Welcome to our weekly FiftyOne tips and tricks blog where we recap interesting questions and answers that have recently popped up on Slack, GitHub, Stack Overflow, and Reddit.
Wait, what’s FiftyOne?
FiftyOne is an open source machine learning toolset that enables data science teams to improve the performance of their computer vision models by helping them curate high quality datasets, evaluate models, find mistakes, visualize embeddings, and get to production faster.

- If you like what you see on GitHub, give the project a star.
- Get started! We’ve made it easy to get up and running in a few minutes.
- Join the FiftyOne Slack community, we’re always happy to help.
Ok, let’s dive into this week’s tips and tricks!
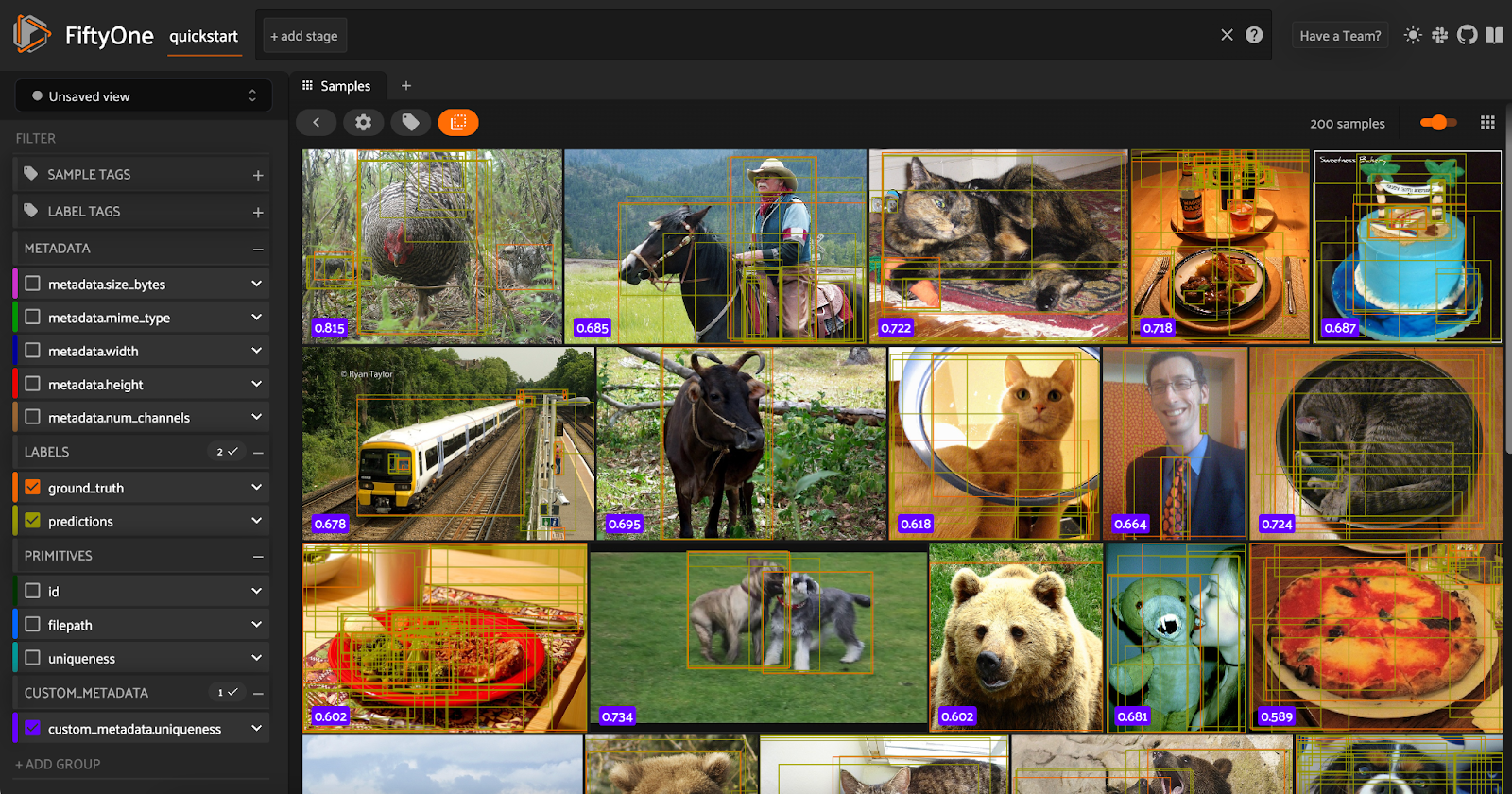
Adding metadata to a FiftyOne dataset
Community Slack member Immanuel Weber asked,
“Hi everyone, first let me say that I really love FiftyOne! I want to add metadata to my samples, and using set_values() I was able to add metadata, but with this approach the fields do not show up in the FiftyOne App. Is my approach a valid way to add new metadata? Is there a way to have the FiftyOne App display these new fields? Thanks!”
