Featured Resource

Featured Case Study

15 Best Data Annotation Companies & Data Labeling Services
Accurate labels on data are critical for training performant models. Yet building large, high-quality training sets in-house can drain budgets and delay releases. This guide compares fifteen of the best AI data-annotation companies and data-labeling services to help you shortlist both classic human-in-the-loop vendors and modern automated platforms.

{kind=link}
What do data annotation companies do?
Annotation vendors recruit trained workforces or build specialized ML pipelines to add structure to unstructured data. Tasks include drawing bounding boxes on images, segmenting objects in video, transcribing audio, and classifying text. Modern providers pair human expertise with model-assisted pre-labels and automated quality checks to deliver faster without sacrificing accuracy.
What do data annotation services offer?
Annotation vendors typically offer the following mix of products and services.
- Tooling: web or API interfaces for annotators and reviewers
- Workforce management: vetting, training, and routing tasks to labelers
- Quality control: multi-tier review, consensus checks, or statistical audits of labeled data
- Security and compliance: ISO, SOC 2, HIPAA, or FedRAMP where needed
- ML-assisted workflows: pre-labels from foundation models, active-learning loops, or automated QA
Methodology
This article summarizes publicly available documentation of tooling depth, turnaround time, workforce scale, and security posture. Preference went to platforms with ML-assisted workflows, transparent pricing, and proven compliance support.
How to choose the right AI data annotation company for you
Before choosing an annotation product or service, consider your organization’s needs around data modalities, velocity, and security/regulatory requirements.
- Supported data types: image, video, 3-D, text, audio, or mixed?
- Volume and turnaround: can the service deliver hours of video per week, or thousands of X-ray frames overnight?
- Quality targets: are precision/recall or inter-annotator agreement metrics transparent?
- Security requirements: are PII considerations, geo-fencing, or on-prem processing needed?
- Pricing model: per-label, per-hour, or usage-based?
Match your answers to each provider’s strengths and service-level commitments.
