Elevate Your GitHub README Game
December 5, 2023 – Written by Jacob Marks
Lessons Learned Creating 25 GitHub Repos in 2023
Over the past year, I’ve created a lot of GitHub repositories. Some of these repositories, such as my 10 Weeks of Plugins repo, are effectively aggregators — centralized locations that I can drive people to, almost like a personal Awesome list. Other repositories like VoxelGPT contain many moving pieces. Others still like Papers with Data are essentially minimum viable products for websites!
Across all 25+ projects that I created, perhaps the sole unifying element is the README. The README is often the first encounter someone has with your project. It’s your virtual welcome mat — your chance to make a lasting impression. In other words, a few lines of Markdown can make the difference between a potential user giving your project a try or saying an abrupt goodbye.
Despite its importance, the README is all too often an afterthought for open source project creators. Every day, software developers, researchers, and hobbyists are solving real problems, but leaving stars, installs, and contributions on the table.
Crafting a compelling README is as much an art as it is a science, and every creator should think deeply about how they want their project to come across to others. That being said, it doesn’t hurt to add some new tools to your README writing toolkit!
In this post, I’ll share some of my favorite tips and tricks for creating a better README. Some of these are Markdown or HTML tricks, others are GitHub-specific, and some regard the applications I’ve found most useful. Broadly, I’ve divided these lessons into three categories: gifs, links, and tables. For a comprehensive README template, check out the accompanying Ultimate GitHub Project README repo!
