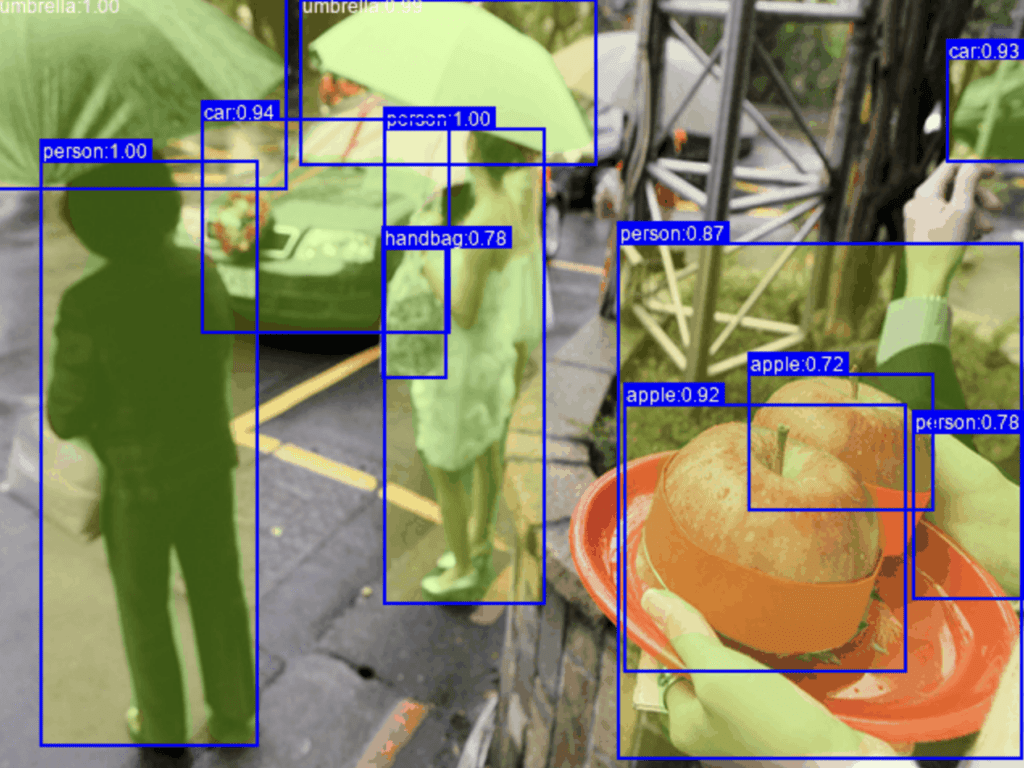
The animation above demonstrates how computer vision algorithms detect, classify, and segment objects, converting raw visual data into structured training data. Industries today generate vast amounts of image and video content, creating demand for labeling methods that exceed the capabilities of traditional manual annotation. Automated data labeling techniques have emerged as effective solutions, providing scalable, precise, and efficient approaches for building high-quality datasets essential for machine learning and artificial intelligence applications.
As machine learning and artificial intelligence drive innovation across industries like healthcare, automotive, retail, and security, the rapid growth in image and video data requires efficient annotation methods. Traditionally, labeling this data has been manual, slowing projects and increasing costs. However, automated data labeling technologies now revolutionize dataset creation by improving both accuracy and efficiency. This article explores the transition from manual to automated labeling, highlights key enabling technologies, and demonstrates how FiftyOne simplifies annotation workflows, helping data scientists and AI practitioners rapidly scale their algorithms without compromising data quality.
The Rise of Computer Vision (CV)
Over the last decade, we’ve seen computer vision evolve from an obscure research field into a mission-critical technology. Automotive manufacturers employ CV-based machine learning for self-driving systems; healthcare providers rely on it for disease detection via medical imaging; retail giants use object detection to track items; and government agencies harness it for security surveillance. In short, computer vision pervades countless applications in modern life.
