A new (and open source!) tool for your machine learning toolbox
The Backstory
My co-founder Jason and I started Voxel51 in 2017 with the vision of building tools that enable CV/ML engineers to tackle the hardest problems in computer vision. We started that journey by participating in the NIST Public Safety Innovation Accelerator Program, which was created to incubate new technologies with the potential to transform the future of public safety.
Over the next two years, we set out to translate our academic research on image/video understanding — over 250 papers and 30 years of experience — into a scalable platform for developing and deploying ML models that process visual data. The platform made it easy to take a model trained on images and deploy it to process video, efficiently and at scale. We trained a variety of models ourselves on road scene videos for tasks such as vehicle recognition, road sign detection, and human activity recognition. With some early successes under our belt, we raised a round of venture capital, built a small team, and began pilots with industry partners to onboard their CV/ML teams to our platform.
During this process, we learned a surprising fact:
There is a serious lack of tooling available to rapidly experiment with data and models.
We found ourselves building our own in-house tools to solve tasks like:
- Wrangling datasets into a common format for training/evaluation
- Choosing a diverse set of images to annotate
- Balancing datasets across classes and visual characteristics
- Validating the correctness of human annotations
- Visualizing model predictions
- Finding and visualizing failure modes of models
Each time we encountered a new task, we wrote more custom scripts, massaged our datasets in similar-but-different ways, and generally found ourselves spending way more time wrangling data than doing actual science to improve our models.
After cross-referencing our experience with CV/ML teams in dozens of other companies, both small and large, as well as academic groups, we learned that others were experiencing the same pain: they needed a tool that would enable them to rapidly experiment with their data and models.
Getting Closer To Your Data
Training great machine learning models requires high quality data. Academic education in CV/ML is an excellent way to develop knowledge of model architectures, tips & tricks for training models, etc. However, most research treats the dataset (often a standard dataset like ImageNet or COCO) as a static, black box.
In our experience, the limiting factor of performance on real problems is not the model, but rather the dataset. The more data you have for training, the better, right? End of story. Well, sort of:
