
Google’s Open Images dataset just got a major upgrade. The dataset that gave us more than one million images with detection, segmentation, classification, and visual relationship annotations has added 22.6 million point labels spanning 4171 classes.
With Open Images V7, Google researchers make a move towards a new paradigm for semantic segmentation: rather than densely labeling every pixel in an image, which leads to expensive and time consuming annotation, in the accompanying paper they show that sparse annotations of a variety they dub pointillism can lead to comparable model performance. This addition to Open Images reflects the ongoing shift in computer vision towards data-centric approaches.
In this article, we’ll show you how to get started working with Open Images V7 and point labels, and explore some features of the dataset. For this exploration, we’ll be using the open source computer vision library FiftyOne, which is one of the official download and visualization tools recommended by the Open Images team.
For a deep-dive into Open Images V6, check out this Medium article and tutorial. Keep reading for a look at point labels and how to navigate what’s new in Open Images V7!
Loading in the data
The easiest way to get started is to import FiftyOne and download Open Images V7 from the FiftyOne Dataset Zoo.
By default, this will download (if necessary) all splits of the data — train, test, and validation — including all available label types for each, and the associated metadata.
As with the Open Images V6 dataset in the FiftyOne Dataset Zoo, however, we can also specify what subsets of the data we would like to download and load! In this article, we’ll be working with the validation split, which consists of 41,620 images. We can download and load in this split in FiftyOne by passing in the
split argument:If we only wanted to download a thousand images, for the purposes of getting a feel for the data, we could specify this with the
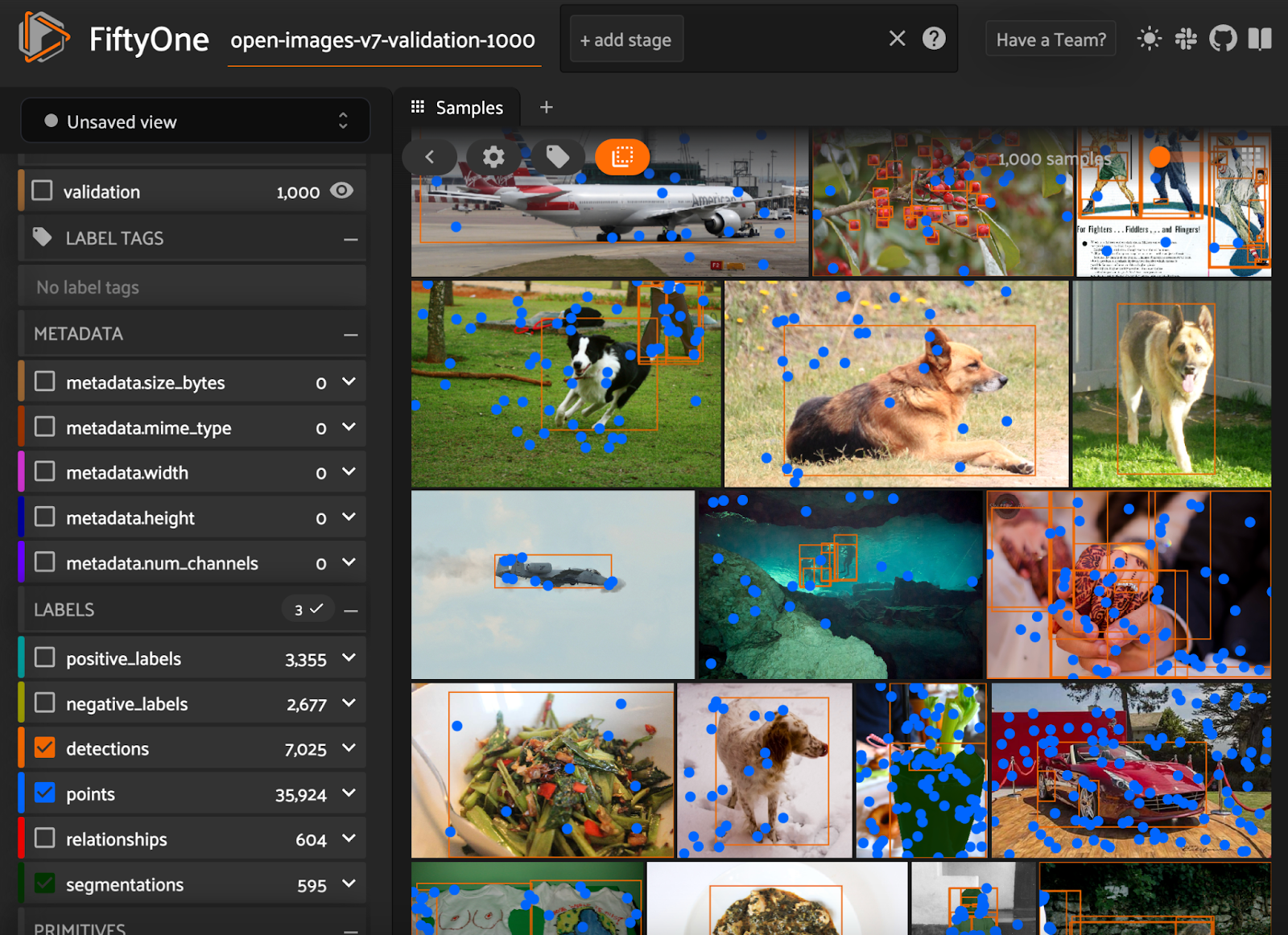
max_samples argument:Let’s take a look at this data by launching the FiftyOne App, a powerful graphical user interface that enables you to visualize, browse, and interact directly with your datasets:

As we can see, there’s a lot going on here. Every one of these images has object bounding boxes, segmentation masks, classification labels, relationship labels, and point labels. However, not every image in the Open Images dataset is annotated with every one of these label types; some images, for instance, do not have point labels. The reason the data that we’ve loaded has all of these is that, by default, FiftyOne prioritizes downloading images that have as many label types as possible!