- GIFs
- Links
- Tables
GIFs
GIFs are a great way to add some life to your README. You can employ a GIF as a highlight reel for features or functionality in your project, or even as a visual walk-through of the installation and setup instructions.
Recording GIFs
In order to record high-quality non-branded GIFs of my screen, I use Gifox. There is a one-time cost for the pro version, but it’s well worth it for the simplicity of recording and editing GIFs that it makes possible.
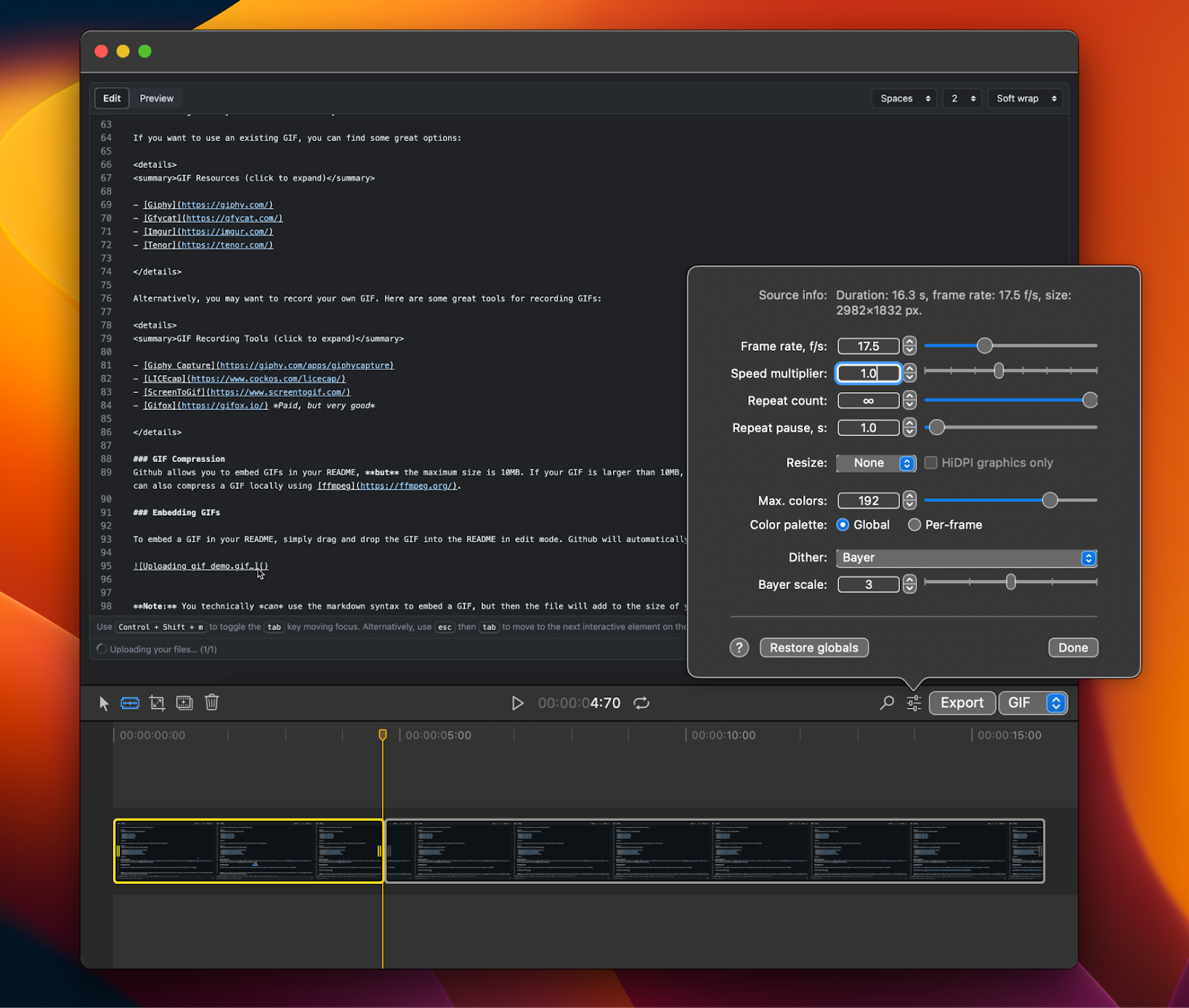
Screenshot of the Gifox GIF editor
In the Gifox editor, you can chop the recording up, stitch segments together, and adjust the frame rate, speed, and palette.
💡I’ve also found that Loom’s screen recording works pretty well, and Loom’s free version is very generous.
GIF Compression
If you’re creating a screen recording with significant frame-to-frame motion, or a recording that lasts longer than a few seconds, there’s a good chance that it will weigh in at 20MB, 30MB, or perhaps even more. I’ve even had GIFs larger than 100MB!
Try to add those GIFs into your README and you’ll run into a problem — GitHub caps the allowed size for uploaded GIFs at 10MB. Fortunately, there are a few ways to address this issue.
- Reduce frame rate: For many screen capture applications, the default frame rate is 15-24 frames per second. To illustrate a feature for your project you likely don’t need that! Lowering to around 10 frames per second should be fine.