The Importance of Labeled Datasets
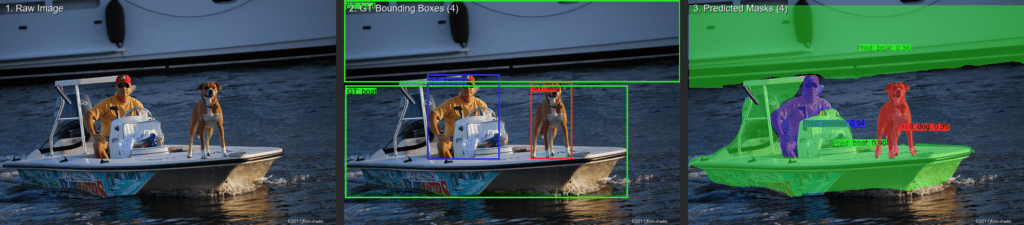
Behind every successful machine learning or CV application is a robust training dataset of images or videos annotated with relevant objects, classes, or attributes. Accurate labels enable machine learning models to interpret visual data effectively and generalize to new inputs, while incomplete or inconsistent datasets negatively impact a model’s performance. Annotations serve as reference points during both training and validation, helping models refine predictions by providing clear examples of correct object classification, segmentation, and localization. Accurate labels clearly delineate object boundaries and consistently represent object classes, whereas inaccurate labels often misrepresent object locations, sizes, or categories, leading to errors and reduced model reliability.
The Challenge of Manual Data Labeling
Although labeled data is critical, manual labeling is labor-intensive, prone to fatigue, bias, and human error, especially with thousands or millions of images. As datasets grow, manual annotation increasingly becomes a bottleneck, driving organizations toward automated labeling solutions that significantly reduce human effort while maintaining or enhancing labeling quality.
The Bottleneck of Manual Data Labeling
Manual Data Labeling Workflow
Historically, the manual data labeling process for computer vision has looked like this:
-
- Identify objects/features: An annotator locates items of interest in each image or video frame (e.g., bounding boxes around cars, tumors in scans).
- Assign labels: Each object or region receives an appropriate label (e.g., “person,” “car,” “tumor”).
- Quality check: A second round of review might spot inconsistencies or mistakes.
Though direct, this becomes overwhelming with millions of data points, introducing several challenges associated with manual labeling, outlined in the table below:
| Challenge | Description |
| Time and Cost | Employing human annotators or external services is expensive and slow. Large-scale labeling tasks can span weeks or months. |
| Inconsistencies | Even expert teams may label data differently, introducing subjective bias (e.g., varying interpretations of partial occlusions). |
| Scaling Limits | Manually annotating datasets that require continuous updates (like autonomous vehicle footage) quickly becomes cumbersome and impractical. |
These difficulties underscore the necessity of automated data labeling for modern, large-scale computer vision initiatives.
Enter Automated Data Labeling: A Game Changer
What is Automated Data Labeling?
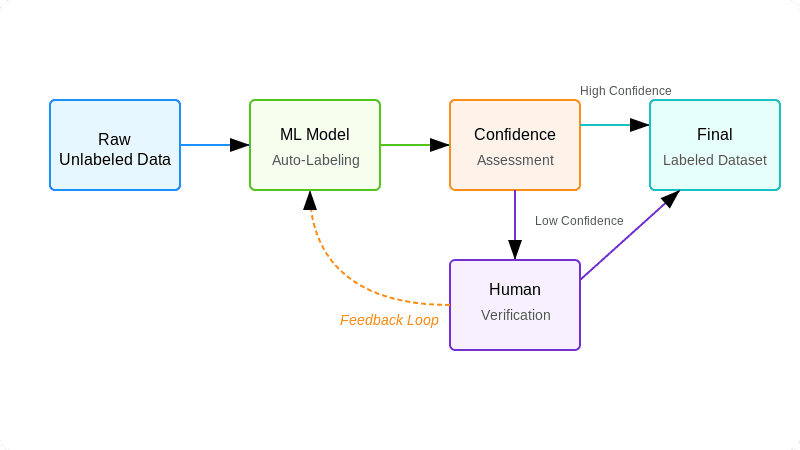
Automated data labeling, or auto labeling, seeks to automate data labeling tasks, reducing human involvement by leveraging machine learning pipelines or pre-trained models to suggest labels, limiting human input primarily to validation or targeted corrections. Techniques include semi-supervised learning, active learning loops, and using pre-trained networks for rapid labeling of new datasets.