Top 15 data annotation and labeling vendors
Voxel51
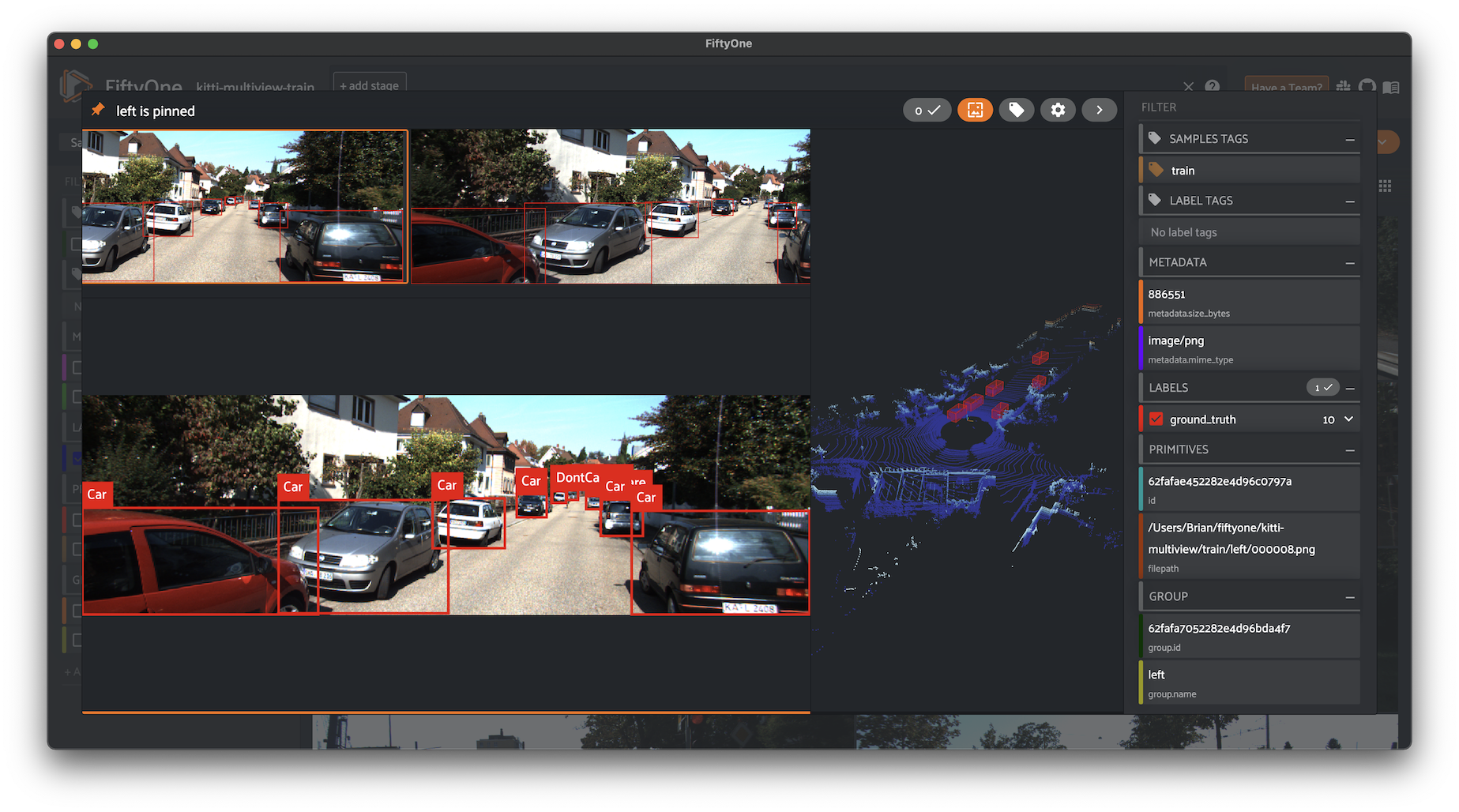
Voxel51 centers its offerings on its FiftyOne toolkit, a Python-based workbench that lets machine-learning engineers build AI applications from massive image and video datasets. Its auto-labeling workflows pair zero-shot model predictions with metrics like Reconstruction Error Ratios (RERs) to surface only the handful of low-confidence samples that still need a human touch, trimming annotation spend by up to 75 percent. Because the platform is code-first, teams can integrate directly into their MLOps stack, automate QA in CI pipelines, and export labels in any schema they choose. However, users must bring their own foundation-model checkpoint (or rely on off-the-shelf models) so non-technical teams may face a steeper learning curve. Support today is focused on visual data and audio; text and other modalities will need a second tool. For companies that value data-centric debugging and want to keep IP on-prem or in their own cloud, Voxel51 delivers a flexible, engineering-friendly solution.
CloudFactory
CloudFactory blends a managed workforce with active-learning tooling to label visual data at scale. Clients get a named account team and SLA-backed turnarounds, which are key for safety-critical verticals such as autonomous driving and precision agriculture. The company’s auditor model means at least two sets of eyes review every label. Per-hour pricing simplifies budget forecasts for long-running projects, yet it can exceed usage-based competitors once workflows stabilize and automation kicks in. Onboarding niche ontologies may require bespoke guideline creation, which lengthens ramp-up.
Hive
Hive taps global crowdsourcing and large proprietary models to deliver bounding boxes, polygons, OCR, and LiDAR annotations. Its API-first platform lets customers submit data and receive labels, often within hours, making it popular among social-media firms, ad platforms, and short-form-video apps that ingest millions of images per day. Built-in pre-labeling bootstraps accuracy, and a consensus algorithm flags disagreements for secondary review. The trade-off is opacity: Hive largely remains a black box, and offers limited visibility into annotator training or error-analysis pipelines. Custom label schemas and complex 3-D use cases force teams to adapt requirements to Hive’s templates.