- Reduce color palette: In the same vein, you may not need 256 colors to get a point across. ImageMagick is a free tool that allows you to change the palette from the command line. For example,
convert input.gif -colors 200 output.gifwill save a new GIF with 200 colors. - Reduce size and/or quality: Free online tools like XConvert give you control over the size and quality of your GIF. The default options often reduce file size by 60-70%, and if you compromise a bit on GIF quality you can compress the GIF down to <10% of its original size!
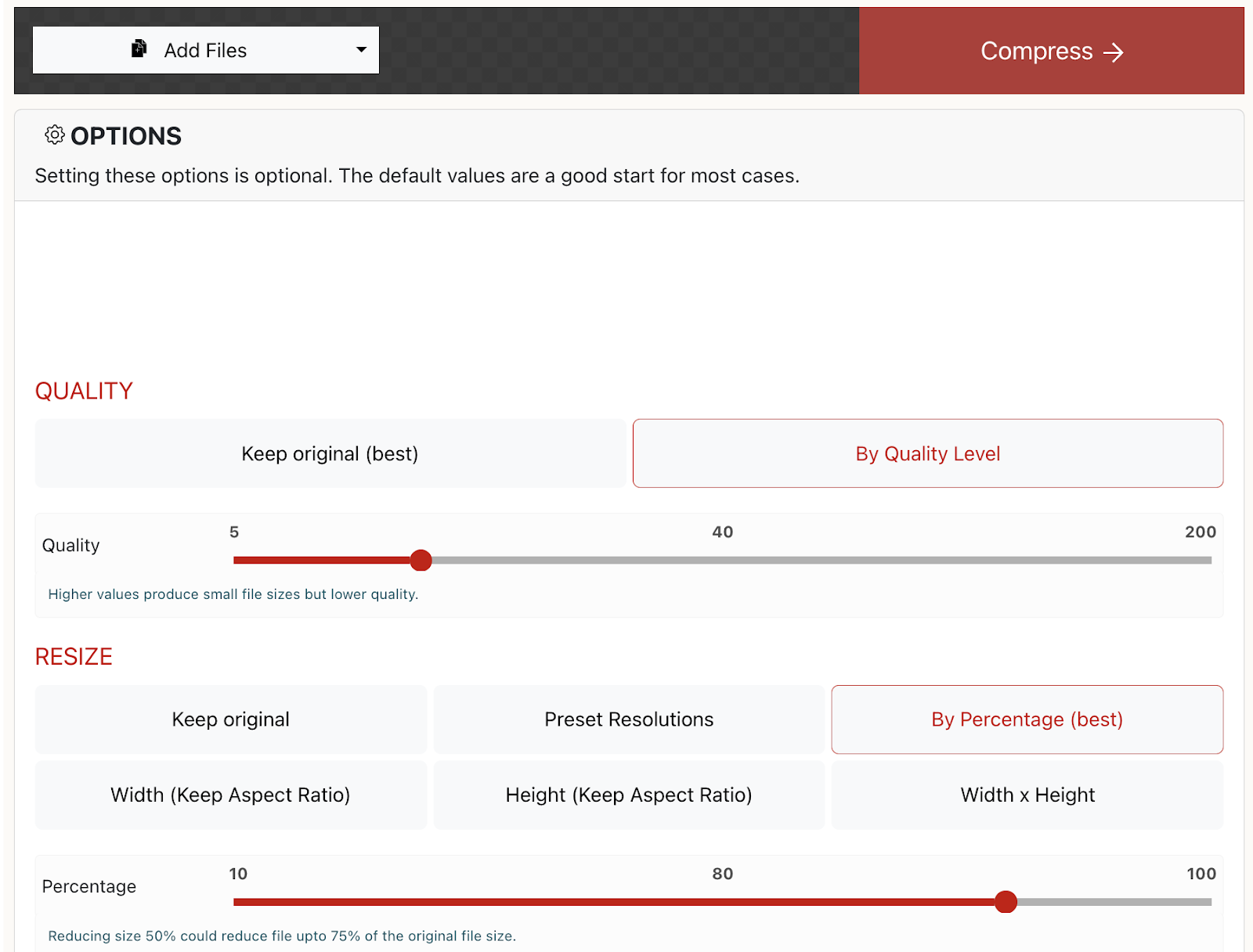
User Interface for XConvert’s GIF compression tool
Uploading GIFs
When you’re ready to add the GIF to your README, instead of adding the file to your repo via the traditional git add syntax, just drag and drop the file into the README!

Why? If you add the GIF as a regular file, it becomes a part of your repo. That means that those 5-10MB are added to the repository’s size, and will be downloaded by everyone who clones your project. A single GIF might not be too inconvenient, but over time these MBs can add up.
If, on the other hand, you drag the GIF into the README, it gets uploaded to GitHub’s servers instead. You can inspect the GIF’s location by right-clicking the GIF and selecting “Copy Image Address”.
Auto-Playing GIFs
If you notice that you set your GIF to automatically play when the page is loaded, but GitHub is making you press the play button, you’re not alone. Fortunately, there’s a way to circumvent this — change the file extension from .gif to .png before uploading! It’s a silly hack that works remarkably well. Here’s an example, just to prove it works.