Nothing hinders the success of machine learning systems more than poor-quality data.
– Jason Corso, CEO of Voxel51 and Professor of CV/ML
In a recent blog post, we found that over 1/3 of false positives of state-of-the-art models on the Open Images dataset are actually due to annotation error! Scientists are busy tweaking model architectures to squeeze a few extra points of mAP out of a dataset whose limiting factor is annotation quality.
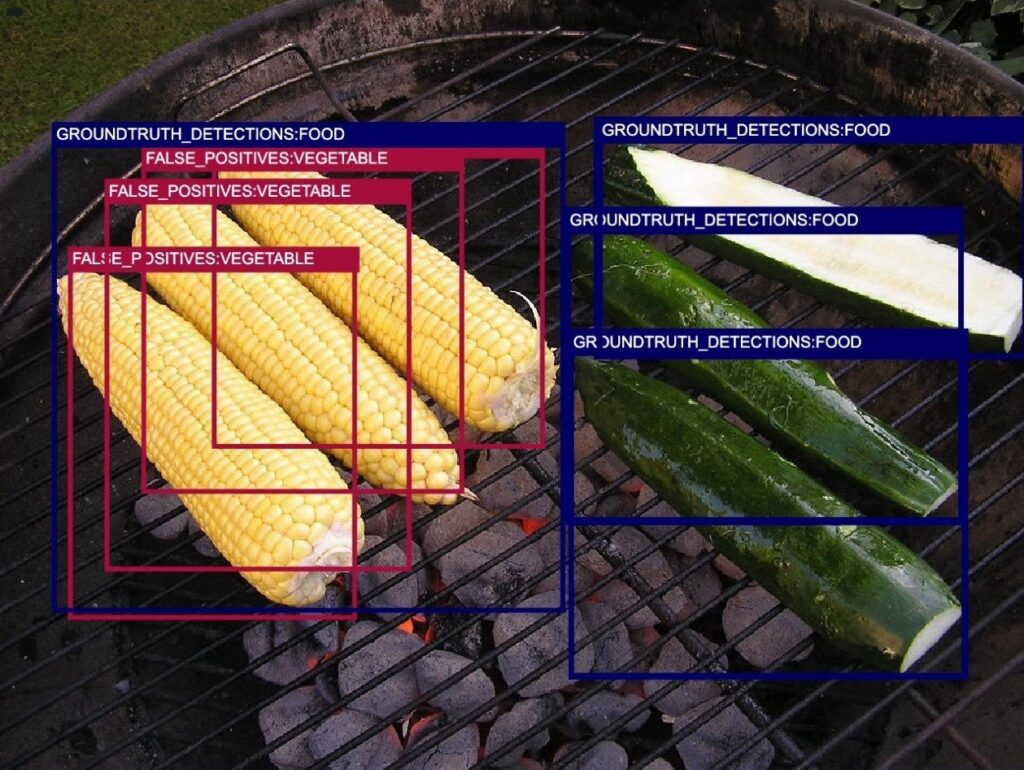
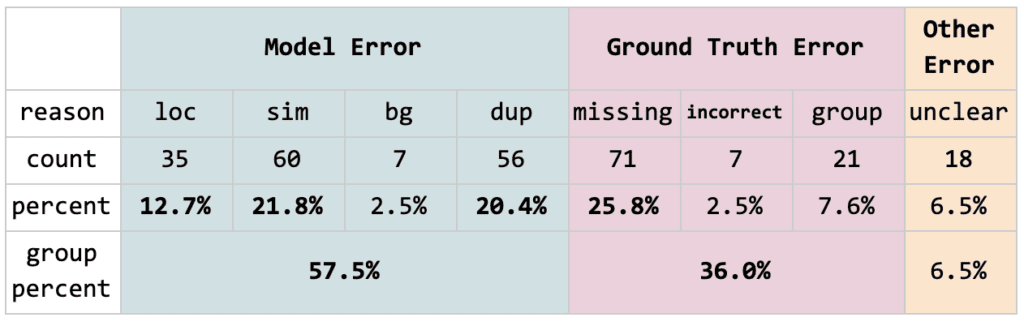
A consistent theme arose from our customer discovery efforts: the diversity of training data and the accuracy of the labels associated with that training data are critically important to developing a high-performance ML system.
That makes sense, but don’t ML engineers already know this?
Not nearly as much as we thought they did.
We found that CV/ML engineers focus primarily on choosing/tweaking model architectures and tuning hyperparameters. These are all important, but guess what? In our experience and that of many of the highest performing ML teams we spoke with, the biggest breakthroughs came by focusing on the data used to train the systems.
So, why aren’t CV/ML engineers acting on this insight?
Lack of tooling.
Seriously. We found that, while the teams and organizations with the most ML experience have built their own tools to make it easier to visualize their data, they only built those tools because they had no other choice. And smaller teams with less computer vision expertise? Most do not have the resources to build tools in-house (they are correctly focused on getting to market as fast as possible), and many do not yet realize the importance of getting closer to their data.
Introducing FiftyOne
We built FiftyOne to help CV/ML engineers and scientists spend dramatically less time wrangling data and more time focusing on the science of building better datasets and better models. The vignettes below give a taste of what I’m talking about.
Loading Data With Ease
FiftyOne removes the effort required to quickly load and visualize data in a variety of common (or custom) formats. While this task is certainly doable by any ML engineer, it takes real effort to properly wrangle the various data/annotation formats out there into a standard format that they can work with. FiftyOne removes that effort and meets engineers where they’re already working: in Python.
With FiftyOne, it takes two lines of code to load an image dataset with labels and display them visually in the FiftyOne App.