Techniques for Automated Data Labeling
-
- Active Learning: The system flags uncertain or highly informative samples for human review, while it auto-labels straightforward examples.
- Weakly Supervised Learning: Partial or uncertain labels are refined using high-level rules. A bounding box guess might be adjusted by the system.
- Leveraging Pre-Trained Models: A model trained on broad data (e.g., ImageNet) annotates new samples, which humans then refine. Iterating these improvements can train the model further, creating a virtuous cycle.
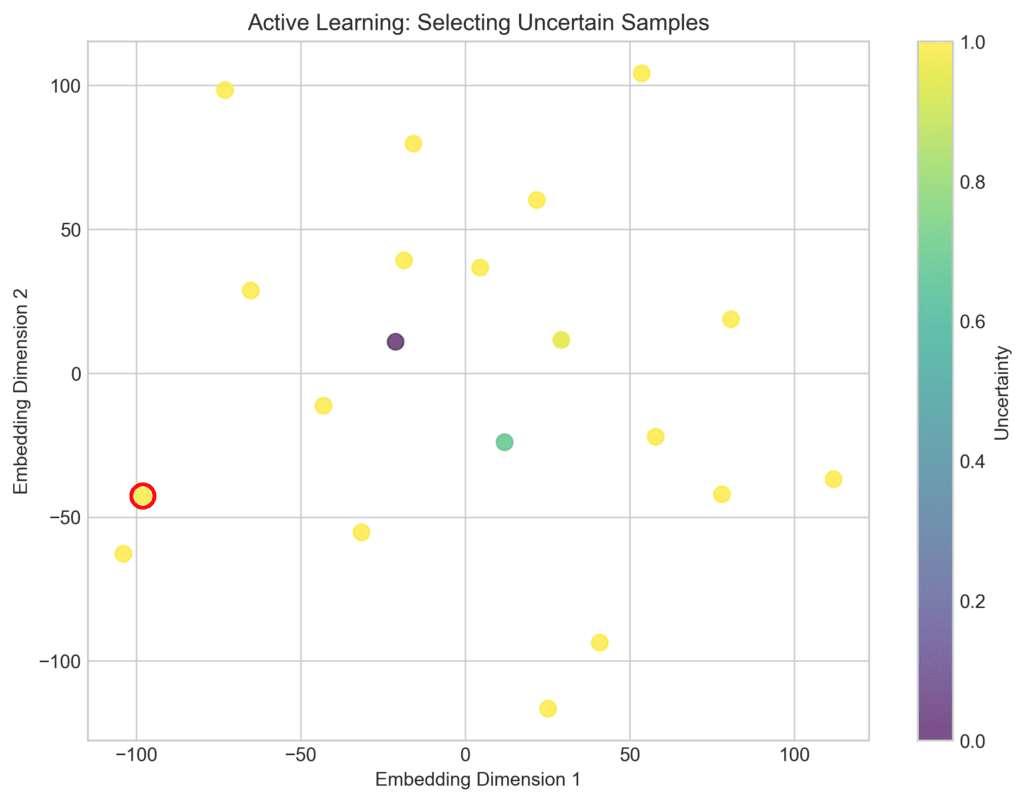
The Benefits of Automated Data Labeling for Efficiency
One standout advantage of automated data labeling is the dramatic reduction in time and costs, achieved by using machine learning algorithms for bulk annotation tasks; this results in quicker dataset turnarounds and allows human effort to be reserved for more complex or ambiguous edge cases.