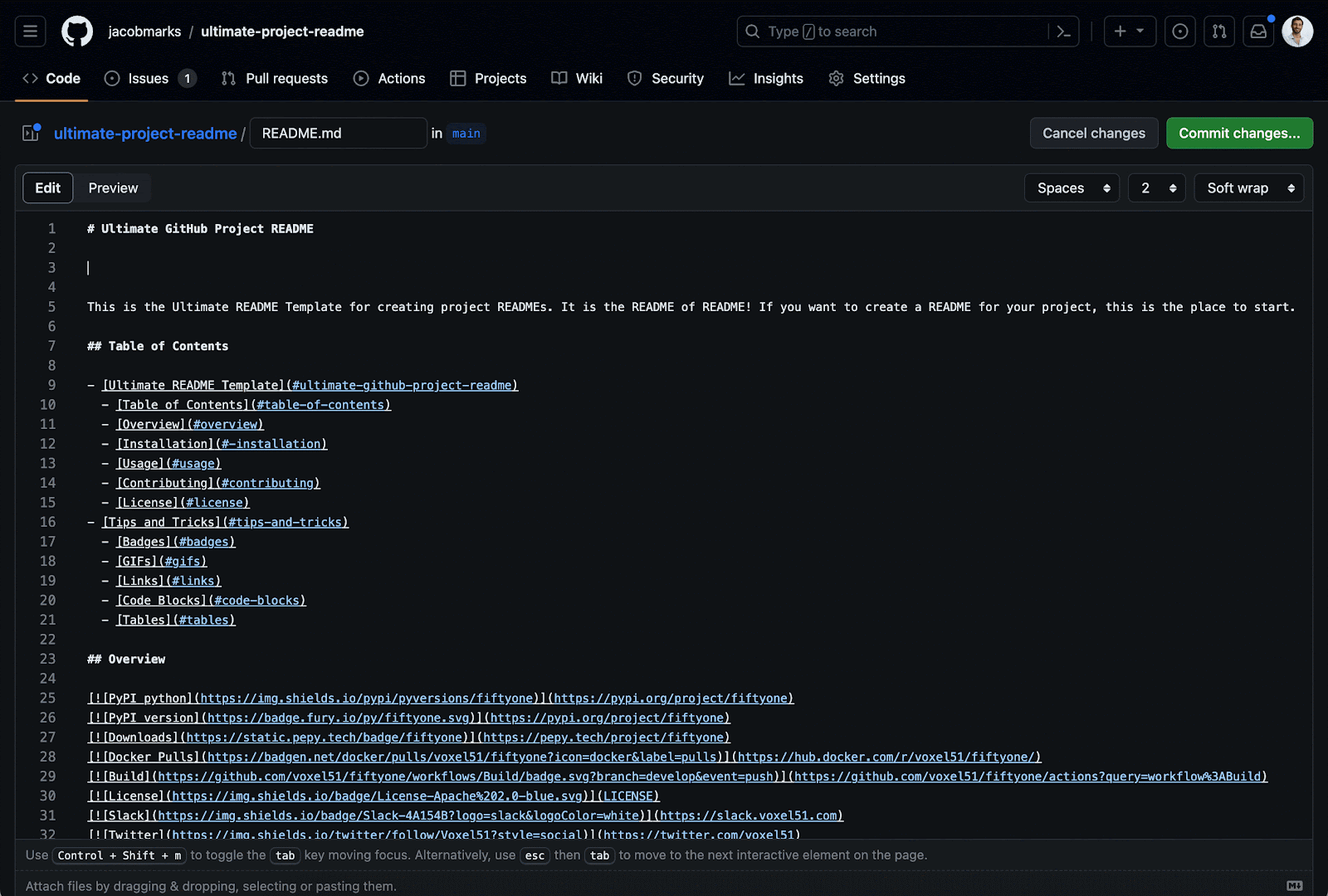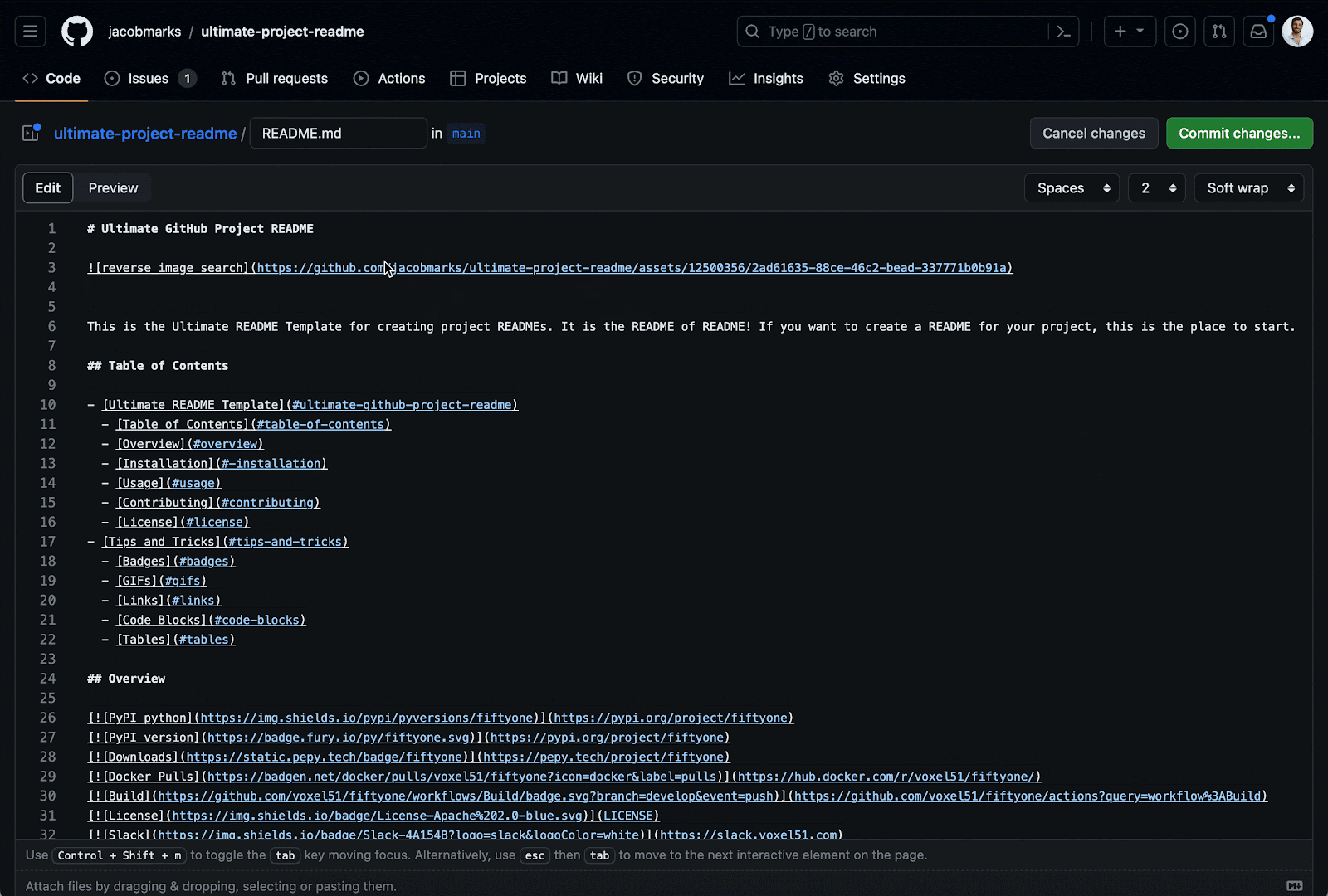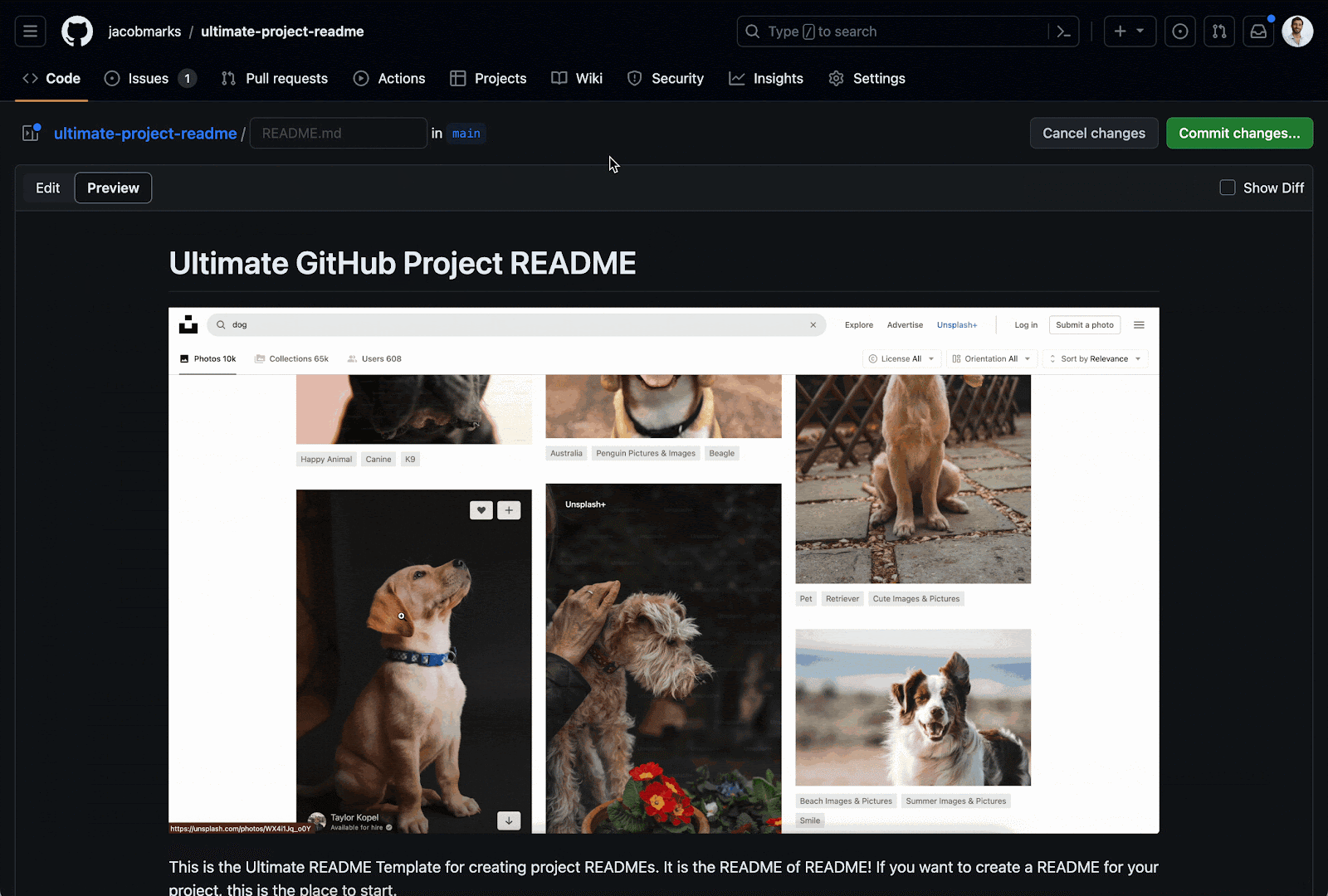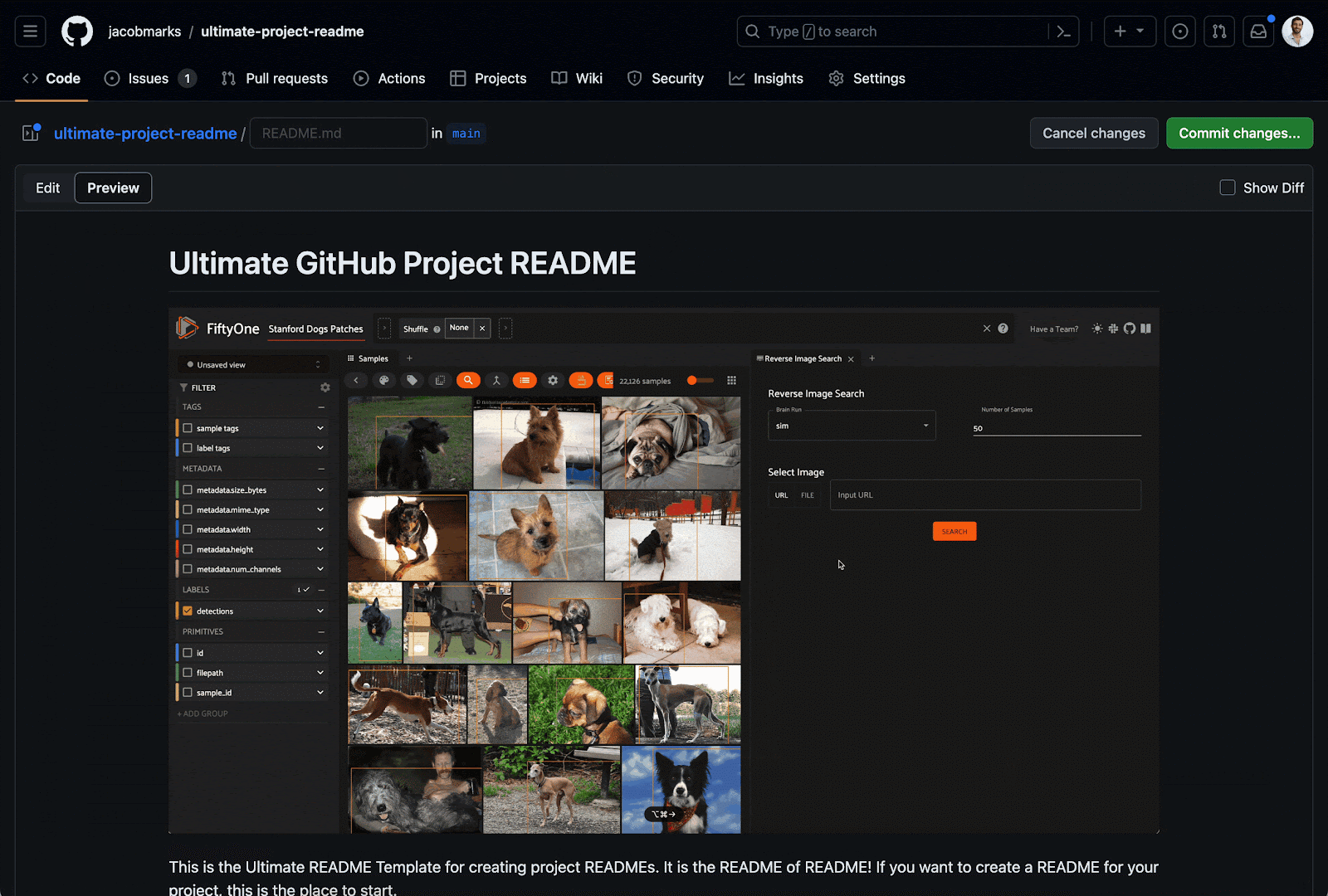
Links
Basic Links
No matter what project you’re building you will almost invariably be including links in your README. In a README, you can represent a link using Markdown syntax:
[Link Text](https://www.example.com)
Or using HTML tags:
<a href="https://www.example.com">Link Text</a>
Relative Links
If you want to link to other files in the same GitHub repository, you can do so with relative links by passing the relative path from the current file to the referenced file.
For instance, in the Ultimate GitHub Project README repo, you can relative link from the README to the data.csv with:
[Link Text](./automation/data.csv)
The “.” specifies the current directory, and what follows is the relative path to the file.
Anchor Links
As is standard in Markdown and HTML, headers in the README (for title, sections and subsections) have associated “anchors”, which we can use to link to these sections. When you create a new section of subsection using Markdown, (using #, ##, etc.), the anchor is automatically assigned by taking all words, converting them to lowercase, and replacing all whitespace with - characters (with a # at the start)
For instance, in the Ultimate GitHub README, the Social Badges section has anchor (#social-badges), so in the README we can link to this section with:
[Anchor Link Text](#social-badges)
💡This works even if you have emojis or other special characters in the section header! To get the anchor, remove these characters and keep the -. Check out the Installation section of the README for an example.
Linking to PRs and Issues
When writing change logs, it can be helpful to refer to the issues that were fixed and the PRs that fixed them and/or added new features. You can do this using the issue or PR number. For example, to reference the first issue in the repo, you can use:
[Issue #1](https://github.com/jacobmarks/ultimate-project-readme/issues/1)
Tables
Basic Tables
As with links, images, and other elements of the README, you can generate a table with either Markdown or HTML.
In Markdown, a basic table looks like this:
| Column 1 | Column 2 | Column 3 | | ------- | -------- | -------- | | Row 1 | Row 1 | Row 1 | | Row 2 | Row 2 | Row 2 | | Row 3 | Row 3 | Row 3 |
Whereas in HTML, the same table would look like this:
<table>
<tr>
<th>Column 1</th>
<th>Column 2</th>
<th>Column 3</th>
</tr>
<tr>
<td>Row 1</td>
<td>Row 1</td>
<td>Row 1</td>
</tr>
<tr>
<td>Row 2</td>
<td>Row 2</td>
<td>Row 2</td>
</tr>
<tr>
<td>Row 3</td>
<td>Row 3</td>
<td>Row 3</td>
</tr>
</table>
But rather than type this all out by hand, there are free tools that facilitate the process. If you need to insert the cell values one by one, you can use a tool like Tables Generator. If you already have your data in a CSV file, then you can use open source libraries like csvtomd to convert the data directly to a Markdown table.
