
Welcome to the latest installment of our ongoing blog series where we highlight datasets from the FiftyOne Dataset Zoo! FiftyOne provides a Dataset Zoo that contains a collection of common datasets that you can download and load into FiftyOne via a few simple commands. In this post, we explore the Cityscapes dataset.
Wait, What’s FiftyOne?
FiftyOne is an open source machine learning toolset that enables data science teams to improve the performance of their computer vision models by helping them curate high quality datasets, evaluate models, find mistakes, visualize embeddings, and get to production faster.

The FiftyOne Dataset Zoo comprises more than 30 datasets, with new datasets being added all the time! They cover a variety of computer vision use cases including:
- Video
- Images
- Location
- Point-cloud
- Action-recognition
- Classification
- Detection
- Segmentation
- Relationships
- And more!

About the Cityscapes Dataset
The Cityscapes Dataset is a large-scale dataset that contains a diverse set of stereo video sequences recorded in street scenes from 50 different cities, with high quality pixel-level annotations of 5,000 frames in addition to a larger set of 20 000 weakly annotated frames. At the time of its release it was an order of magnitude larger than similar previous attempts.
Its primary use case is for assessing the performance of vision algorithms for major tasks of semantic urban scene understanding: pixel-level, instance-level, and panoptic semantic labeling; supporting research that aims to exploit large volumes of (weakly) annotated data, e.g. for training deep neural networks.
What Is Visual Scene Understanding?
Scene understanding is the process of perceiving, analyzing and elaborating an interpretation of a 3D dynamic scene observed through a network of sensors. This usually involves matching signal information coming from the sensors observing the scene, with machine learning models humans are using to understand the scene. As a result, scene understanding both adds and extracts semantic information from the sensor data characterizing a scene. The type of sensors usually involved in visual scene understanding are cameras. But, you may also have scenarios where additional data is being captured by microphones, radar or other sensors. Object-wise, the scene can contain a variety of physical objects of various types (for example cars and people) interacting with each other or with their environment. The scene itself can be just a few seconds long or a multi-day time lapse. It can also be confined to a microscopic view or involve an entire cityscape.
Design Choices
Here’s an overview of the design choices that were made in regards to the dataset’s focus.
Features
| Polygonal annotations |
|
| Complexity |
|
| Diversity |
|
| Volume |
|
| Metadata |
|
| Extensions by other researchers |
|
| Benchmark suite and evaluation server |
|
Labeling Policy
Labeled foreground objects must never have holes. For example if there is some background visible ‘through’ some foreground object, it is considered to be part of the foreground. This also applies to regions that are highly mixed with two or more classes: they are labeled with the foreground class. Some examples would include:
- tree leaves in front of house or sky (everything tree)
- transparent car windows (everything car)
Class Definitions
| Group | Classes |
| flat |
|
| human |
|
| vehicle |
|
| construction |
|
| object |
|
| nature |
|
| sky |
|
| void |
|
* Single instance annotations are available. However, if the boundary between such instances cannot be clearly seen, the whole crowd/group is labeled together and annotated as group, e.g. car group.
+ This label is not included in any evaluation and treated as void (or in the case of license plate as the vehicle mounted on).
Dataset Quick Facts
- Research Paper: The Cityscapes Dataset for Semantic Urban Scene Understanding
- Authors: M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele
- Download Dataset: Register and download
- License: Free, but registration is required
- Dataset Size: 11.8 GB
- Last Release: 2016
- FiftyOne Dataset Name:
cityscapes - Tags:
image,multilabel,automotive,manual - Supported Splits:
train,validation,test - Zoo Dataset class:
CityscapesDataset
Step 1: Download the Dataset
In order to load the Cityscape Dataset into FiftyOne, you must download the source data manually with your source_dir organized in the following manner:
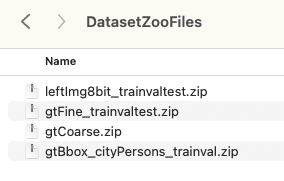
Note that the gtFine_trainvaltest, gtCoarse, and gtBbox_cityPersons_trainval are optional directories.
Step 2: Install FiftyOne
If you don’t already have FiftyOne installed on your laptop, it takes just a few minutes! For example on macOS:
- Verify your version of Python
- Create and activate a virtual environment
- Install IPython (optional)
- Upgrade your
Setuptools - Install FiftyOne

Learn more about how to get up and running with FiftyOne in the Docs.
Step 3: Import the Dataset
Now that you have the dataset downloaded and FiftyOne installed, let’s import the dataset into FiftyOne and launch the FiftyOne App. This should take just a few minutes and a few more lines of code.
import fiftyone as fo
import fiftyone.zoo as foz
# The path to the source files that you manually downloaded
source_dir = "/path/to/dir-with-cityscapes-files"
dataset = foz.load_zoo_dataset(
"cityscapes",
split="validation",
source_dir=source_dir,
)
session = fo.launch_app(dataset)
The last line in the code snippet will launch the FiftyOne App in your default browser. You should see the following initial view of the cityscapes-validation dataset in the FiftyOne App:

Tip: If you want to persist the dataset, add the following to your initial load command:
dataset.persistent = True
Ok, let’s do a quick exploration of the Cityscape Dataset!
Sample Details
Click on any of the samples to get additional detail like tags, metadata, labels, and primitives.