Great question, Immanuel. In FiftyOne, what fields are visible in the FiftyOne App is determined by the schema of your dataset. Only fields that are part of the schema show up in the App. You can print out dataset.get_field_schema() to see your field schema.
As of FiftyOne 0.19.0, when you use set_values() to add a field to the samples in your dataset, it has an argument dynamic which you can use to control whether or not the field is added to your schema. By default, dynamic=False, so the field is not added. If you pass in dynamic=True, then it will be added to the schema, and so it will show up in the FiftyOne App.
Additionally, while it is possible to add to the metadata field, we strongly recommend creating a separate field on your samples for whatever attribute you want to store. This is because the compute_metadata() method, which computes height and width for each image in a dataset, will not function as desired if the metadata is not empty, which could lead to issues downstream.
You can still create more complicated, nested objects, in new EmbeddedDocumentField fields, and have them show up in the FiftyOne App. For instance, if you wanted to create a new custom_metadata field with an embedded field that stores the sample’s uniqueness, you could do so as follows:
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
import fiftyone.core.odm as foo
# load dataset
dataset = foz.load_zoo_dataset("quickstart")
# compute uniqueness
fob.compute_uniqueness(dataset)
# Add a generic embedded document field to which you can add any fields you want
dataset.add_sample_field(
"custom_metadata",
fo.EmbeddedDocumentField,
embedded_doc_type=foo.DynamicEmbeddedDocument,
)
# set values and add to schema
dataset.set_values(
"custom_metadata.uniqueness",
dataset.values("uniqueness"),
dynamic=True,
)
# visualize
session = fo.launch_app(dataset)
Learn more about embedded documents and dynamic attributes in the FiftyOne Docs.
Changing tags when loading CVAT annotations into FiftyOne
Community Slack member Daniel Fortunato asked,
“Hi all! I want to load samples from a CVAT annotation run that have the tag “to_annotate”, and then change these to “being_annotated” in FiftyOne, so that I can keep track of what samples still need to be loaded. I tried using load_annotation_view() to load the view from a specific annotation run, but this does not seem to work with changing the tags. How would you recommend I do this?”
Hey, Daniel! When you change the tags, the reason load_annotation_view() no longer works is that internally, the method is using a MatchTags view stage, which is defined by finding all samples that have certain tags. If you create the view by passing “to_annotate” into match_tags(), and then change the tags on your samples to “being_annotated”, these samples will no longer match the condition.
An alternative approach that bypasses this problem is to redefine the DatasetView with a select() operation after match_tags() and before you change the tags. The Select view stage is defined by a set of sample IDs, so it will not be impacted by changes in tags.
import fiftyone as fo
import fiftyone.zoo as foz
# load dataset
dataset = foz.load_zoo_dataset("quickstart")
# match tags
view = dataset.match_tags("to_annotate")
# redefine the view by sample ID
view = dataset.select(view)
# change tags
view.untag_samples("to_annotate")
view.tag_samples("being_annotated")
Learn more about view stages, the FiftyOne Annotation API, and our CVAT integration in the FiftyOne Docs.