If we only care about some of the types of annotations, we can isolate these in one of a few ways. We can use the sidebar on the left hand side to toggle label types on/off:
Or we can create a view of the data using
select_labels() to choose the label types we want, and then view this in the FiftyOne App:Another alternative is to explicitly specify which label types we want when loading the dataset:
What’s the point?
Now that we’ve loaded in the data, let’s get a better sense for what these point labels are, and what they actually mean. In the FiftyOne App, click on one of the images in the sample grid and hover over one of the points in the image. You’ll see a box that lists properties of that point label. In a moment, we’ll go through these one by one, but first, a crucial point (no pun intended) must be made.

In generating this dataset, the creators set about asking yes/no questions about whether a given point corresponded to a given class label. This means that these point labels are not labels for the classes they specify. Rather, the point labels are the class labels about which the yes/no questions were concerned.
If you are familiar with previous versions of the Open Images dataset, this notion may be familiar to you, as the classification labels follow a similar pattern, with negative labels and positive labels. Point labels, however, are slightly more nuanced than classification labels.
First off, different points received different numbers of total votes. Second, annotators were allowed to cast votes as “yes”, “no”, or “unsure” votes for the same class label. As a result, some point labels are estimated as unsure!
One last difference is that these point labels were generated via two different methods. Some of the yes/no questions were answered by human annotators, while others were “answered” by a model which predicted a candidate class.
Properties
label: the things/stuff class about which the yes/no question was askedyes_votes: the number of “yes” votes cast by annotatorsno_votes: the number of “no” votes cast by annotatorsunsure_votes: the number of “unsure” votes cast by annotatorsestimated_yes_no: the best guess for whether the class label fits the point, given the votes castsource: the method used to evaluate (cast votes for) the class label, with “ih” for human annotators and “cc” for model-predicted candidate classid: unique identifier within FiftyOne
With the exception of the
id, all of these properties are extracted directly from the Open Images raw data. For more details on these properties, see the Open Images V7 paper.In FiftyOne, these point labels are represented by Keypoint Labels, which enable us to easily access, filter, and perform operations on these labels.
For an individual sample, it is easy to read out this data:
[<Keypoint: {
'id': '63dd4da3c5d1bb17274b573e',
'attributes': {},
'tags': [],
'label': 'Rope',
'points': [[0.11230469, 0.7114094]],
'confidence': None,
'index': None,
'estimated_yes_no': 'no',
'source': 'ih',
'yes_votes': 0,
'no_votes': 3,
'unsure_votes': 0,
}>, <Keypoint: {
'id': '63dd4da3c5d1bb17274b573f',
'attributes': {},
'tags': [],
'label': 'Rope',
'points': [[0.49609375, 0.31767338]],
'confidence': None,
'index': None,
'estimated_yes_no': 'no',
'source': 'ih',
'yes_votes': 0,
'no_votes': 3,
'unsure_votes': 0,
........
}>, <Keypoint: {
'id': '63dd4da3c5d1bb17274b5751',
'attributes': {},
'tags': [],
'label': 'Fixed-wing aircraft',
'points': [[0.79840761, 0.73948359]],
'confidence': None,
'index': None,
'estimated_yes_no': 'yes',
'source': 'cc',
'yes_votes': 1,
'no_votes': 0,
'unsure_votes': 0,
}>, <Keypoint: {
'id': '63dd4da3c5d1bb17274b5752',
'attributes': {},
'tags': [],
'label': 'Fixed-wing aircraft',
'points': [[0.8213462, 0.51104984]],
'confidence': None,
'index': None,
'estimated_yes_no': 'yes',
'source': 'cc',
'yes_votes': 1,
'no_votes': 0,
'unsure_votes': 0,
}>]
'id': '63dd4da3c5d1bb17274b573e',
'attributes': {},
'tags': [],
'label': 'Rope',
'points': [[0.11230469, 0.7114094]],
'confidence': None,
'index': None,
'estimated_yes_no': 'no',
'source': 'ih',
'yes_votes': 0,
'no_votes': 3,
'unsure_votes': 0,
}>, <Keypoint: {
'id': '63dd4da3c5d1bb17274b573f',
'attributes': {},
'tags': [],
'label': 'Rope',
'points': [[0.49609375, 0.31767338]],
'confidence': None,
'index': None,
'estimated_yes_no': 'no',
'source': 'ih',
'yes_votes': 0,
'no_votes': 3,
'unsure_votes': 0,
........