Improved Scalability
Manual efforts might suffice for modest projects, but fail to scale for massive data streams. Automated pipelines, however, improve with volume:
-
- Effectively handle vast, diverse datasets
- Adapt quickly to dynamic environments, like new road signs or store layouts
Consistency and Reduced Bias
Humans can inadvertently produce inconsistent labels, especially under pressure. Automated systems employ the same logic every time, generating uniform bounding boxes, categories, or segmentation masks, resulting in more consistent automated data. This uniformity reduces label noise and boosts overall dataset quality.
Enhanced Accuracy with Automation: Beyond Efficiency
Automated data labeling enhances accuracy by enabling the annotation of a wider variety of images, including rare cases and complex features often tedious for humans, leading to better model generalization. Additionally, these systems continuously improve their own precision over time by learning from human feedback through confirmation and correction loops.
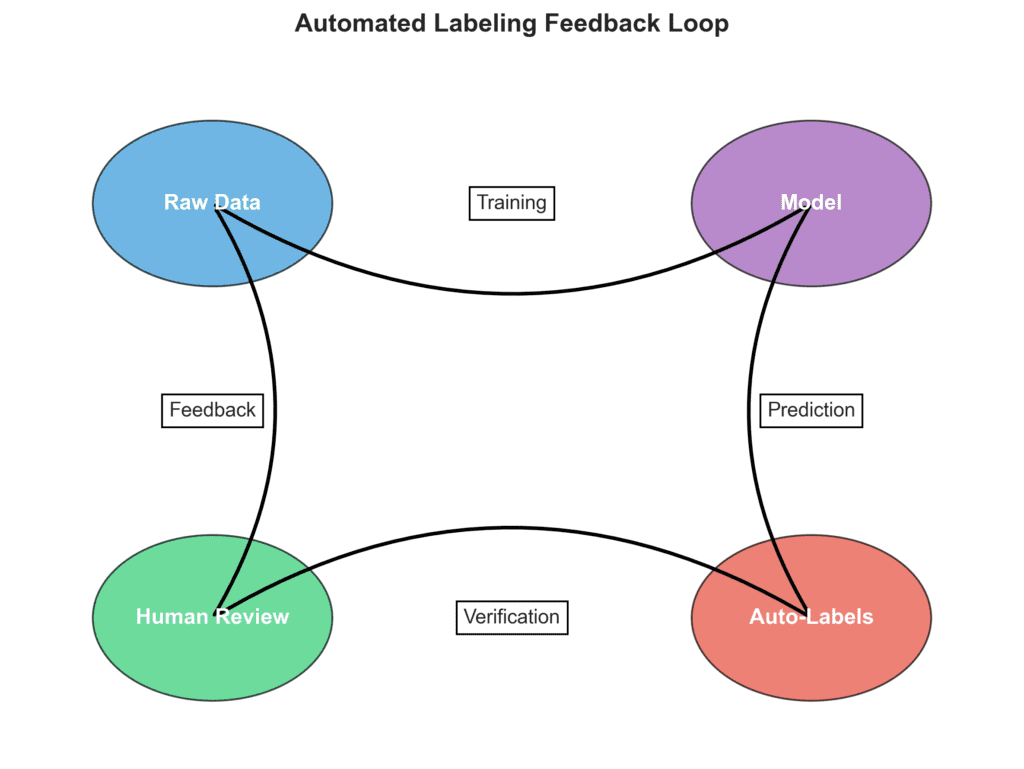
Leveraging FiftyOne for Advanced Labeling
Practical automated labeling requires strong infrastructure for dataset management, refinement, and quality control. Enter Voxel51’s open-source tool, FiftyOne, which supports every stage of your computer vision workflow.