Previewing video frames in FiftyOne
Community Slack member Thrisha Ramkumar asked,
“I have a video dataset with one thousand frames. How do I sample images at regular intervals and preview this in the FiftyOne App?”
Hi Thrisha! Depending on the length of your videos, you may be able to natively “preview” them in the FiftyOne App with its built-in video visualizer. With the video visualizer, you can play the video by hovering over the sample’s thumbnail, as well as scan frame-by-frame, or jump to specific timestamps.
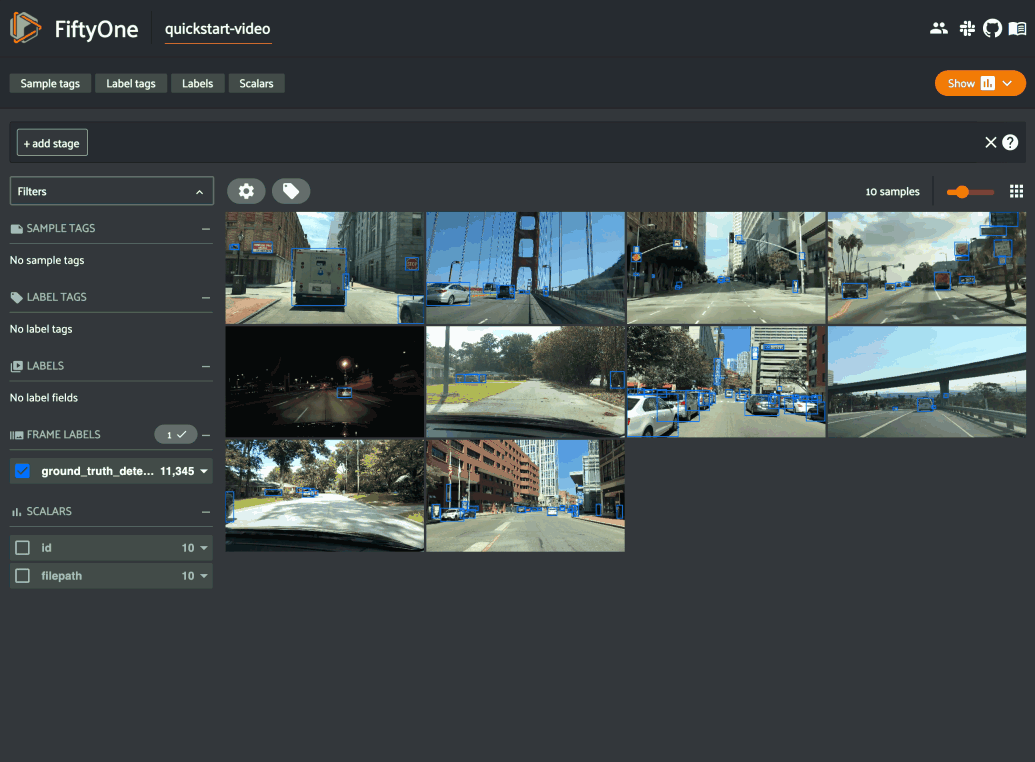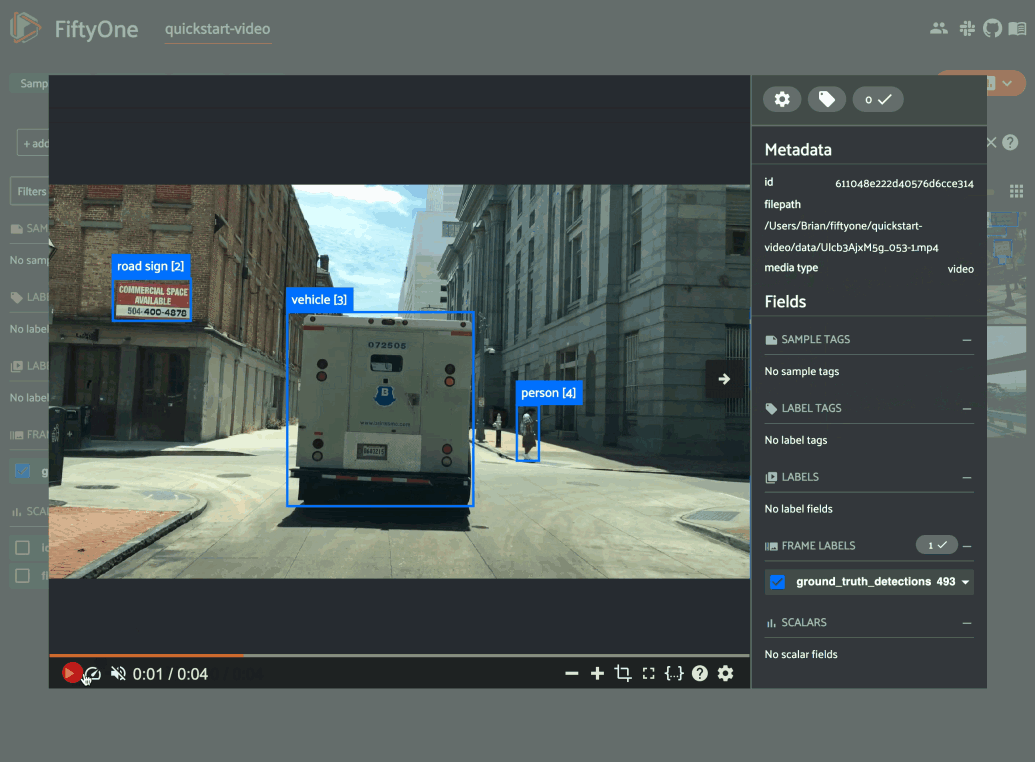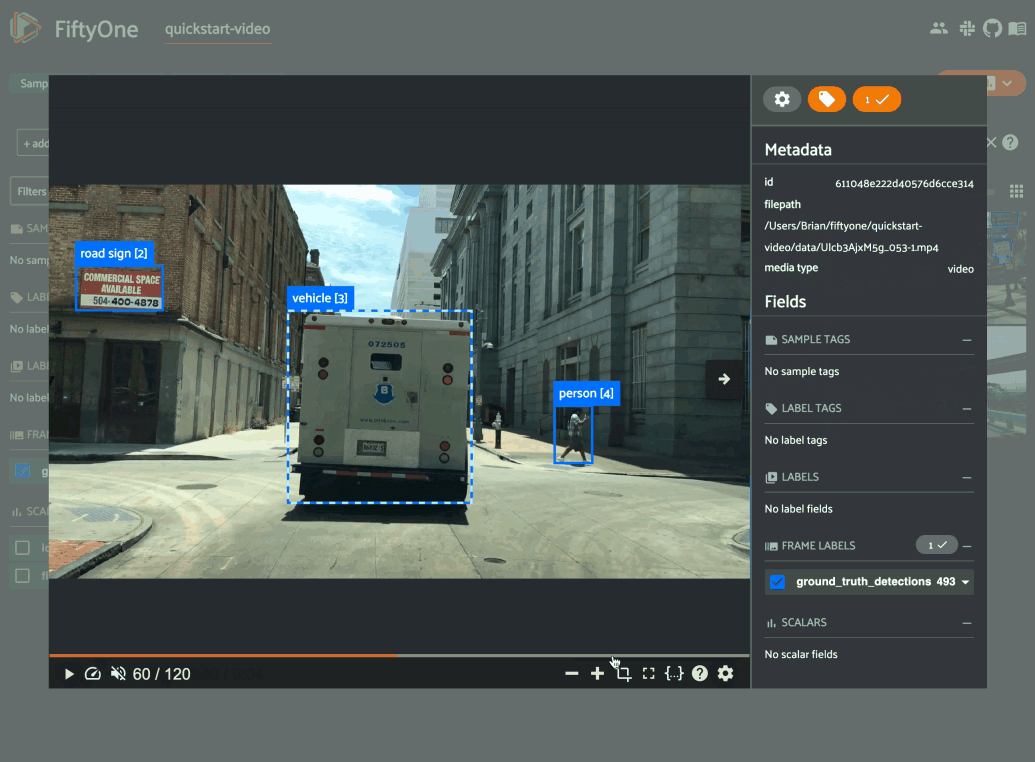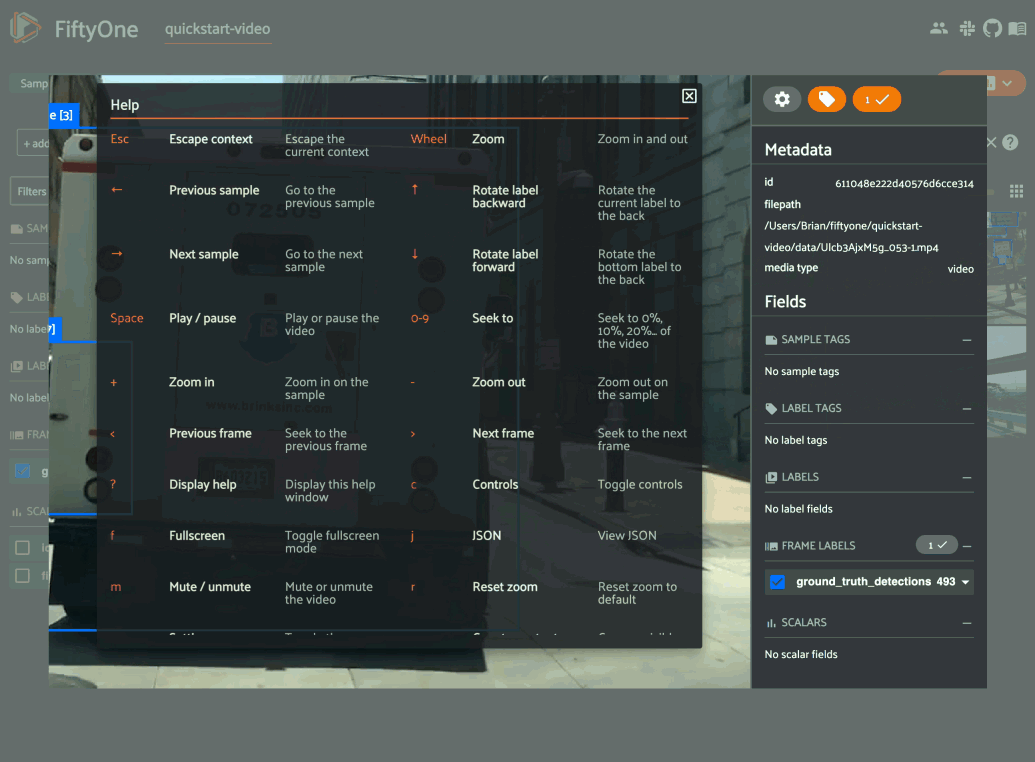
If you are working with very large videos, however, it might be the case that you only want to look at one out of every 100 or 1000 frames. One way you could “preview” the video frames in the FiftyOne App is by converting the video dataset to an image dataset, treating each frame as a new sample. You can then use FiftyOne’s ViewField and the match() method to filter by frame number, in field frame_number, of the frames-turned-image samples.