AWS SageMaker Ground Truth Plus
AWS SageMaker Ground Truth Plus delivers labeling as a managed service that plugs into S3 buckets and SageMaker pipelines, so data never leaves the Amazon ecosystem. Active-learning loops route high-confidence predictions past humans, and AWS claims up to 40% lower costs for common vision workflows like object detection and image classification. The downside is vendor lock-in: JSON manifests, IAM roles, and CloudWatch metrics are all AWS-centric, making migration painful. Ground Truth Plus also masks its human workforce behind service endpoints, limiting transparency into annotator expertise. For organizations already “all-in” on AWS, however, the convenience and native security controls are compelling.
Appen
Appen boasts one of the world’s largest multilingual crowds, spanning 235+ dialects and specialized in speech, text, and conversational AI. Customers can purchase turnkey datasets or engage the workforce for custom annotation, sentiment scoring, and search-relevance tasks. The company backs projects with ISO 9001 quality processes and a suite of reviewer dashboards that measure inter-annotator agreement. Yet quality can drift on large jobs unless you pay for Appen’s premium multi-stage QC, and smaller engagements often find pricing opaque. Ramp-up times stretch if task guidelines or language expertise are niche.
SuperAnnotate
SuperAnnotate offers a browser-based IDE with dataset versioning, branching, and diff views for teams iterating rapidly on vision models. Built-in automation suggests polygon masks and tracking boxes for video frames, and an optional marketplace of vetted vendors can absorb overflow work. The platform’s analytics panel shows accuracy and reviewer throughput, which help managers calibrate effort versus impact. However, per-frame pricing climbs quickly for hi-res footage, and large jobs still require external workforce contracts that SuperAnnotate merely brokers. Text and audio support lag behind vision features.
Cogito
Cogito specializes in regulated verticals like healthcare, insurance, and finance. The company maintains secure facilities, geo-fenced data centers, and a vetted medical workforce that can annotate DICOM images. Every label passes through double-blind review plus automated rule checks to maximize precision for diagnostic models. That rigor, however, extends turnaround times and elevates per-image costs to sometimes double a generalist vendor. Cogito’s tooling is purpose-built for visual medical data, so teams operating in other verticals may need another partner.
Encord
Encord couples a timeline-based labeling UI with a Python SDK that lets engineers run active-learning loops and push predictions back to annotators. Its ontology versioning is designed to keep teams operating in domains like large robotics or autonomous-driving in sync. The platform is vision-centric: text, tabular, or audio tasks feel tacked on, and the marketplace of third-party labelers is smaller than those of longer-established rivals. Pricing is usage-based but skews higher for sensor-fusion modalities like LiDAR.
Labelbox
Labelbox positions itself as an end-to-end “data engine” that blends labeling, curation, and model-error analysis. Model-in-the-loop pre-labels are designed to speed up bounding-box and segmentation tasks, while also surfacing sparse classes or failure slices for re-training. A talent marketplace gives customers on-demand access to vetted labeling partners, but enterprise-grade seats and advanced QA workflows sit behind premium SKUs. Teams get granular analytics, yet long-term storage fees can surprise if you park raw media indefinitely. Because Labelbox is cloud-only, on-prem or air-gapped deployments aren’t supported.
Kili Technology
Kili Technology prioritizes security, holding ISO 27001 and SOC 2 Type II certifications and offering on-prem or single-tenant cloud deployments for classified projects. Its UI supports image, video, text, and PDF annotations. Collaborative dashboards display reviewer consensus in real time to spot drift. Public pricing is scarce, and API support is thinner than that of bigger rivals, so integration work often falls on internal engineers. Kili’s talent pool is smaller, which can slow ramp-up on very large, multilingual jobs.