FiftyOne’s Role in Automated Data Labeling
FiftyOne integrates with various ML frameworks and active learning setups, acting as a central hub for:
-
- Uploading and versioning unlabeled data
- Merging auto-labeled results from models or weak supervision
- Visualizing annotations in a user-friendly interface
- Allowing rapid validation and edits
By consolidating data and tools, FiftyOne helps you assess label consistency and overall dataset integrity in one place.
Key FiftyOne Features for Data Labeling
- Integration with Active Learning Frameworks
FiftyOne pinpoints ambiguous data points that need human attention. Updated labels are fed back to retrain the system. - Refinement Tools
If bounding boxes or categories are somewhat accurate, FiftyOne’s GUI allows quick corrections. This human-in-the-loop synergy maintains quality without starting from scratch.
- Collaboration Features
Teams often have multiple subject matter experts. FiftyOne lets users share datasets, track annotation changes, and unify feedback, ensuring consistent labeling and accountability.
Real-World Applications: Automation in Action
Medical Imaging
In healthcare, MRI or X-ray images often require labeling to detect tumors or fractures. Automated labeling pinpoints potential anomalies, drastically reducing a radiologist’s effort. This shorter cycle propels machine learning-driven diagnostics and speeds up critical refinements.
Self-Driving Cars
Autonomous vehicle systems rely on huge datasets containing cars, pedestrians, and road elements. Automated labeling rapidly annotates camera feeds, letting self-driving companies adapt to changing conditions. As roads evolve, these pipelines keep the labeled data current without overtaxing human teams.

Retail Object Recognition
Retailers monitor inventory, warehouse workflows, and customer interactions through CV. Automated labeling supports swift recognition of new products, quick re-annotation for seasonal changes, and accurate tracking despite constantly shifting store layouts. This ensures models stay relevant without relentless manual interventions.
Future Trends in Automated Labeling
Future trends in automated labeling include emerging techniques like using Natural Language Processing (NLP) to create richer, context-aware semantic annotations by linking textual descriptions to images, and employing self-supervised learning models that train on unlabeled data to become proficient at auto-labeling with reduced human intervention.
Fully Automated Labeling Pipelines
While expert oversight may still be necessary, routine labeling tasks are rapidly approaching full automation, particularly in familiar domains. Feedback loops continually refine algorithms, enabling near real-time generation of labeled data. Ultimately, we’re moving toward on-demand systems where prior knowledge automatically annotates datasets, humans provide essential corrections, and the process iterates seamlessly.
Final Insights
The Power of Automated Data Labeling
Automated labeling marks a pivotal shift for machine learning and computer vision. By taking over repetitive annotation, teams reduce costs, expedite model development, and broaden project scopes. Crucially, automating labeling can also improve quality, ensuring thorough coverage of complex, real-world data.
How FiftyOne Empowers AI Builders:
Even top-tier auto-labeling gains from comprehensive data management. Voxel51’s FiftyOne helps data scientists:
-
- Incorporate varied labeling methods (weak supervision, active learning, or pre-trained predictions).
- Quickly refine results with human-in-the-loop edits.
- Collaborate with domain experts.
- Analyze label consistency and dataset balance to ensure thoroughness.
Accelerate Your Computer Vision Workflow Today
Whether you are building diagnostic tools, self-driving systems, or advanced retail analytics, embracing automated labeling can help you outpace manual bottlenecks. With the right pipelines and platforms like FiftyOne, you achieve scalable, high-quality results that adapt with incoming data. Consider integrating automated labeling into your CV workflow now to unlock faster, more accurate model outcomes.
Image Citations
-
- Lin, Tsung-Yi, et al. “Microsoft COCO: Common Objects in Context.” COCO Dataset 2017 Validation Split, cocodataset.org, 2017, https://cocodataset.org/#home. Accessed 24 Mar. 2025.