import fiftyone as fo
# Load a dataset stored in COCO format
dataset = fo.Dataset.from_dir(
dataset_dir="/path/to/coco-formatted-dataset",
dataset_type=fo.types.COCODetectionDataset,
)
# Explore the dataset in the App
session = fo.launch_app(dataset)
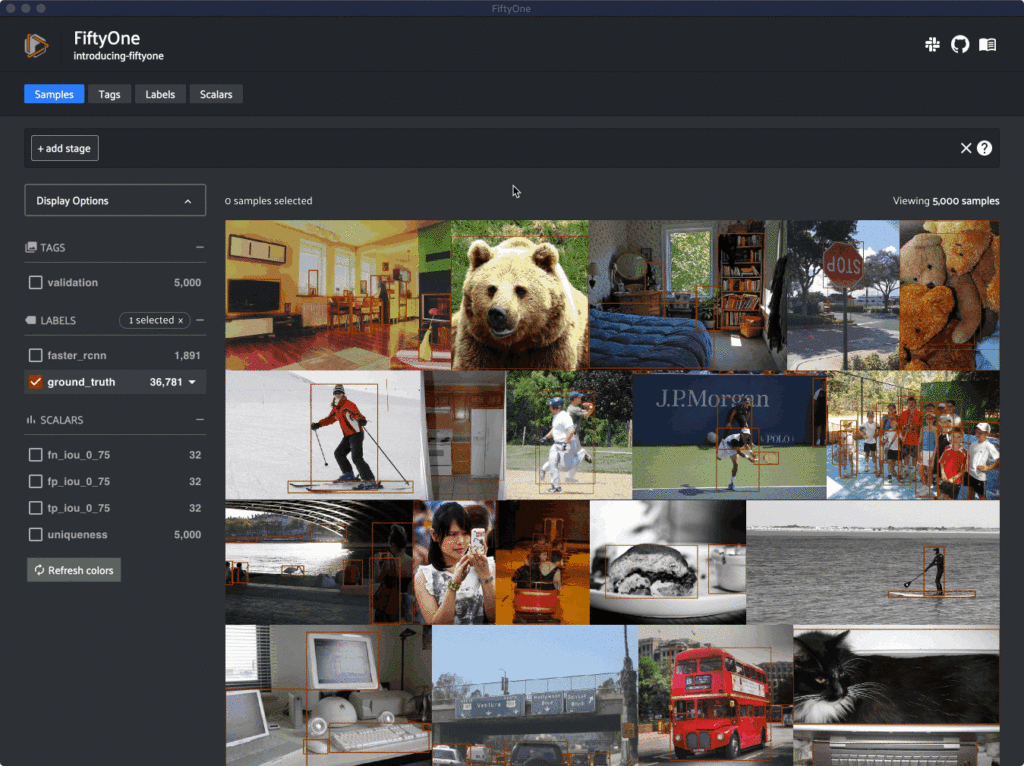
Powerful Dataset Analysis
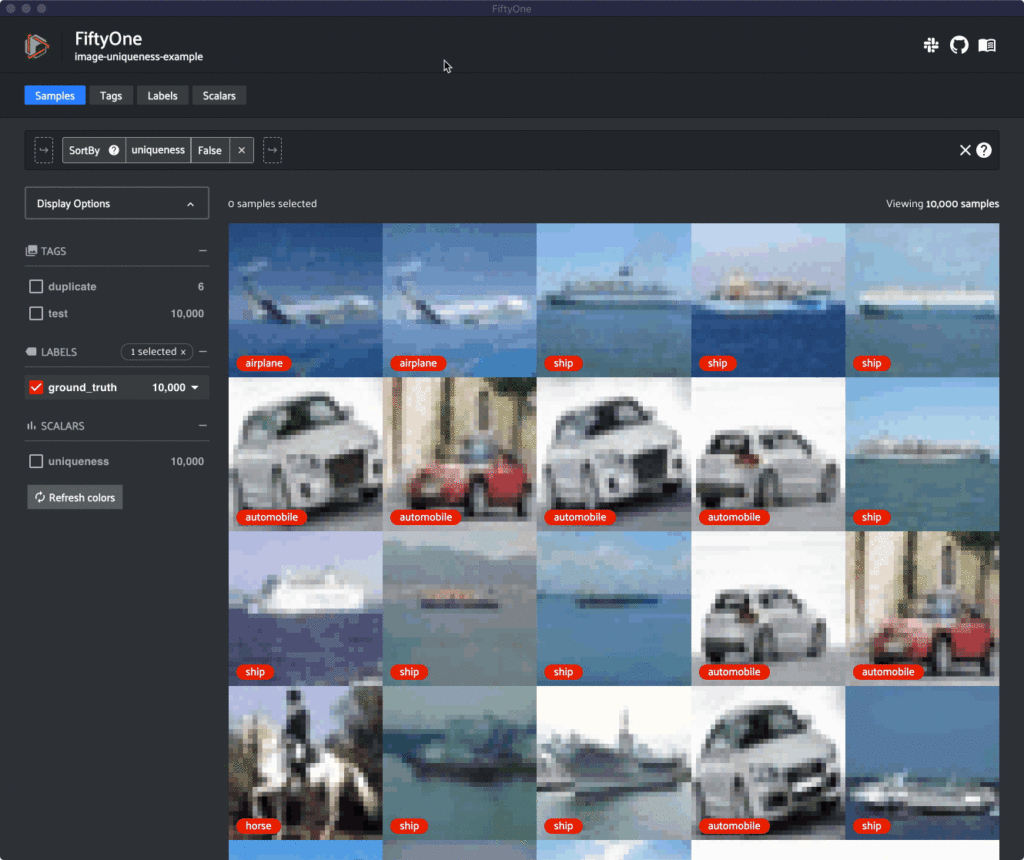
FiftyOne does more than just visualize your data. It also provides powerful dataset analysis utilities. For example, look how easy it is to find visually similar images in your dataset:
import fiftyone.brain as fob
