The multimodal data platform for physical AI
Build and iterate faster. FiftyOne surfaces the right data insights to maximize AI performance.
FiftyOne Platform
Your data drives AI success
AI success depends on visual data quality, not just models. FiftyOne puts data at the center to give you a competitive edge.
Get full visibility into your data
Instantly slice, search, and filter massive multimodal datasets to weed out low-quality samples and surface the right insights.
Multimodal
One platform for every physical AI modality
Work with any data type and modality. Visualize, query, annotate, and understand images, video, point clouds, and time-series data—all in one place.

Benefits & ROI
Leading enterprises build using FiftyOne
0%
increase in model accuracy
0+
months of development time saved
0x
faster data curation


Maintained 99% fall detection rates for model performance.









Sped up investigations of robotic arms by 3x.






Maintained 99% fall detection rates for model performance.
Sped up investigations of robotic arms by 3x.
COMPLIANCE & GOVERNANCE
Enterprise-grade security, scale, and extensibility
FiftyOne is built to meet the requirements of the most complex AI stacks.
Deploy anywhere

Fully customizable and extensible
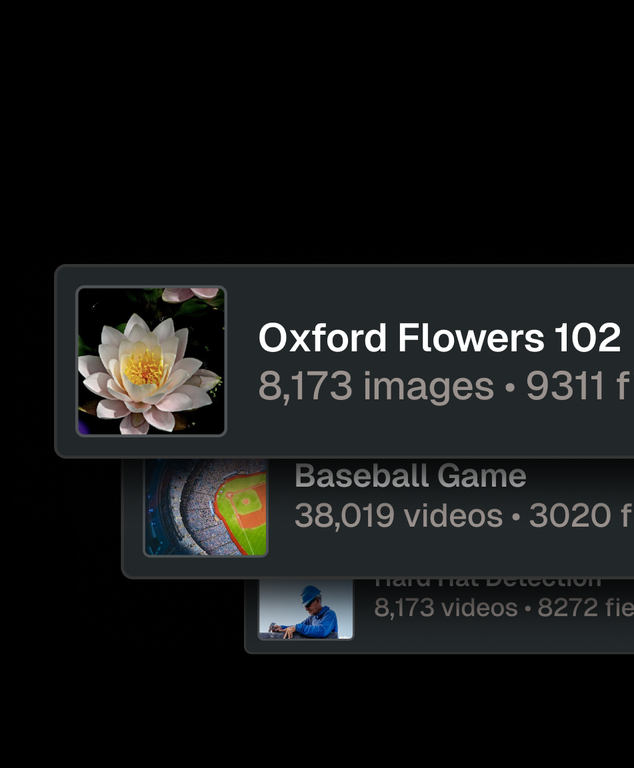
Supports billions of samples
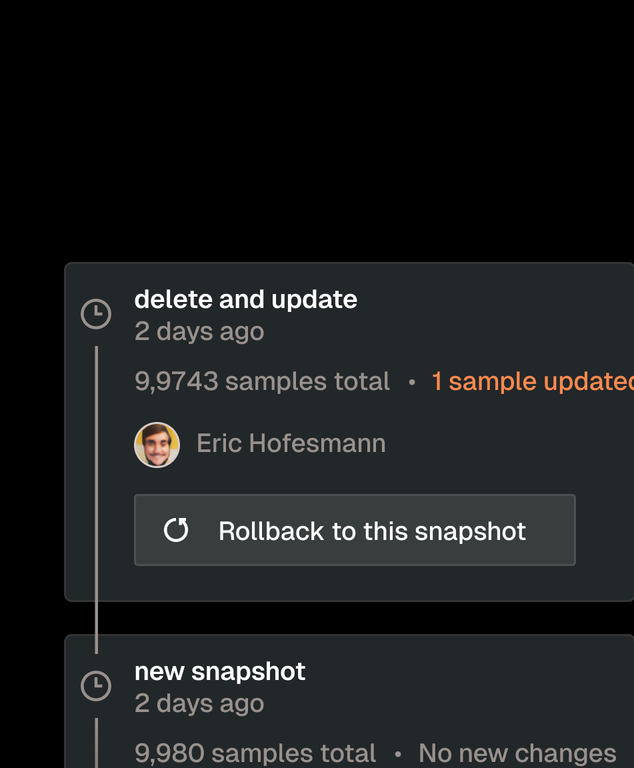
Dataset versioning
Role-based access controls
ISO 27001 certification