Filtering by ID
FiftyOne makes it very easy to filter the samples to find the ones that meet your specific criteria. For example we can filter by a specific id:
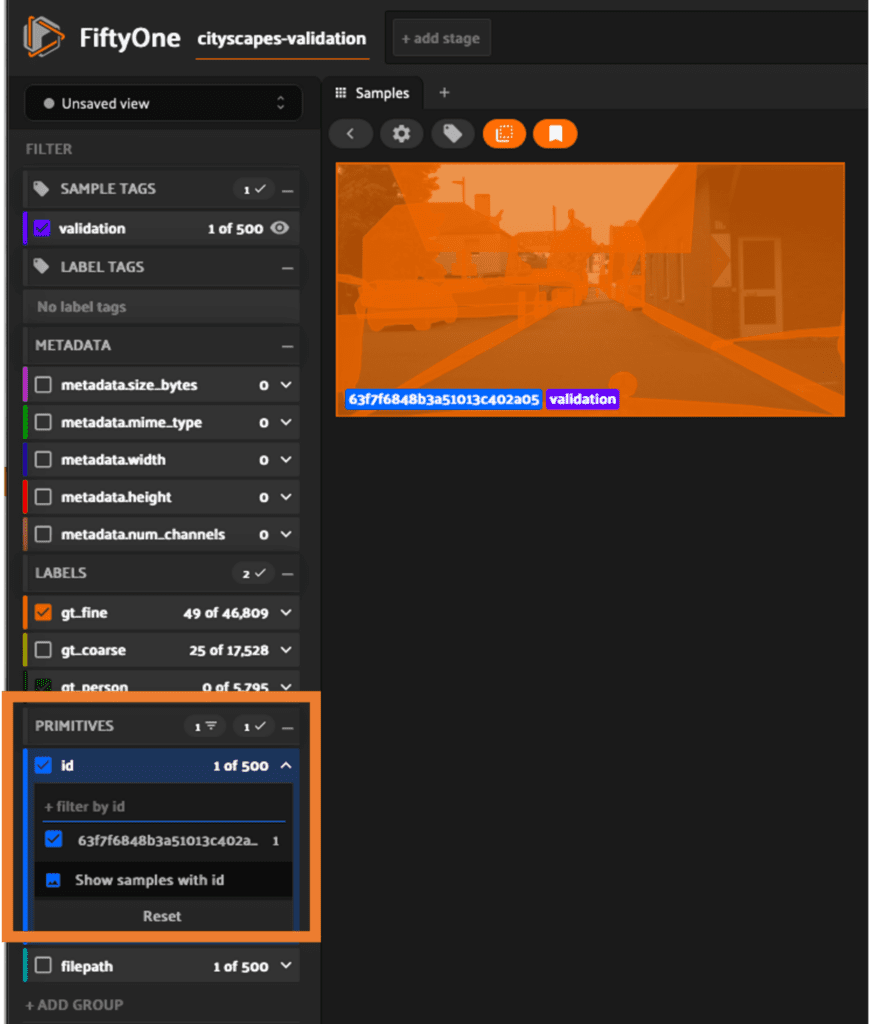
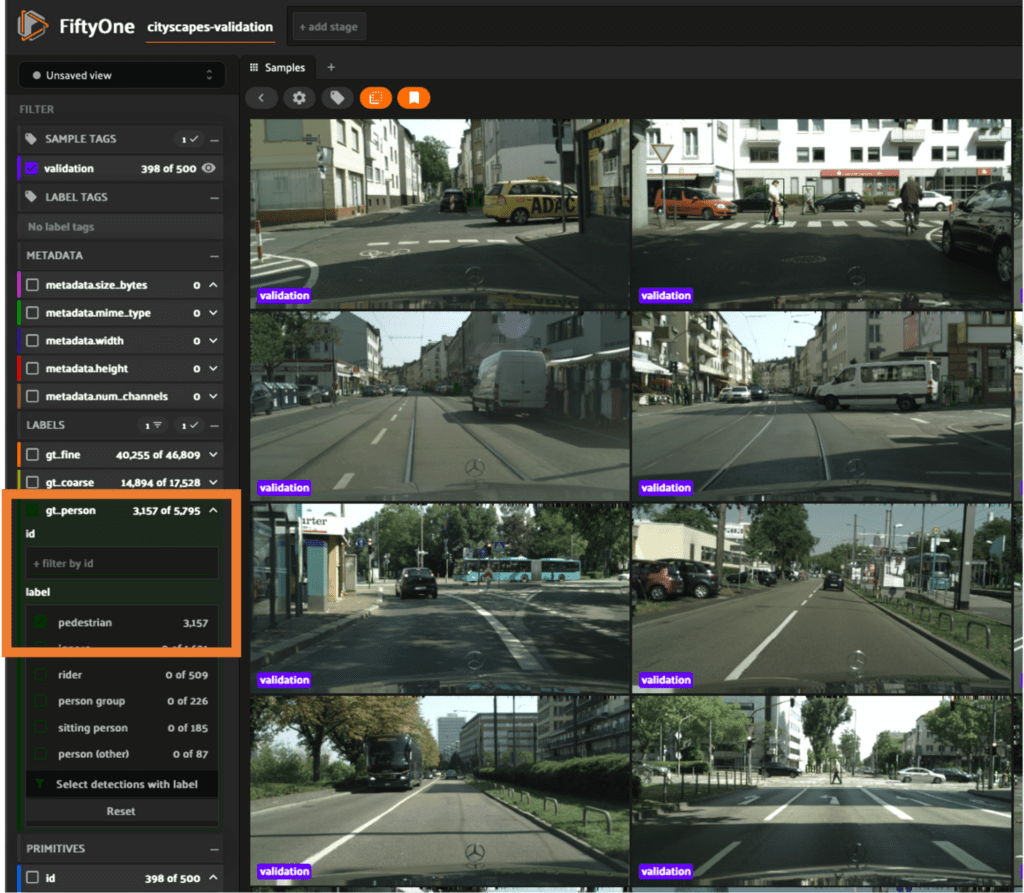
Filtering by Label
In this example we filter the samples by the gt_person label selecting only those with pedestrian:

In this example we filter the samples by the gt_coarse label:
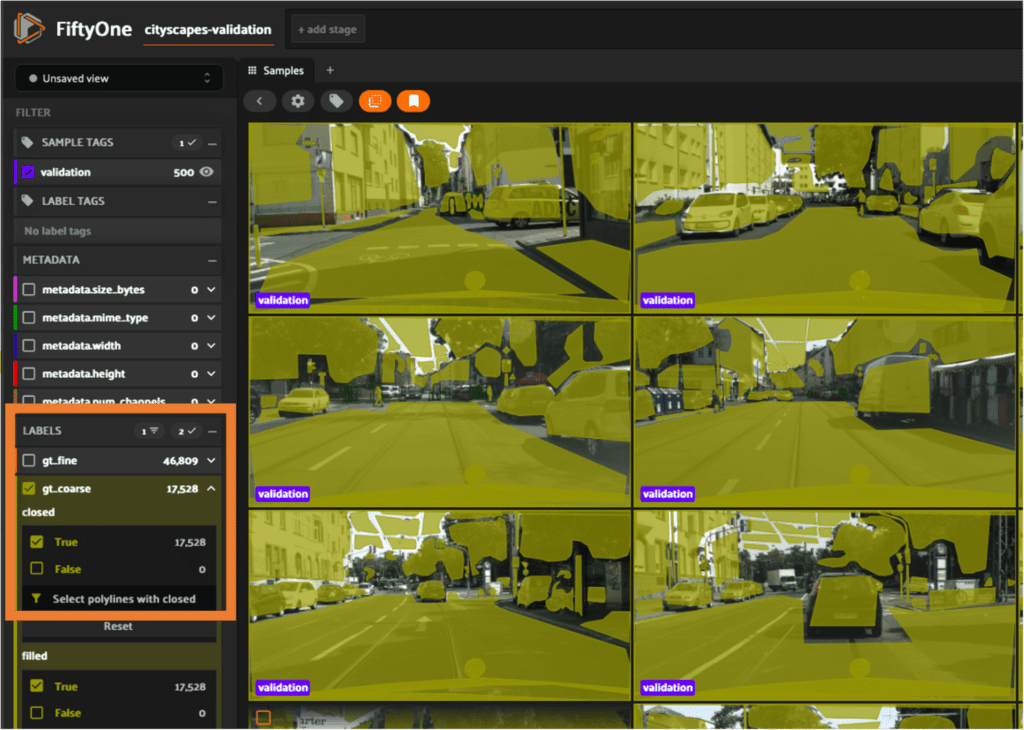
Start Working with the Cityscapes Dataset
Now that you have a general idea of what the dataset contains, you can start using FiftyOne to perform a variety tasks including:
- Creating dataset views
- Creating aggregations
- Creating interactive plots
- Annotating datasets
- Evaluating models
You can also start making use of the FiftyOne Brain which provides powerful machine learning techniques you can apply to your workflows like visualizing embeddings, finding similarity, uniqueness and mistakenness.