# Index the images in the dataset by visual uniqueness
fob.compute_uniqueness(dataset)
# View the least unique (most visually similar) images in the App
session.view = dataset.sort_by("uniqueness")
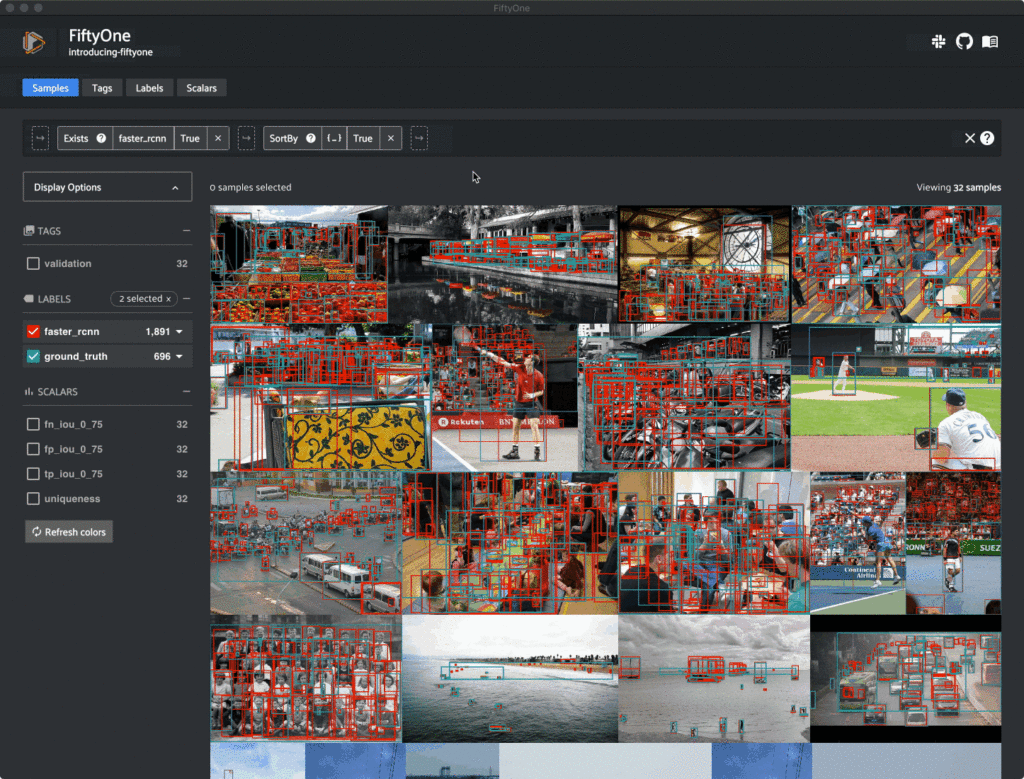
Interactive Model Evaluation
When working with image/video datasets, some tasks are best performed visually, while others are best performed programmatically. We built FiftyOne to enable seamless handoff between the App and the Python library. You can load a dataset from code, then search and filter it from the App to identify particular samples/labels in the App, then access those samples of interest back in Python.