Get started today
Leading enterprises build using FiftyOne
30% increase in model accuracy
5+ months of development time saved
30% boost in team productivity
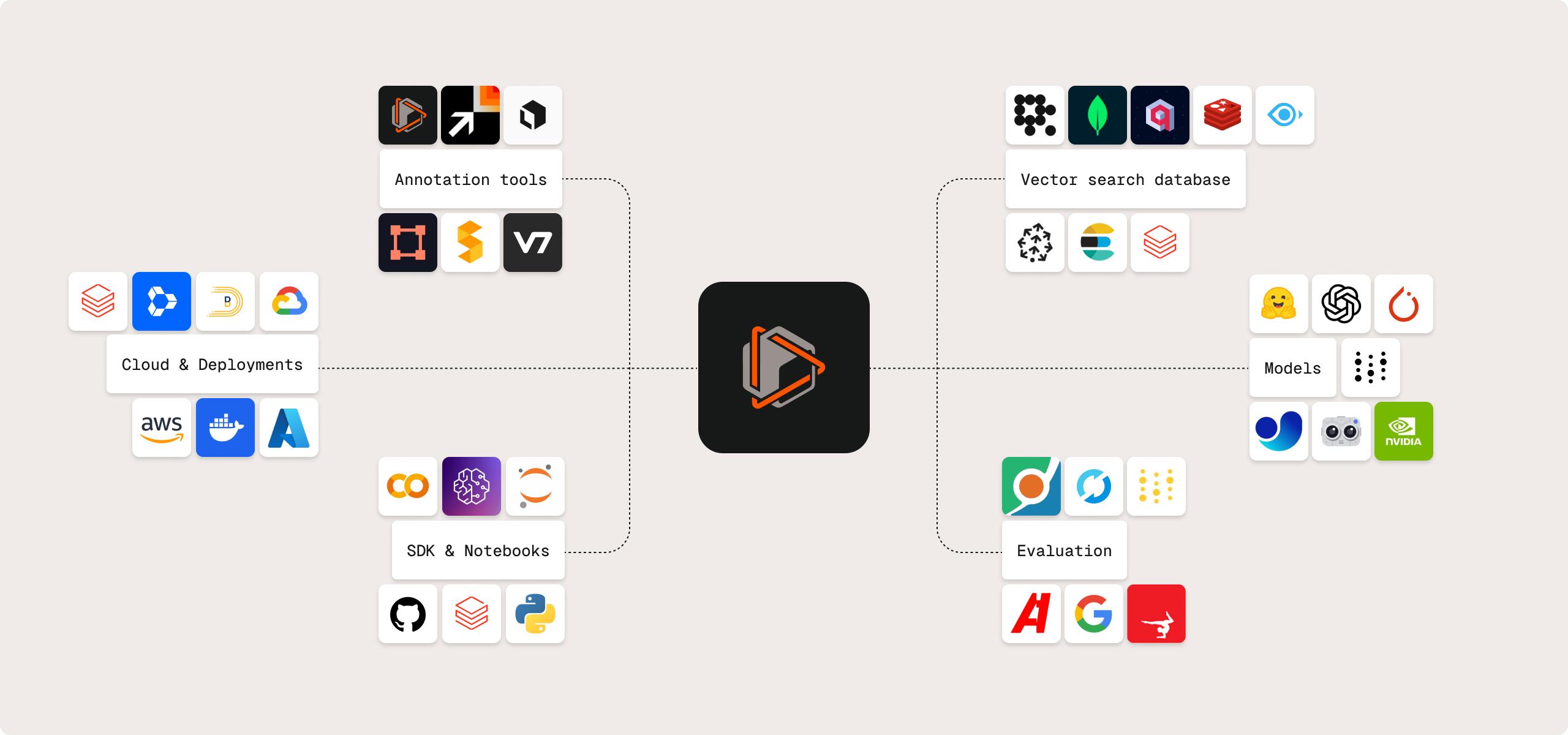
INTEGRATIONS
Your stack, your choice —
no vendor lock-in
FiftyOne seamlessly integrates with your existing tech stack, giving