For example, if you were working with the Quickstart Video Dataset, and you wanted to sample frames at a rate of one image per every ten frames in the original videos, you could run the following:
import fiftyone as fo
import fiftyone.zoo as foz
from fiftyone import ViewField as F
# load dataset
dataset = foz.load_zoo_dataset("quickstart-video")
# convert from videos to frames
frames = dataset.to_frames(sample_frames=True)
# sample every tenth frame
view = frames.match(F("frame_number") % 10 == 0)
# display, or "preview" the results
session = fo.launch_app(view)

Learn more about working with videos, video views, and frames in the FiftyOne Docs.
Frame-level aggregations
Community Slack member Joy Timmermans asked,
“How do I compute the height distribution for bounding boxes in my video dataset without looping over each detection?”
Great question, Joy! Depending on what type of statistics or information about the distribution you want to extract from the dataset, there are a variety of Aggregation methods available in FiftyOne. These methods allow you to extract values, distinct values, means, or upper and lower bounds. In your case, the histogram_values() method might be especially useful, which allows you to compute the histogram over a field’s values. You can even set the number of bins and the range for the histogram!
In FiftyOne, aggregations and many other operations work natively on the frames of videos via the "." syntax to access frame-level attributes. For instance, the following generates a histogram of frame height values across all frames and samples in the Quickstart Video Dataset.
import fiftyone as fo
import fiftyone.zoo as foz
from fiftyone import ViewField as F
# load dataset
dataset = foz.load_zoo_dataset("quickstart-video")
# compute frame width and height
dataset.compute_metadata()
# compute histogram counts and bin edges
# height is last element of bounding box
count, edges, _ = dataset.histogram_values(
F('frames.detections.detections.bounding_box')[3]
)
Learn more about histogram_values() and Expressions in the FiftyOne Docs.
Deleting duplicate samples
Community Slack member Dan Erez asked,
“I accidentally ended up with a bunch of duplicate samples in my dataset. Is there a quick way to drop the duplicates and keep only one of each?”
Hey Dan! Accidental duplication is a common problem when dealing with computer vision data. In FiftyOne, for instance, if you try to add a sample that already exists in your dataset, rather than doing nothing or overwriting the original sample, the dataset will create a new copy of the sample and add that to the dataset. For instance, the following code adds fifty duplicate samples to the Quickstart Dataset:
import fiftyone as fo
import fiftyone.zoo as foz
# load dataset
dataset = foz.load_zoo_dataset("quickstart")
print(dataset.count())
# 200
# randomly select 50 samples
samples_to_duplicate = dataset.take(50)
# add these as duplicates
dataset.add_samples(samples_to_duplicate)
print(dataset.count())
# 250
In many cases, the ability to have multiple samples with the same filepath can be useful, but in some cases, this behavior can have unintended consequences.
Assuming that every sample in your original dataset had a unique filepath, it is easy to “undo” this duplication and get back to your initial dataset. The key to identifying the duplicates is finding which filepaths occur more than once in the dataset, and then deleting all but one sample with each.
To find the multiply-occuring filepaths, you can use FiftyOne’s count_values() aggregation:
fp_counts = dataset.count_values("filepath")
dup_fps = [key for key in list(fp_counts.keys()) if fp_counts[key] > 1]
In the above example, where samples were duplicated at most once, we can deduplicate our dataset by getting the sample IDs of all duplicate filepaths, and passing these into delete_samples():
## IDs of first sample in dataset for each fp sids = [dataset[dup_fp].id for dup_fp in dup_fps] dataset.delete_samples(sids)
If you have more than one duplicate per filepath, check out our recipe for image deduplication.
Learn more about aggregations and deduplication in the FiftyOne Docs.
Join the FiftyOne community!
Join the thousands of engineers and data scientists already using FiftyOne to solve some of the most challenging problems in computer vision today!
- 1,400+ FiftyOne Slack members
- 2,600+ stars on GitHub
- 3,300+ Meetup members
- Used by 254+ repositories
- 56+ contributors