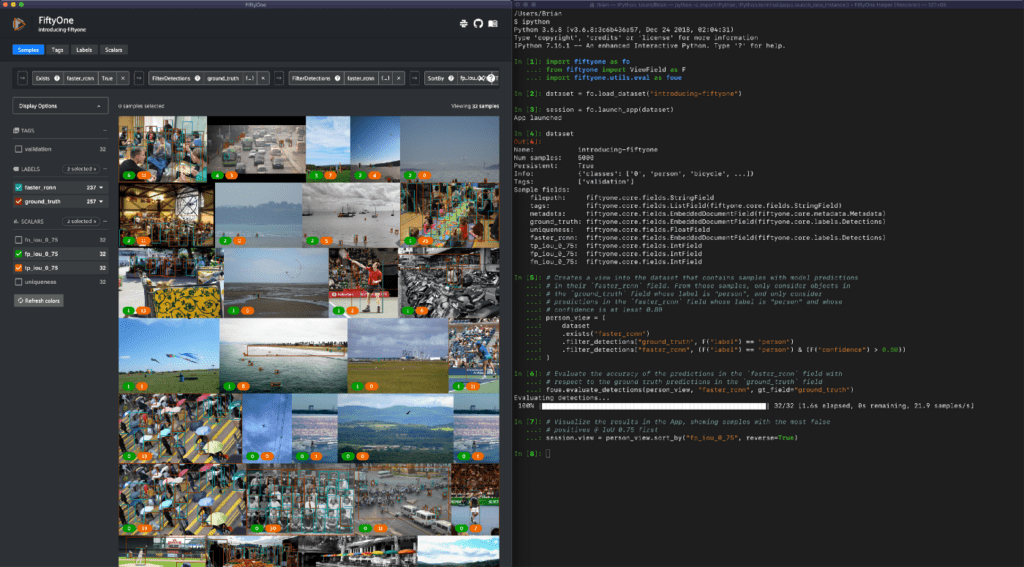
One important instance of this workflow is evaluating model predictions. Quantitative measures such as confusion matrices or mAP scores don’t tell the whole story of a model’s performance. You need to visualize the failure modes of your model to understand what actions to take to remove the glass ceiling on the model’s performance.
With FiftyOne, you can perform complex operations on your data, such as evaluating the quality of a particular class at a given confidence threshold for your model’s predictions, and then visualizing the worst performing samples in the App:
from fiftyone import ViewField as F
# Creates a view into the dataset that contains samples with model predictions
# in their `faster_rcnn` field. From those samples, only consider objects in
# the `ground_truth` field whose label is "person", and only consider
# predictions in the `faster_rcnn` field whose label is "person" and whose
# confidence is at least 0.80
person_view = (
dataset
.exists("faster_rcnn")
.filter_labels("ground_truth", F("label") == "person")
.filter_labels("faster_rcnn", (F("label") == "person") & (F("confidence") > 0.80))
)
# Evaluate the accuracy of the predictions in the `faster_rcnn` field with
# respect to the ground truth predictions in the `ground_truth` field
person_view.evaluate_detections("faster_rcnn", gt_field="ground_truth")
# Visualize the results in the App, showing samples with the most false
# positives @ IoU 0.75 first
session.view = person_view.sort_by("fp_iou_0_75", reverse=True)
Less Wrangling, More Science
While we’ve heard that visualizing datasets in the App and the power of the Python library alone are already useful to CV/ML engineers, we’re also building out features in FiftyOne to power common workflows that are important but-challenging to implement today:
- Converting between dataset formats
- Curating diverse and representative datasets
- Selecting video frames for annotation and training of image models
- Automatically finding label mistakes
- Evaluating model predictions
- Identifying and visualizing failure modes in your models
Ready to jump in? Check out the easy-to-follow tutorials and recipes in the FiftyOne Docs to learn how to execute these tasks on your datasets.
Oh, and getting started with FiftyOne is a breeze!
# Install FiftyOne pip install fiftyone # Downloads a dataset and opens it in the App for you to explore! fiftyone quickstart
We Believe In Open Source Software
At Voxel51, we’re strong believers in the virtues of open source software. As a point of reference, many of the most popular tools in the ML ecosystem — TensorFlow, PyTorch, Apache Spark, and MLflow, to name a few — are open source. We believe this is not a coincidence: the best way to build a community around a developer tool is to make the project as open and transparent as possible. Making a project free and open source removes barriers to entry and allows individual developers to directly evaluate the merits of a tool, cast a vote of approval for the project with their code (and GitHub stars), and evangelize the tool within their organizations.
That’s why we released FiftyOne open source on GitHub with a permissive license. We’re committed to making the best tools for rapid data and model experimentation openly available for all CV/ML engineers to use. Issues, feature requests, and pull requests are welcome!
Although the core FiftyOne library will always be free and open source, we know that professional organizations and other advanced users have unique requirements to adopt tools more broadly and integrate them into their production workflows. That’s why we’re pursuing an open core model for FiftyOne. But more on that soon…
For now, we’re excited to see the amazing CV/ML-powered solutions that are built using FiftyOne!