you the freedom to evolve your toolchain as needs change.
Developer resources
Loved by ML engineers
More than 5 million installs
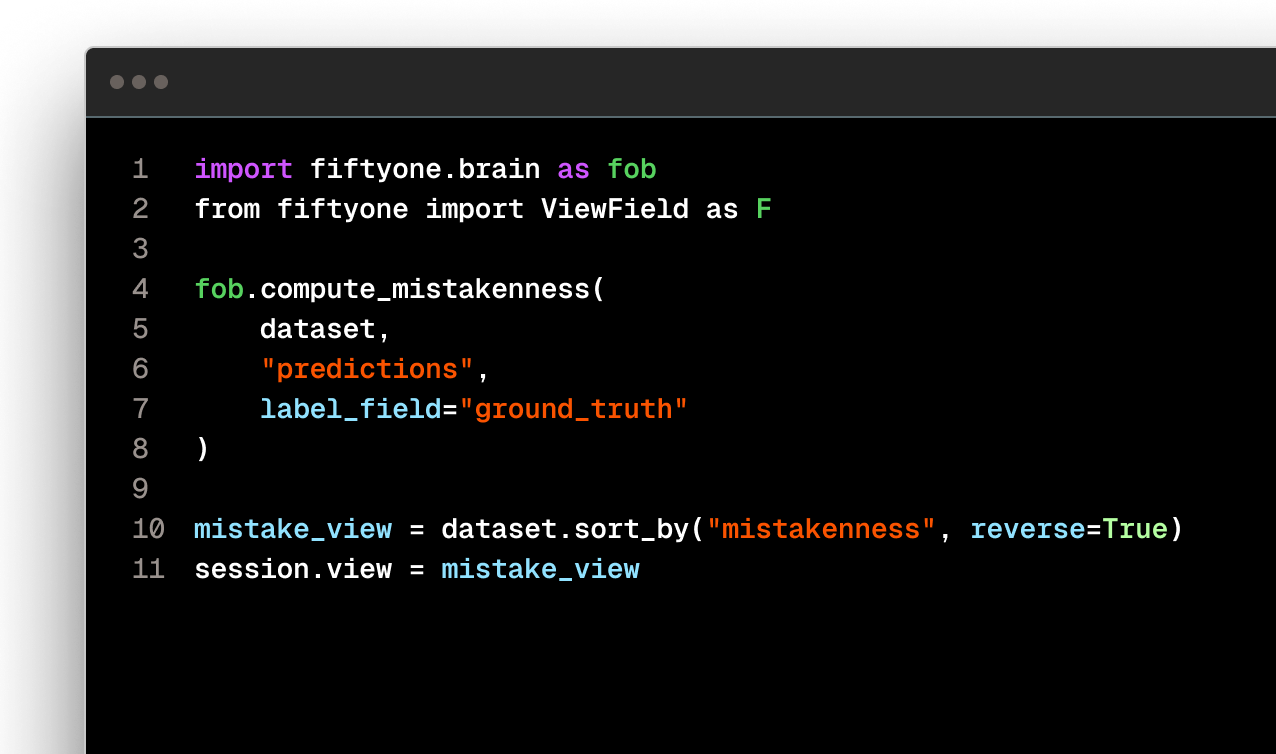
Built on open source standards


100K+ computer vision community members

Enough data wrangling.
Request a demo.

© 2026 Voxel51 All Rights Reserved