Formatted Tables
If you want to exert more control over the look and feel of your tables, there are multiple ways to do so. You can specify the alignment (where within the cell the text will be located) using `:`. This gives you three options:
- Left-aligned (default): |:———|
- Center-aligned: |:——–:|
- Right-aligned: |———:|
| Left Align | Center Align | Right Align | |:----------- |:------------: |------------:| | text | text | text. |
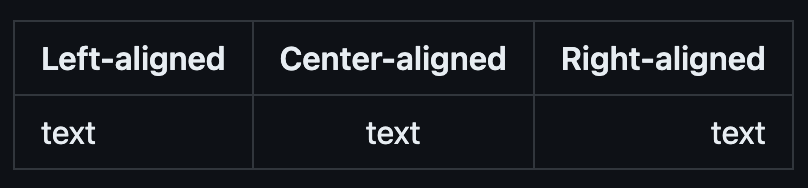
Table generated from the Markdown above
You can specify the cell width with which is code for “non-breaking space”. And you can make a cell go onto multiple lines by inserting a <br> tag to break the line!
| Header 1 | Header 2 | |----------|----------| | Line 1<br>Line 2 | Text |
Table generated from the Markdown above
Dynamically Updated Tables
Thanks for sticking around until the end — lucky for you we’ve saved the best for last!
If you have data which is being frequently (or even continually) updated, and you’d like the tables in your README to reflect the latest data, you can automate the process of table creation.
In your REAMDE, add two instances of some token which you will use to indicate where the table should go — where it should start and end. This token should be wrapped in <!-- -> so that it is interpreted as a comment and is not rendered in the README. Then write a script that inserts the table, with up-to-date data, at that location in the file!
The example in the Ultimate GitHub Project README makes this explicit. In the directory automation, there is a Python script generate.py which generates a table in the README with data from the file data.csv. We define the token along with a warning header and table header:
AUTOGENERATED_TABLE_TOKEN = "<!--- AUTOGENERATED_TABLE -->"
WARNING_HEADER = [
"<!---",
" WARNING: DO NOT EDIT THIS TABLE MANUALLY. IT IS AUTOMATICALLY GENERATED.",
"-->"
]
TABLE_HEADER = [
"| **Title** | **Dataset** |",
"|:---------:|:-----------:|"
]
Once we’ve read the table in as a pandas DataFrame, we format the table as Markdown:
def format_to_md_table(df):
"""Formats DataFrame into a Markdown table."""
md_table = 'n'.join(TABLE_HEADER) + 'n'
for _, row in df.iterrows():
md_table += f"| {row['Title']} | {_wrap_dataset_link(row['Dataset'])} |n"
return md_table
And then we inject the Markdown table into the README at the location specified by the tokens:
def inject_table_into_readme(readme_path, table):
"""Injects the Markdown table into the README file at specified token location."""
with open(readme_path, 'r') as file:
content = file.readlines()
token_indices = [index for index, line in enumerate(content) if AUTOGENERATED_COURSES_TABLE_TOKEN in line]
if len(token_indices) != 2:
raise ValueError("README must contain exactly two AUTOGENERATED_TABLE_TOKEN markers")
new_content = content[:token_indices[0] + 1] + ['n'.join(WARNING_HEADER) + 'n', table] + content[token_indices[1]:]
with open(readme_path, 'w') as file:
file.writelines(new_content)
To update the README, we just run the script:
python automation/generate.py
You can even automate the running of this script — hence the directory name automation — to happen every time the data changes, using GitHub Actions.
For a more complex example of dynamic table updating, check out the script in Papers With Data!
Conclusion
Whether you want it to or not, your project README makes a statement — about the work you’ve done, the team who created it, your user base, and where the project fits into the larger open source ecosystem. The bulk of the work is in answering these questions, and the answers may be ever-evolving. I hope at the very least that the lessons learned, tips and tricks, and tools in this blog help you to put your project’s best foot forward!