}>, <Keypoint: {
'id': '63dd4da3c5d1bb17274b5751',
'attributes': {},
'tags': [],
'label': 'Fixed-wing aircraft',
'points': [[0.79840761, 0.73948359]],
'confidence': None,
'index': None,
'estimated_yes_no': 'yes',
'source': 'cc',
'yes_votes': 1,
'no_votes': 0,
'unsure_votes': 0,
}>, <Keypoint: {
'id': '63dd4da3c5d1bb17274b5752',
'attributes': {},
'tags': [],
'label': 'Fixed-wing aircraft',
'points': [[0.8213462, 0.51104984]],
'confidence': None,
'index': None,
'estimated_yes_no': 'yes',
'source': 'cc',
'yes_votes': 1,
'no_votes': 0,
'unsure_votes': 0,
}>]
We can also use FiftyOne’s Aggregation class and filtering capabilities to quickly get some summary statistics about the dataset (the validation split that we downloaded in the first section).
We can compute the total number of “yes”, “no” and “unsure” votes across all points:
total YES votes: 1055849
total NO votes: 1700581
total UNSURE votes: 114893
total NO votes: 1700581
total UNSURE votes: 114893
And the number of times a point had a certain number of votes for these three options:
YES vote counts: {0: 804909, 1: 450783, 2: 78768, 4: 132, 3: 148409, 5: 151, 6: 170}
NO vote counts: {4: 113, 1: 376188, 3: 394390, 0: 642460, 6: 75, 5: 43, 2: 70053}
UNSURE vote counts: {1: 114855, 2: 19, 0: 1368448}
NO vote counts: {4: 113, 1: 376188, 3: 394390, 0: 642460, 6: 75, 5: 43, 2: 70053}
UNSURE vote counts: {1: 114855, 2: 19, 0: 1368448}
Using FiftyOne’s ViewField with
from fiftyone import ViewField as F, we can also do things like count the total number of point labels:And efficiently compute the number of point labels that received at least one “yes” vote and at least one “no” vote:
Point(s) of interest
Now that we understand what these point labels are and how to access their basic properties, let’s discuss how to massage the data into a form that is potentially more useful for downstream processing.
One thing we might want to do is extract a subset of the dataset with point labels for particular classes. As an example, suppose we are working on a wildlife conservation project and we want to train a model to identify turtles and tortoises. In FiftyOne there are multiple ways to accomplish this!
If we already have the entire dataset loaded, we can filter the point labels for instances of “Turtle” or “Tortoise”, and either use
select_labels() to get only the point labels and perhaps the positive classification labels, or we can toggle the rest of the labels off in the FiftyOne App, as we’ve done here:
Alternatively, if you know from the start that you are only interested in certain label classes, you can pass this information directly into the
load_zoo_dataset() method:Another thing we might want to do is turn the raw “yes”, “no”, and “unsure” votes that were cast for these point labels into something more concrete that we can use to train models. For simplicity’s sake, let’s say that rather than use the
estimated_yes_no values given by the dataset’s authors, we want to generate “positive” and “negative” point labels in direct analogy with the classification labels.As an example workflow, we could imagine that we are only interested in point label votes cast by human annotators — not the candidate classes generated by models. And let’s further suppose that to ensure with high probability that our ground truth labels are accurate, we will only label points as “positive” or “negative” if there are at least two human votes cast, and all votes agree. Here’s one way to do this in FiftyOne:
First, we will filter the point labels for points with multiple positive votes, no negative or unsure votes, and
source="ih", and clone this view into a new dataset positive_dataset, only keeping the points field:Then rename the embedded field
points to positive_points, so that we can merge this into the original dataset shortly.We can then get rid of a bunch of the embedded fields within the Keypoint label, because we already know the source and number of “no” and “unsure” votes. For similar reasons, we can also rename the
yes_votes field to votes:Finally, we can merge this
positive_dataset into the original dataset:After going through an analogous procedure for the negative point labels, we can use
select_fields one more time to create a view containing only the positive and negative point labels, and the positive and negative classification labels:
Conclusion
In this article, we’ve only scratched the surface of what you can do with FiftyOne and Google’s latest version of the Open Images dataset. If you want to dive deeper into features of the Open Images dataset, check out this Medium article and tutorial, and if you want to know more about the pointillism-based approach to semantic segmentation, I encourage you to check out Google’s paper on the topic.
I hope this article showed you how easy it is to get started working with Open Images V7 using FiftyOne!
Loading related posts...
© 2026 Voxel51 All Rights Reserved