SuperbAI
SuperbAI differentiates with its few-shot Custom Auto-Label feature: you upload a couple thousand seed annotations and the system retrains a lightweight detector that improves with each review cycle. A Bayesian uncertainty engine highlights low-confidence predictions for targeted cleanup. I features a modern WebUI along with granular role-based access control. Because the engine learns per project, users must allocate GPU hours, which increases cost if classes evolve frequently. Reasonable accuracy still demands roughly 2,000 seed labels per class, so the “few” in few-shot isn’t free.
TrainingData.pro
TrainingData.pro offers fully managed data-collection and annotation services for image, video, text, audio, DICOM, LiDAR. Custom quotes start at a $550 minimum invoice and 100 % post-payment terms. The concierge model handles security (GDPR, NDAs) and iBeta-certified workflows for biometrics, but lacks a self-serve IDE and publishes no per-label pricing, so smaller teams may face longer sales cycles than with other tools.
Keymakr
Keymakr focuses on retail, smart-home footage, and security CCTV. It offers pixel-level segmentation and attribute tagging with claimed accuracy above 95%. Its annotators receive domain-specific training to enable faster ramp-up and fewer guideline iterations. The firm provides a custom QA dashboard that visualizes class distribution across store layouts. Yet this narrow focus limits relevance to other verticals like autonomous vehicles, robotics, or NLP. Keymakr’s pricing is competitive within retail but less so for general vision work.
Playment (GT Studio)
Playment’s GT Studio—acquired by TELUS International in 2021—specializes in autonomous-vehicle data, and lets teams label video, LiDAR, and radar concurrently in a synchronized 3-D viewer. Enterprise clients benefit from SLAs and geo-fenced labeling centers. Since the TELUS acquisition, new contracts are enterprise-only and pricing is available on request, creating a barrier for startups. Some customers note slower feature rollouts post-merger.
Scale AI
Scale AI pioneered hybrid human-plus-model pipelines that have labeled billions of frames for autonomous driving, defense, and industrial robotics. Reviewers praise Scale’s throughput, helped by a global on-demand workforce and integrated automation. Premium SLAs, FedRAMP Moderate authorization, and dedicated annotation taxonomies make it popular among government and Fortune 500 customers. The flip side is cost (often 1.5-2× generalist vendors) and tight vendor lock-in, because many tooling components are proprietary.
Getting Started — What Matters Most
Before signing an annotation contract, align on the outcomes that will make your models production-ready. That means looking beyond headline price and asking how well each vendor fits your data, workflows, and risk profile. Use the checklist below to focus discussions and structure a low-risk pilot:
- Domain & data fit: Does the provider have proven success with your modality (e.g., LiDAR, medical DICOM) and ontology complexity?
- Quality guarantees: Are precision/recall targets, disagreement thresholds, and escalation paths clearly spelled out in the SLA?
- Workflow integration: Will labels flow directly into your MLOps pipeline (S3, GCS, DVC, etc.) and can you automate model-in-the-loop pre-labels or QA?
- Security & compliance: Do you need HIPAA, FedRAMP, on-prem deployment?
- Pricing transparency: How do costs scale after automation kicks in—per label, per hour, or usage tiers tied to active-learning loops?
Run a Data-Backed Pilot
- Sample ≈1 % of your dataset. Choose a representative slice that covers common classes and edge-cases.
- Instrument baseline metrics. Track QA pass rates, review latency, disagreement rate, and Reconstruction Error Ratios (RERs).
- Automate the feedback loop. Pass low-confidence or high-RER samples back to annotators while auto-accepting high-confidence labels to keep humans focused on the hardest cases.
- Stress-test collaboration. Invite reviewers, engineers, and project managers: ensure review threads and versioning works as expected.
- Score the pilot. Compare cost per labeled item, turnaround, and rework effort against your internal KPIs. Shortlist only vendors that meet or beat your thresholds.
When the pilot clears your bar, lock in SLAs, define automated QA hooks, and scale from 1% to 100% of the data in staggered batches. By keeping metrics front and center, you shorten time-to-model, control spend, and free your team to iterate on model innovation instead of annotation.